

《Spring Boot 实战派》--08.用ORM操作SQL数据库
8. 用ORM操作SQL数据库
本章首先介绍如何使用。RM (JPA. MyBatis )操作数据库;然后讲解常用的查询方式、自定 义查询方式、原生SQL (Structured Query Language,结构化查询语言)的开发和映射,
还会深 入地讲解一对一、一对多、多对多的关系映射操作以及事务的使用;最后对比分析JPA和MyBatis 的区别
8.1 认识Java的数据库连接模板JDBCTemplate
8.1.1 认识 J DBCTemplate
1. 了解 JDBC
我们先来了解一下 JDBC( Java DataBase Connectivity )。 它是Java用于连接数据库的规范,也就是用于执行数据库SQL语句的Java API。从JDBC的名 称上看,它似乎没有指定某种数据库。可以猜想它可以为多种数据库提供统一访问的接口,这更符 合程序设计的模式。实际上,它由一组用Java语言编写的类和接口组成,为大部分关系型数据库 提供访问接口。
JDBC需要每次进行数据库连接,然后处理SQL语句、传值、关闭数据库。如果都由开发人 员编写代码,则很容易出错,可能会出现使用完成之后,数据库连接忘记关闭的情况。这容易导致 连接被占用而降低性能,为了减少这种可能的错误,减少开发人员的工作量,JDBCtemplate就被 设计出来了。
2, 了解 JDBCTemplate
JDBCTemplate = JDBC+Template的组合,是对JDBC的封装。它更便于程序实现,替我们完成所有的JDBC底层工作。因此,对于数据库的操作,再不需要每次都进行连接、打开' 关闭了。
现在通过JDBCtemplate不需要进行全局修改,就可以轻松地应对开发人员常常要面对的增加、 删除、修改和查询操作。
JDBC和JDBCtemplate就像是仓库管理员,负责从仓库(数据库)中存取物品。而后者不需 要“每次进入都开门,取完关门”,因为有电动门自动控制。
下面通过具体使用JDBCTemplate的实例来理解它。
8.1.2 实例25:用JDBCTemplate实现数据的增加、删除、修改和查询
本实例演示如何通过JDBCTemplate实现数据的增加、删除、修改和查询。
1.配置基础依赖
要使用JDBCTemplate,则需要添加其Starter依赖。因为要操作数据库,所以也需要配置数 据库(以MySQL为例)的连接依赖,见以下代码:
1 2 3 4 5 6 7 8 9 10 | <!--JDBCTemplate 依赖--><dependency> <groupld>org.springframework.boot</groupld> <br> <artifactld>spring-boot-starter-jdbc</artifactld></dependency><!-- MySql数据库依赖 --><dependency> <groupld>mysql</groupld> <artifactld>mysql-connector-java</artifactld> <scope>runtime</scope></dependency> |
添加完依赖后,还需要配置数据库的连接信息。这样JDBCTemplate才能正常连接到数据库。 在application.properties配置文件中配置数据库的地址和用户信息,见以下代码:
1 2 3 4 5 6 7 | spring.datasource.driver-class-name=com.mysql.jdbc.Driver//配置IP地址、编码、时区和SSLspring.datasource.url=jdbc:mysql://127.0.0.1/book?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC&useSSL=true//用户名spring.datasource.username=root//密码spring.datasource.password=root |
2、新建实体类
新建一个测试实体类User,实现RowMapper类,重写mapRow方法,以便实体字段和数 据表字段映射(对应)映射是指把Java中设置的实体字段和MySQL数据库的字段对应起来,因 为实体的id可以对应数据库字段的u_id,也可以对应id、name等。
如果不重写,则程序不知道如何对应。具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | package com.example.demo.model;@Datapublic class User implements RowMapper<User> (<br> private int id; private String username; private String password;<br> //必须重写mapRow方法 @Override public User mapRow(ResultSet resultSet, int i) throws SQLException ( User user = new User(); user.setld(resultSet.getlnt("id")); user.setUsemame(resultSet.getString("username")); <br> user.setPassword(resultSet.getString("password")); return user; }) |
3、 操作数据
JDBCTemplate提供了以下操作数据的3个方法。
- execute:表示“执行”,用于直接执行SQL语句。
- update:表示“更新”,包括新增、修改、删除操作。
- query:表示查询。
下面使用这3个方法来实现数据的増加、删除、修改和查询功能。
(1)创建数据表。
在使用JDBCTemplate之前,需要在控制器中注入JDBCTemplate,然后就可以通过 “execute”方法执行SQL操作了,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | @SpringBootTest@RunWith(SpringRunner.class)public class UserControllerTest {<br> @Autowired private JdbcTemplate jdbcTemplate;<br><br> /* * Description:创建表 */<br> @Test public void createUserTable() throws Exception { String sql = "CREATE TABLE 'user' (\n" + "'id' int(1O) NOT NULL AUTO_lNCREMENT,\n" + "'username' varchar(IOO) DEFAULT NULL,\n" + "'password' varchar(IOO) DEFAULT NULL,\n" + "PRIMARY KEY ('id')\n" + ")ENGINE二InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;\n" + "\n"; jdbcTemplate.execute(sql); }} |
(2)添加数据。
添加数据可以通过“update”方法来执行,见以下代码:
1 2 3 4 5 6 | @Testpublic void saveUserTest() throws Exception { String sql = "INSERT INTO user (USERNAME,PASSWORD) VALUES ('longzhiran','123456')"; int rows = jdbcTemplate.update(sql); System.out.println(rows);} |
(3)查询数据。
以下代码是根据name查询单个记录,执行下面sql字符串里的SQL语句(SELECT FROM user WHERE USERNAME = ? ); 这里需要通过“query”方法来执行。
1 2 3 4 5 6 7 8 9 | @Testpublic void getUserByNameO throws Exception ( String name="longzhiran"; String sql = "SELECT * FROM user WHERE USERNAME = ?"; List<User> list = jdbcTemplate.query(sql, new User(), new ObjectQ(name}); for (User user: list) { System.out.println(user); }} |
运行测试,会在控制台中输出以下结果:
1 | User(id=4, username=longzhiran, password=123456) |
(4) 查询所有记录。
查询所有记录和查询单个记录一样,也是执行“query”方法。区别是,SQL语句使用了查询 通配符“*”,见以下代码:
1 2 3 4 5 6 7 8 | @Testpublic void list() throws Exception( String sql = "SELECT * FROM userjdbct"; List<User> userList = jdbcTemplate.query(sql,new BeanPropertyRowMapper(User.class)); for (User userLists : userList) ( System.out.println(userLists); }} |
(5) 修改数据。
要进行数据的修改,可以使用“update”方法来实现,见以下代码:
1 2 3 4 5 6 7 8 9 | 〃修改用户的密码@Testpublic void updateUserPassword() throws Exception!Integer id=1;String passWord="999888";String sql =”UPDATE userjdbct SET PASSWORD = ? WHERE ID = ?";int rows = jdbcTemplate.update(sql, password, id);System.out.println(rows);} |
(6) 删除数据。
这里删除数据并不用DELETE方法,而是通过“update”方法来执行SQL语句中的“DELETE” 方法。
1 2 3 4 5 6 7 | 〃通过用户id删除用户@Testpublic void deletellserByldO throws Exception!String sql=”DELETE FROM userjdbct WHERE ID =?";int rows = jdbcTemplate.update(sql, 1);System.out.println(rows);} |
8.1.3 认识 ORM
ORM ( Object Relation Mapping )是对象/关系映射。它提供了概念性的、易于理解的数据模 型,将数据库中的表和内存中的对象建立映射关系。它是随着面向对象的软件开发方法的发展而产 生的,面向对象的幵发方法依然是当前主流的幵发方法。
对象和关系型数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中表 现为关系型数据。内存中的对象不会被永久保存,只有关系型数据库(或NoSQL数据库,或文件) 中的对象会被永久保存。
对象/关系映射(ORM)系统一般以中间件的形式存在,因为内存中的对象之间存在关联和继 承关系,
而在数据库中,关系型数据无法直接表达多对多的关联和继承关系。对象、数据库通过ORM 映射的关系如图8-1所示。
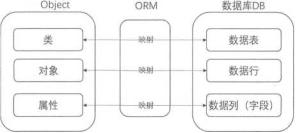
目前比较常用的ORM是国外非常流行的JPA和国内非常流行的MyBatis
8.2 JPA---Java 持久层 API
8.2.1 认识 Spring Data
Spring Data是Spring的一个子项目,旨在统一和简化各类型数据的持久化存储方式,而不拘 泥于是关系型数据库还是NoSQL数据库。
无论是哪种持久化存储方式,数据访问对象(Data Access Objects, DA。)都会提供对对象 的增加、删除、修改和查询的方法,以及排序和分页方法等。
Spring Data 提供了基于这些层面的统一接口(如:CrudRepository、PagingAndSorting- Repository),以实现持久化的存储。
Spring Data包含多个子模块,主要分为主模块和社区模块:
1、主要模块
- Spring Data Commons:提供共享的基础框架,适合各个子项目使用,支持跨数据库持 久化。
- Spring Data JDBC:提供了对 JDBC 的支持,其中封装了 JDBCTemplate。
- Spring Data JDBC Ext:提供了对JDBC的支持,并扩展了标准的JDBC,支持Oracle RAD、高级队列和高级数据类型。
- Spring Data JPA:简化创建JPA数据访问层和跨存储的持久层功能。
- Spring Data KeyValue:集成了 Redis和Riak,提供多个常用场景下的简单封装,便于构 建 key-value 模块。
- Spring Data LDAP:集成了 Spring Data repository 对 Spring LDAP 的支持。
- Spring Data MongoDB:集成了对数据库 MongoDB 支持。
- Spring Data Redis:集成了对 Redis 的支持。
- Spring Data REST:集成了对 RESTful 资源的支持。
- Spring Data for Apache Cassandra :集成了对大规模、高可用数据源 Apache Cassandra 的支持。
- Spring Data for Apace Geode:集成了对 Apache Geode 的支持。
- Spring Data for Apache Solr:集成了对 Apache Sole 的支持。
- Spring Data for Pivotal GemFire:集成了对 Pivotal GemFire 的支持。
2、社区模块
- Spring Data Aerospike:集成了对 Aerospike 的支持。
- Spring Data ArangoDB:集成了对 ArangoDB 的支持。
- Spring Data Couchbase:集成了对 Couchbase 的支持。
- Spring Data Azure Cosmos DB:集成了对 Azure Cosmos 的支持。
- Spring Data Cloud Datastore:集成了对 Google Datastore 的支持。
- Spring Data Cloud Spanner:集成了对 Google Spanner 的支持。
- Spring Data DynamoDB:集成了对 DynamoDB 的支持。
- Spring Data Elasticsearch:集成了对搜索引擎框架 Elasticsearch 的支持。
- Spring Data Hazelcast:集成了对 Hazelcast 的支持。
- Spring Data Jest:集成了对基于 Jest REST client 的日asticsea「ch 的支持。
- Spring Data Neo4j:集成了对Neo4j数据库的支持。
- Spring Data Vault:集成了对 Vault 的支持。
8.2.2 认识 JPA
