目录
协议的五个元素
实例
服务描述
环境假设
协议词汇
信息格式
过程规则
设计缺陷
服务与环境
词汇与格式
面向比特编码
面向字符编码
面向字节数编码
信息的头与尾
过程规则
结构化协议设计
简单化
模块化
符合规范的协议
健壮性
一致性
设计规则
2.1 协议的五个元素
一个协议规范包含5个不同部分,完整起见,每个规范应该明确包含:
1. 服务(Service):协议提供的服务。在语言抽象模型中为语义(Semantic)
2. 假设(Assumptions):协议执行时对环境的假设。语言抽象模型中为元语言(Meta-language),对对象语言进行底层语义解释。
3. 词汇(Vocabulary):用来实现协议的信息,在协议将相互交互。语言抽象模型中为词汇。
4. 编码(Encoding):每个词汇的编码格式。语言抽象模型中为词法(Syntax)
5. 过程规则(Procedure Rules):保证信息交换的一致性,定义了信息交换的规则。语言抽象模型中为语法(Grammer)
2.2 实例
此处给出一个简单的协议,以解释协议五元素的具体意义。
2.2.1 服务描述
该协议用来在电话线上以字符序列的传输方式来传输一个文本文件,同时防止传输错误,并假设所有传输错误都能被检测到。
该协议是双工文件传输程序。流量的正反馈(Positive ACK)和负反馈(Negative ACK)从信道的两边都能互相传输。
每个信息包含两个部分:信息部分和流控制部分。
2.2.2 环境假设
该协议假设至少两个文件传输用户和一个信道。
用户行为被假设为:发送一个请求然后等待传输结束。
信道行为被假设为:信息损坏(不丢失)、重复、插入(无中生有)、乱序。
对低级模块的假设:捕捉所有损坏,并把它们转化为未被损坏的信息,其类型为err。
2.2.3 协议词汇
该协议的词汇为 {ack, err, nak},其意义解释如下:
ack:带有正反馈的信息。
nak:带有负反馈的信息。
err:表示传输错误的信息。
2.2.4 信息格式
该协议的词汇使用类C语言描述其编码为:
enum ctrl {ctrl_ACK, ctrl_NAK, ctrl_ERR}; struct msg { enum ctrl tag; //信息类型 unsigned char data; //数据 };
2.2.5 过程规则
该协议的过程规则用自然语言描述如下:
1. 若前一个信息无错接收,那么会在反向信道上传递一个正反馈信息,反之,将会传递一个负反馈信息。
2. 若前一个接收信息带有负反馈或出错,那么重传那个旧信息。否则取出一个新的信息然后传输之。
2.2.6 设计缺陷
该设计有以下已知缺陷:
1. 数据传输程序只有在两个传输方向都能传输才能正确运行。
2. 没有定义协议初始化和结束过程。
3. 没有能够处理乱序、重复、插入。
