【温故而知新-Javascript】理解 DOM
DOM(Document Object Model,文档对象模型)允许我们用 JavaScript 来探查和操作 HTML 文档里的内容。它对于创建丰富性内容而言是必不可少的一组功能。
1. 理解文档对象模型
DOM 是一组对象的集合,这些对象代表了HTML文档里的各个元素。顾名思义,DOM就像一个模型,它由代表文档的众多对象组成。
先来个简单的HTML文档的例子:
<!DOCTYPE html> <html> <head> <meta name="author" content="Luka" /> <meta name="description" content="A simple example" /> <title>Example</title> </head> <body> <p> 你的特别不是因为你在创业,不是因为你进了牛企,不是因为你的牛offer,而是因为你就是你,坚信自己的特别,坚信自己的内心,勇敢做自己。 <span>IT DOESN'T MATTER WHERE YOU ARE, IT MATTERS WHO YOU ARE.</span> </p> <p> 15岁的时候再得到那个5岁的时候热爱的布娃娃,65岁的时候终于有钱买25岁的时候热爱的那条裙子,又有什么意义。 什么都可以从头再来,只有青春不能。 那么多事情,跟青春绑在一起就是美好,离开青春,就是傻冒。 </p> </body> </html>
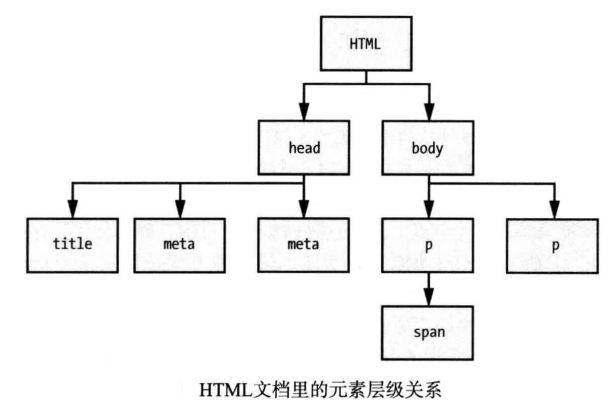
从下图可以看到浏览器是如何显示上述示例HTML文档的:

作为显示HTML文档过程中的一个步骤,浏览器会解析HTML并创建一个模型。这个模型保存了各个HTML元素之间的层级关系(如下图所示),每个元素都由一个 JavaScript 对象表示。
你可以用DOM来获取文档信息,也可以对其进行修改。这是现代Web应用程序的基础。
模型里的每个对象都由若干个属性和方法。当你用它们来修改对象的状态时,浏览器会让这些改动反映到对应的HTML元素上,并更新文档。
所有代表元素的DOM对象都支持同一组基本功能:HTMLElement 对象和其定义的核心功能始终是可用的,无论对象代表何种元素都是如此。另外,某些对象会定义一些额外的功能。这些操作反映了特定HTML元素的独一无二的特性。文档模型里任何代表某个元素的对象都至少能支持HTMLElement 功能,其中一些还支持额外的功能。
不是所有可供使用的对象都代表了HTML元素。一些对象代表元素的集合,另一些则代表DOM自身的信息,当然还有Document这个镀锡,它是我们探索DOM的入口。
2. 理解 DOM Level和兼容性
DOM Level是标准化过程中的版本号,在大多数情况下应该忽略它们。
DOM 的标准化并不是完全成功的,每一个DOM Level都有描述它的标准和文档,但它们并没有完整地实现,浏览器只是简单的挑选了其中的有用功能,而忽略了其他的。更糟的是,已经实现的功能还存在某种程度的不一致性。
部分问题在于,DOM规范与HTML标准过去是分别开发的。HTML5试图通过包含一组必须实现的DOM核心功能来解决这个问题。然而这种做法尚未见效,碎片化仍然存在。
有多种方式可用来实现DOM功能的多变性。第一种方式是使用某个JavaScript库(比如jQuery),它消除了浏览器之间实现方式的差别。使用库的有点在于其一致性,但缺点是只能用库支持的那些功能。如果想突破原有功能的局限,就只能转回到直接操作DOM上,并重新面对之前的问题。
第二种是保守方式:只使用所知的被广泛支持的那些功能。这种方式一般来说是最明智的,不过它需要仔细而全面的测试。不仅如此,还必须测试新版的浏览器确保对这些功能的支持没有发生编号或者被移除。
测试DOM功能
第三张方式是测试与某一功能相关的DOM对象属性或方法是否存在。下面是一个简单的例子:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Example</title> </head> <body> <p id="sentence"> <img src="imgs/apple.png" alt="apple" /> </p> <script> var images; if(document.querySelectorAll){ images = document.querySelectorAll("#sentence > img"); }else{ images = document.getElementById("sentence").getElementsByTagName("img"); } for (var i = 0; i < images.length; i++){ images[i].style.border = "thick solid black"; images[i].style.padding = "4px"; } </script> </body> </html>
此例中,脚本使用一条 if 语句来判断 document 对象是否定义了一个名为 querySelectorAll 的方法。如果这条语句的计算结果是 true,那么浏览器是支持这一功能的,我们就可以开始使用它。如果该语句的计算结果是 false,那么可以换一种方式来达到同样的目的。
谈到DOM时,经常看到的就是刚才这种建议,但它过于草率,没有指出其中的缺陷,而这些缺陷有可能很严重。
第一个缺陷在于,并不总是存在另一种方式能实现某个给定功能的效果。此例代码能顺利功能是因为测试的功能是其他函数的一种便利性加强形式,但情况并不总是如此。
第二个缺陷是只测试了该功能是否存在,而不是它的实现质量和一致性。许多功能(特别是新功能)需要多个版本的浏览器才能稳定下来并实现一致性。虽然这个问题不像以前那样严重,但也许很容易就遇到意料之外 的结果,因为依赖的浏览器功能实现方式存在差别。
第三个缺陷是必须测试每一种所依赖的功能。这么做需要耗费大量的精力,而且产生的代码充斥着无穷无尽的测试。这里并不是说它不是一种有用的测试,而是它存在缺陷,不应该取代恰当的测试。