JPA (Java Persistence API)是Java的持久化API,用于对象的持久化。它是一个非常强大的ORM持久化的解决方案,免去了使用JDBCTemplate幵发的编写脚本工作。
JPA通过简单 约定好接口方法的规则自动生成相应的JPQL语句,然后映射成POJO对象。
JPA是一个规范化接口,封装了 Hibemate的操作作为默认实现,让用户不通过任何配置即可 完成数据库的操作。JPA、Spring Date和Hibernate的关系如图8-2所示。
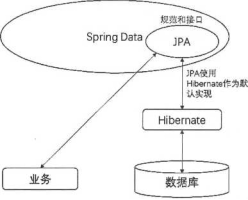
Hibernate 主要通过 hibernate-annotationx hibernate-entitymanager hibernate-core 三个组件来操作数据。
- hibernate-annotation:是Hibernate支持annotation方式配置的基础,它包括标准的JPA annotation^ Hibernate 自身特殊功能的 annotationo
- hibernate-core:是Hibemate的核心实现,提供了 Hibernate所有的核心功能。
- hibernate-entitymanager:实现了标准的 JPA,它是 hibernate-core 和 JPA 之间的适 配器,它不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符 合JPA的规范。
如果要JPA创建8.1.2节中“2.新建实体类”里的实体,可使用以下代码来实现
1 2 3 4 5 6 7 8 9 10 11 12 | @Data@Entitypublic class User { @ld //id的自增由数据库自动管理 @GeneratedValue(strategy = GenerationType. IDENTITY) private int id; private String username; private String password; } |
对比JPA与JDBCTemplate创建实体的方式可以看出:JPA的实现方式简单明了,不需要重 写映射(支持自定义映射),只需要设置好属性即可。
id的自增由数据库自动管理,也可以由程序管 理,其他的工作JPA自动处理好了。
8.2.3 使用 JPA
要使用JPA,只要加入它的Starter依赖,然后配置数据库连接信息。
1、添加 JPA 和 MySQL 数据库的依赖
下面以配置JPA和MySQL数据库的依赖为例,具体配置见以下代码:
1 2 3 4 5 6 7 8 | <dependency> <groupld>org.springframework.boot</groupld> <artifactld>spring-boot-starter-data-jpa</artifactld></dependency><dependency> <groupld>mysql</groupld> <artifactld>mysql-connector-java</artifactld> <br> <scope>runtime</scope></dependency> |
2, 配置数据库连接信息
Spring Boot项目使用MySQL等关系型数据库,需要配置连接信息,可以在 application.properties文件中进行配置。以下代码配置了与MySQL数据库的连接信息:
1 2 3 4 5 | spring.datasource.url=jdbc:mysql://127.0.0.1/book?useUnicode=true&characterEncoding=utf-8&serverTi mezone=UTC&useSSL=truespring.datasource.usemame=root <br>spring.datasource.password=rootspring.datasource.driver-class-name=com.mysql.jdbc.Driver<br>//hibernate的配置属性, 主要作用是:自动创建、更新、验证数据库表结构。该参数的几种配置见下表:spring.jpa.properties.hibernate.hbm2ddl.auto=update<br>//spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5lnnoDBDialect <br>//开发工具的控制台是否显示SQL语句, 建议打开<br>spring.jpa.show-sql= true |
| 属性 | 说明 |
| create |
每次加载Hibemate时都会删除上一次生成的表,然后根据Model类再重新生成新表,哪怕没有任何 改变也会这样执行,这会导致数据库数据的丢失 |
|
create-drop |
每次加载Hibernate时会根据Model类生成表,但是sessionFactory 一旦关闭,表就会自动被删除 |
|
update |
最常用的属性。第一次加载Hibernate时会根据Model类自动建立表的结构(前提是先建立好数据库)。 以后加载Hibernate 会根据Model类自动更新表结构,即使表结构改变了,但表中的数据仍然存在, 不会被删除。要注意的是,当部署到服务器后,表结构是不会被马上建立起来的,要等应用程序第一次运 行起来后才会建立。Update表示如果Entity实体的字段发生了变化,那么直接在数据库中逬行更新 |
|
validate |
每次加载Hibernate时,会验证数据库的表结构,只会和数据库中的表进行比较,不会创建新表,但 是会插入新值 |
8.2.4 了解JPA注解和属性
1. JPA的常用注解
JPA的常用注解见表
| 注解 | 说明 |
|
@ Entity |
声明类为实体 |
|
@Table |
声明表名,©Entity W@Table注解一般一块使用,如果表名和实体类名相同,那么©Table 可以省略 |
|
@Basic |
指定非约束明确的各个字段 |
|
©Embedded |
用于注释属性,表示该属性的类是嵌入类(@embeddable用于注释Java类的,表示类是 嵌入类) |
|
@ld |
指定的类的属性,一个表中的主键 |
|
@GeneratedValue |
指定如何标识属性可以被初始化,如@GeneratedValue(strategy=GenerationType. SEQUENCE, generator= urepair_seqn ):表示主键生成策略是sequence,还有 Auto、 Identity、Native 等 |
|
©Transient |
表示该属性并非一个数据库表的字段的映射,ORM框架将忽略该属性。如果一个属性并非 数据库表的字段映射,就务必将其标示为@T「ansient,即它是不持久的,为虚拟字段 |
|
©Column |
指定持久属性,即字段名。如果字段名与列名相同,则可以省略。使用方法如: @Column(length=11,name="phone",nullable=false, columnDefinition="varchar(11) unique comment '电话号码 |
|
@SequenceGenerator |
指定在@GeneratedValue注解中指定的属性的值。它创建一个序列 |
|
@TableGenerator |
在数据库生成一张表来管理主键生成策略 |
|
@AccessType |
这种类型的注释用于设置访问类型。如果设置@AccessType (FIELD),则可以直接访问变量,并且不需要使用Getter和Setter方法,但必须为public属性。如果设置@AccessType(PROPERTY),则通过Getter和Setter方法访问Entity的变量 |
|
@UniqueConstraint |
指定的字段和用于主要或辅助表的唯一约束 |
|
@ColumnResult |
可以参考使用select子句的SQL查询中的列名 |
|
@NamedQueries |
指定命名查询的列表 |
|
@NamedQuery |
指定使用靜态名称的查询 |
|
@Basic |
指定实体属性的加载方式,如@Basic(fetch=FetchType.LAZY) |
|
@Jsonlgnore |
作用是JSON序列化时将Java Bean中的一些属性忽略掉,序列化和反序列化都受影响 |
2.映射关系的注解
映射关系的注解见表:
| 注解 | 说明 |
|
@JoinColumn |
指定一个实体组织或实体集合。用在“多对一”和“一对多”的关联中 |
|
@OneToOne |
定义表之间“一对一”的关系 |
|
@OneToMany |
定义表之间“一对多”的关系 |
|
@ManyToOne |
定义表之间“多对一”的关系 |
|
@ManyToMany |
定义表之间“多对多”的关系 |
3.映射关系的属性
映射关系的属性见表
| 属性名 | 说明 |
|
targetEntity |
表示默认关联的实体类型,默认为当前标注的实体类 |
|
cascade |
表示与此实体一对一关联的实体的级联样式类型,以及当对实体进行操作时的策略。 在定义关系时经常会涉及是否定义Cascade (级联处理)属性,如果担心级联处理容易造 成负面影响,则可以不定义。它的类型包括CascadeType.PERSIST (级联新建)、 CascadeType.REMOVE (级联删除)、 CascadeType.REFRESH (级联刷新)、 CascadeType.MERGE(级联更新)、 CascadeType.ALL (级联新建、更新、删除、刷新) |
|
fetch |
该实体的加载方式,包含LAZY和EAGER |
|
optional |
表示关联的实体是否能够存在null值。默认为true,表示可以存在null值。如果为false, 则要同时配合使用@JoinColumn标记 |
|
mappedBy |
双向关联实体时使用,标注在不保存关系的实体中 |
|
JoinColumn |
关联指定列。该属性值可接收多个@JoinColumn0用于配置连接表中外键列的信息。 @JoinColumn配置的外键列参照当前实体对应表的主键列 |
|
JoinTable |
两张表通过中间的关联表建立联系时使用,即多对多关系 |
|
PrimaryKeyJoinColumn |
主键关联。在关联的两个实体中直接使用注解@PrimaryKeyJoinColumn注释。 |
注:
懒加载LAZY和实时加载EAGER的目的是,实现关联数据的选择性加载。
懒加载是在属性被引用时才生成查询语句,抽取相关联数据。
实时加载则是执行完主查询后,不管是否被引用,都会马上执行后续的关联数据查询。
使用懒加载来调用关联数据,必须要保证主查询的Session (数据库连接会话)的生命周期没有结束,否则是无法抽取到数据的。
在 Spring Data J PA 中,要控制 Session 的生命周期,否则会出现 “could not initialize proxy [xxxx#18]-no Session" 错误。
可以在配置文件中配置以下代码来控制Session的生命周期:
1 2 | spring.jpa.open-in-view=truespring.jpa.properties.hibernate.enable_lazy_load_no_trans=true |
8.2.5 实例26:用JPA构建实体数据表
下面通过实例来体验如何通过JPA构建对象/关系映射的实体模型。
这里以编写实体Article为例,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | package com.example.demo.entity;©Entity@Datapublic class Article implements Serializable (<br> @ld /** * Description: IDENTITY代表由数据库控制,auto代表由Spring Boot应用程序统一控制(有多个表时,id 的自增值不一定从1开始) */ @GeneratedValue(strategy = GenerationType. IDENTITY) private long id; @Column(nullable = false, unique = true) @NotEmpty(message 二"标题不能为空") private String title; /** *Description:枚举类型 7 @Column(columnDefinition=,'enum(,^7 图文、文)”) private String type;//类型 /** *Description: Boolean 类型默认 false */ private Boolean available = Boolean.FALSE; @Size(min=0, max=20) private String keyword; @Size(max = 255) private String description; @Column(nullable = false) private String body; /** * Description:创建虚拟字段 */ ©Transient private List keyword lists; public List getKeywordlists() ( return Arrays.asList(this.keyword.trim().split('T')); } public void setKeywordlists(List keywordlists) ( <br> this, keyword lists = keyword lists; }} |
如果想创建虚拟字段,则通过在属性上加注解©Transient来解决。
运行项目后会自动生成数据表
|
字段 |
类型 |
长度 |
小数点 |
允许空值 |
|
id |
bigint |
20 |
0 |
否 |
|
available |
bit |
1 |
0 |
是 |
|
body |
varchar |
255 |
0 |
否 |
|
description |
varchar |
255 |
0 |
是 |
|
keyword |
varchar |
20 |
0 |
是 |
|
title |
varchar |
255 |
0 |
否 |
|
type |
enum |
0 |
0 |
是 |
8.3认识JPA的接口
JPA提供了操作数据库的接口。在开发过程中继承和使用这些接口,可简化现有的持久化开发 工作。可以使Spring找到自定义接口,并生成代理类,后续可以把自定义接口注入Spring容器中 进行管理。
在自定义接口过程中,可以不写相关的SQL操作,由代理类自动生成。
8.3.1 JPA 接口 JpaRepository
JpaRepository 继承自 PagingAndSortingRepository。该接口提供了 JPA 的相关实用功能, 以及通过Example进行查询的功能。Example对象是JPA提供用来构造查询条件的对象。该接口 的关键代码如下:
1 | public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> (} |
在上述代码中,T表示实体对象,ID表示主键。ID必须实现序列化。
JpaRepository提供的方法见表
|
方 法 |
描 述 |
|
List<T> findAll(); |
查找所有实体 |
|
List<T> findAll(Sort var1); |
排序、查找所有实体 |
|
List<T> findAIIByld(lterable<ID> var1); |
返回制定一组ID的实体 |
|
