
数仓(十八)数仓建模以及分层总结(ODS、DIM、DWD、DWS、DWT、ADS层)
通过前面内容分享,我们讲解了数仓建模的概念、理论、OLTP、OLAP、以及ODS、DIM、DWD、DWS、DWT、ADS层简单搭建。涉及的内容非常多,这节我们捋一捋数仓建模的步骤、以及数仓分层思路、五层每层的设计、处理、加载等总结一下。
一、建模步骤
1、关于数仓的建模有两种基本的模型:
-
关系建模(Inmon)
- 维度模型(Kimball)
两者之间的概念、关系、类型、区别等,请看数仓(三)关系建模和维度建模,我们选择的是kimball维度建模的思想,一般现在数仓的建模也都是基于维度建模来做的。可以解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能,直接面向业务,以用户理解性和查询性能为目标。
2、维度建模步骤这里我们采用的是Kimball的《数据仓库工具箱》这本书里面的维度建模4步骤:

2.1、选择业务过程整个业务流程中选取我们需要建模的业务,根据公司业务提供的需求及日后的易扩展性等进行选择业务。这里我们选择了几个业务过程是:支付、订单、加购物车、优惠券领用、收藏、评价退款等。
2.2、声明粒度总体采用最小粒度规则,不做任何聚合操作。而在实际公司应用中,对于有明确需求的数据,我们建立针对需求的上卷汇总粒度,对需求不明朗的数据我们建立原子粒度。对于支付业务,声明的粒度如下:支付业务中(事实表)中一行数据表示的是一个支付记录;对于订单业务,声明的粒度如下:订单业务(事实表)中一行数据表示的是一个订单中的一个商品项;
2.3、确认维度这里我们确认维度的原则是:(1)根据目前业务需求的相关描述性标识;(2)描述业务相关维度指标;(3)后续需求相关维度指标。确定了6个维度:时间、用户、地点、商品、优惠券、活动这6个维度。
2.4、确认事实确认业务中的度量值(如:次数、个数、件数、金额等其他可以进行累加的值),例如订单金额、下单次数等。简单理解为:我们站在事实表的角度上,分别对每个事实表进行维度关联操作,建立关联关系。
二、数仓分层
确定采用维度建模的设计模型来搭建数仓,并且也厘清了维度建模的4个经典步骤,那我们开始搭建数仓,首先遇到的问题是数仓总体规划分层问题。
Q1:为什么要分层?这个问题请看:数仓(四)数据仓库分层我们说数仓的建设并不是数据存储的最终目的地,而是为数据最终的目的地做好准备:清洗、转义、分类、重组、合并、拆分、统计等等。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制、成本、提高产品质量等。主要在以下场景中:
-
理清数据资产提高排查和开发运维效率
-
提高数据质量
-
数据解耦
-
解决频繁的临时性需求(比如监管报送)
Q2:分几层合适?不同的企业不同的业务类型服务不同的用户,没有定论说分3、4层还是5层,只有最合适的分层。当我们在选择分几层合适的时候,我们不妨看看这几家公司的数仓分层:数仓(五)简析阿里、美团、网易、恒丰银行、马蜂窝5家数仓分层架构;包含:离线数仓、准实时、实时数仓;我们这里是采用T+1离线数仓,分为五层架构。
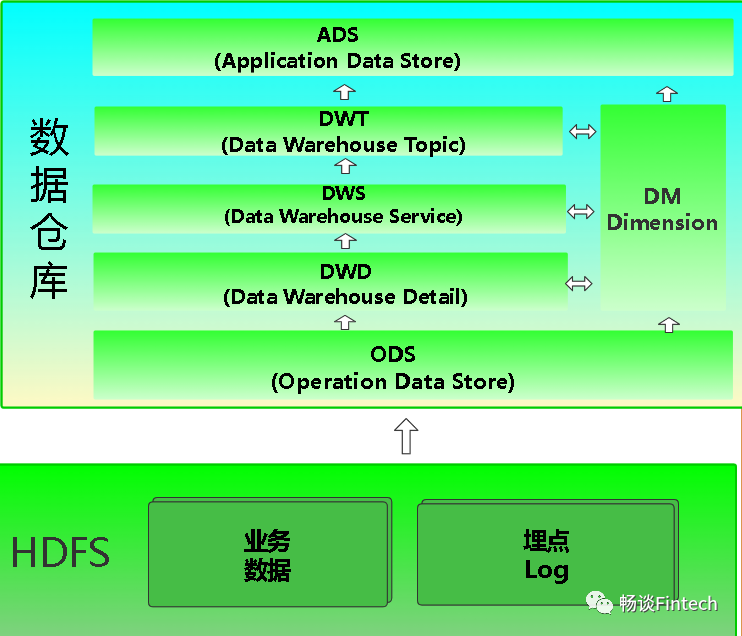
分别是ODS、DWD、DIM、DWS、DWT、以及ADS层。其中除了ADS层(数据应用层、报表应用层指标计算存储)不涉及建模以外。其他均涉及建模工作。
三、ODS层
1、ODS层设计要点
这层又叫“贴源层”,存储来自多个业务系统、前端埋点、爬虫获取等的一系列数据源的数据。我们主要做三件事:
-
保持数据原貌不做任何修改,保留历史数据,储存起到备份数据作用;
- 数据一般采用lzo、Snappy、parquet等压缩格式;
- 创建分区表,防止后续的全表扫描,减少集群资源访问数仓的压力,一般按天存储在数仓中。
2、ODS层数据组成
ODS层数据由两部分组成:
前端埋点日志信息
