

MySql之Mycat分片路由原理
一、Mycat分片路由原理
我们先来看下面的一个SQL在Mycat里面是如何执行的:
select * from travelrecord where id in(5000001, 10000001);
有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数据在dn3上。
查询时可能有出现的问题:
1)全部扫描一遍dn1 dn2 dn3,结果导致性能浪费。
2)只扫描某个片。漏掉数据的情况。
总结:
不能多扫——>性能不足
也不能少——>漏掉数据
那么Mycat是如何解决上面的问题的呢?
Mycat使用Druid的DruidParser作为分析器/解析器,解析的过程主要有Visitor和Statement两个阶段

说明:
1)Visitor过程,解析出如下属性:
哪一张表
字段列表
条件信息
什么样的SQL
解析出以上信息以后就可以根据schema.xml和rule.xml文件确认要去哪个分片上进行DML操作了
2)Statement过程转化:转化后知道执行的是什么样的SQL(增删改查)
3)改写SQL
通过查询条件可以知道要查询的数据都在哪些分片上
Dn2, id= 5000001
Dn3, id= 100000001
所以SQL被改写成以下的形式:
select * from travelrecord where id = 5000001;(dn2执行) select * from travelrecord where id = 10000001;(dn3执行)
4)分别在分片dn2,dn3上执行第 3)步改写的SQL,然后把从dn2,dn3上得到的结果进行拼装就是最终的结果了
备注:
多表关联查询的时候,visitor会遍历出所有的表,然后去各个分片上去获取结果,同时把结果缓存起来,最后根据关联查询计算出结果。
确定分片的过程:首先看where条件里面是否含有分片字段,有就根据分片字段的值结合schema.xml、rule.xml的值确定是哪个分片。当不能确定在哪一个分片上的时候,mycat会到所有的分片上去找
二、Mycat常用分片规则
1. 时间类:按天分片、自然月分片、单月小时分片
2. 哈希类:Hash固定分片、日期范围Hash分片、截取数字Hash求模范围分片、截取数字Hash分片、一致性Hash分片
3. 取模类:取模分片、取模范围分片、范围求模分片
4. 其他类:枚举分片、范围约定分片、应用指定分片、冷热数据分片
下面基于源码来介绍Mycat的常用分片规则,源码地址
三、Mycat常用分片规则介绍
说明:分片规则都定义在rule.xml文件里面

<!--
tableRule标签:定义table分片策略
-->
<tableRule name="rule1">
<!--
rule标签:策略定义标签
-->
<rule>
<!--
columns标签:对应的分片字段
-->
<columns>id</columns>
<!--
algorithm标签:tableRule分片策略对应的function名称
-->
<algorithm>func1</algorithm>
</rule>
</tableRule>
<!-- 定义分片函数 -->
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">1,1,2,3,1</property><!-- 分片数 -->
<property name="partitionLength">128,128,128,128,128</property><!-- 分片长度 -->
</function>
1. 自动范围分片
在rule.xml里面的配置:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
说明:
有3个分片,第1个分片存储的是1-500000的数据,第2个分片存储的是500001-1000000的数据,第3个分片存储的是1000001-1500000的数据
insert into employee(id, name) value(1,Tom);在第1个分片
insert into employee(id, name) value(500002,Jack);在第2个分片
insert into employee(id, name) value(1000002,Lucy);在第3个分片
对应代码:
 View Code
View Code2. 枚举分片
把数据分类存储
在rule.xml里面的配置:
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="defaultNode">0</property> <!-- 找不到分片时设置容错规则,把数据插入到默认分片0里面 -->
</function>
说明:找不到分片时设置容错规则,把数据插入到默认分片0里面
对应代码:
View Code3. Hash固定分片(固定分片Hash算法)
固定分片Hash算法,最多有1024个分片
在rule.xml里面的配置:
<tableRule name="rule1">
<!--
rule标签:策略定义标签
-->
<rule>
<!--
columns标签:对应的分片字段
-->
<columns>id</columns>
<!--
algorithm标签:tableRule分片策略对应的function名称
-->
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">1,1,2,3,1</property><!-- 分片数 -->
<property name="partitionLength">128,128,128,128,128</property><!-- 分片长度 -->
</function>
说明:
1) partitionCount.length必须等于partitionLength.length
2) sum((partitionCount[i]*partitionLength[j])) === 1024——>partitionCount[0]*partitionLength[0]+partitionCount[1]*partitionLength[1] === 1024
即:1*128+1*128+2*128+3*128+1*128 === 1024
eg:
8个分片表
第1个分片表的下标为0: 0-127
第2个分片表的下标为1: 127-255
...................