<S extends T> List<S> saveAll(lterable<S> var1); |
保存集合 |
|
void flush(); |
执行缓存与数据库同步 |
|
<S extends T> S saveAndFlush(S var1); |
强制执行持久化 |
|
void deletelnBatch(lterable<T> var1); |
删除一个实体集合 |
|
void deleteAlllnBatch(); |
删除所有实体 |
|
T getOne(ID var1); |
返回ID对应的实体。如果不存在,则返回空值 |
|
<S extends T> List<S> findAll(Example<S> var1); |
查询满足Example的所有对象 |
|
<S extends T> List<S> findAll(Example<S> var1, Sort var2); |
查询满足Example的所有对象,并且进行排序返回 |
8.3.2 分页排序接口 PagingAndSortingRepository
PagingAndSortingRepository继承自CrudRepository提供的分页和排序方法。其关键代码 如下:
1 2 3 4 | @NoRepositoryBeanpublic interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> { <br> Iterable<T> findAll(Sort var1); Page<T> findAll(Pageable var1);} |
其方法有如下两种:
1 2 | • Iterable<T>findAII(Sortsort):排序功能。它按照"sort"制定的排序返回数据。• Page<T> findAll(Pageable pageable):分页查询(含排序功能)。 |
8.3.3 数据操作接口 CrudRepository
CrudRepository接口继承自Repository接口,并新增了增加、删除、修改和查询方法。 CrudRepository提供的方法见表
|
方 法 |
说 明 |
|
<S extends T> S save(S entity) |
保存实体。当实体中包含主键时,JPA会进行更新操作 |
|
<S extends T> lterable<S> saveAll(lterable<S> entities) |
保存所有实体。实体必须不为空 |
|
Optional<T> findByld(ID id) |
根据主键id检索实体 |
|
boolean existsByld(ID id) |
根据主键id检索实体,返回是否存在。值为布尔类型 |
|
lterable<T> findAll() |
返回所有实体 |
|
lterable<T> findAIIByld(lterable<ID> ids) |
根据给定的一组id值返回一组实体 |
|
long count() |
返回实体的数量 |
|
void deleteByld(ID id) |
根据id删除数据 |
|
void delete(T entity) |
删除给定的实体 |
|
void deleteAll(lterable<? extends T> entities) |
删除实体 |
|
void deleteAll() |
删除所有实体 |
8.3.4 分页接口 Pageable 和 Page
Pageable接口用于构造翻页查询,返回Page对象。Page从。开始分页。 例如,可以通过以下代码来构建文章的翻页查询参数。
1 2 3 4 5 6 7 8 9 10 | @RequestMapping(7article")public ModelAndView articleList(@RequestParam(value = "start", defaultvalue = "0") Integer start, @RequestParam(value = "limit", defaultvalue = "10") Integer limit){ start = start < 0 ? 0 : start; Sort sort = new Sort(Sort.Direction.DESC, "id"); Pageable pageable = PageRequest.of(start, limit, sort); Page<Article> page = articleRepository.findAII(pageable);<br> ModelAndView mav = new ModelAndView("admin/article/list");<br> mav.addObject("page", page); return mav;} |
然后,再调用它的参数获取总页数、上一页、下一页和末页,见以下代码。
1 2 3 4 5 6 | <div><a th:href="@(/article(start=O)}">[首页]</a><a th:if="$(not page.isFirst())" th:href="@{/article(start=${page. number-1 })}">[上页]</a><a th:if="$(not page.isLast())" th:href="@(/article(start=$(page.number+1})}">[下页]</a><a th:href="@{/article(start=$(page.totalPages-1 }))">[末页]</a></div> |
8.3.5 排序类Sort
Sort类专门用来处理排序。最简单的排序就是先传入一个属性列,然后根据属性列的值进行排 序。默认情况下是升序排列。它还可以根据提供的多个字段属性值进行排序。
例如以下代码是通过 Sort.Order对象的List集合来创建Sort对象的:
1 2 3 4 | List<Sort.Order> orders = new ArrayList<>();orders.add(new Sort.Order(Sort.Direction.DESC, "id"));orders.add(new Sort.Order(Sort.Direction.ASC, "view"));Pageable pageable = PageRequest.of(start, limit, sort);<br>Pageable pageable = PageRequest.of(start, limit, Sort.by(orders)); |
Sort排序的方法还有下面几种:
- 直接创建Sort对象,适合对单一属性做排序。
- 通过Sort.Order对象创建Sort对象,适合对单一属性做排序。
- 通过属性的List集合创建Sort对象,适合对多个属性采取同一种排序方式的排序。
- 通过Sort.Order对象的List集合创建Sort对象,适合所有情况,比较容易设置排序方式。
- 忽略大小写排序。
- 使用JpaSort.unsafe进行排序。
- 使用聚合函数进行排序。
8.4 JPA的查询方式
8.4.1使用约定方法名
约定方法名一定要根据命名规范来写,Spring Data会根据前缀、中间连接词(Or、And、Like、NotNull等类似SQL中的关键词)、内部拼接SQL代理生成方法的实现。
约定方法名的方法见表:
|
SQL |
方法例子 |
JPQ L语句 |
|
and |
findByLastnameAndFirstname |
where x.lastname = ?1 and x.firstname = ?2 |
|
or |
findByLastnameOrFirstname |
where x.lastname = ?1 or x.firstname = ?2 |
|
= |
findByFirstname,findByFirstnamels JindByFirstnameEquals |
where x.firstname = ?1 |
|
between xxx and xxx |
findByStartDateBetween |
where x.startDate between ?1 and ?2 |
|
< |
findByAgeLessThan |
where x.age < ?1 |
|
<= |
findByAgeLessThanEqual |
where x.age <= ?1 |
|
> |
findByAgeGreaterThan |
where x.age > ?1 |
|
>= |
findByAgeGreaterThanEqual |
where x.age >= ?1 |
|
> |
findByStartDateAfter |
where x.startDate > ?1 |
|
< |
findByStartDateBefore |
where x.startDate < ?1 |
|
is null |
findByAgelsNull |
where x.age is null |
|
is not null |
findByAge(ls)NotNull |
where x.age not null |
|
like |
findByFirstnameLike |
where x.firstname like ?1 |
|
not like |
findByFirstnameNotLike |
where x.firstname not like ?1 |
|
like 'xxx%' |
findByFirstnameStartingWith |
where x.firstname like ?1 (parameter bound with appended %) |
|
like 'xxx%' |
findByFirstnameEndingWith |
where x.firstname like ?1 (parameter bound with prepended %) |
|
like '%xxx%' |
findByFirstnameContaining |
where x.firstname like ?1 (parameter bound wrapped in %) |
|
order by |
findByAgeOrderByLastnameDesc |
where x.age = ?1 order by x.lastname desc |
|
<> |
findByLastnameNot |
where x.lastname <> ?1 |
|
in() |
findByAgeln(Collection<Age> ages) |
where x.age in ?1 |
|
not in() |
findByAgeNotln(Collection<Age> ages) |
where x.age not in ?1 |
|
TRUE |
findByActiveTrue() |
where x.active = true |
|
FALSE |
findByActiveFalse() |
where x.active 二 false |
接口方法的命名规则也很简单,只要明白And、Or、Is、Equal、Greater、StartingWith等 英文单词的含义,就可以写接口方法。具体用法如下:
1 2 3 | public interface UserRepository extends Repository<User, Long> { List<User> findByEmailOrName(String email, String name);} |
上述代码表示,通过email或name来查找User对象。
约定方法名还可以支持以下几种语法:
- User findFirstByOrderByNameAsc()
- Page<User> queryFirst100ByName(String name, Pageable pageable)
- Slice<User> findTop100ByName(String name, Pageable pageable)
- List<User> findFirst100ByName(String name, Sort sort)
- List<User> findTop100ByName(String name, Pageable pageable)
8.4.2 用JPQL进行查询
JPQL语言(Java Persistence Query Language)是一种和SQL非常类似的中间性和对象 化查询语言,它最终会被编译成针对不同底层数据库的SQL语言,从而屏蔽不同数据库的差异。
JPQL语言通过Query接口封装执行,Query接口封装了执行数据库查询的相关方法。调用 EntityManager的Query、NamedQuery及NativeQuery方法可以获得查询对象,进而可调用 Query接口的相关方法来执行查询操作。
JPQL是面向对象进行查询的语言,可以通过自定义的JPQL完成UPDATE和DELETE操 作。JPQL不支持使用INSERTo对于UPDATE或DELETE操作,必须使用注解@Modifying 进行修饰。
JPQL的用法见以下两段代码。
(1 )下面代码表示根据name值进行查找。
1 2 3 4 | public interface UserRepository extends JpaRepository<User, Long> ( @Query("select u from User u where u.name = ?1") User findByName(String name);} |
(2)下面代码表示根据name值进行模糊查找。
1 | public interface UserRepository extends JpaRepository<User, Long> { <br> @Query("select u from User u where u.name like %?1") <br> List<User> findByName(String name);<br>} |
8.4.3用原生SQL进行查询
在使用原生SQL查询时,也使用注解@Query此时,nativeQuery参数需要设置为true。 下面先看一些简单的查询代码。
1、根据ID查询用户
1 2 3 4 5 | public interface UserRepository extends JpaRepository<User, Long> (〃根据ID查询用户@Query(value = "select * from user u where u.id=:id", nativeQuery = true)User findByld (@Param("id")Long id);) |
2、查询所有用户
1 2 3 4 5 | public interface UserRepository extends JpaRepository<User, Long> {〃查询所有用户@Query(value = "select * from user", nativeQuery = true)List<User> findAIINative();} |
3、根据email查询用户
1 2 3 4 | public interface UserRepository extends JpaRepository<User, Long> (〃根据email查询用户@Query(value = " select * from user where email= ?1", nativeQuery 二 true) User findByEmail(String email);) |
4、根据name查询用户,并返回分页对象Page
