机器学习——参数管理
参数访问
我们从已有模型中访问参数。 当通过Sequential类定义模型时, 我们可以通过索引来访问模型的任意层。 这就像模型是一个列表一样,每层的参数都在其属性中。 如下所示,我们可以检查第二个全连接层的参数。
print(net[2].state_dict())
OrderedDict([('weight', tensor([[-0.0427, -0.2939, -0.1894, 0.0220, -0.1709, -0.1522, -0.0334, -0.2263]])), ('bias', tensor([0.0887]))])
输出的结果告诉我们一些重要的事情: 首先,这个全连接层包含两个参数,分别是该层的权重和偏置。 两者都存储为单精度浮点数(float32)。
print(type(net[2].bias)) print(net[2].bias) print(net[2].bias.data)
<class 'torch.nn.parameter.Parameter'> Parameter containing: tensor([0.0887], requires_grad=True) tensor([0.0887])
net[2].weight.grad == None
True
注意,每个参数都表示为参数类的一个实例。参数是复合的对象,包含值、梯度和额外信息。 这就是我们需要显式参数值的原因。 除了值之外,我们还可以访问每个参数的梯度。
参数初始化
默认情况下,PyTorch会根据一个范围均匀地初始化权重和偏置矩阵, 这个范围是根据输入和输出维度计算出的。 PyTorch的nn.init模块提供了多种预置初始化方法。