第8个分片表的下标为7: 896-1024
如何确定落在哪个分片上呢?分片id的值与1024取余可确定在哪个分片上:
如id%1024 = 128 则落在第2个分片上
对应代码:
View Code4. 求模分片
分片字段id%分片数=分片下标
在rule.xml里面的配置:
<tableRule name="mod-long">
<rule>
<columns>id</columns><!--分片字段 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property><!--分片数 -->
</function>
对应代码:
View Code5. 自然月分片
按照自然月的方式进行分片
在rule.xml里面的配置:
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
说明:
如果月份超过了分片数,则通过设置sEndDated的值来解决
如有3个分片,分别插入2015-01-12,2015-02-12、2015-03-12、2016-11-12,月份超过了分片数,此时设置sEndDated= 2015-04-12表示4个月放一个分片,如下可知2016-11-12在分片2上
|
分片0 |
分片1 |
分片2 |
|
1月 |
5月 |
9月 |
|
2月 |
6月 |
10月 |
|
3月 |
7月 |
11月 |
|
4月 |
8月 |
12月 |
对应代码:
View Code6. 匹配求模分片
根据prefixLength截取n个字符并charAt(i)每个字符的值进行累加得到一个整数,然后和分区长度patternValue进行求模,得出的值就是分区编号。
在rule.xml里面的配置:
<tableRule name="partitionbyprefixpattern">
<rule>
<columns>id</columns>
<algorithm>partitionbyprefixpattern</algorithm>
</rule>
</tableRule>
<function name="partitionbyprefixpattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="patternValue">3</property> <!-- 分区长度/分区数量 -->
<property name="prefixLength">6</property> <!-- 截取多少字符串 -->
</function>
说明:
有下面这种类型的数据
年月+大区+流水编号
201801 01 10001
就可以采用匹配求模分片,把分片字段columns取前6个字符串201801并charAt(i)每个字符的值进行累加得到一个整数,然后和分区长度3进行求模,得出的值就是分区编号
对应代码:
View Code7. 冷热数据分片
根据日期查询日志数据冷热数据分布 ,最近 n 个月的到实时交易库查询,超过 n 个月的按照 m 天分片。
在rule.xml里面的配置:
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hotdate</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hotdate" class="org.opencloudb.route.function.PartitionByHotDate">
<property name="dateFormat">yyyy-MM-dd</property> <!-- 定义日期格式 -->
<property name="sLastDay">30</property> <!-- 热库存储多少天数据 -->
<property name="sPartionDay">30</property> <!-- 超过热库期限的数据按照多少天来分片 -->
</function>
对应代码:
View Code8. 一致性哈希分片
1)首先求出mysql服务器(节点)的哈希值,并将其配置到0~2^32的圆(continuum)上。
2)为每台mysql服务器物理节点虚拟出多个虚拟节点,并计算hash值映射到相同的圆上。
3)然后从数据映射到的mysql服务器虚拟节点的位置开始顺时针查找,将数据保存到找到的第一个mysql服务器上。如果超过232仍然找不到服务器,就会保存到第一台mysql服务器上。
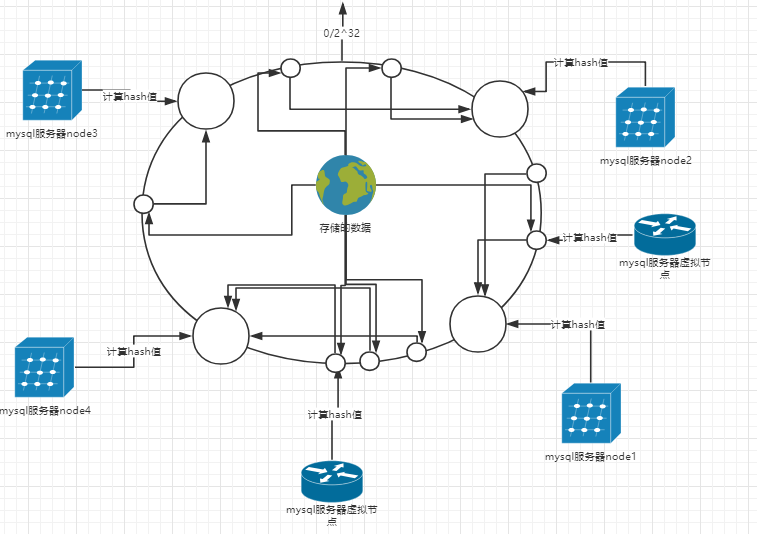
特点:解决数据均匀分布
在rule.xml里面的配置:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
对应代码:

package io.mycat.route.function; import java.io.BufferedReader; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import java.util.SortedMap; import java.util.TreeMap; import com.google.common.hash.HashFunction; import com.google.common.hash.Hashing; import io.mycat.config.model.rule.RuleAlgorithm; import io.mycat.util.exception.MurmurHashException; /** * consistancy hash, murmur hash * implemented by Guava * @author wuzhih * */ public class PartitionByMurmurHash extends AbstractPartitionAlgorithm implements RuleAlgorithm { private static final int DEFAULT_VIRTUAL_BUCKET_TIMES=160; private static final int DEFAULT_WEIGHT=1; private static final Charset DEFAULT_CHARSET=Charset.forName("UTF-8"); private int seed; private int count; private int virtualBucketTimes=DEFAULT_VIRTUAL_BUCKET_TIMES; private Map<Integer,Integer> weightMap=new HashMap<>(); // private String bucketMapPath; private HashFunction hash; private SortedMap<Integer,Integer> bucketMap; @Override public void init() { try{ bucketMap=new TreeMap<>(); // boolean serializableBucketMap=bucketMapPath!