1 2 3 4 5 | public interface UserRepository extends JpaRepository<User, Long> (@Query(value = " select * from user where name= ?1",countQuery = " select count(*) from user where name= ?1", nativeQuery = true)Page<User> findByName(String name, Pageable pageable);} |
5、根据名字来修改email的值
1 | @Modifying @Query("update user set email = :email where name =:name") <br>Void updateUserEmailByName(@Param("name")String name,@Param("email")String email); |
6、使用事务
UPDATE或DELETE操作需要使用事务。此时需要先定义Service层,然后在Service层的方法上添加事务操作。
对于自定义的方法,如果需要改变Spring Data提供的事务默认方式,则 可以在方法上使用注解 @Transactional, 如以下代码:
1 2 3 4 5 6 7 8 9 | @Servicepublic classUserService {<br> @Autowired private UserRepository userRepository;<br> @Transactional public void updateEmailByName(String name,String email)( userRepository.updateUseEmaiByName(name, email); }) |
测试代码:
1 2 3 4 | @Testpublic void testUsingModifingAnnotation(){ userService.updateEmailByName("longzhonghua", "363694485@qq.com");} |
在进行多个Repository操作时,也应该使这些操作在同一个事务中。按照分层架构的思想,这些操作属于业务逻辑层,因此需要在Service层实现对多个Repository的调用,并在相应的方法 上声明事务。
8.4.4 用 Specifications 进行查询
如果要使 Repository 支持 Specification 查询,则需要在 Repository 中继承 JpaSpecificationExecutor接口,具体使用见如下代码:
1 2 | public interface CardRepository extends JpaRepository<Card,Long> , JpaSpecificationExecutor<Card> {<br> Card findByld(long id);} |
下面以一个例子来说明Specifications的具体用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | @SpringBootTest@RunWith(SpringRunner.class)public class testJpaSpecificationExecutor (<br> @Autowired private CardRepository CardRepository;<br><br> @Test public void testJpaSpecificationExecutor() ( int pageNo = 0; int pageSize = 5; PageRequest pageable = PageRequest.of(pageNo, pageSize); //通常使用Specification的匿名内部类 Specification<Card> specification = new Specification<Card>() {<br> @Override public Predicate toPredicate(Root<Card> root,CriteriaQuery<?> query, CriteriaBuilder cb) {<br> Path path = root.get("id"); //gt是大于的意思。这里代表id大于2 Predicate predicatel = cb.gt(path, 2); //equal是等于的意思,代表查询num值为422803的数据记录 Predicate predicate? = cb.equal(root.get("num"), 422803); //构建组合的Predicate Predicate predicate = cb.and(predicate1 ,predicate2); <br> return predicate; } };<br> Page<Card> page = cardRepository.findAII(specification, pageable); System.out.println("S记录数:"+ page.getTotalElements()); System.out.println(”当前第:"+ (page.getNumber() + 1) +"页, System.out.println(',1& 页数:" + page.getTotalPages()); System.out.println("当前页面的 List:" + page.getContent()); <br> System.out.println("当前页面的记录数:"+ page.getNumberOfElements()); }) |
代码解释如下:
- CriteriaQuery接口:specific的顶层查询对象,它包含查询的各个部分,比如,select、from、 where、group by、order by等。CriteriaQuery对象只对实体类型或嵌入式类型的Criteria 查询起作用。
- root:代表查询的实体类是Criteria查询的根对象。Criteria查询的根定义了实体类型,能 为将来的导航获得想要的结果。它与SQL查询中的From子句类似。Root实例是类型化的, 且规定了 From子句中能够出现的类型。
查询根实例通过传入一个实体类型给 AbstractQuery.from 方法获得。
- query:可以从中得到Root对象,即告知JPA Criteria查询要查询哪一个实体类。还可 以添加查询条件,并结合EntityManager对象得到最终查询的TypedQuery对象。
- CriteriaBuilder对象:用于创建Criteria相关对象的工厂,可以从中获取到Predicate 对象。
- Predicate类型:代表一个查询条件。
运行上面的测试代码,在控制台会输出如下结果(确保数据库已经存在数据):
1 2 3 4 | Hibernate: select card0_.id as id1_0_, card0_.num as num2_0_ from card cardO_ where card0_.id>2 and card0_.num=422803 limit ?Hibernate: select count(cardO_.id) as col_0_0_ from card card0_ where card0_.id>2 and card0_.num=422803总记录数:6当前第:1页 总页数:2 当前页面的 List: [Card(id=4, num=422803), Card(id=8, num=422803), Card(id=10, num=422803), Card(id=20, num=422803), Card(id=23, num=422803)] 当前页面的记录数:5 |
8.4.5 用 ExampleMatcher 进行查询
Spring Data可以通过Example对象来构造JPQL查询,具体用法见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 | User user•二 new User();//构建查询条件user.setName("zhonghua");ExampleMatcher matcher = ExampleMatcher.matchingO〃创建一个ExampleMatcher,不区分大小写匹配name.withlgnorePaths("name")〃包括null值.withlncludeNullValuesO//执行后缀匹配.withStringMatcherEndingO;〃通过Example构建查询Example< User > example = Example.of(user, matcher);List<User> list userRepository.findALL(example); |
默认情况下,ExampleMatcher会匹配所有字段。
可以指定单个属性的行为(如name或内嵌属性“name.use"')。如:
- withMatcher("name", endsWith())
- withMatcher("name", startsWith().ignoreCase())
8.4.6用谓语QueryDSL进行查询
QueryDSL也是基于各种ORM之上的一个通用查询框架,它与SpringData JPA是同级别的。 使用QueryDSL的API可以写出SQL语句(Java代码,非真正标准SQL ),不需要懂SQL语句。
它能够构建类型安全的查询。这与JPA使用原生查询时有很大的不同,可以不必再对“Object/ 进行操作。它还可以和JPA联合使用。
8.4.7用NamedQuery进行查询
官方不推荐使用NamedQuery,因为它的代码必须写在实体类上面,这样不够独立。其使用方 法见以下代码:
1 2 | ©Entity @NamedQuery(name = "User.findByName", query = "select u from User u where u.name = ?1") <br>public class User {) |
8.5 实例27:用JPA开发文章管理模块
下面以开发文章管理模块的实例来讲解JPA的用法。
8.5.1实现文章实体
新建Spring Boot项目,然后在项目的业务代码入口下(入口类同级目录下)新建entity、 repositoryx servicex controller文件夹,并在service文件夹中新建impl文件夹。
用鼠标右键单击entity文件夹,在弹岀的下拉菜单中选择“new->java class”命令,在弹出 的窗口中输入“Article”,然后在Article类中输入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 | package com.example.demo.entity;©Entity@Datapublic class Article extends BaseEntity implements Serializable { <br> @ld @GeneratedValue(strategy = GenerationType. IDENTITY) <br> private long id;<br> @Column(nullable = false, unique = true) @NotEmpty(message ="标题不能为空") private String title;<br> @Column(nullable = false) private String body;) |
代码解释如下。
• ©Entity:声明它是个实体,然后加入了注解@Data, @Data是Lombok插件提供的注解, 以简化代码,自动生成GetterSetter方法。文章的属性字段一般包含id、title、keyword、
body,以及发布时间、更新时间、处理人。这里只简化设置文章id、关键词、标题和内容。
- @GeneratedValue:将 id 作为主键。GenerationType 为“identity”,代表由数据库统 —控制id的自增。如果属性为“auto",则是Spring Boot控制id的自增。使用identity 的好处是,通过数据库来管理表的主键的自增,不会影响到其他表。
- nullable = false, unique = true:建立唯一索引,避免重复。
- @NotEmpty(message ="标题不能为空'):作为提示和验证消息。
8.5.2实现数据持久层
鼠标右键单击repository文件夹,然后新建接口。在Kind类型处选择接口 interface,将名字 设为ArticleRepository0完成后的代码如下:
1 2 3 4 5 | package com.example.demo.repository;public interface ArticleRepository extends JpaRepository<Article,Long> , JpaSpecificationExecutor<Article> { Article findByld(long id);} |
这里继承JpaRepository来实现对数据库的接口操作。
8.5.3实现服务接口和服务接口的实现类
通过创建服务接口和服务接口的实现类来完成业务逻辑功能。
(1) 创建服务接口,见以下代码:
1 2 3 4 5 6 | package com.example.demo.service;public interface ArticleService (<br> public List<Article> getArticleList(); public Article findArticleByld(long id);} |
这里定义List (列表)方法,并根据id查找对象的方法。
(1) 编写服务接口的实现。
在impl包下,新建article的impl实现service,并标注这个类为service服务类。
通过implements声明使用ArticleService接口,并重写其方法,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | package com.example.demo.service.impl;/* * Description:标注为服务类 */©Servicepublic class ArticleServicelmpI implements ArticleService {<br> @Autowired private ArticleRepository articleRepository;<br> /** *Description:重写service接口的实现,实现列表功能 */ @Override public List<Article> getArticleList() { return articleRepository.findAII(); }<br><br> /** *Description:重写service接口的实现,实现根据id查询对象功能 */ @Override public Article findArticleByld(long id) { return articleRepository.findByld(id); }} |
8.5.4实现增加、删除、修改和查询的控制层API功能
