机器学习——GPU
张量与GPU
不同GPU之间操作
神经网络与GPU
总结
-
我们可以指定用于存储和计算的设备,例如CPU或GPU。默认情况下,数据在主内存中创建,然后使用CPU进行计算。
-
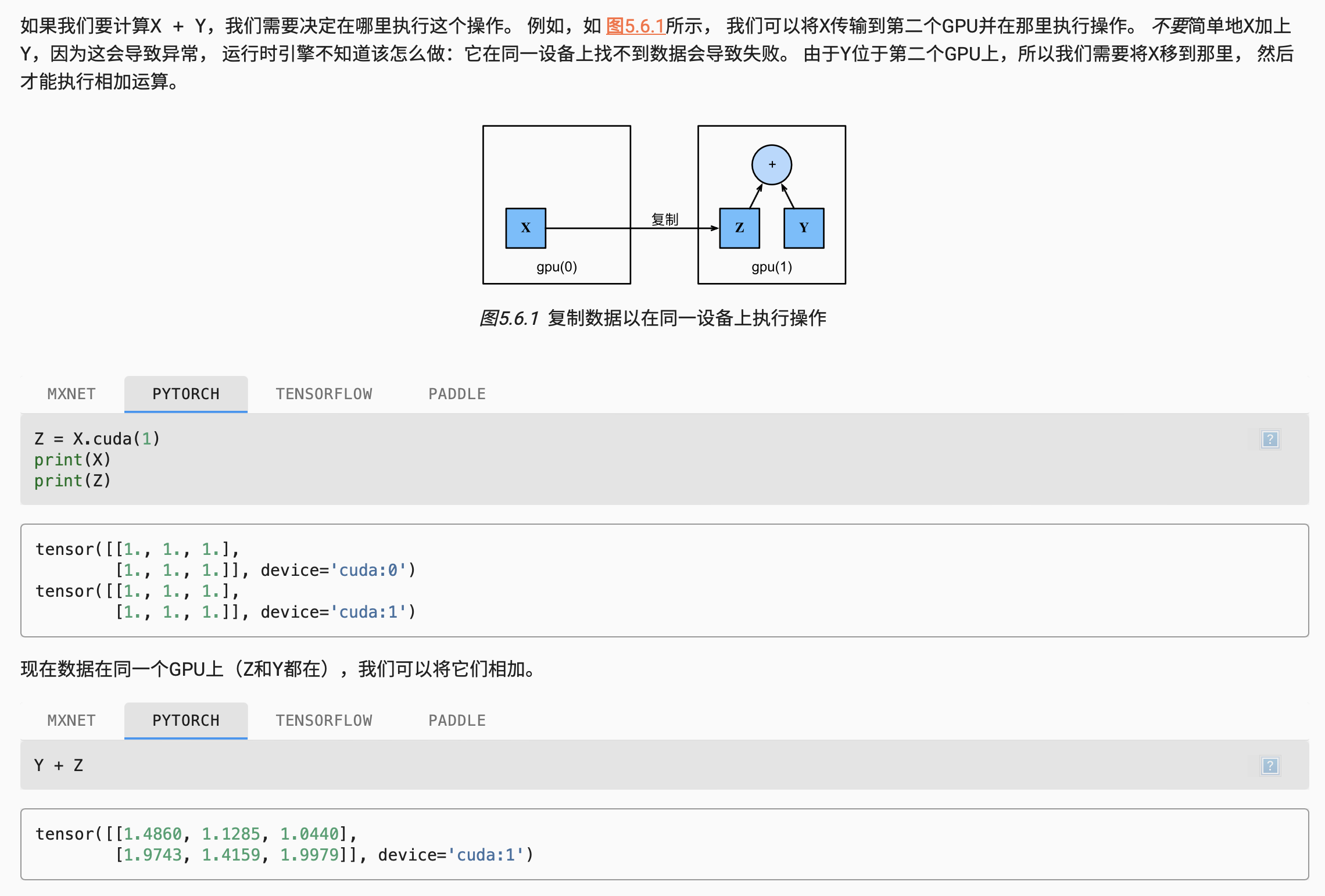
深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU。
-
不经意地移动数据可能会显著降低性能。一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy
ndarray中)时,将触发全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志。(当我们打印张量或将张量转换为NumPy格式时, 如果数据不在内存中,框架会首先将其复制到内存中, 这会导致额外的传输开销。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号