每个开发都应该懂的正则表达式
在日常工作中,相信每个开发都接触过一些检索、替换字符串/文本的问题。对于一些简单的问题例如查找字符串中是否存在某个子串,可能直接使用各类开发语言自带的 api 接口就可以很方便地实现。但是一旦规则复杂起来可能就会比较棘手,例如校验邮箱、手机号、版本号等,如果自行实现可能需要写不少逻辑代码,正则表达式就是为了解决这类问题的。举个例子,以下是 CI 构建组件时对版本号的校验,你能够快速读懂其规则吗?如果你对此不甚了解,那相信这篇文章一定能给你带来一些收获。

什么是正则表达式
如上图所示,正则表达式就是一串字符/^[0-9]+.[0-9].+[0-9]+$/,正则表达式规定了由一个或几个特殊的字符组合成一个规则,并且多个规则可以自由组合。
在学习正则表达式时,不要被表达式里的特殊符号所迷惑,觉得看起来好复杂,其实说白了这些字符只是一些规则的映射而已,并且需要注意的是,如果字符串里使用到这些符号还需要转义。
常见的字符有 * . ? + ^ - $ | \ / [ ] ( ) { }。另外有的开发语言在使用时需要将正则表达式使用 / 符号抱起来,形如 /xxx/,这个了解下即可。
既然正则表达式由一系列规则组成,每个规则都描述了一套匹配的逻辑,那么学习正则表达式其实就是在学习这些匹配规则。让我们先从最直观的匹配字符开始入手。在开始之前,推荐大家两个网站,一个是用于测试的 正则表达式规则测试,一个正则表达式图形化工具,便于我们理解。
匹配字符
精确匹配
例如从 abcde 里寻找 abc,那么很明显,我们的匹配规则就是需要精确匹配 abc,其规则自然就是 abc。这个不多赘述。
模糊匹配
除了精确匹配以外,我们可能还需要一些模糊的规则,以便于发现/容纳更多可能。比如我们需要某处的字符是可变的,或者我们对于某处的字符数量不确定。因此就产生了横向和纵向两种字符模糊匹配。