下面举例说明对某些块应用不同的初始化方法。 例如,下面我们使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42。(以PyTorch为例)
def init_xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
def init_42(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 42)
net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)
tensor([ 0.5236, 0.0516, -0.3236, 0.3794])
tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])
下面的代码将所有权重参数初始化为标准差为0.01的高斯随机变量, 且将偏置参数设置为0。
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
(tensor([-0.0214, -0.0015, -0.0100, -0.0058]), tensor(0.))
自定义参数初始化
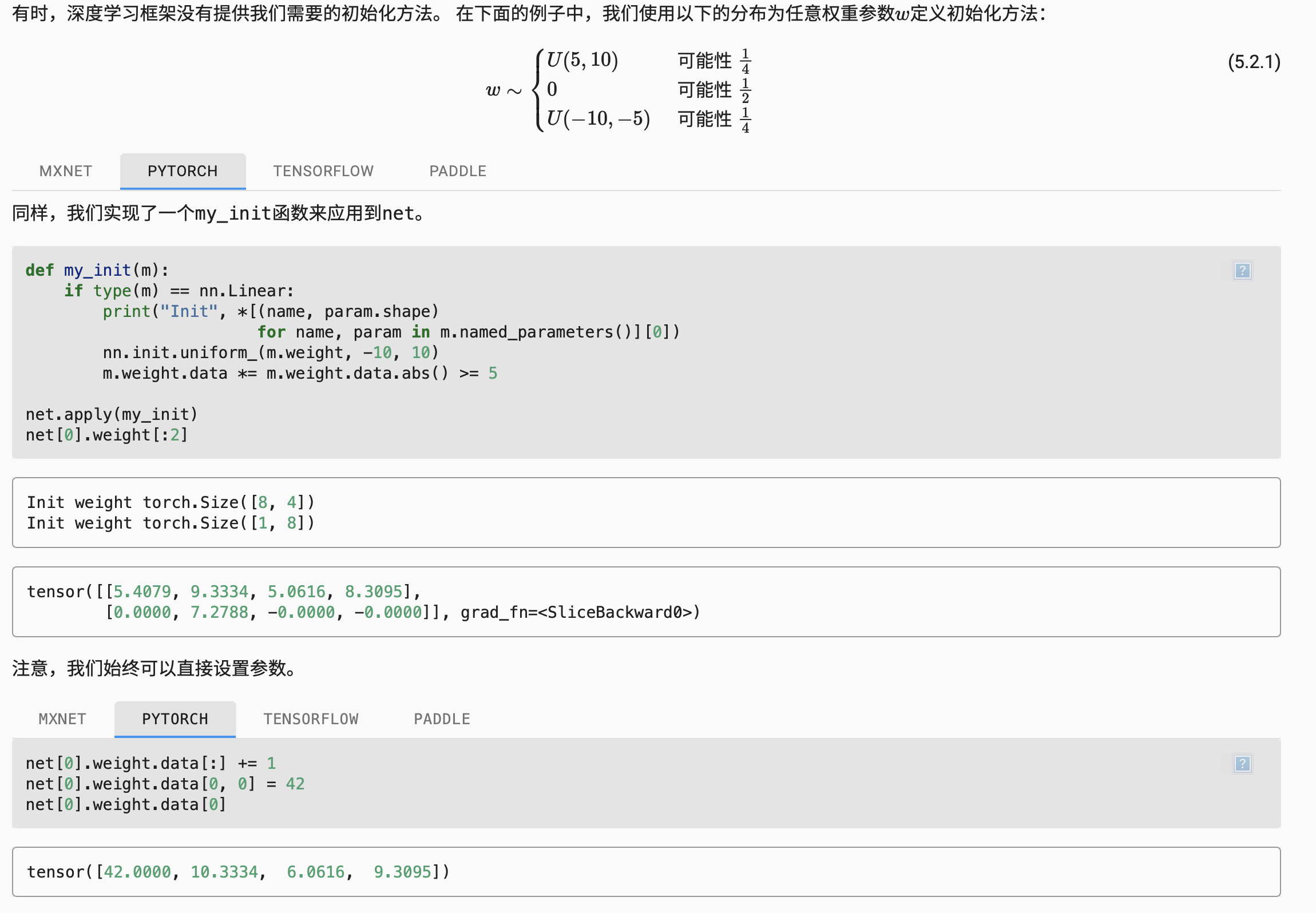
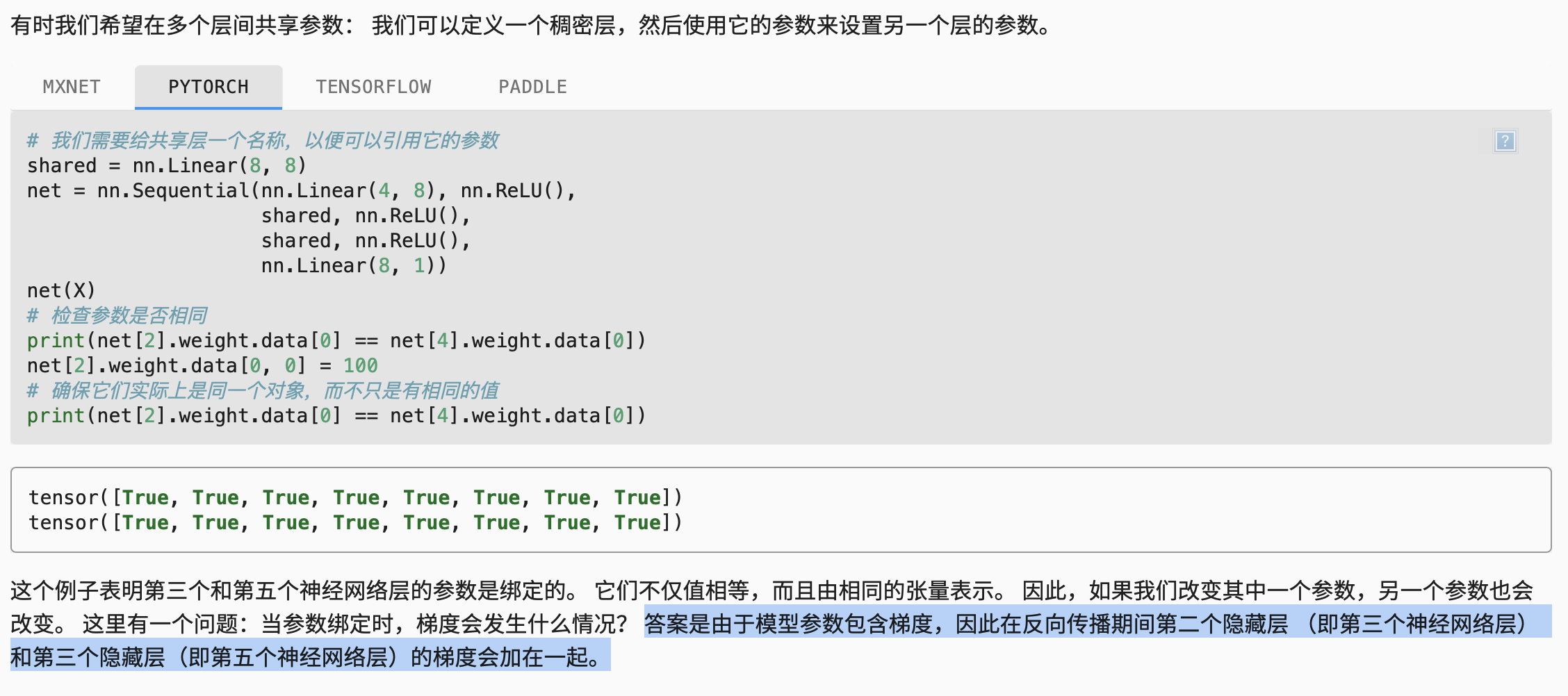
参数绑定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号