
spark的安装
1. 下载并解压
在官网:https://archive.apache.org/dist/spark/ 下载所需版本的 spark,这里我下载的版本为2.3.1,下载后进行解压(Linux文件类型:*.tar.gz和*.tgz 用 tar –xzf 解压):
1 [root@linux01 ~]# tar -zxvf jdk-8u321-linux-x64.tar.gz
2. 修改SPARK配置文件
进入spark解压所在目录下的conf文件夹内:
[root@linux01 spark-2.3.1-bin-hadoop2.7]# cd conf/
[root@linux01 conf]# ls
docker.properties.template log4j.properties.template slaves.template spark-env.sh.template
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
可以看到conf目录下的所有文件的后缀都是 ”.template“,这是官方默认的文件命名方式。如果此时启动spark,则这些文件内的属性不会生效。
因此需要将这些配置文件的文件名改为spark可以识别的形式。
2.1 去掉默认的配置文件的后缀名”.template“
具体命令如下:
[root@linux01 conf]# for i in *.template; do cp ${i} ${i%.*}; done
或者
[root@linux01 conf]# for i in *.template; do mv ${i} ${i%.*}; done
这是shell语法中的for循环,对当前目录中的所有文件拷贝操作。
其中”${i%.*}“的含义是从右边截取字符串到第一个”.”字符出现的位置到并删除该字符右边的全部内容,并保留该字符左边的全部内容。这样就不需要一次使用“mv”命令来重命名文件了。
上边区别在于一个是复制一个是重命名,复制保留了所有”.template“的文件。
2.1 修改配置文件:slaves;
[root@linux01 conf]# vi slaves
先删除“localhost”所在的那一行,
然后添加主机名称:
linux01
linux02
linux03
2.2 修改配置文件:spark-env.sh
[root@linux01 conf]# vi spark-env.sh
添加如下 :
SPARK_MASTER_PORT=7077
3 配置LINUX环境变量
vi /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6export PATH=${SPARK_HOME}/bin:$PATH
看我的结果:
export HADOOP_HOME=/usr/software/hadoop-2.7.2 export SPARK_HOME=/usr/software/spark-2.3.1-bin-hadoop2.7 export JAVA_HOME=/usr/java/jdk1.8.0_321 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
执行 source 命令,使得配置立即生效:
[root@linux01 ~]# source /etc/profile
分发至其他节点
[root@linux01 software]# scp -r spark-2.3.1-bin-hadoop2.7 linux02:`pwd`
[root@linux01 software]# scp -r spark-2.3.1-bin-hadoop2.7 linux03:`pwd`
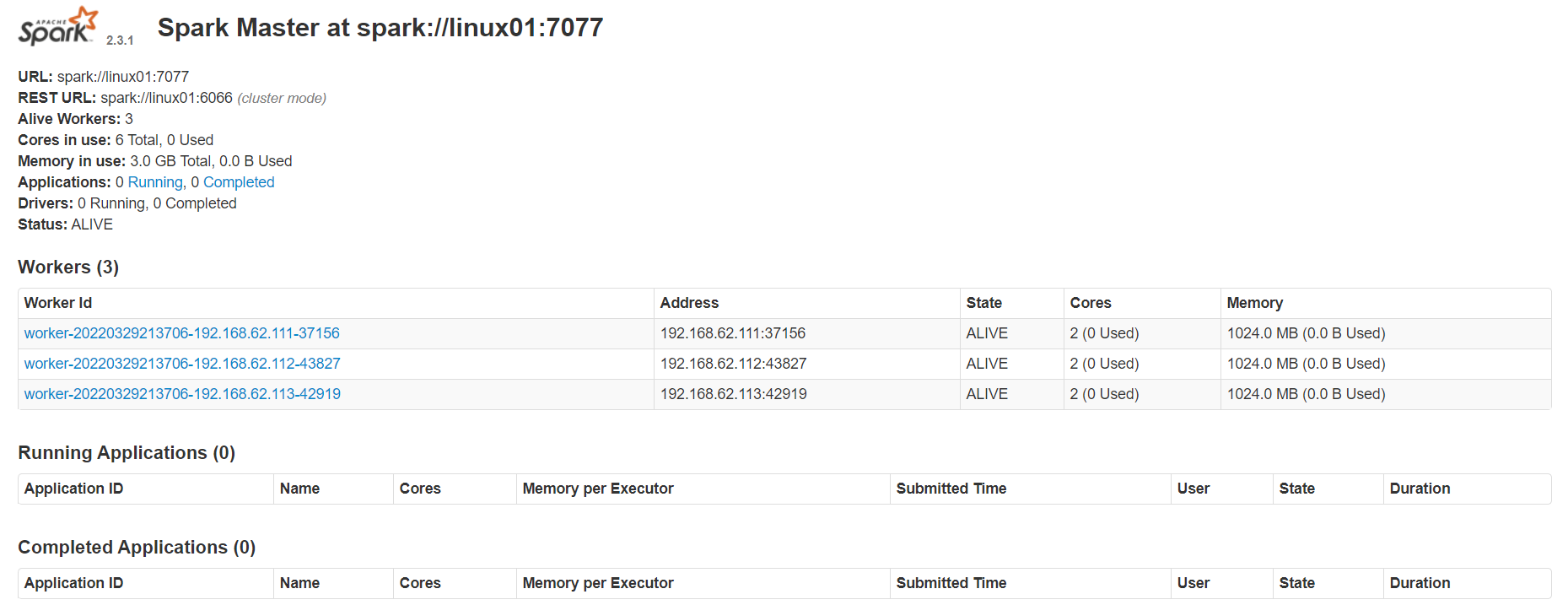
启动并查看服务 :(spark的sbin目录下 ./start-all.sh,浏览器中输入http://linux01:8080查看,以下为结果图)
[root@linux01 ~]# cd /usr/software/spark-2.3.1-bin-hadoop2.7/sbin/
[root@linux01 sbin]# ./start-all.sh
[root@linux01 sbin]# jps
9777 Worker
9825 Jps
9699 Master
[root@linux02 ~]# jps
4384 Jps
4339 Worker
[root@linux01 sbin]# netstat -nlt
#在浏览器中输入http://linux01:8080,即可以进入Spark集群状态页面(看到别的博客windows防火墙打开,可能会导致直接访问有问题,需要把宿主机端口与访问的虚拟机端口进行关联配置,通过访问宿主机端口来达到访问虚拟机端口的目的,去此处解决此问题https://www.cnblogs.com/swordfall/p/7903678.#html)
[root@linux01 sbin]# spark-shell --master local[2] 22/03/22 00:30:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://linux01:4040 Spark context available as 'sc' (master = local[2], app id = local-1647880243991). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_321) Type in expressions to have them evaluated. Type :help for more information. scala>
#此时可及进行j简单作业WordCount,并进入通过 Web UI 查看作业的执行情况,访问端口为4040,即地址为:linux01:4040
spark的sbin目录下 ./start-all.sh,浏览器中输入http://linux01:8080查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号