2.3 服务与环境
一个协议为了实现某个高层抽象级别描述的功能(即服务),必须依靠低级抽象级别的功能来构造,那么就对协议运行环境做出了假设(或者说是底层对上层的限制)。
借助软件构架的分层结构,将通信问题分割为不同级别的抽象层次,每个级别解决特定抽象层次的问题,并为上层高级抽象逻辑提供低级解释,使各个抽象层彼此相对独立。
ISO定义了若干抽象层次,如下所示:
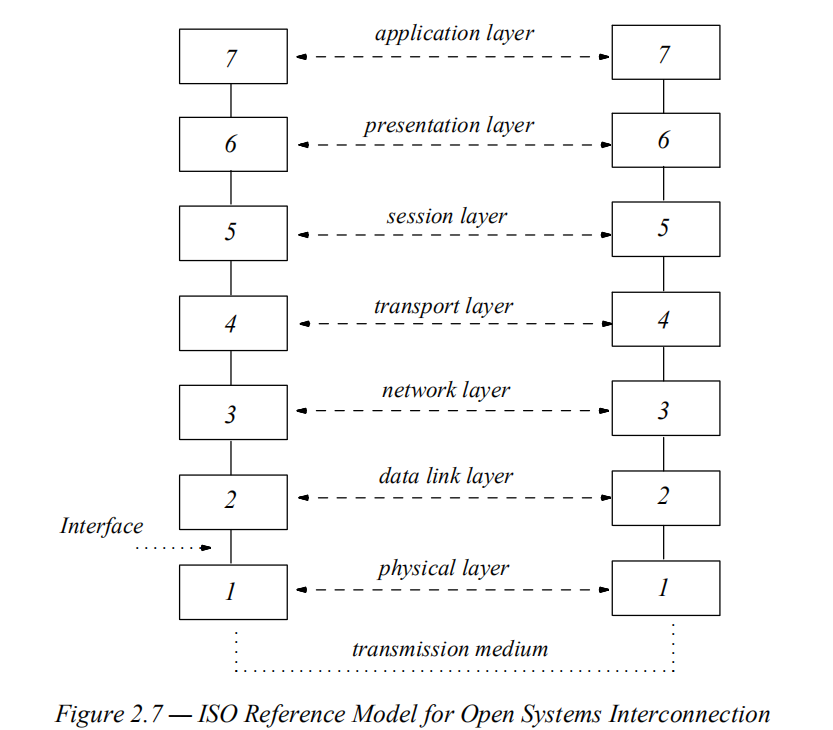
2.4 词汇与格式
协议在物理设备上实现时需要对其协议数据包编码,有以下三种主要编码方法:
1. 面向比特编码。
2. 面向字符编码。
3. 面向字节数编码。
2.4.1 面向比特编码
面向比特的协议将数据作为比特流传输。为使接受者识别信息的起始处和结尾,必须使用一组特殊的比特序列来标识。
必须注意,这些特殊比特序列可能出现在信息内部,可能操作对信息的错误接收。
例如,若一个数据帧的开头和结尾都是以0111_1110b标识,那么必须对每5个连续一之间插入一个0来防止错误接受
(但是书上没有给出一些特殊情况接收者如何确定某个零是否是数据本身还是被插入的的解决方法,例如若本身数据中就含有序列0_11111_0,接收者如何判断最后的0是不是被插入的呢?)。
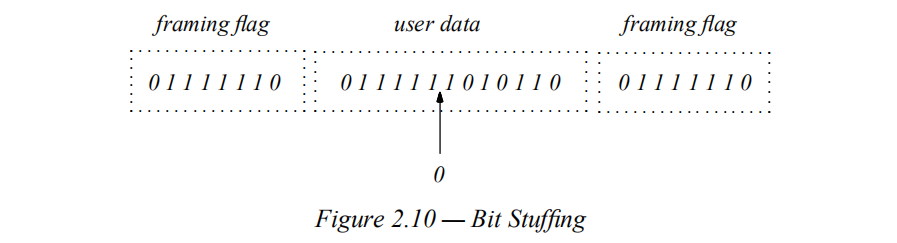
这种方法被称为比特填充(bit Stuffing)。
2.4.2 面向字符编码
面向字符编码的协议将数据看做n-bit的字符流来传输,为了标识信息的起始和结尾,使用特殊的字符标识。
例如ASCII的控制代码STX (Start of TeXt)标识起始、ETX(End of TeXt)标识结尾。

与面向比特编码的协议有同样的问题,如果数据中含有特殊字符将会导致错误的信息接收,通过加入转义字符DLE(DeLimitEr)使特殊字符意义无效,作为普通字符处理,该种处理方法叫做字符填充(Character Stuffing)。
2.4.3 面向字节计数的编码
该种编码方式是对使用标记来标识信息起始和结尾这种编码方式的改进,其主要的改进在于在起始符号STX的后面附加一个信息包字节计数,这样根据字节计数就可以得到信息包的结尾。
2.4.4 信息的头与尾
由于需要对信息的错误、丢失、乱序等传输错位进行纠正,所以需要在信息上附加其他信息来纠正这些错误(根据以往经验得知的),于是有下图结构:
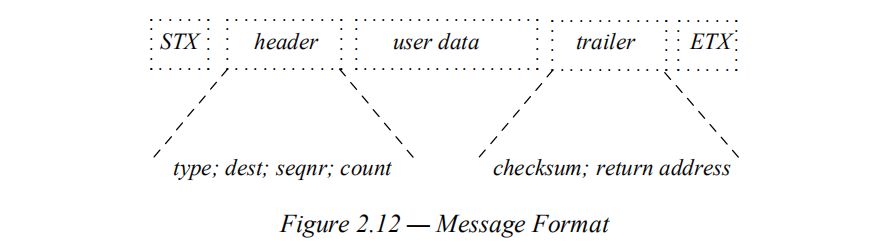
其中
header.type 表示该信息的类型。
header.dest 是该信息的接收地址。
header.seqnr 是用来重传、保序等。
header.count 是信息的大小。
trailer.checksum 用来纠错。