=null && bucketMapPath.length()>0; // if(serializableBucketMap){ // File bucketMapFile=new File(bucketMapPath); // if(bucketMapFile.exists() && bucketMapFile.length()>0){ // loadBucketMapFile(); // return; // } // } generateBucketMap(); // if(serializableBucketMap){ // storeBucketMap(); // } }catch(Exception e){ throw new MurmurHashException(e); } } private void generateBucketMap(){ hash=Hashing.murmur3_32(seed);//计算一致性哈希的对象 for(int i=0;i<count;i++){//构造一致性哈希环,用TreeMap表示 StringBuilder hashName=new StringBuilder("SHARD-").append(i); for(int n=0,shard=virtualBucketTimes*getWeight(i);n<shard;n++){ bucketMap.put(hash.hashUnencodedChars(hashName.append("-NODE-").append(n)).asInt(),i); } } weightMap=null; } // private void storeBucketMap() throws IOException{ // try(OutputStream store=new FileOutputStream(bucketMapPath)){ // Properties props=new Properties(); // for(Map.Entry entry:bucketMap.entrySet()){ // props.setProperty(entry.getKey().toString(), entry.getValue().toString()); // } // props.store(store,null); // } // } // private void loadBucketMapFile() throws FileNotFoundException, IOException{ // try(InputStream in=new FileInputStream(bucketMapPath)){ // Properties props=new Properties(); // props.load(in); // for(Map.Entry entry:props.entrySet()){ // bucketMap.put(Integer.parseInt(entry.getKey().toString()), Integer.parseInt(entry.getValue().toString())); // } // } // } /** * 得到桶的权重,桶就是实际存储数据的DB实例 * 从0开始的桶编号为key,权重为值,权重默认为1。 * 键值必须都是整数 * @param bucket * @return */ private int getWeight(int bucket){ Integer w=weightMap.get(bucket); if(w==null){ w=DEFAULT_WEIGHT; } return w; } /** * 创建murmur_hash对象的种子,默认0 * @param seed */ public void setSeed(int seed){ this.seed=seed; } /** * 节点的数量 * @param count */ public void setCount(int count) { this.count = count; } /** * 虚拟节点倍数,virtualBucketTimes*count就是虚拟结点数量 * @param virtualBucketTimes */ public void setVirtualBucketTimes(int virtualBucketTimes){ this.virtualBucketTimes=virtualBucketTimes; } /** * 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。 * 所有权重值必须是正整数,否则以1代替 * @param weightMapPath * @throws IOException * @throws */ public void setWeightMapFile(String weightMapPath) throws IOException{ Properties props=new Properties(); try(BufferedReader reader=new BufferedReader(new InputStreamReader(this.getClass().getClassLoader().getResourceAsStream(weightMapPath), DEFAULT_CHARSET))){ props.load(reader); for(Map.Entry entry:props.entrySet()){ int weight=Integer.parseInt(entry.getValue().toString()); weightMap.put(Integer.parseInt(entry.getKey().toString()), weight>0?weight:1); } } } // /** // * 保存一致性hash的虚拟节点文件路径。 // * 如果这个文件不存在或是空文件就按照指定的count, weightMapFile等构造新的MurmurHash数据结构并保存到这个路径的文件里。 // * 如果这个文件已存在且不是空文件就加载这个文件里的内容作为MurmurHash数据结构,此时其它参数都忽略。 // * 除第一次以外在之后增加节点时可以直接修改这个文件,不过不推荐这么做。如果节点数量变化了,推荐删除这个文件。 // * 可以不指定这个路径,不指定路径时不会保存murmur hash // * @param bucketMapPath // */ // public void setBucketMapPath(String bucketMapPath){ // this.bucketMapPath=bucketMapPath; // } @Override public Integer calculate(String columnValue) { SortedMap<Integer, Integer> tail = bucketMap.tailMap(hash.hashUnencodedChars(columnValue).asInt()); if (tail.isEmpty()) { return bucketMap.get(bucketMap.firstKey()); } return tail.get(tail.firstKey()); } @Override public int getPartitionNum() { int nPartition = this.count; return nPartition; } private static void hashTest() throws IOException{ PartitionByMurmurHash hash=new PartitionByMurmurHash(); hash.count=10;//分片数 hash.init(); int[] bucket=new int[hash.count]; Map<Integer,List<Integer>> hashed=new HashMap<>(); int total=1000_0000;//数据量 int c=0; for(int i=100_0000;i<total+100_0000;i++){//假设分片键从100万开始 c++; int h=hash.calculate(Integer.toString(i)); bucket[h]++; List<Integer> list=hashed.get(h); if(list==null){ list=new ArrayList<>(); hashed.put(h, list); } list.add(i); } System.out.println(c+" "+total); double d=0; c=0; int idx=0; System.out.println("index bucket ratio"); for(int i:bucket){ d+=i/(double)total; c+=i; System.out.println(idx+++" "+i+" "+(i/(double)total)); } System.out.println(d+" "+c); Properties props=new Properties(); for(Map.Entry entry:hash.bucketMap.entrySet()){ props.setProperty(entry.getKey().toString(), entry.getValue().toString()); } ByteArrayOutputStream out=new ByteArrayOutputStream(); props.store(out, null); props.clear(); props.load(new ByteArrayInputStream(out.toByteArray())); System.out.println(props); System.out.println("****************************************************"); // rehashTest(hashed.get(0)); } private static void rehashTest(List<Integer> partition){ PartitionByMurmurHash hash=new PartitionByMurmurHash(); hash.count=12;//分片数 hash.init(); int[] bucket=new int[hash.count]; int total=partition.size();//数据量 int c=0; for(int i:partition){//假设分片键从100万开始 c++; int h=hash.calculate(Integer.toString(i)); bucket[h]++; } System.out.println(c+" "+total); c=0; int idx=0; System.out.println("index bucket ratio"); for(int i:bucket){ c+=i; System.out.println(idx+++" "+i+" "+(i/(double)total)); } } public static void main(String[] args) throws IOException { hashTest(); } }
package io.mycat.route.function;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.SortedMap;
import java.util.TreeMap;
import com.google.common.hash.HashFunction;
import com.google.common.hash.Hashing;
import io.mycat.config.model.rule.RuleAlgorithm;
import io.mycat.util.exception.MurmurHashException;
/**
* consistancy hash, murmur hash
* implemented by Guava
