

go map底层实现
1、map原理
map是由key-value组成实现,主要的数据结构由:哈希查找表和搜索树;
哈希查找表一般会存在“碰撞”的问题,就是对于不同的key会哈希到同一个单元中,解决这个问题有两种实现方法:链表法和开放地址法。链表法是为每一个单元创建一个链表,去存储不同的key;开放地址发,则是碰撞发生后通过某种方法,将key放到空的单元种
2、map底层实现
//map结构体是hmap,是hashmap的缩写 type hmap struct { count int //元素个数,调用len(map)时直接返回 flags uint8 //标志map当前状态,正在删除元素、添加元素..... B uint8 //单元(buckets)的对数 B=5表示能容纳32个元素 noverflow uint16 //单元(buckets)溢出数量,如果一个单元能存8个key,此时存储了9个,溢出了,就需要再增加一个单元 hash0 uint32 //哈希种子 buckets unsafe.Pointer //指向单元(buckets)数组,大小为2^B,可以为nil oldbuckets unsafe.Pointer //扩容的时候,buckets长度会是oldbuckets的两倍 nevacute uintptr //指示扩容进度,小于此buckets迁移完成 extra *mapextra //与gc相关 可选字段 } //a bucket for a Go map type bmap struct { tophash [bucketCnt]uint8 } //实际上编辑期间会动态生成一个新的结构体 type bmap struct { topbits [8]uint8 keys [8]keytype values [8]valuetype pad uintptr overflow uintptr }
bmp也就是bucket,由初始化的结构体可知,里面最多存8个key,每个key落在桶的位置有hash出来的结果的高8位决定。整体如下图
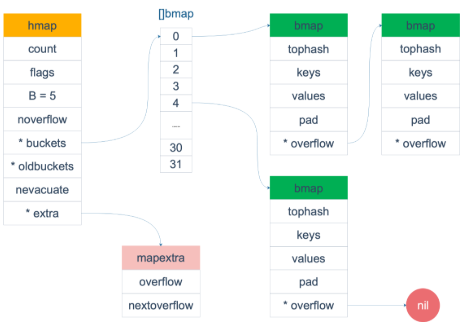
由上图可以看到,map中的key和value都不是指针,所以当size小于128字节时,会把bmap标记为不含指针,这样能够避免gc时扫描整个hmap;但是bmap中是存在一个overflow指针,用于指向下一个bmap,为了满足条件,这时候会把overflow指针到extra字段中。
type mapextra struct { // overflow[0] contains overflow buckets for hmap.buckets. // overflow[1] contains overflow buckets for hmap.oldbuckets. overflow [2]*[]*bmap // nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucket nextOverflow *bmap }
bmp的内部组成如下:

上面就是bmap的内存模型,HOB Hash指的就是tophash;这里可以看到,key value并不是以键值对的形式存放的,而是独立放在一起的,源码给出的解释是,减少pad字段,节省内存空间。
比如:map[int64] int8,如果以key-value的形式存储就必须在每个value后面添加padding7个字节,如果以上图的形式只需要在最后一个value后面添加padding就可以了
3、创建map
func makemap(t *maptype, hint int, h *hmap) *hmap { mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 } // initialize Hmap if h == nil { h = new(hmap) } h.hash0 = fastrand() //查找一个B,使得map的装载因子在一个正常的范围 B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B // 初始化hash table // if B == 0, 那么buckets会在复制后再分配 // 如果长度太大,复制会花费很长的时间 if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } } return h } // overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor. func overLoadFactor(count int, B uint8) bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) }
4、key定位
key经过哈希值计算得到哈希值,共64位(64位机器),后面5位用于计算该key放在哪一个bucket中,前8位用于确定该key在bucket中的位置;比如一个key经过计算结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
01010值是10,也就是第10个bucket;10010111值是151,在6号bucket中查找tophash值为151的key(最开始bucket还没有 key,新加入的 key 会找到第一个空位,放入)。
如果在bucket中没有找到,此时如果overflow不为空,那么就沿着overflow继续查找,如果还是没有找到,那就从别的key槽位查找,直到遍历所有bucket。key查找源码如下(mapaccess1为例):
// mapaccess1返回一个指向h[键]的指针。决不返回nil,相反,如果键不在映射中,它将返回对elem类型的zero对象的引用。 // 注意:返回的指针可能会使整个映射保持活动状态,所以不要长时间保持。 func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if raceenabled && h != nil { callerpc := getcallerpc() pc := funcPC(mapaccess1) racereadpc(unsafe.Pointer(h), callerpc, pc) raceReadObjectPC(t.key, key, callerpc, pc) } if msanenabled && h != nil { msanread(key, t.key.size) } //如果h说明都没有,返回零值 if h == nil || h.count == 0 { if t.hashMightPanic() { //如果哈希函数出错 t.key.alg.hash(key, 0) // see issue 23734 } return unsafe.Pointer(&zeroVal[0]) } //写和读冲突 if h.flags&hashWriting != 0 { throw("concurrent map read and map write") } //不同类型的key需要不同的hash算法需要在编译期间确定 alg := t.key.alg //利用hash0引入随机性,计算哈希值 hash := alg.hash(key, uintptr(h.hash0)) //比如B=5那m就是31二进制是全1, //求bucket num时,将hash与m相与, //达到bucket num由hash的低8位决定的效果, //bucketMask函数掩蔽了移位量,省略了溢出检查。 m := bucketMask(h.B) //b即bucket的地址 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) // oldbuckets 不为 nil,说明发生了扩容 if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { //新的bucket是旧的bucket两倍 m >>= 1 } //求出key在旧的bucket中的位置 oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) //如果旧的bucket还没有搬迁到新的bucket中,那就在老的bucket中寻找 if !evacuated(oldb) { b = oldb } } //计算tophash高8位 top := tophash(hash) bucketloop: //遍历所有overflow里面的bucket for ; b != nil; b = b.overflow(t) { //遍历8个bucket for i := uintptr(0); i < bucketCnt; i++ { //tophash不匹配,继续 if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } //tophash匹配,定位到key的位置 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) //若key为指针 if t.indirectkey() { //解引用 k = *((*unsafe.Pointer)(k)) } //key相等 if alg.equal(key, k) { //定位value的位置 e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { //value解引用 e = *((*unsafe.Pointer)(e)) } return e } } } //没有找到,返回0值 return unsafe.Pointer(&zeroVal[0]) }
这里说一下定位key和value的方法以及整个循环的写法:
//key定位公式 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) //value定位公式 e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
b是bmap的地址,dataOffset是key相对于bmap起始地址的偏移:
dataOffset=unsafe.Offsetof(struct{ b bmap v int64 }{}.v)
因此bucket里key的起始地址就是unsafe.Pointer(b)+dataOffset;第i个key的地址就要此基础上加i个key大小;value的地址是在key之后,所以第i个value,要加上所有的key的偏移。
遍历所有bucket如下:

再来说一下minTopHash:
// 计算tophash值 func tophash(hash uintptr) uint8 { top := uint8(hash >> (sys.PtrSize*8 - 8)) //增加一个minTopHash(默认最小值为5) if top < minTopHash { top += minTopHash } return top }
当一个cell的tophash值小于minTopHash时,标志该cell的迁移状态。因为这个状态值是放在tophash数组里,为了和正常的哈希值区分开,会给key计算出来的哈希值一个增量:minTopHash,这样就能区分正常的tophash值和表示状态的哈希值。
emptyRest = 0 //这个单元格是空的,在更高的索引或溢出处不再有非空单元格 emptyOne = 1 //单元是空的 evacuatedX = 2 // key/elem有效. 实体已经被搬迁到新的buckt的前半部分 evacuatedY = 3 //同上,实体已经被搬迁到新的buckt的后半部分 evacuatedEmpty = 4 // 单元为空,以搬迁完成 minTopHash = 5 // 正常填充单元格的最小tophash
源码中通过第一个tophash值来判断bucket是否搬迁完成:
func evacuated(b *bmap) bool { h := b.tophash[0] return h > emptyOne && h < minTopHash }
参考地址:https://github.com/qcrao/Go-Questions/blob/master/map/map%20%E7%9A%84%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86%E6%98%AF%E4%BB%80%E4%B9%88.md