由Kafka或者Sqoop采集到HDFS上;
业务系统数据
由前端业务mysql数据库数据,采集到HDFS上;
3、ODS层前端埋点日志处理
分析思路:
前端埋点日志以JSON格式形式存在,又分为两部分:
(1)启动日志;(2)事件日志:

我们把前端整个埋点日志,存在hive的一张表ods_log里面,1条记录埋点日志,当一个字符串类型string来处理。
3.1、创建语句
drop table if exists ods_log;
create external table ods_log(line string)
partitioned by (dt string)
Stored as
inputformat 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
Location '/warehouse/gmail/ods/ods_log';
注意:需要添加lzo索引
具体做法是通过hadoop自带的jar包在hadoop集群命令行里面执行:
hadoop jar /opt/module/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jar
com.hadoop.compression.lzo.DistributedLzoIndexer
-Dmapreduce.job.queuename=hive
/warehouse/gmail/ods/ods_log/dt=2021-05-01
3.2、加载读取HDFS数据到hive
load data inpath '/origin_data/gmall/log/topic_log/2021-05-01'
into table ods_log partition (dt='2021-05-01');
这样就完成了ODS层前端埋点日志的处理。
4、ODS层业务数据处理
分析思路:
现在我们来处理ODS层业务数据。整体思路是:根据外部业务表逻辑结构的关系,在hive表里面根据表的每日加载同步策略来创建相对应的表。
先需要回顾一下ODS层当时建表的表结构关系。
4.1、业务表逻辑结构关系
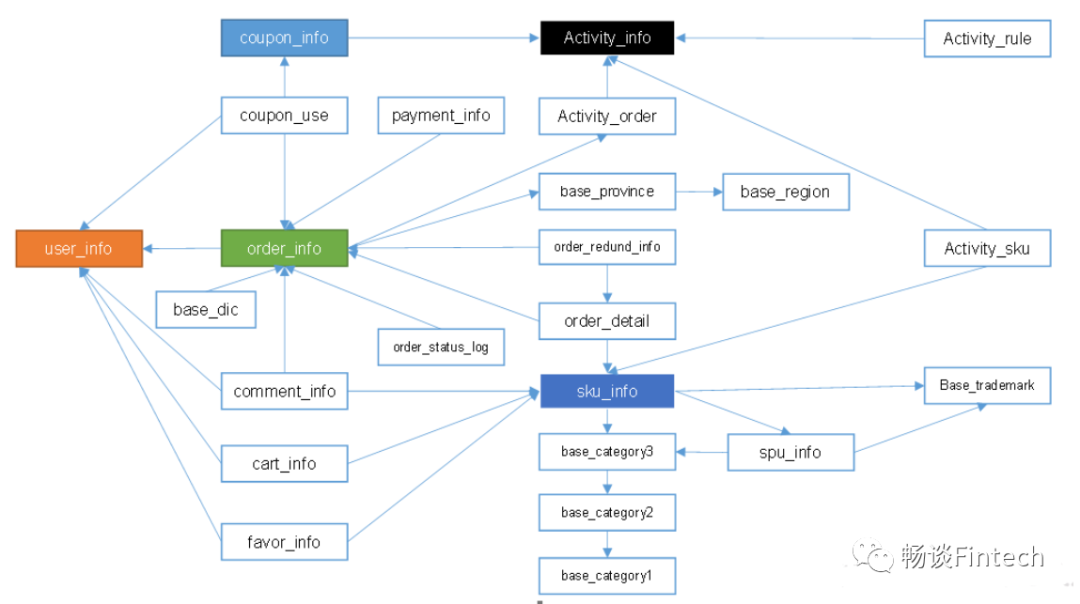
其中有颜色填充的表:事实表;
其他空白颜色表:代表维度表;
4.2、HDFS文件对应hive表结构关系
(1)考虑到分区partitioned by 时间
(2)考虑到lzo压缩,并且需要lzo压缩支持切片的话,必须要添加lzo索引
(3)mysql数据库的表通过sqoop采集到HDFS,用的是\t作为分割,那数仓里面ODS层也需要\t作为分割;
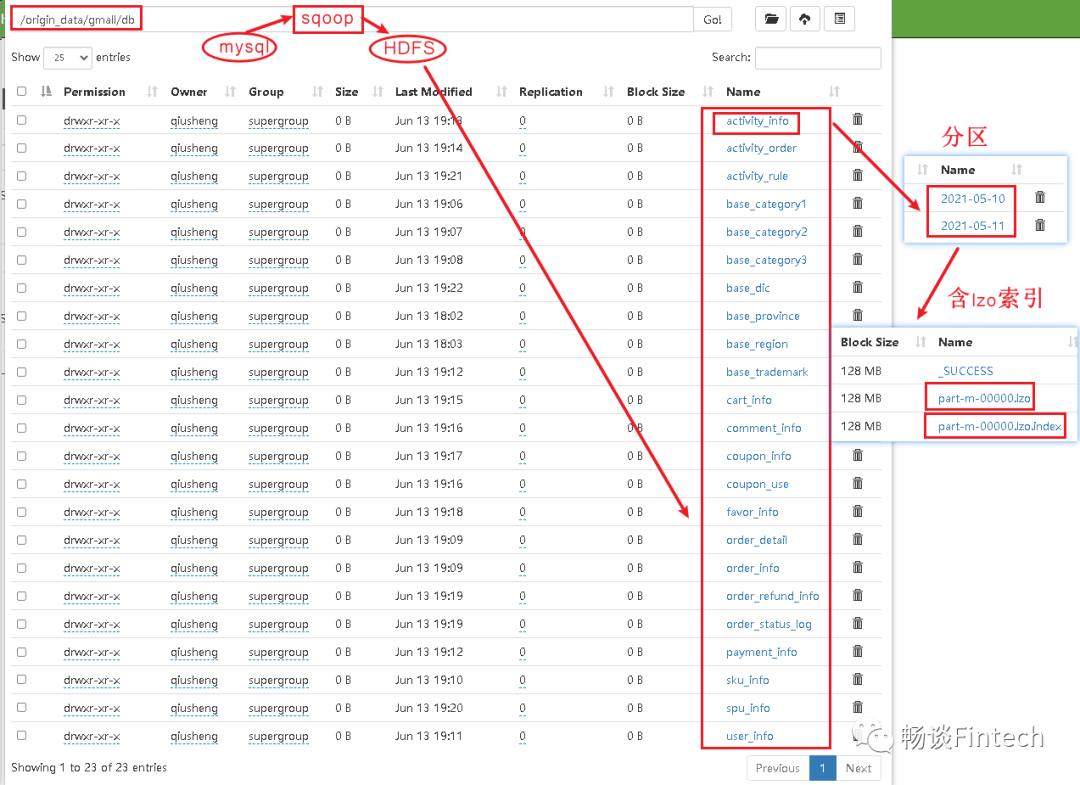
4.3、创建ODS层业务表
业务系统javaweb项目一共有23张表,数仓hive也要一一创建23张。但是需要注意数据的每日加载的同步策略。例如:
-
订单表ods_order_info
表数据同步更新策略:增量
-
SKU商品表ods_sku_info表
数据同步更新策略:全量
-
省份表ods_base_province
数据同步更新策略:特殊一次性全部加载,不做分区partitioned By
4.4、加载数据
load data
inpath '/origin_data/gmall/db/表名/XXXX-XX-XX'
OVERWRITE into table gmail.o表名 partition(dt='XXXX-XX-XX');
我们就完成了整个ODS层的数据处理。
四、DIM层
1、DIM层设计要点
分析思路:
我们先确定有6个维度表,根据不同的加载方式建立维度表,其中比较难处理的是拉链表。
表名和加载策略方式如下:

2、DIM层实现
-
根据维度表的字段来创建hive表结构;
-
选择PARQUET列式存储,压缩格式采用lzo;
-
按照dt每天分区;
-
拼接和关联字段