* @author wuzhih
*
*/
public class PartitionByMurmurHash extends AbstractPartitionAlgorithm implements RuleAlgorithm {
private static final int DEFAULT_VIRTUAL_BUCKET_TIMES=160;
private static final int DEFAULT_WEIGHT=1;
private static final Charset DEFAULT_CHARSET=Charset.forName("UTF-8");
private int seed;
private int count;
private int virtualBucketTimes=DEFAULT_VIRTUAL_BUCKET_TIMES;
private Map<Integer,Integer> weightMap=new HashMap<>();
// private String bucketMapPath;
private HashFunction hash;
private SortedMap<Integer,Integer> bucketMap;
@Override
public void init() {
try{
bucketMap=new TreeMap<>();
// boolean serializableBucketMap=bucketMapPath!=null && bucketMapPath.length()>0;
// if(serializableBucketMap){
// File bucketMapFile=new File(bucketMapPath);
// if(bucketMapFile.exists() && bucketMapFile.length()>0){
// loadBucketMapFile();
// return;
// }
// }
generateBucketMap();
// if(serializableBucketMap){
// storeBucketMap();
// }
}catch(Exception e){
throw new MurmurHashException(e);
}
}
private void generateBucketMap(){
hash=Hashing.murmur3_32(seed);//计算一致性哈希的对象
for(int i=0;i<count;i++){//构造一致性哈希环,用TreeMap表示
StringBuilder hashName=new StringBuilder("SHARD-").append(i);
for(int n=0,shard=virtualBucketTimes*getWeight(i);n<shard;n++){
bucketMap.put(hash.hashUnencodedChars(hashName.append("-NODE-").append(n)).asInt(),i);
}
}
weightMap=null;
}
// private void storeBucketMap() throws IOException{
// try(OutputStream store=new FileOutputStream(bucketMapPath)){
// Properties props=new Properties();
// for(Map.Entry entry:bucketMap.entrySet()){
// props.setProperty(entry.getKey().toString(), entry.getValue().toString());
// }
// props.store(store,null);
// }
// }
// private void loadBucketMapFile() throws FileNotFoundException, IOException{
// try(InputStream in=new FileInputStream(bucketMapPath)){
// Properties props=new Properties();
// props.load(in);
// for(Map.Entry entry:props.entrySet()){
// bucketMap.put(Integer.parseInt(entry.getKey().toString()), Integer.parseInt(entry.getValue().toString()));
// }
// }
// }
/**
* 得到桶的权重,桶就是实际存储数据的DB实例
* 从0开始的桶编号为key,权重为值,权重默认为1。
* 键值必须都是整数
* @param bucket
* @return
*/
private int getWeight(int bucket){
Integer w=weightMap.get(bucket);
if(w==null){
w=DEFAULT_WEIGHT;
}
return w;
}
/**
* 创建murmur_hash对象的种子,默认0
* @param seed
*/
public void setSeed(int seed){
this.seed=seed;
}
/**
* 节点的数量
* @param count
*/
public void setCount(int count) {
this.count = count;
}
/**
* 虚拟节点倍数,virtualBucketTimes*count就是虚拟结点数量
* @param virtualBucketTimes
*/
public void setVirtualBucketTimes(int virtualBucketTimes){
this.virtualBucketTimes=virtualBucketTimes;
}
/**
* 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。
* 所有权重值必须是正整数,否则以1代替
* @param weightMapPath
* @throws IOException
* @throws
*/
public void setWeightMapFile(String weightMapPath) throws IOException{
Properties props=new Properties();