接下来,实现增加、删除、修改和查询的控制层API功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | package com.example.demo.controller;©Controller@RequestMapping("article")public class AritcleController {<br> @Autowired private ArticleRepository articleRepository;<br> /* * Description:文章列表 <br> */ @RequestMapping("") public ModelAndView articlelist(@RequestParam(value ="start", defaultvalue = "0") Integer start, @RequestParam(value = "limit", defaultvalue = "5") Integer limit) {<br> start = start < 0 ? 0 : start; Sort sort = Sort.by(Sort.Direction.DESC, "id"); Pageable pageable = PageRequest.of(start, limit, sort); Page<Article> page = articleRepository.findAII(pageable); ModelAndView mav = new ModelAndView("article/list"); mav.addObject("page", page); return mav; }<br> /** * Description:根据id获取文章对象 */ @GetMapping("/(id}") public ModelAndView getArticle(@PathVariable("id") Integer id) ( <br> Article articles = articleRepository.findByld(id); ModelAndView mav = new ModelAndView("article/show"); mav.addObject("article", articles); return mav; }<br> /** * Description:新增操作视图 */ @GetMapping("/add") public String addArticle() ( return "article/add"; }<br> /** * Description:新增保存方法 */ @PostMapping("") public String saveArticle(Article model) { <br> articleRepository.save(model); return "redirect:/article/"; }<br> /** * Description:删除 */ @DeleteMapping("/{id}") public String del(@PathVariable("id") long id) ( <br> articleRepository.deleteByld(id); return "redirect:"; }<br> /** * Description:编辑视图 */ @GetMapping("/edit/{id}") public ModelAndView editArticle(@PathVariable("id") long id) { <br> Article model = articleRepository.findByld(id); <br> ModelAndView mav = new ModelAndView("article/edit"); <br> mav.addObject("article", model); return mav;<br> }<br>}<br><br> |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | /** * Description:根据id获取文章对象 */@GetMapping("/{id}")public ModelAndView getArticle(@PathVariable("id") Integer id) ( <br> Article articles = articleRepository.findByld(id); ModelAndView mav = new ModelAndView("article/show"); <br> mav.addObject("article", articles); return mav;}/** * Description:新增操作视图 */@GetMapping("/add")public String addArticle() ( return "article/add";}/** * Description:新增保存方法 */@PostMapping("")public String saveArticle(Article model) { <br> articleRepository.save(model); return "redirect:/article/";}/** * Description:删除 */@DeleteMapping("/{id}")public String del(@PathVariable("id") long id) ( <br> articleRepository.deleteByld(id); return "redirect:";}/** * Description:编辑视图 */@GetMapping("/edit/{id}")public ModelAndView editArticle(@PathVariable("id") long id) {<br> Article model = articleRepository.findByld(id); <br> ModelAndView mav = new ModelAndView("article/edit"); <br> mav.addObject("article", model); return mav;<br>}/** * Description:修改方法 */@PutMapping("/{id}")public String editArticleSave(Article model, long id) ( <br> model.setld(id); articleRepository.save(model); return "redirect:";} |
代码解释如下。
- @Autowired:即自动装配。Spring会自动将标记为@Autowired的元素装配好。这个注 解可以用到构造器、变量域、方法、注解类型上,该注解用于自动装配。
视图从Bean工厂 中获取一个Bean时, Spring会自动装配该Bean中标记为@Autowired的元素, 而无须手动完成。
- @RequestMapping(“/article") : 用户访问网页的URL。这个注解不限于GET方法。
- ModelAndView:分为Model和View。Model负责从后台处理参数。View就是视图,用 于指定视图渲染的模板。
- ModelAndView mav = new ModelAndView("article/list") : 指定视图和视图路径。
- mav.addObject("page", page):指定传递 page 参数。
8.6 实现自动填充字段
在操作实体类时,通常需要记录创建时间和更新时间。如果每个对象的新增或修改都用手工来 操作,则会显得比较烦琐。这时可以使用Spring Data JPA的注解@EnableJpaAuditing来实现 自动填充字段功能。具体步骤如下。
1、开启JPA的审计功能
通过在入口类中加上注解@EnableJpaAuditing,来开启JPA的Auditing功能。
2、创建基类
创建基类,让其他实体类去继承,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | @MappedSuperclass@EntityListeners(AuditingEntityListener.class)public abstract class BaseEntity ( /* * 创建时间 */ @CreatedDate //@DateTimeFormat(pattem 二"yyyy-MM-dd HH:mm:ss") private Long createTime;<br> /* * 最后修改时间 */ @LastModifiedDate //@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") private Long updateTime;<br> /* * 创建人 */ @Column(name = "create_by") @CreatedBy private Long createBy;<br> /* * 修改人 */ @Column(name = "lastmodified_by") @LastModifiedBy private String lastmodifiedBy;<br> 〃省略 getterx setter 方法} |
3.赋值给 CreatedBy 和 LastModifiedBy
上述代码已经自动实现了创建和更新时间赋值,但是创建人和最后修改人并没有赋值,所以需 要实现“AuditorAware”接口来返回需要插入的值。
这里通过创建一个配置类并重写"getCurrentAuditor”方法来实现,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | package com.hua.sb.config;〃省略/** * Description:给 Bean 中的 @CreatedBy @LastModifiedBy 注入操作人 */@Configurationpublic class InjectAuditor implements AuditorAware<String> {<br> /** * Description:重写 getCurrentAuditor 方法 */ ©Override public Optional<String> getCurrentAuditor() { SecurityContext securitycontext = SecurityContextHolder.getContext(); if (securitycontext == null) ( return null; } if (securityContext.getAuthentication() == null) {<br> return null; } else { String loginUserName = securityContext.getAuthentication().getName(); Optional<String> name = Optional.ofNullable(loginUserName); return name; } }} |
代码解释如下。
- @Configuration:表示此类是配置类。让Spring来加载该类配置。
- SecurityContextHolder : 用于获取 SecurityContext,其存放了 Authentication 和特定于 请求的安全信息。这里是判断用户是否登录。如果用户登录成功,则获取用户名,然后把用 户名返回给操作人。
4.使用基类
要在其他类中使用基类,通过在其他类中继承即可,用法见以下代码:
1 2 | public class Article extends BaseEntity {} |
8.7掌握关系映射开发
8.7.1认识实体间关系映射
对象关系映射(object relational mapping)是指通过将对象状态映射到数据库列,来开发和 维护对象和关系数据库之间的关系。它能够轻松处理(执行)各种数据库操作,如插入、更新、 删除等。
1、映射方向
ORM的映射方向是表与表的关联(join),可分为两种。
• 单向关系:代表一个实体可以将属性引用到另一个实体。即只能从A表向B表进行联表查询。
• 双向关系:代表每个实体都有一个关系字段(属性)引用了其他实体。
2.、ORM映射类型
- 一对一(@OneToOne):实体的每个实例与另一个实体的单个实例相关联。
- 一对多(@OneToMany): 一个实体的实例可以与另一个实体的多个实例相关联。
- 多对一(@ManyToOne): —个实体的多个实例可以与另一个实体的单个实例相关联。
- 多对多(@ManyToMany): —个实体的多个实例可能与另一个实体的多个实例有关。在 这个映射中,任何一方都可以成为所有者方。
8.7.2 实例28:实现"一对一”映射
“一对一”映射首先要确定实体间的关系,并考虑表结构,还要考虑实体关系的方向性。
若为双向关联,则在保存实体关系的实体中要配合注解@JoinColumn;在没有保存实体关系的实体中,要用mappedBy属性明确所关联的实体。
下面通过实例来介绍如何构建一对一的关系映射。
1.编写实体
(1 )新建Student实体,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 | ©Entity@Data@Table(name = "stdu")public class Student {<br> @ld @GeneratedValue(strategy = GenerationType.IDENTITY) private long id;<br> private String name;<br> @Column(columnDefinition = "enum('male','female')")<br> private String sex;<br> @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "cardjd") //关联的表为 card 表,其主键是 id private Card card; //建立集合,指定关系是"一对一",并且声明它在card类中的名称} |
(2)新建Card实体,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 | package com.example.demo.entity;©Entity@Table(name = "card")@Datapublic class Card {<br> @ld @GeneratedValue(strategy = GenerationType. IDENTITY) private long id;<br> private Integer num;) |
2. 编写 Repository 层
(1 )编写Student实体的Repository,见以下代码:
1 2 3 4 5 | package com.example.demo.repository;<br>public interface StudentRepository extends JpaRepository<Student, Long> ( Student findByld(long id); Student deleteByld(long id);} |
(2)编写Card实体的Repository,见以下代码:
1 2 3 4 5 | package com.example.demo.repository;public interface CardRepository extends JpaRepository<Card,Long> { Card findByld(long id);) |
3. 编写Service层
(1 )编写Student的Service层,见以下代码:
1 2 3 4 5 6 | package com.example.demo.service;public interface StudentService (<br> public List<Student> getStudentlist(); public Student findStudentByld(long id);} |
(2)编写Card的Service层,见以下代码:
1 2 3 4 5 | package com.example.demo.service;<br>public interface CardService { public List<Card> getCardList(); public Card findCardByld(long id);) |
4. 编写Service实现
(1 )编写Student实体的Service实现,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.example.demo.service.impl;public class StudentServicelmpI implements StudentService {<br> @Autowired private StudentRepository studentRepository;<br> ©Override public List<Student> getStudentlist() ( return studentRepository.findAII(); } <br> ©Override public Student findStudentByld(long id) ( return studentRepository.findByld(id); }} |
(2)编写CaRd实体的Service实现,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.example.demo.service.impl;public class CardServicelmpI implements CardService (<br> @Autowired private CardRepository cardRepository; <br><br> ©Override public List<Card> getCardList() ( return cardRepository.findAII(); )<br> ©Override public Card findCardByld(long id) ( return cardRepository.findByld(id); }} |
5. 编写测试
完成了上面的工作后,就可以测试它们的关联关系了,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | @SpringBootTest@RunWith(SpringRunner.class)public class oneToOneTest {<br> @Autowired private StudentRepository StudentRepository;<br> @Autowired private CardRepository CardRepository;<br> @Test public void testOneToOne() {<br> Student studentl = new Student(); studentl .setName("赵大伟, studentl .setSex("male"); <br> Student student2 = new StudentO; student2.setName("Jx 大宝”); student2.setSex("male"); <br> Card cardl = new Card(); cardl .setNum(422802); student1.setCard(card1); studentRepository.save(student1); <br> studentRepository.save(student2);<br> Card card2 = new Card(); card2.setNum(422803); cardRepository.save(card2);<br> /** * Description:获取添加之后的id */ Long id = student1.getld(); /** * Description:删除刚刚添加的studentl */ studentRepository.deleteByld(id); } ) |
运行代码,在控制台输出如下测试结果:
1 2 3 4 5 6 7 8 | Hibernate: insert into card (num) values (?)Hibernate: insert into stdu (cardjd, name, sex) values (?, ?, ?)Hibernate: insert into stdu (cardjd, name, sex) values (?, ?, ?)Hibernate: insert into card (num) values (?)Hibernate: select studentO_.id as id1_1_0_, studentO_.card_id as card_id4_1_0_, studentO_.name as name2_1_0_, studentO_.sex as sex3_1_0_, card 1_.id as card1_.num as num2_0_1_from stdustudentO_ left outer join card card1_ on student0_.card_id=card1_.id where studentO_.id=?Hibernate: delete from stdu where id=?Hibernate: delete from card where id=? |
可以看到,同时在两个表stdu和card中添加了内容,然后删除了刚添加的有关联的stdu和 card表中的值。如果没有关联,则不删除;
对于双向的“一对一”关系映射,发出端和接收端都要使用注解@OneToOne, 同时 定义一个接收端类型的字段属性和@OneToOne注解中的"mappedBy”属性。
这个在双向 关系的接收端是必需的。在双向关系中,有一方为关系的发出端,另一方是关系的反端,即 “Inverse” 端 (接收端);
8.7.3 实例29:实现“一对多”映射
单向关系的一对多注解@oneToMany,只用于关系的发出端(“一”的一方)。另外,需要关 系的发出端定义一个集合类型的接收端的字段属性。
在一对多关联关系映射中,默认是以中间表方式来映射这种关系的。中间表的名称为“用下画 线连接关系的拥有端(发岀端)和 Inverse端(接收端)”,
中间表两个字段分别为两张表的表名加下画线"_"再加主键组成。
当然,也可以改变这种默认的中间表的映方式。在关系的拥有端,使用@JoinClolum注解定义外键来映射这个关系。
1.编写实体
下面以学校(School)和老师(Teacher)来演示一对多的映射关系。
(1) @OneToMany 中 One 的一方 School, 见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.example.demo.entity;©Entity@Datapublic class School (<br> @ld @GeneratedValue(strategy = GenerationType.IDENTITY) private long id;<br> private String name;<br> // @OneToMany(cascade = CascadeType.ALL) @OneToMany() @JoinColumn(name = "school_id") private List<Teacher> teacherList;) |
(2) @OneToMany 中 Many 的一方--> Teacher,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 | package com.example.demo.entity;@Data©Entitypublic class Teacher {<br> @ld @GeneratedValue(strategy = GenerationType. IDENTITY) private long id;<br> private String name;<br> @ManyToOne private School school;} |
2.测试映射关系
Service和Repository层在前面已经讲过,这里并没有区别,所以不再讲解。如果不会,请参考本节提供的源代码。
下面直接测试一对多的关系映射。在测试类中,写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | @SpringBootTest@RunWith(SpringRunner.class)public class OneToManyTest {<br> @Autowired private SchoolRepository schoolRepository; @Autowired private T eacherRepository teacherRepository;<br> @Test public void add() {<br> School school 1 = new School(); schooll.setNameC 清华大学”); schoolRepository.save(school1); Teacher teacher = new Teacher(); teacher.setName("long"); teacher.setSchool(school1); <br> teacherRepository.save(teacher); }<br> @Test public void find() { School schooll = new School(); school 1 = schoolRepository.findSchoolByld(3); List<Teacher> teacherList = schooll .getTeacherListQ; System.out.println(school1.getName()); <br> for (Teacher teacher: teacherList) { System.out.println(teacher.getNameO); } } <br> @Test <br> public void deleteSchoolByld() { <br> schoolRepository.deleteByld(5);<br> }<br> @Test public void deleteTeacherByld() { <br> teacherRepository.deleteByld(5);<br> }} |
(1 )运行测试add方法,在控制台输出如下结果:
1 2 | Hibernate: insert into school (name) values (?)Hibernate: insert into teacher (name, schooljd) values (?, ?) |
运行测试find方法,在控制台输出如下结果:
1 2 3 4 5 6 7 | 2019-04-28 00:30:30.662 INFO 8484 [ main] o.h.h.i.QueryTranslatorFactorylnitiator: HHH000397: Using ASTQueryTranslatorFactoryHibernate: select school0_.id as id1_0_, school0_.name as name2_0_ from school school0_ where school0_.id=?清华大学Hibernate: select teacherlisO_.school_id as school_i3_1_0_, teacherlisO_.id as id1_1_0_, teacherlisO_.id as teacherlis0_.name as name2_1_1_, teacherlisO_.school_id as school_i3_1_1_ from teacherteacherlis0_ where teache「lis0_.school_id =?Hibernate: select school0_.id as id1_0_0_, school0_.name as name2_0_0_ from school school0_ where school0_.id=?long |
(2) 运行测试deleteSchoolByld方法,在控制台输出如下结果:
1 2 3 | Hibernate: select school0_.id as id1_0_0_, school0_.name as name2_0_0_<br> from school school0_ where school0_.id=?Hibernate: update teacher set school_id=null where school_id=?Hibernate: delete from school where id=? |
可以看到,先将所有Teacher表的外键设置为空,然后删除School表的指定值。
运行测试deleteTeacherByld方法,在控制台输岀如下结果:
1 2 | Hibernate: select teacherO_.id as id1_1_0_, teacherO_.name as name2_1_0_, teacherO_.school_id as school_i3_1_0_, school 1_.id as id1_0_1_, school1_.name as name2_0_1_ from teacher teacherO_ <br>left outer join school school 1_ <br>on teacher0_.school_id=school1_.id where teacherO_.id=?<br>Hibernate: delete from teacher where id=? |
可见是直接删除指定Teacher表的值,并没有删除School表的数据。
在双向一对多关系中,注解@OneToMany(mappedBy= '发出端实体名称小写')用于关系的发出端(即“One”的一方),同时关系的发出端需要定义一个集合类型的接收端的字段属性;
注解@ManyToOne用于关系的接收端(即“Many”的一方),关系的接收端需要定义一个发出端的字段属性。
8.7.4实例30:实现"多对多”映射
在“多对多”关联关系中,只能通过中间表的方式进行映ft,不能通过增加外键来实现。
注解@ManyToMany用于关系的发出端和接收端。关系的发出端定义一个集合类型的接收端 的字段属性,关系的接收端不需要做任何定义。
1.创建实体