trailer.returen address 是源地址。
2.5 过程规则
协议交互过程是一个分布式并行算法的运行,没有模型(该书作者在第10章详细讨论)能够解析出一个分布式并行算法所有理论缺陷,只能使用一些技巧来减少设计缺陷。这本书的作者列举了以下方法:
1. 使用转换表、有限状态机来形式化协议的描述。
2. 使用协议模拟器来自动化验证协议的运行。
3. 使用一些软件架构思想来减少协议设计的复杂度。
2.6 结构化协议设计
我个人觉得这种诸如软件设计思想的这种东西很虚,听着高大上,没有提供具体的实践规范,纸上谈兵,为了完整起见,下面摘要了作者的大意。
2.6.1 简单化
一个良好结构化的协议是从若干设计良好且容易理解的模块构造而成,这些模块之间的交互机制也要优雅。每一个模块做好做专特定功能,使得整个协议易于修改、维护、验证。
2.6.2 模块化
高内聚、低耦合、复用性高、简单化、易于验证。
2.6.3 符合规范的协议
描述协议要结合实际物理限制并尽可能考虑周全,不要出现不能实现或不能执行的模型,也要注意一些可能没有被考虑到的意外情形,做好防御性编程,并满足下列规范:
确界性(bounded)
不能超越已知的系统极限。
自稳定(self-stabilizing)
若一个瞬时误差任意改变了协议的状态,自稳定协议总能在有限步骤内会到合适的状态,恢复正常工作。同样,处于任何系统状态的自稳定协议都能在有限时间内到达特定状态。
自适应(self-adapting)
可以根据环境的反馈对自身工作进行调节以达到特定的要求。
2.6.4 健壮性
协议设计时总要假设设计的协议是有缺陷的,不能对协议的运行环境做出过多的假设,并做好适当的防御性编程,防御意料之外的情况。
2.6.5 一致性
有三种主要的错误会影响协议的一致性:
死锁(deadlock):处于该状态下的协议无法继续执行,例如:协议进程在等待一个永远不能满足的条件。
活锁(livelock):执行序列无限重复执行,但没有做任何实质性工作。
不正确的终止:未在正确的终止条件下终止协议的执行。
2.7 设计规则
有以下10个规则用以作为协议设计的基本规则。
1. 确保问题是良定义的。
2. 在决定使用那个结构实现实现具体功能之前先把每个抽象层次的功能定义清楚(“是什么”在“如何实现之前”)。
3. 在实现内部功能之前先把外部功能定义好。
4. 保持协议简单。
5. 不要耦合互相独立的机制。
6. 不要介入不重要的问题特征,使解决办法能够解决具有某种同样抽象特征的问题。
7. 在实现设计之前先建立高级原型。
8. 实现设计、测量其效率,尽可能优化之。
9. 检查优化后的实现是否与验证的高抽象级设计等价。
10. 不要跳过规则1到7。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号