注意:维度表有一些字段是数组结构体类型来封装数据属性的。
3、DIM层表的加载方式
-
全量表3张:
商品维度表、优惠券维度表、活动维度表;
首日和每日ODS层数据都是全量加载到DIM层
-
特殊加载2张:
地区维度表、时间维度表;
地区维度表
这种特殊表,没有分区。即每天不会装载数据到DIM层。存储也是PARQUET。
时间维度表
时间纬度表的数据其实并不是来自于业务系统,是手动写入的。并且由于时间维度表数据的可预见性即日期年份都是固定的,无须每日导入,一般可一次性导入一年的数据(因为节假日这种数字都是前一年确定下一年的节假日)。
但是文本文件数据,传到hive的DIM层(DIM层存储是PARQUET格式)无法识别,一般解决办法是:
(1)节假日数据(一年)通过text文本格式上传到HDFS上临时表指定的路径
(2)在hive里面创建相对应的临时表
(3)通过查询临时表把数据装载到DIM表
-
拉链表1张(用户维度表)
适用于数据在每日发生变化,但是变化频繁又不是特别高的那种场景即数据缓慢变化。
操作步骤:
(1)获取当前日期的全量数据结束日期 = 9999-99-99
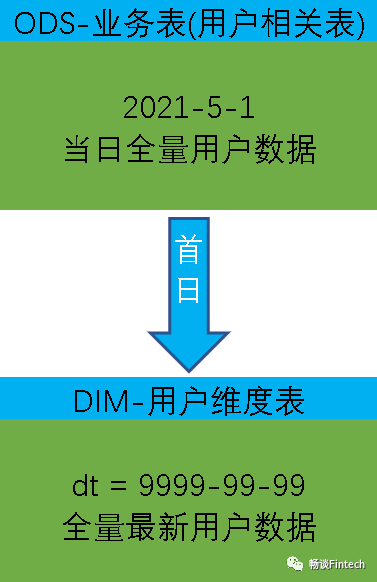
(2)获取某个时间点的全量切片数据(某个时间点的历史数据)开始日期 >= 某个时间 and 结束日期 <= 某个时间
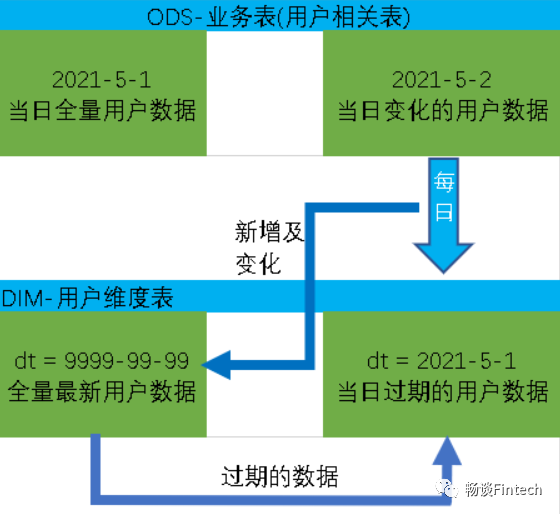
首日加载
具体工作为将ODS层当日的全部历史用户数据一次性导入到DIM层拉链表9999分区中。比如:ODS层,ods_user_info表,如果初始时间是2021年5月1日,则2021-05-01的分区数据就是全部的历史用户数据,故将该分区数据导入DIM层拉链表的9999分区即可。
每日加载
-
获取全量最新9999分区数据
-
获取前一日过期分区数据
-
把两部分数据做union写入到拉链表中
注意:
因为要写入两个分区,一个是9999分区,一个是2021-05-01分区。所以需要处理动态分区问题,传入分区的时候,不能写死。这里写dt,最后一列数据copy前面一列数据,作为分区字段,但是又因为列字段不能一样,修改第二个列的别名为dt,分区是按照dt分区。
nvl(new_end_date,old_end_date),
nvl(new_end_date,old_end_date) dt
cast(date_add('2021-05-02',-1) as string),
cast(date_add('2021-05-02',-1) as string) dt
到此就完成了DIM层用户维度表。
五、DWD层
DWD层是对事实表的处理,代表的是业务的最小粒度层。任何数据的记录都可以从这一层获取,为后续的DWS和DWT层做准备。DWD层是站在选择好事实表的基础上,对维度建模的视角,这层维度建模主要做的4个步骤:选择业务过程、声明粒度、确认维度、确认事实。前面我们已经论述过了。
1、DWD层设计要点
DWD层是对用户的日志行为进行解析,以及对业务数据采用维度模型的方式重新建模(维度退化),这两部分内容需要分别处理。
2、DWD层埋点日志log处理
前端埋点的日志信息,已经写到ODS层ods_log表了,传入的参数是一个String类型字符串即一条日志信息一个String类型字符串。
2.1、埋点日志解析思路
我们根据ODS层日志数据内容来解析到DWD层。一共拆解分为5个表,也可以根据启动日志和事件日志来解析到DWD层分为2个表。前者是根据内容信息来解析,颗粒度更细,后者比较简单就是根据数据的类型来解析。我们这里采用第一种方式,把页面日志和启动日志信息的数据装载到DWD层里面的五张表。所以DWD层日志处理工作就是解析这五张表。
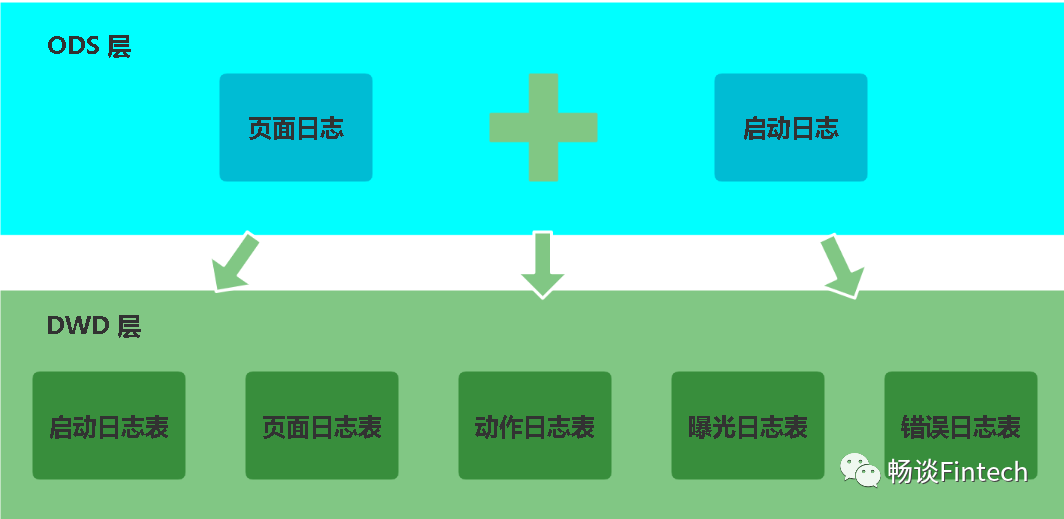
2.2、操作步骤
日志解析需要根据不同的表的具体情况解析,具体通用步骤为:
-
包含字段的日志过滤出来,然后使用get_json_object函数解析每个字段;
-
分区,`dt` STRING
-
压缩格式,lzo,存储是PARQUET
-
装载数据
首日和每日加载数据分区都是一样的策略,每天DWD层从ODS层获取数据后加载。
注意:
有些表比如动作页面action_log处理会复杂很多
常规解析思路是:先将包含action字段的日志过滤出来,然后通过UDF、UDTF函数将action数组“炸裂”,然后使用get_json_object函数解析每个字段。最后拼接sql完成。
UDF、UDTF函数:我们通过java代码来实现功能,并且通过MAVEN来打成jar。然后上传到HDFS集群,给hive做关联调用。
函数编写要点:
(1继承hive的GenericUDTF类;(2)实现initialize、process、close三个方法;
3、DWD层业务数据处理
业务数据解析之前我们先来看一下下图关于事实表和维度表的关系
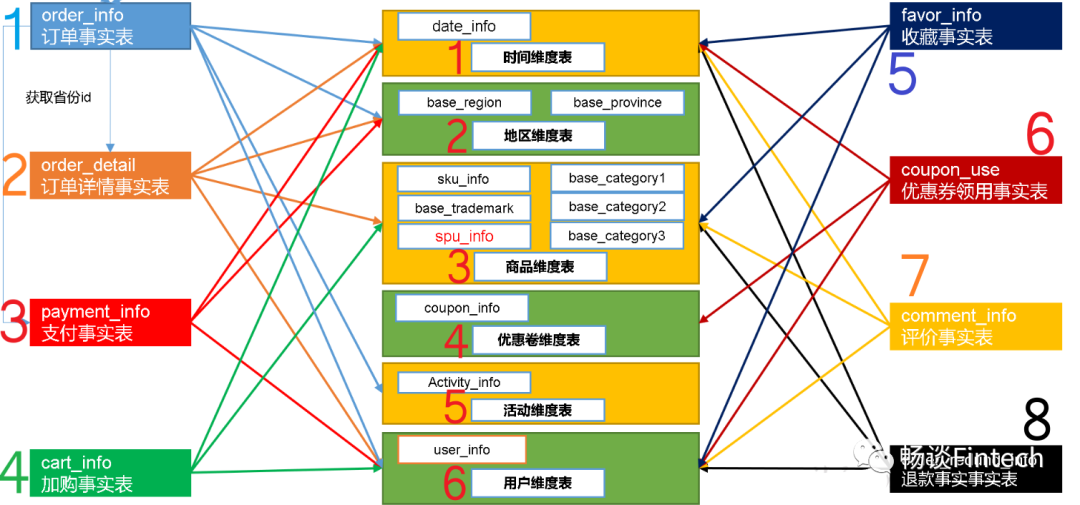
这里我们按照事实表的类型来解析:
-
事务型事实表
8张表包含:支付事实表、评价事实表、退款事实表、订单明细(详情)事实表。
根据事实表(行),选择不同的维度(列)来建表。

-
周期型快照事实表
每天做一次快照,导入的数据是全量,区别于事务型事实表是每天导入新增。
存储的数据比较讲究时效性,时间太久了的意义不大,可以删除以前的数据。
-
累积型快照事实表
我们以优惠券领用事实表为例。首先要了解优惠卷的生命周期:领取优惠卷——>用优惠卷下单——>优惠卷参与支付
累积型快照事实表使用:统计优惠卷领取次数、优惠卷下单次数、优惠卷参与支付次数。

首日装载要点
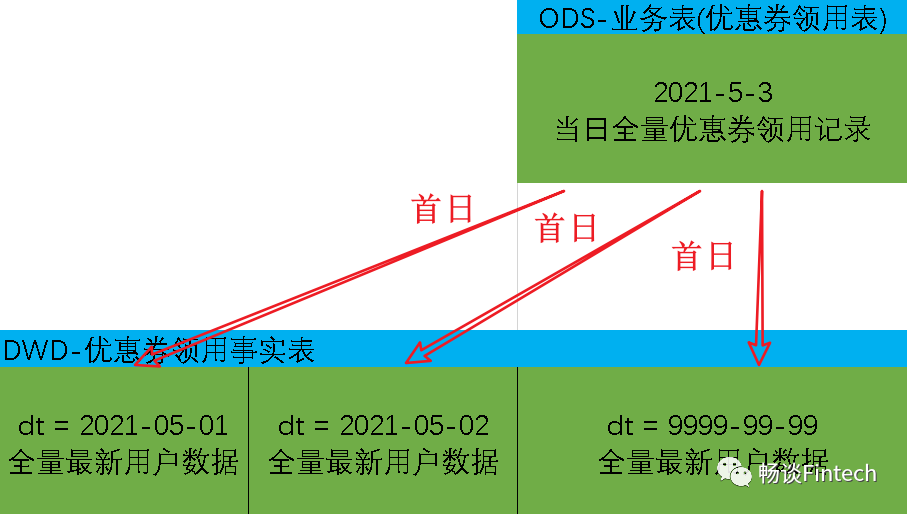
每日装载要点
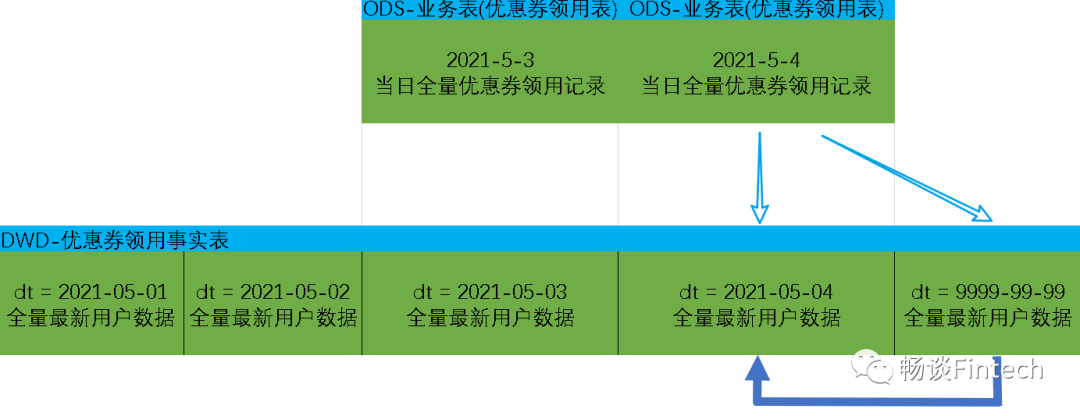
这样就完成了DWD层埋点日志和业务数据的建模和设计。
六、DWS层
DWS层就是关于各个主题的加工和使用,这层是宽表聚合值,是各个事实表的聚合值。这里做轻度的汇总会让以后的计算更加的高效,如:统计各个主题对象计算7天、30天、90天的行为, 应对特殊需求(例如,购买行为,统计商品复购率)会快很多不必走ODS层反复拿数据做加工。
涉及的主题包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等。具体见数仓(十五)从0到1简单搭建加载数仓DWS层
这里我们只举一个用户主题的加工和计算:DWS层用户主题表分析要点1、首先我们看一下需要统计加工的指标
login_count` BIGINT COMMENT '登录次数',
`cart_count` BIGINT COMMENT '加入购物车次数',
`favor_count` BIGINT COMMENT '收藏次数',
`order_count` BIGINT COMMENT '下单次数',
`order_activity_count` BIGINT COMMENT '订单参与活动次数',
`order_activity_reduce_amount` DECIMAL(16,2) COMMENT '订单减免金额(活动)',
`order_coupon_count` BIGINT COMMENT '订单用券次数',
`order_coupon_reduce_amount` DECIMAL(16,2) COMMENT '订单减免金额(使用优惠券)',
`order_original_amount` DECIMAL(16,2) COMMENT '订单单原始金额',
`order_final_amount` DECIMAL(16,2) COMMENT '订单总金额',
`payment_count` BIGINT COMMENT '支付次数',
`payment_amount` DECIMAL(16,2) COMMENT '支付金额',
`refund_order_count` BIGINT COMMENT '退单次数',
`refund_order_num` BIGINT COMMENT '退单件数',
`refund_order_amount` DECIMAL(16,2) COMMENT '退单金额',
`refund_payment_count` BIGINT COMMENT '退款次数',
`refund_payment_num` BIGINT COMMENT '退款件数',
`refund_payment_amount` DECIMAL(16,2) COMMENT '退款金额',
`coupon_get_count` BIGINT COMMENT '优惠券领取次数',
`coupon_using_count` BIGINT COMMENT '优惠券使用(下单)次数',
`coupon_used_count` BIGINT COMMENT '优惠券使用(支付)次数',
`appraise_good_count` BIGINT COMMENT '好评数',
`appraise_mid_count` BIGINT COMMENT '中评数',
`appraise_bad_count` BIGINT COMMENT '差评数',
`appraise_default_count` BIGINT COMMENT '默认评价数',
`order_detail_stats` array<struct<sku_id:string,sku_num:bigint,order_count:bigint,activity_reduce_amount:decimal(16,2),coupon_reduce_amount:decimal(16,2),original_amount:decimal(16,2),final_amount:decimal(16,2)>> COMMENT '下单明细统计'
2、我们把指标分为8大类
分别计算指标值,然后拼接SQL。
2.1、login_count 登录次数这个指标简单,根据dwd层,dwd_page_log表可以直接计算。
2.2、cart_count 加入购物车次数; favor_count 收藏次数;这两个指标也是很简单,直接根据dwd层,dwd_action_log表中获取。
2.3、order_count 下单次数; order_activity_count 订单参与活动次数; order_activity_reduce_amount 订单减免金额(活动);订单表的几个指标相对也很简单,直接根据dwd层,dwd_order_info表中获取。
2.4、payment_count'支付次数', payment_amount'支付金额',
elect
date_format(callback_time,'yyyy-MM-dd') dt,
user_id,
count(*) payment_count,
sum(payment_amount) payment_amount
from dwd_payment_info
group by date_format(callback_time,'yyyy-MM-dd'),user_id
2.5、refund_order_count 退单次数', refund_order_num 退单件数', refund_order_amount '退单金额',
select
date_format(create_time,'yyyy-MM-dd') dt,
user_id,
count(*) refund_order_count,
sum(refund_num) refund_order_num,
sum(refund_amount) refund_order_amount
from dwd_order_refund_info