(1 )创建Student实体,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.example.demo.entity;@Entity@Datapublic class Student (<br> @ld @GeneratedValue(strategy = GenerationType.IDENTITY) private long id;<br> private String name; @Column(columnDefinition ="enum('male','female')") private String sex;<br> @ManyToMany(fetch=FetchType.LAZY) JoinTable(name="teacher_student",joinColumns={@JoinColumn(name="s_id")},inverseJoinColumns=(@J oinColumn(name="tJd"))) private Set<Teacher> teachers;<br>} |
(2)创建Teacher实体,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 | package com.example.demo.entity;@Data©Entitypublic class Teacher {<br> @ld @GeneratedValue(strategy = GenerationType. IDENTITY) private long id;<br> private String name;<br> @ManyToMany(fetch=FetchType LAZY) @JoinTable(name="teacher_student,,,joinColumns={@JoinColumn(name="t_id")),inverseJoinColumns=( @JoinColumn(name="s_id")}) private Set<Student> students;) |
在“多对多”关系中需要注意以下几点:
- 关系两方都可以作为主控。
- 在 joinColumns 的@JoinColumn(name="tJd")中,t_id 为 JoinTable 中的外键。由于 Student 和 Teacher 的主键都为 id,所以这里省略了 referencedColumnName="id"0
- 在设计模型之间的级联关系时,要考虑好应该采用何种级联规则。
- 如果设置 cascade 二 CascadeType.PERSIST,则在执行 save 时会调用 onPersist()方 法。这个方法会递归调用外联类(Student或Teacher)的onPersist ()进行级联新增。
但因为值已经添加了,所以会报detached entity passed to persist错误,将级联操作取消 (去掉 “cascade = CascadeType.PERSIST”)即可。
2.创建测试
由于Service和Repository层和8.7.3节中的一样,所以这里不再重复写代码,直接进入测 试层的代码编写。如果读者不清楚怎么实现,请具体查看本节的源代码。创建以下测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | @SpringBootTest@RunWith(SpringRunner.class) <br>public class ManyToManyTest (<br> @Autowired private StudentRepository studentRepository;<br> @Autowired private TeacherRepository teacherRepository;<br> @Test public void add() { Set<Teacher> teachers = new HashSet<>(); Set<Student> students = new HashSeto();<br> Student studentl = new Student(); <br> studentl.setName("zhonghua"); <br><br> students.add(student1); <br> studentRepository.save(studentl);<br> Student student2 = new Student(); <br> student2.setName("zhiran"); <br> students.add(student2); <br> studentRepository.save(student2);<br> Teacher teacherl = new Teacher(); <br> teacher1.setName("龙老师"); <br> teacherl.setStudents(students); teachers.add(teacher1); <br> teacherRepository.save(teacherl); }} |
运行测试类,在控制器中输岀如下结果:
1 2 3 4 5 | Hibernate: insert into student (name, sex) values (?, ?)Hibernate: insert into student (name, sex) values (?, ?)Hibernate: insert into teacher (name) values (?)Hibernate: insert into teacher_student (t_id, s_id) values (?, ?)Hibernate: insert into teacher_student (t_id, sjd) values (?, ?) |
对于双向ManyToMany关系,注解@ManyToMany用于关系的发出端和接收端。另外, 关系的接收端需要设置@ManyToMany(mappedBy=,集合类型发出端实体的字段名称)。
8.8 认识MyBatis一 Java数据持久层框架
MyBatis和JPA -样,也是一款优秀的持久层框架,它支持定制化SQL、存储过程,以及高 级映射。它可以使用简单的XML或注解来配置和映射原生信息,将接口和Java的POJOs ( Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。
MyBatis 3提供的注解可以取代XML。
例如,使用注解©Select直接编写SQL完成数据查询; 使用高级注解@SelectProvider还可以编写动态SQL,以应对复杂的业务需求。
8.8.1 CRUD 注解
增加、删除、修改和查询是主要的业务操作,必须掌握这些基础注解的使用方法。MyBatis提 供的操作数据的基础注解有以下4个。
- @Select:用于构建查询语句。
- @lnsert:用于构建添加语句。
- @Update:用于构建修改语句。
- @Delete:用于构建删除语句。
下面来看看它们具体如何使用,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | @Mapperpublic interface UserMapper{<br> @Select("SELECT * FROM user WHERE id = #(id}") User queryByld(@Param("id") int id);<br> @Select("SELECT * FROM user") List<User> queryAll();<br> @Insert(("INSERT INTO user(name,age) VALUES(#{name),#{age})")) int add(User user);<br> @Delete("DELETE FROM user WHERE id = #{id}”) int delByld(int id);<br> @Update("UPDATE user SET name=#{name},age=#(age} WHERE id = #(id}") int updateByld(User user);<br> @Select(”SELECT * FROM user") Page<User> getUserList();) |
从上述代码可以看出:首先要用@Mapper注解来标注类,把UserMapper这个DAO交给 Spring管理。这样Spring会自动生成一个实现类,不用再写UserMapper的映射文件了。最后使 用基础的CRUD注解来添加要实现的功能。
8.8.2映射注解
MyBatis的映射注解用于建立实体和关系的映射。它有以下3个注解。
• @Results :用于填写结果集的多个字段的映射关系。
• ©Result :用于填写结果集的单个字段的映射关系。
• @ResultMap : 根据 ID 关联 XML 里面的<resultMap>
可以在查询SQL的基础上,指定返回的结果集的映射关系。其中,property表示实体对象的 属性名,column表示对应的数据库字段名。使用方法见以下代码:
1 2 3 4 5 6 | @Results({ @Result(property = "username", column = "USERNAME"), @Result(property = "password", column = "PASSWORD")})@Select("select * from user")List<User> list(); |
8.8.3高级注解
1、高级注解
MyBatis 3.x版本主要提供了以下4个CRUD的高级注解。
- @SelectProvider:用于构建动态查询SQL。
- @InsertProvider:用于构建动态添加SQL。
- @UpdateProvider:用于构建动态更新SQL。
- @DeleteProvider:用于构建动态删除SQL。
高级注解主要用于编写动态SQL。这里以@SelectProvider为例,它主要包含两个注解属性, 其中,type表示工具类,method表示工具类的某个方法(用于返回具体的SQL )。
以下代码可以构建动态SQL,实现查询功能:
1 2 3 4 5 | @Mapperpublic interface UserMapper {<br> @SelectProvider(type = UserSql.class, method = "listAll") List<User> listAllUser();} |
1 | UserSql 工具类的代码如下: |
1 2 3 4 | public class UserSql {<br> public String listAll() { return "select * from user; }<br>} |
2、MyBatis3注解的用法举例
(1 )如果要查询所有的值,则基础CRUD的代码是:
1 2 | @Select("SELECT * FROM user3")List<User> queryAll(); |
也可以用映射注解来一一映射,见以下代码:
1 2 3 4 5 6 7 | //使用注解编写SQL, 完成映射<br>@Select("select * from user3")@Results({ @Result(property = "id", column = "id"), @Result(property = ''name", column = "name"), @Result(property = "age", column = "age")})List<User> listAll; |
(2)用多个参数进行查询。
如果要用多个参数进行查询,则必须加上注解@Param,否则无法使用EL表达式获取参数。
UserMapper接口的写法如下:
1 2 | @Select("select * from user where name like #(name} and age like #(age}")User getByNameAndAge(@Param("name") String name, @Param("age") int age); |
对应的控制器代码如下:
1 2 3 4 | @RequestMapping("/querybynameandage")User querybynameandage(String name, int age) { return userMapper.getByNameAndAge(name,age);} |
还可以根据官方提供的API来编写动态SQL:
1 2 3 4 5 6 7 8 9 | public String getUser(@Param("name") String name, @Param("age") int age) { <br> return new SQL() {{ SELECT("*"); FROMC("user3"); if (name != null && age != 0) { WHERE("name like #(name} and age like #{age}"); } else { WHERE("1=2"); } }).toString(); |
8.9 实例31:用MyBatis实现数据的增加、删除、修改、查询和分页
本节以实现常用的数据增加、删除、修改、查询和分页功能,来体验和加深对MyBatis的知识 和使用的理解。
8.9.1创建Spring Boot项目并引入依赖
创建一个Spring Boot项目,并引入MyBatis和MySQL依赖,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <dependency> <groupld>org.springframework.boot</groupld> <artifactld>spring-boot-starter-web</artifactld></dependency><dependency> <groupld>org.mybatis.spring.boot</groupld> <artifactld>mybatis-spring-boot-starter</artifactld> <version>2.0.0</version></dependency><dependency> <groupld>mysql</groupld> <artifactld>mysql-connector-java</artifactld> <scope>runtime</scope></dependency><dependency> <groupld>org.projectlombok</groupld> <artifactld>lombok</artifactld> <optional>true</optional></dependency> |
8.9.2实现数据表的自动初始化
(1 )在项目的"resources"目录下新建db目录,并添加“schema.sql”文件,然后在此文 件中写入创建user表的SQL语句,以便进行初始化数据表。具体代码如下:
1 2 3 4 5 6 7 | DROP TABLE IF EXISTS 'user';CREATE TABLE 'user' ('id' int(11) NOT NULL AUTOJNCREMENT,'name' varchar(255) DEFAULT NULL,'age' int(11) DEFAULT NULL,PRIMARY KEY ('id'))ENGINE=lnnoDB DEFAULT CHARSET=utf8; |
(2)在application.properties配置文件中配置数据库连接,并加上数据表初始化的配置。具 体代码如下:
1 2 | spring.datasource.initialize=truespring.datasource.initialization-mode=always <br>spring.datasource.schema=classpath:db/schema.sql |
完整的 application.properties 文件如下:
1 2 3 4 5 6 7 8 | spring.datasource.url=jdbc:mysql://127.0.0.1/book?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC&useSSL=truespring.datasource.usemame=rootspring.datasource.password=rootspring.datasource.driver-class-name=com.mysql.jdbc.Driver<br>spring.jpa.properties.hibernate.hbm2ddl.auto=updatespring.jpa. properties.hibernate.dialect=org.hibernate.dialect.MySQL5lnnoDBDialect <br><br>spring.datasource.initialize=truespring.datasource.initialization-mode=alwaysspring.datasource.schema=classpath:db/schema.sql |
这样,Spring Boot在启动时就会自动创建user表。
8.9.3实现实体对象建模
用MyBatis来创建实体,见以下代码:
1 2 3 4 5 6 7 8 | package com.example.demo.model;import lombok.Data;<br>@Datapublic class User { private int id; private String name; private int age;} |
从上述代码可以看出,用MyBatis创建实体是不需要添加注解@Entity的, 因为@Entity属于JPA的专属注解。
8.9.4实现实体和数据表的映射关系
实现实体和数据表的映射关系可以在Mapper类上添加注解©Mapper,见以下代码。
建议以 后直接在入口类加@MapperScan("com.example.demo.mapper"),如果对每个 Mapper 都加注 解则很麻烦。
1 2 3 4 5 6 7 8 9 10 11 12 | package com.example.demo.mapper;@Mapperpublic interface UserMapper {<br> @Select("SELECT * FROM user WHERE id 二 #{id)") User queryByld(@Param("id") int id);<br> @Select(HSELECT * FROM user") List<User> queryAll();<br> @lnsert(("INSERT INTO user(name,age) VALUES(#(name},#(age})")) <br> int add(User user);<br> @Delete(”DELETE FROM user WHERE id = #(id}")<br> int delByld(int id);<br> @Update("UPDATE user SET name=#(name),age=#(age} WHERE id 二 #(id)") <br> int updateByld(User user);} |
8.9.5实现增加、删除、修改和查询功能
创建控制器实现操作数据的API,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | package com.example.demo.controller;@RestController@RequestMapping("/user")public class UserController (<br> @Autowired UserMapper userMapper;<br> @RequestMapping("/queryById") User queryById(int id) { return userMapper.queryByld(id); }<br> @RequestMapping("") List<User> queryAll() { return userMapper.queryAII(); }<br> @RequestMapping("/add") String add(User user) { return userMapper.add(user) == 1 ? "success": "failed"; }<br><br> @RequestMapping("/updatebyid") String updateByld(User user) { return userMapper.updateByld(user) == 1 ? "success": "failed"; }<br> @RequestMapping("/delById") String delById(int id) ( return userMapper.delByld(id) == 1 ? "success": "failed"; }} |
(1 )启动项目,访问 http://localhost:8080/user/add?name=long&age=1,会自动添加一个 name=long、age=1 的数据。
(2) 访问 http://localhost:8080/user/updatebyid?name=zhonghua&age=28&id=1,会实 现对id=1的数据的更新,更新为name=zhonghua、age=28。
(3) 访问 http://localhost:8080/user/querybyid?id=1,可以查找到 id=1 的数据,此时的数 据是 name=zhonghua、age=28。
(4) 访问http://localhost:8080/user/,可以查询出所有的数据。
访问 http://localhost:8080/user/delbyid?id=1,可以删除 id 为 1 的数据
8.9.6配置分页功能
1、增加分页支持
分页功能可以通过PageHelper来实现。要使用PageHelper,则需要添加如下依赖,并增加 Thymeleaf 支持。
1 2 3 4 5 6 7 8 9 10 | <!-- 增加对PageHelper的支持--><dependency> <groupld>com.github.pagehelper</groupld> <arti factld>pagehelper</artifactld> <version>4.1.6</version></dependency><!一增加 thymeleaf 支持--><dependency> <groupld>org.springframework.boot</groupld> <br> <artifactld>spring-boot-starter-thymeleaf</artifactld></dependency> |
1. 创建分页配置类
创建分页配置类来实现分页的配置,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 | package com.example.demo.config;@Configurationpublic class PageHelperConfig (<br> @Bean public PageHelper pageHelper(){ PageHelper pageHelper = new PageHelper();<br><br> Properties p = new Properties(); p.setProperty("offsetAsPageNum", "true"); p.setProperty("rowBoundsWithCount", "true"); <br> p.setProperty('Teasonable", "true");<br> pageHelper.setProperties(p); return pageHelper; }) |
代码解释如下。
• ©Configuration:表示PageHelperConfig这个类是用来做配置的。
• @Bean:表示启动PageHelper拦截器。
• offsetAsPageNum:当设置为 true 时,会将 RowBounds 第 1 个参数 offset 当成 pageNum (页码)使用。
• rowBoundsWithCount : 当设置为true时,使用RowBounds分页会迸行count查询。
• reasonable : 在启用合理化时,如果pageNum<1 ,则会查询第一页;如果 pageNum>pages,则会查询最后一页。
8.9.7实现分页控制器
创建分页列表控制器,用以显示分页页面,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | package com.example.demo.controller;©Controllerpublic class UserListController {<br> @Autowired UserMapper userMapper;<br> @RequestMapping("listAll") public String listCategory(Model model, @RequestParam(value="start",defaultValue="0")int start, @RequestParam(value = "size", defaultvalue = "20") int size) throws Exception { PageHelper.startPage(start, size,"id desc"); List<User> cs = userMapper.queryAll(); Pagelnfo<User> page = new PagelnfoO(cs); <br> model.addAttribute("page", page); return "list"; }) |
代码解释如下。
• start:在参数里接收当前是第几页。
• size:每页显示多少条数据。默认值分别是0和20。
• PageHelper.startPage(start,size,"id desc") : 根据 start、size 进行分页, 并且设置 id 倒排序。
• List<User>:返回当前分页的集合。
• Pagelnfo<User>:根据返回的集合创建Pagelnfo对象。
• model.addAttribute("page", page):把 page ( Pagelnfo 对象)传递给视图,以供后续显示。
8.9.8创建分页视图
接下来,创建用于视图显示的list.html,其路径为"resources/template/list.html"
在视图中,通过page.pageNum获取当前页码,通过page.pages获取总页码数,见以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 | <div th:each="u : $(page.list}"> <span scope="row" th:text-'$(u.id}">id</span> <span th:text="${u.name)">name</span></div><br><div> <a th:href="@{listAll?start=1}n>[首页]</a> <a th:href="@{/listAll(start=${page.pageNum-1})}">[上页]</a> <a th:href="@{/listAll(start=${page.pageNum+1})}">[下页]</a> <a th:href="@{/listAll(start=${page.pages})}">[末页]</a><div><br> 当前页/总页数:<a th:text="${page.pageNum}" th:href="@{/listAll(start=${page.pageNum})}"></a> /<a th:text="${page.pages}" th:href="@{/listAll(start=${page.pages})}"></a><br></div></div> |
启动项目,多次访问 "http://localhost:8080/user/add?name=long&age=11"增加数据,然 后访问"http://localhost:8080/listAll"可以查看到分页列表。
但是,上述代码有一个缺陷:显示分页处无论数据多少都会显示“上页、下页”。所以,需要通 过以下代码加入判断,如果没有上页或下页则不显示。
1 2 | <a th:if="${not page.lsFirstPage}" th:href="@{/listall(start=${page.pageNum-1})}">[上页]</a><a th:if="$(not page.lsLastPage}" th:href="@{/listall(start=$(page.pageNum+1}))">[下页]</a> |
上述代码的作用是:如果是第一页,则不显示“上页”;如果是最后一页,则不显示“下一页”。 还有一种更简单的方法 在Mapper中直接返回page对象,见以下代码:
1 | @Select("SELECT * FROM user") Page<User> getUserList(); |
然后在控制器中这样使用:
1 2 3 4 5 6 7 8 | @RestControllerpublic class UserListControllerB {<br> @Autowired UserMapper userMapper;<br> @RequestMapping("/listAllb") public Page<User> getUserList(Integer pageNum, Integer pageSize){<br> PageHelper.startPage(pageNum, pageSize); <br> Page<User> userList= userMapper.getUserList(); <br> return userList; }} |
代码解释如下。
• pageNum:页码。
• pageSize:每页显示多少记录。
8.10 比较 JPA 与 MyBatis
JPA基于Hibernate,所以JPA和MyBatis的比较实际上是Hibernate和MyBatis之间 的比较。
1、Hibernate 的优势
- DAO层开发比MyBatis简单,MyBatis需要维护SQL和结果映射。
- 对对象的维护和缓存要比MyBatis好,对增加、删除、修改和查询对象的维护更方便。
- 数据库移植性很好。MyBatis的数据库移植性不好,不同的数据库需要写不同的SQL语句。
- 有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
2、MyBatis的优势
- 可以进行更为细致的SQL优化,可以减少查询字段(大部分人这么认为,但是实际上 Hibernate-样可以实现)。
- 容易掌握。Hibemate门槛较高(大部分人都这么认为,但是笔者认为关键还是要看编写的 教材是否易读)。
3、简单总结
- MyBatis:小巧、方便、高效、简单、直接' 半自动化。
- Hibernate:强大、方便、高效、复杂、间接、全自动化。
它们各自的缺点都可以依据各自更深入的技术方案来解决。所以,笔者的建议是:
- 如果没有SQL语言的基础,则建议使用JPA。
- 如果有SQL语言基础,则建议使用MyBatis,因为国内使用MyBatis的人比使用JPA的 人多很多。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!