try(BufferedReader reader=new BufferedReader(new InputStreamReader(this.getClass().getClassLoader().getResourceAsStream(weightMapPath), DEFAULT_CHARSET))){
props.load(reader);
for(Map.Entry entry:props.entrySet()){
int weight=Integer.parseInt(entry.getValue().toString());
weightMap.put(Integer.parseInt(entry.getKey().toString()), weight>0?weight:1);
}
}
}
// /**
// * 保存一致性hash的虚拟节点文件路径。
// * 如果这个文件不存在或是空文件就按照指定的count, weightMapFile等构造新的MurmurHash数据结构并保存到这个路径的文件里。
// * 如果这个文件已存在且不是空文件就加载这个文件里的内容作为MurmurHash数据结构,此时其它参数都忽略。
// * 除第一次以外在之后增加节点时可以直接修改这个文件,不过不推荐这么做。如果节点数量变化了,推荐删除这个文件。
// * 可以不指定这个路径,不指定路径时不会保存murmur hash
// * @param bucketMapPath
// */
// public void setBucketMapPath(String bucketMapPath){
// this.bucketMapPath=bucketMapPath;
// }
@Override
public Integer calculate(String columnValue) {
SortedMap<Integer, Integer> tail = bucketMap.tailMap(hash.hashUnencodedChars(columnValue).asInt());
if (tail.isEmpty()) {
return bucketMap.get(bucketMap.firstKey());
}
return tail.get(tail.firstKey());
}
@Override
public int getPartitionNum() {
int nPartition = this.count;
return nPartition;
}
private static void hashTest() throws IOException{
PartitionByMurmurHash hash=new PartitionByMurmurHash();
hash.count=10;//分片数
hash.init();
int[] bucket=new int[hash.count];
Map<Integer,List<Integer>> hashed=new HashMap<>();
int total=1000_0000;//数据量
int c=0;
for(int i=100_0000;i<total+100_0000;i++){//假设分片键从100万开始
c++;
int h=hash.calculate(Integer.toString(i));
bucket[h]++;
List<Integer> list=hashed.get(h);
if(list==null){
list=new ArrayList<>();
hashed.put(h, list);
}
list.add(i);
}
System.out.println(c+" "+total);
double d=0;
c=0;
int idx=0;
System.out.println("index bucket ratio");
for(int i:bucket){
d+=i/(double)total;
c+=i;
System.out.println(idx+++" "+i+" "+(i/(double)total));
}
System.out.println(d+" "+c);
Properties props=new Properties();
for(Map.Entry entry:hash.bucketMap.entrySet()){
props.setProperty(entry.getKey().toString(), entry.getValue().toString());
}
ByteArrayOutputStream out=new ByteArrayOutputStream();
props.store(out, null);
props.clear();
props.load(new ByteArrayInputStream(out.toByteArray()));
System.out.println(props);
System.out.println("****************************************************");
// rehashTest(hashed.get(0));
}
private static void rehashTest(List<Integer> partition){
PartitionByMurmurHash hash=new PartitionByMurmurHash();
hash.count=12;//分片数
hash.init();
int[] bucket=new int[hash.count];
int total=partition.size();//数据量
int c=0;
for(int i:partition){//假设分片键从100万开始
c++;
int h=hash.calculate(Integer.toString(i));
bucket[h]++;
}
System.out.println(c+" "+total);
c=0;
int idx=0;
System.out.println("index bucket ratio");
for(int i:bucket){
c+=i;
System.out.println(idx+++" "+i+" "+(i/(double)total));
}
}
public static void main(String[] args) throws IOException {
hashTest();
}
}