group by date_format(create_time,'yyyy-MM-dd'),user_id
2.6、refund_payment_count '退款次数', refund_payment_num '退款件数', refund_payment_amount '退款金额',
2.7、coupon_get_count '优惠券领取次数',
coupon_using_count
'优惠券使用(下单)次数',
coupon_used_count
'优惠券使用(支付)次数',
2.8、coupon_get_count 优惠券领取次数
coupon_using_count
优惠券使用(下单)次数
coupon_used_count
优惠券使用(支付)次数,
3、完成首日加载
注意:分区是动态分区
insert overwrite table dws_user_action_daycount partition(dt)
select
coalesce(tmp_login.user_id,tmp_cf.user_id,tmp_order.user_id,tmp_pay.user_id,tmp_ri.user_id,tmp_rp.user_id,tmp_comment.user_id,tmp_coupon.user_id,tmp_od.user_id),
nvl(login_count,0),
nvl(cart_count,0),
nvl(favor_count,0),
XXXX,
4、完成每日加载
分区是每日时间
insert overwrite table dws_user_action_daycount partition(dt='2020-06-15')
select
coalesce(tmp_login.user_id,tmp_cf.user_id,tmp_order.user_id,tmp_pay.user_id,tmp_ri.user_id,tmp_rp.user_id,tmp_comment.user_id,tmp_coupon.user_id,tmp_od.user_id),
nvl(login_count,0),
nvl(cart_count,0),
nvl(favor_count,0),
nvl(order_count,0),
这样我们就完成了关于用户主题的DWS层的汇聚值的计算。
七、DWT层
这层涉及的主题和DWS层一样包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等。只不过DWS层的粒度是对当日用户汇总信息,而DWT层是对截止到当日、或者近7日、近30日等的汇总信息。
其实这两层建模完全可以构建放到一层里面做加工和处理。但是为了更好的复用,我们分为两层。
这里我们拿用户主题这个来举列:
DWS层:用户主题层是记录某一个用户在某一天的汇总行为。DWT层:用户主题层是记录某一个用户截止在当日的汇总行为。一般情况下DWT层指标是DWS层的好几倍!这里我们只举一个用户主题的加工和计算:DWT层用户主题表分析要点:1、首先我们看一下需要统计加工的指标
`login_date_first` STRING COMMENT '首次活跃日期',
`login_date_last` STRING COMMENT '末次活跃日期',
`login_date_1d_count` STRING COMMENT '最近1日登录次数',
`login_last_1d_day_count` BIGINT COMMENT '最近1日登录天数',
`login_last_7d_count` BIGINT COMMENT '最近7日登录次数',
`login_last_7d_day_count` BIGINT COMMENT '最近7日登录天数',
`login_last_30d_count` BIGINT COMMENT '最近30日登录次数',