横向(字符次数匹配)
某处的字符数量可变,可以使用次数匹配规则。
常见的次数匹配规则有:
- {n}:限定n次
- {m,n}:上下限次数(闭区间)
- +:一次或多次,等效于
- ?:零次或一次,等效于
- *:任意多次
这些规则跟在某个字符后面,代表规则前面的字符长度可变。
例如正则表达式: a{2,3}c,代表 a 字符出现2次或3次,例如 aac、aaac 都是可以匹配的。但是 ac 是无法匹配的。
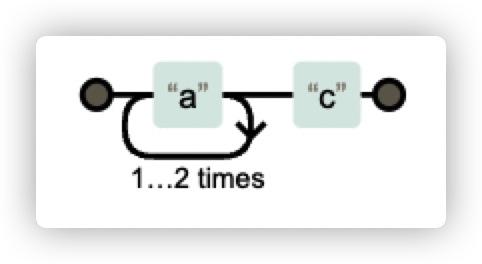
纵向
某处的字符可变,比如需要匹配 dog 和 log。第一个字符有多种可能。
常见的字符可变规则有:
- . :点代表任意字符
- | :或匹配。可以配合 () ,将多个子表达式组合
- []:区间里的字符都是允许的,例如 [123],代表该处的字符可以是 1 或 2 或 3
- -:区间里使用,表示范围,例如 [1-3] 等同于 [123],[a-z] 代表所有小写英文字母
- ^:区间里使用,表示取反,例如 [^1-3] 代表除了 1、2、3 以外的字符
这些规则放在某处,代表某处的字符是可变的。
例如 [dl]og ,代表中括号处(第一个字符)可以是 d 或 l,因此 log、dog 都是可以匹配的
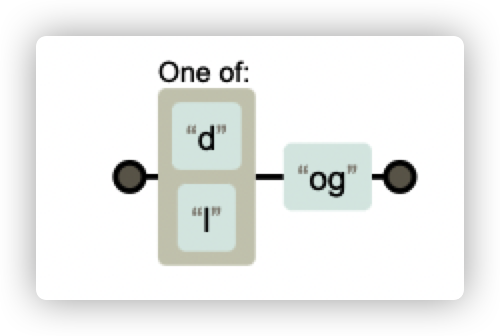
除此之外,还会有一些常用的简写:
- \d:数字
- \D:非数字
- \w:数字大小写下划线,等同于 [0-9a-zA-Z_]
- \W:非单词字符,等同于 [^0-9a-zA-Z_]
- \s:空白字符,包括空白、tab、换行
匹配位置
一个字符串,除了我们最直观看到字符以外,其实还暗含了许许多多的位置。这也是正则匹配的另一大块。什么是位置?首先用一张图来表示:
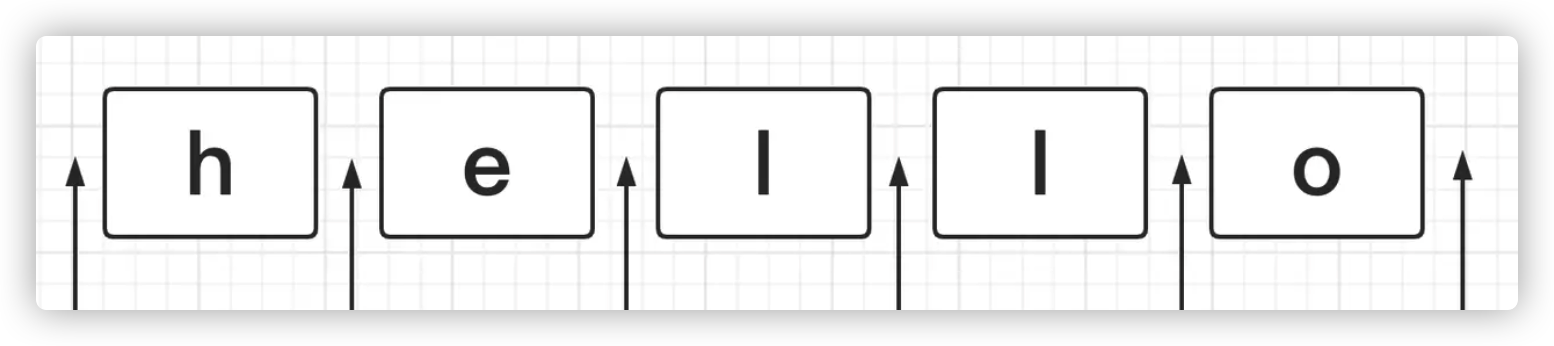
如图所示,一个字符串 hello,除了五个字符以外,每个字符首尾都有一个位置,这些位置都可以被匹配规则所扫描到。
常用的匹配位置的符号有:
- ^ :代表一行的开头
- $ :代表一行的结尾
- \b:单词边界。具体就是单词字符和非单词字符之间的位置。包括非单词字符和开头、结尾之间的位置
- \B:非单词边界
可能有人对匹配位置的用法不太了解,举个例子,有一个字符串 123123,这时候如果你使用精确匹配规则 123,那么会匹配到两个123。但是如果配合 ^ 使用,将规则修改为 ^123,那么就只会匹配到第一个开头的 123,后续的 123 则不会被匹配到。
除此之外,关于匹配位置还有一个很灵活的特性:前瞻后顾
相关的规则有:
- exp1(?=exp2):前瞻,查找后面是exp2的exp1 = 查找exp2前面的exp1(exp1、exp2 代表一个表达式)
- (?<=exp2)exp1:后顾,查找exp2后面的exp1
- exp1(?!exp2):负前瞻,查找后面不是exp2的exp1
- (?<!exp2)exp1:负后顾:查找前面不是exp2的exp1
这个在过滤日志时十分有用。例如有一些重复关键字的日志:
receive some error
receive yuv
receive yuv
receive yuv
receive yuv
//receive(?! yuv)
可以使用负前瞻过滤掉一些不想要的日志。只会匹配到 receive some error 这一行的 rece
实际应用
在对正则表达式有个大致的认识后,让我们回到文章的开头,看一下文章开头的版本号验证正则表达式代表什么含义:^[0-9]+.[0-9].+[0-9]+$

