

浅谈HashMap
程序 = 数据结构 + 算法
谈论这个问题,需要用jdk1.7和jdk1.8对比来看,来说,不然面试官会觉得你是个low货,他本身期待你自己说的时候,对比来说。
具体从这几个方面对比来说:数据结构,原理,插入键值对的put方法的区别,扩容策略, 扩容检查顺序, 流程图。
HashMap的实现:数据结构 = 数组 + 链表
数据结构:
数组:采用一段连续的储存单元来存储数据;查询快、增删慢


链表:是一种物理存储单元上非连续的、非顺序的存储结构;查询慢、增删快

算法:哈希算法(散列),就是把任意长度值(key)通过散列算法变换成固定长度的key(地址)通过这个地址进行访问的数据结构;
它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度;
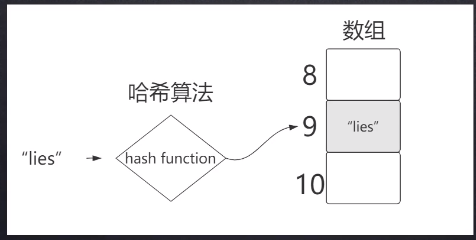

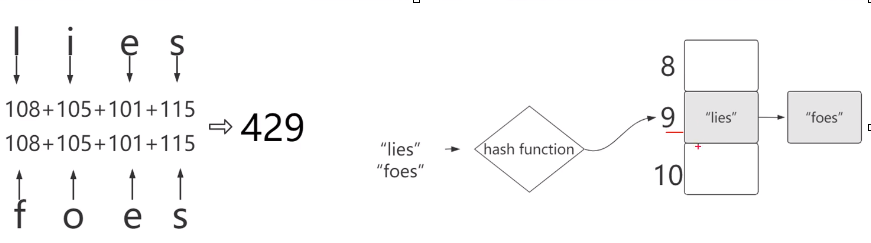
取模(mod): 节省数组的空间;
哈希碰撞(冲突): 用链表解决
一、数据结构:
1.7版本:数组+单向链表(HashMap底层就是一个数组,数组中的每一项又是一个单向链表)