`login_last_30d_day_count` BIGINT COMMENT '最近30日登录天数',
`login_count` BIGINT COMMENT '累积登录次数',
`login_day_count` BIGINT COMMENT '累积登录天数',
用户主题的指标分为几大类:登录类指标、订单类指标、退单类指标、支付指标、优惠券指标、购物车、评论、收藏等等。
我们主要关注主题的
-
首次、末次登录、购买、支付、退款等;
-
最近1日、7日、30日各个主题;
-
累积登录、次数、支付、退款等;
2、首日计算加载思路首日加载的思路是:如下图:DWS层2021年5月1日的数据、5月2日、5月3日的各个维度的对象的汇总统计数据,需要全部汇集到DWT层2021年5月3日的数据里面。
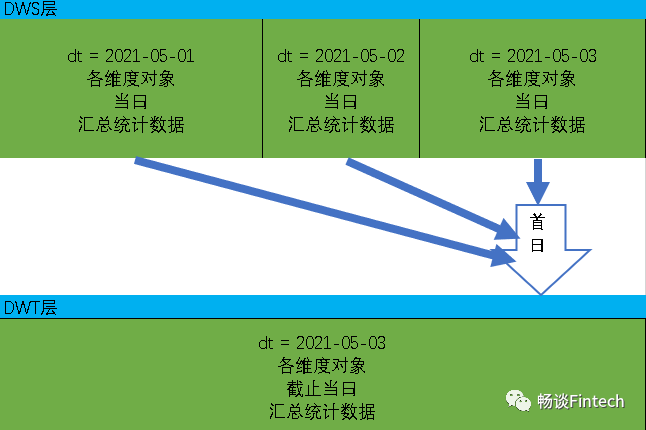
3、每日计算加载策略每日加载的思路是:如下图:DWT层2021年5月4日的数据里面有两部分:一个是DWT层5月3日的数据,一部分是DWS层2021年5月4日的当日的汇总数据,这两部分需要全部汇集到DWT层2021年5月4日的数据里面。

这样我们就完成了DWT的汇总加工。
到这里就完成了整个数仓的建模过程。数仓建模需要大量的业务经验,分析思考建模能力和经验。
八、ADS层
ADS层数据是专门给业务使用的数据层,这层是面向业务定制的应用数据层。
-
这一层是提供为数据产品使用的结果数据、指标等。
-
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、MySQL等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。如报表数据,或者说那种大宽表。
这个项目中ADS层也是包含有多个主题:设备主题、会员主题、商品主题、营销主题、地区主题、访客主题、用户主题、订单主题、优惠券主题、活动主题等等。每个主题都包含多个指标的计算。
下面还是用用户主题来讲解。
1、业务需求指标

2、根据指标建表
分别计算指标值,然后拼接SQL。
需要注意的是
-
ADS层表我们不会建立分区,因为计算的都是业务指标数值;
-
也不设置存储方式和压缩方式,就是文本格式;
DROP TABLE IF EXISTS ads_user_total;
CREATE EXTERNAL TABLE `ads_user_total`
(
`dt` STRING COMMENT '统计日期',
`recent_days` BIGINT COMMENT '最近天数,0:累积值,1:最近1天,7:最近7天,30:最近30天',
`new_user_count` BIGINT COMMENT '新注册用户数',
`new_order_user_count` BIGINT COMMENT '新增下单用户数',
`order_final_amount` DECIMAL(16,2) COMMENT '下单总金额',
`order_user_count` BIGINT COMMENT '下单用户数',
`no_order_user_count` BIGINT COMMENT '未下单用户数(具体指活跃用户中未下单用户)'
) COMMENT '用户统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_user_total/';
3、指标-用户变动统计这个需求包括两个指标,分别为流失用户数和回流用户数,以下为对两个指标的解释说明。

3.1、建表
DROP TABLE IF EXISTS ads_user_change;
CREATE EXTERNAL TABLE `ads_user_change` (
`dt` STRING COMMENT '统计日期',
`user_churn_count` BIGINT COMMENT '流失用户数',
`user_back_count` BIGINT COMMENT '回流用户数'
) COMMENT '用户变动统计'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_user_change/';
3.2、分别计算流失用户数和回流用户数计算可以参考数仓(十七)从0到1简单搭建加载数仓ADS层
4、指标-用户行为漏斗分析漏斗分析是一个数据分析模型,它能够科学反映一个业务过程从起点到终点各阶段用户转化情况。这里我们简单概述一下,如果想详细了解的可以去看有关数据分析模型。

4.1、建立对应的表
DROP TABLE IF EXISTS ads_user_action;
CREATE EXTERNAL TABLE `ads_user_action` (
`dt` STRING COMMENT '统计日期',
`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`home_count` BIGINT COMMENT '浏览首页人数',
`good_detail_count` BIGINT COMMENT '浏览商品详情页人数',
`cart_count` BIGINT COMMENT '加入购物车人数',
`order_count` BIGINT COMMENT '下单人数',
`payment_count` BIGINT COMMENT '支付人数'
) COMMENT '漏斗分析'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_user_action/';
4.2、计算每层指标思路是计算每一层的数据总和,然后多重case when嵌套。计算可以参考:数仓(十七)从0到1简单搭建加载数仓ADS层
5、指标-用户留存率
留存分析是衡量产品对用户价值高低的重要指标。留存分析一般包含新增留存和活跃留存分析。
-
新增留存分析
是分析某天的新增用户中,有多少人有后续的活跃行为
-
活跃留存分析
活跃留存分析是分析某天的活跃用户中,有多少人有后续的活跃行为。
此处要求统计新增留存率,新增留存率具体是指留存用户数与新增用户数的比值。
例如:2020-06-14新增100个用户,1日之后(2020-06-15)这100人中有80个人活跃了,那2020-06-14的1日留存数则为80,2020-06-14的1日留存率则为80%。
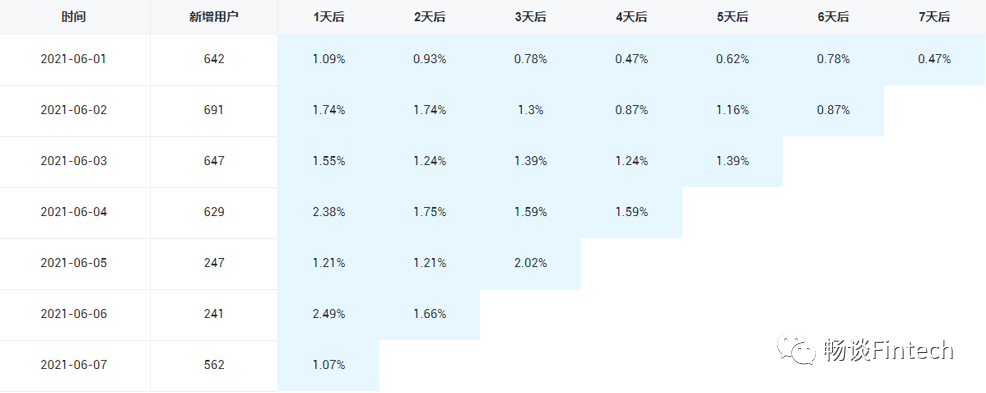
5.1、建表分别计算后SQL拼接
DROP TABLE IF EXISTS ads_user_retention;
CREATE EXTERNAL TABLE ads_user_retention (
`dt` STRING COMMENT '统计日期',
`create_date` STRING COMMENT '用户新增日期',
`retention_day` BIGINT COMMENT '截至当前日期留存天数',
`retention_count` BIGINT COMMENT '留存用户数量',
`new_user_count` BIGINT COMMENT '新增用户数量',
`retention_rate` DECIMAL(16,2) COMMENT '留存率'
) COMMENT '用户留存率'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_user_retention/';
计算可以参考数仓(十七)从0到1简单搭建加载数仓ADS层
总结:
这样我们把数仓建模的步骤、以及数仓分层思路、ODS、DIM、DWD、DWS、DWT、ADS层的设计、处理、加载等总结了一下。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET10 - 预览版1新功能体验(一)