机器学习——Bahdanau 注意力
9.7节中探讨了机器翻译问题: 通过设计一个基于两个循环神经网络的编码器-解码器架构, 用于序列到序列学习。 具体来说,循环神经网络编码器将长度可变的序列转换为固定形状的上下文变量, 然后循环神经网络解码器根据生成的词元和上下文变量 按词元生成输出(目标)序列词元。 然而,即使并非所有输入(源)词元都对解码某个词元都有用, 在每个解码步骤中仍使用编码相同的上下文变量。 有什么方法能改变上下文变量呢?
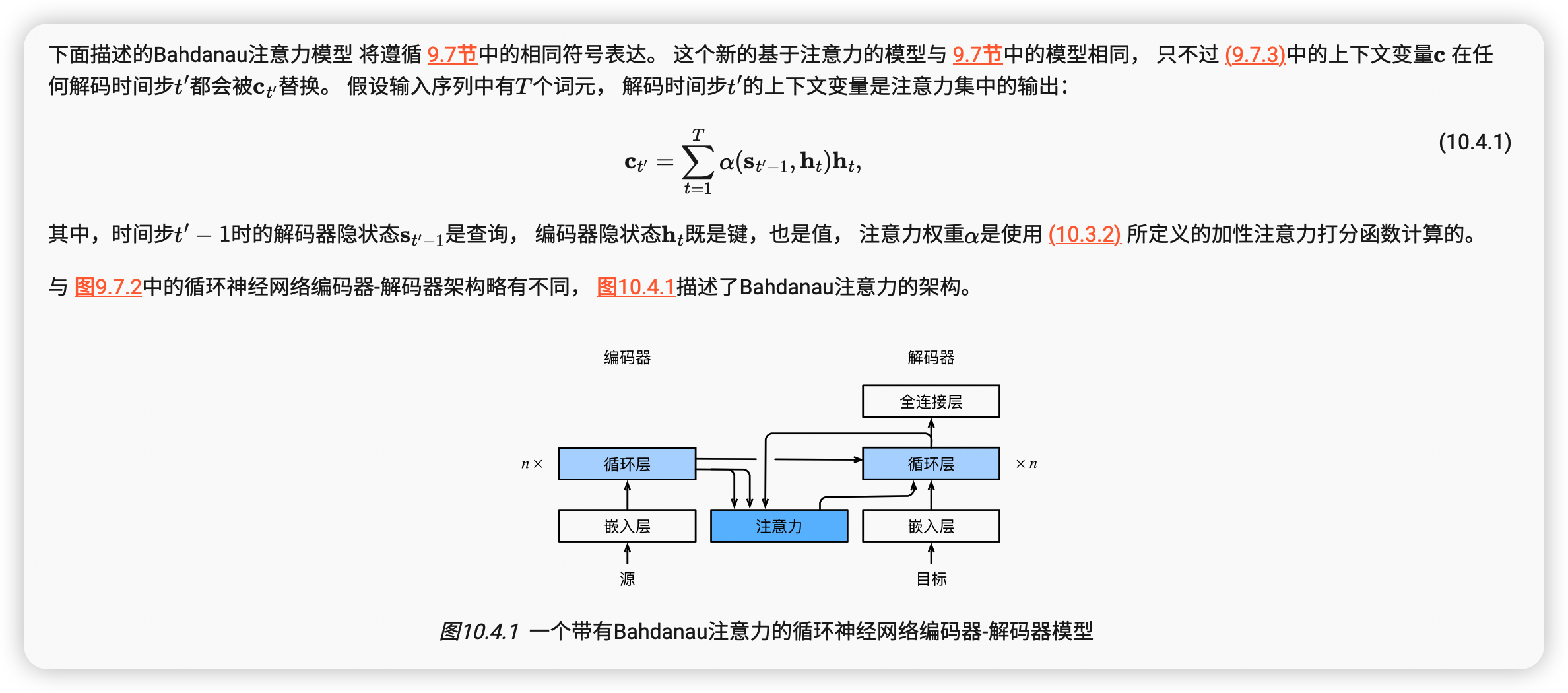
Bahdanau等人提出了一个没有严格单向对齐限制的 可微注意力模型 (Bahdanau et al., 2014)。 在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
模型
总结
-
在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
-
在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号