这里可以明显看出是有问题的,例如表达式里的 . 应该需要转义,否则就代表任意字符,这明显不符合版本号要求。经过确认后得知是前端显示问题,并了解到他们实际校验使用的正则表达式是:^\d+\.\d+\.(\d+\.)*\d+((-rc\.\d+)|(\d*))$
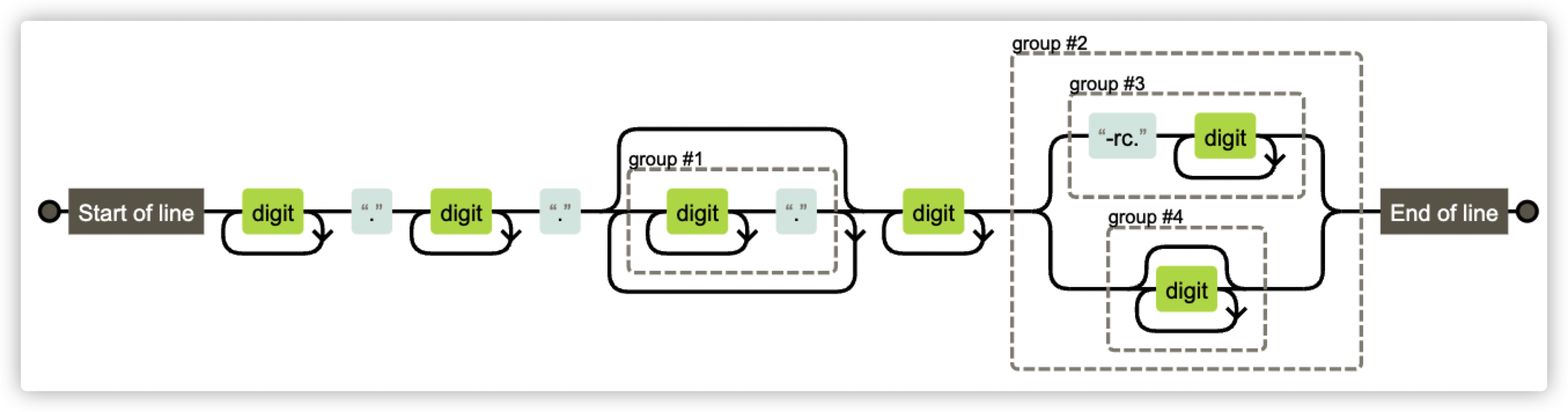
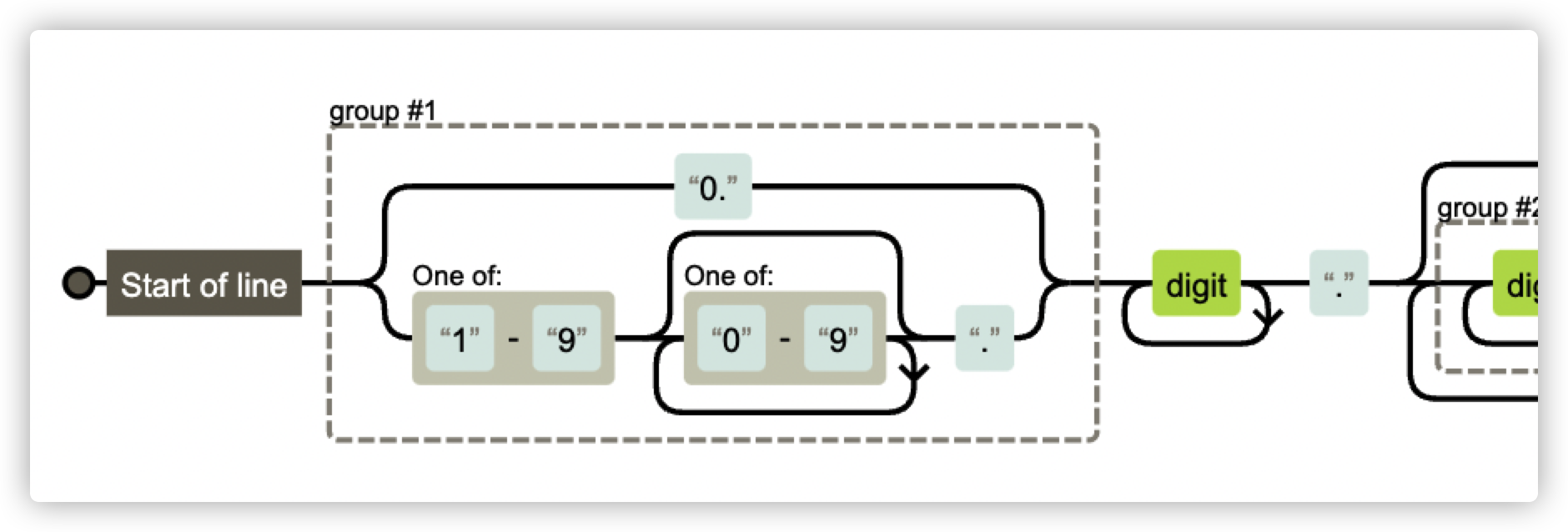
在对正则规则有个大致了解后,借助图形化工具可以很方便地了解正则表达式规则所代表的含义。
例如 1.1.1.1.1 这样的版本号也是允许的,经了解 CI 之前有特殊原因没限制版本号一定是 3 位。并且可以看到除了 rc 字符以外,不允许其他英文字母。
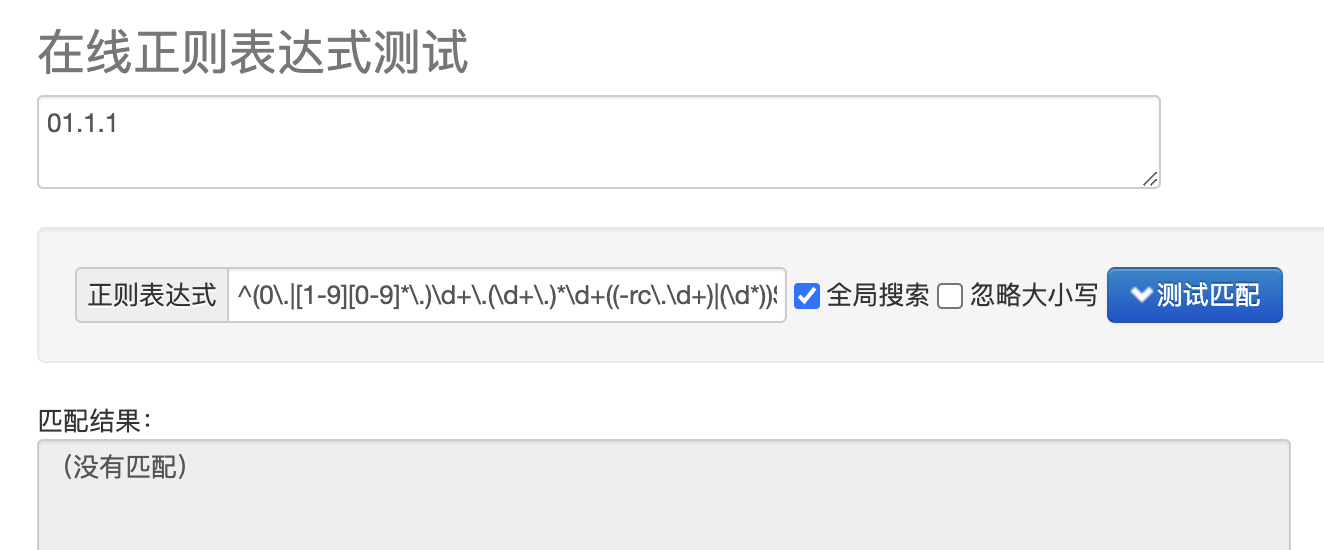
但同时我们也会发现另一个小问题,那就是类似 01.1.1 这样的版本号也是被允许的:
如果让你来优化会怎么做呢?我认为优化后的规则可以这么写:^(0\.|[1-9][0-9]*\.)\d+\.(\d+\.)*\d+((-rc\.\d+)|(\d*))$。
使用(0\.|[1-9][0-9]*\.)限制要么是0,要么是非0的两位以上数字,即可过滤 01.1.1 这样的不合理版本号。
相信看到这里,大家都对正则表达式有了一个大致的了解。对于正则表达式还有一些特性(例如捕获、贪婪等)没有提及,这里抛砖引玉,感兴趣的小伙伴可以自行了解。
有了正则表达式的帮助可以让我们少写很多字符串判断逻辑的代码,除了让代码更简洁以外,也会大大提高代码的可读性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号