1.8版本:数组+hash表+红黑树
二、底层原理 :
我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法 找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
插入键值对的put方法的区别:
1.7版本:1.7中是采用头插;
1.8版本:1.8中会将节点插入到链表尾部(因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。)
扩容策略:
1.7版本:1.7中是只要不小于阈值就直接扩容2倍;
1.8版本:1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容
扩容检查顺序:
1.7版本:是先进行扩容后进行插入的。
1.8版本:JDK1.8的时候则是先插入后进行扩容的。
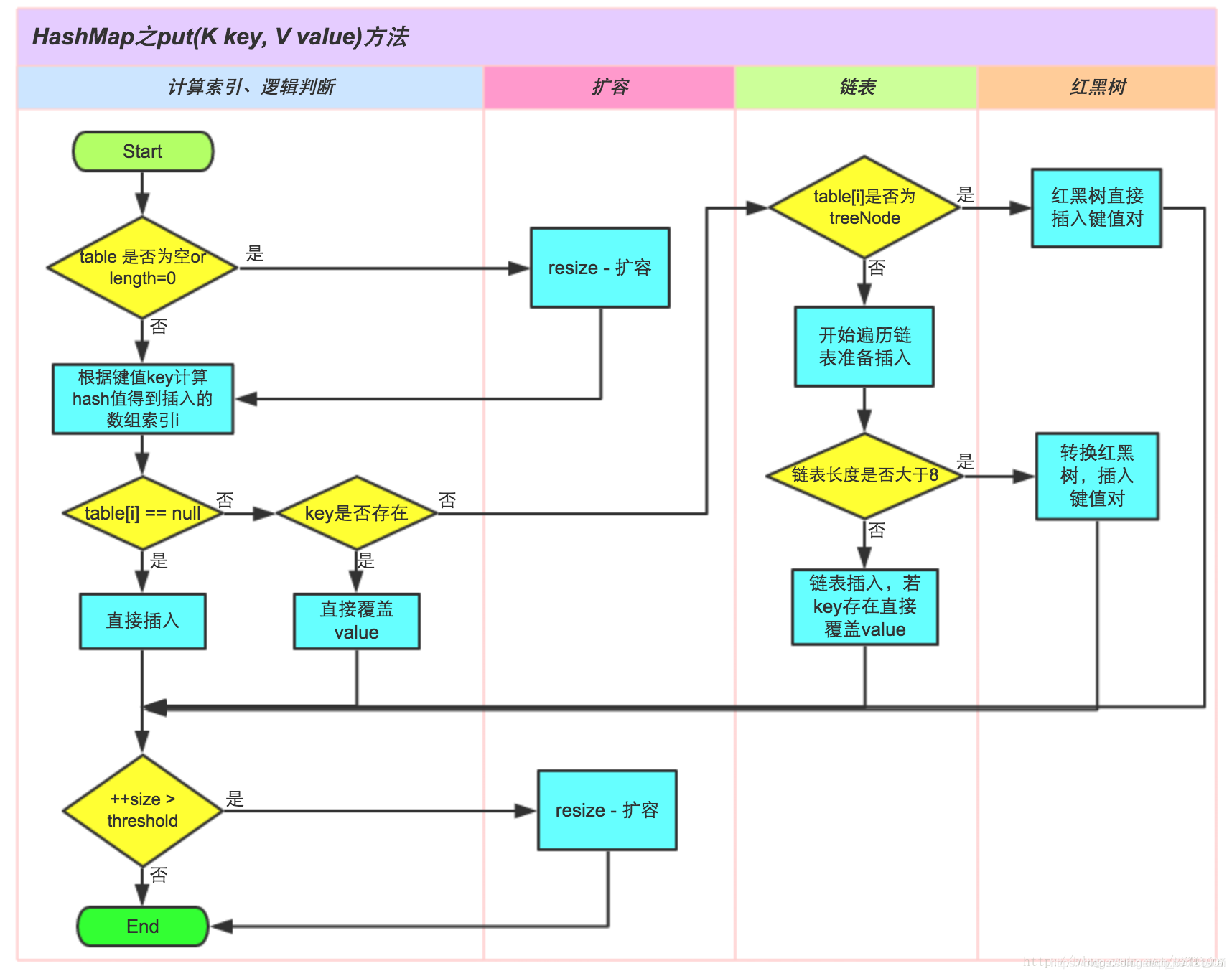
流程图(口语化能够说出流程):
1.8版本:
1.7版本:
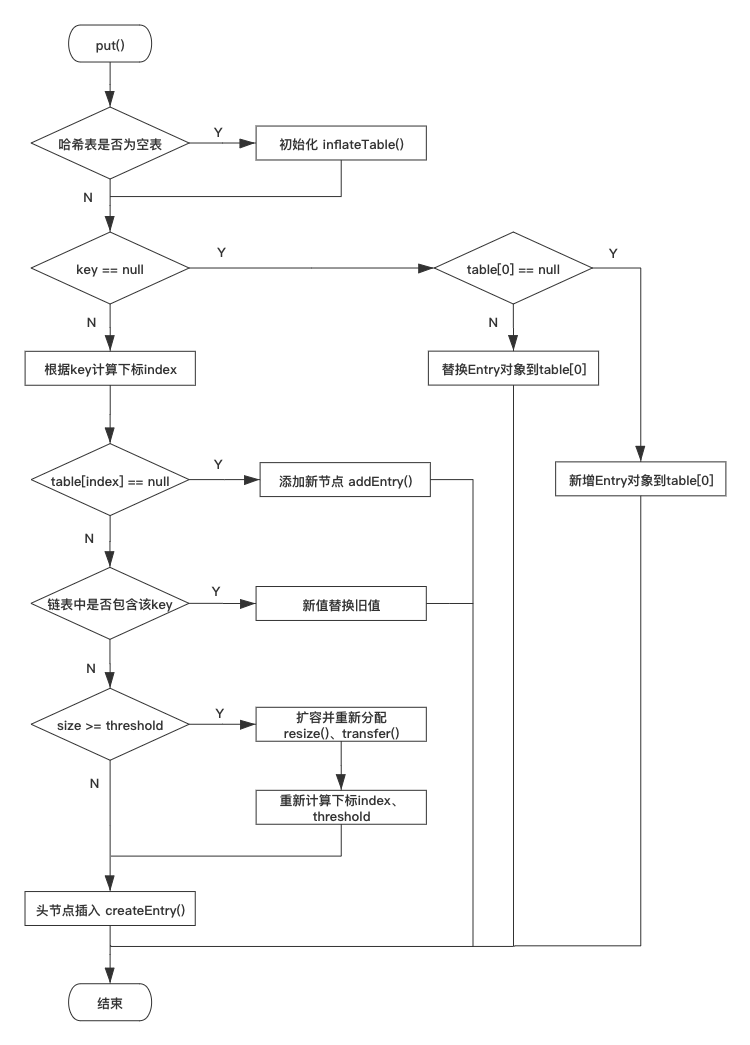
1.8版本:
