

阿里云开源离线同步工具DataX3.0介绍
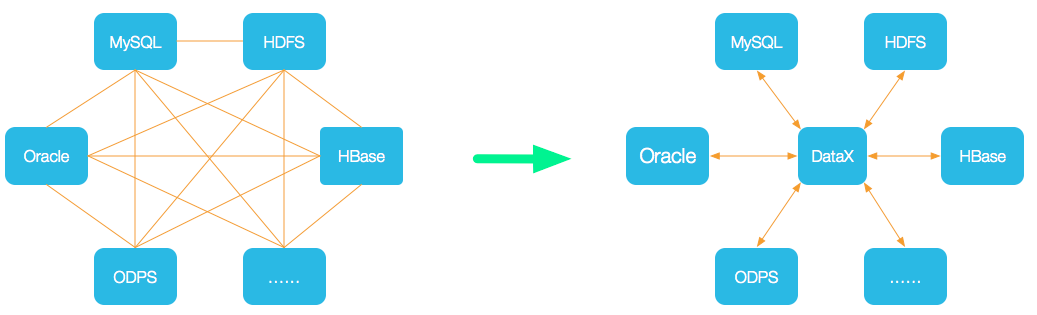
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
-
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
-
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader�为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
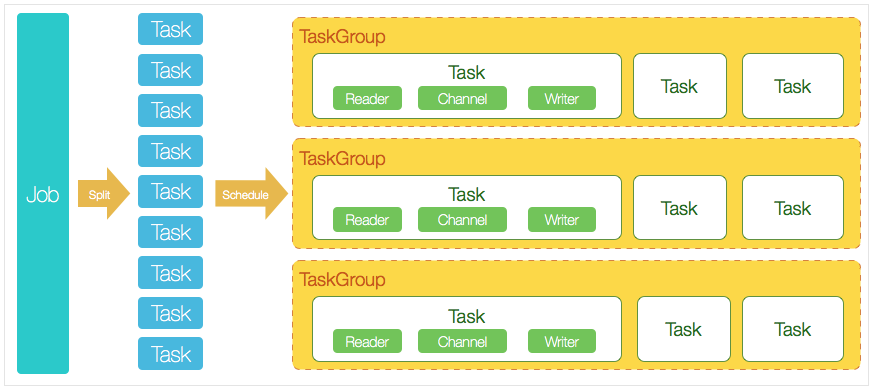
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
-
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量�运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
-
-
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
-
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": {
"channel": 5,
"byte": 1048576,
"record": 10000
}
-
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
-
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
-
-
-
易用
下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
-
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
-
传输过程中打印传输速度、进度等

-
传输过程中会打印进程相关的CPU、JVM等
-

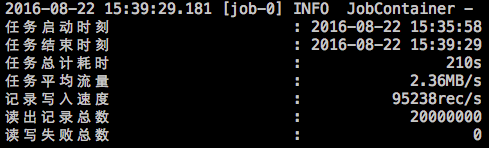
- 在任务结束之后,打印总体运行情况
-
-
-
1.8 Quick Start
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
Quick start地址:https://github.com/alibaba/DataX/blob/master/userGuid.md
1.8.1 System Requirement
• Linux • JDK(1.8以上,推荐1.8) • Python(推荐Python2.6.X) • Apache Maven 3.x (Compile DataX)
1.8.2 工具部署
方法一、直接下载DataX工具包:DataX下载地址(http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz)
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
自检脚本:python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
方法二:下载DataX源码,自己编译:https://github.com/alibaba/DataX
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git
(2)、通过maven打包
$ cd {DataX_source_code_home} $ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] -----------------------------------------------------------------
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] -----------------------------------------------------------------
打包成功后的DataX包位于{DataX_source_code_home}/target/datax/datax/,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
1.8.3 配置示例:从stream读取数据并打印到控制台
(1)、第一步、创建创业的的配置文件(json格式)
可以通过命令查看配置模板:python datax.py -r {YOUR_READER} -w {YOUR_WRITER}

[root@hadoop1 bin]# pwd /home/installed/datax/bin [root@hadoop1 bin]# python datax.py -r streamreader -w streamwriter DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Please refer to the streamreader document: https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document: https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job. { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "column": [], "sliceRecordCount": "" } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "", "print": true } } } ], "setting": { "speed": { "channel": "" } } } } [root@hadoop1 bin]#
根据模板配置json如下:
#stream2stream.json { "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "sliceRecordCount": 10, "column": [ { "type": "long", "value": "10" }, { "type": "string", "value": "hello,你好,世界-DataX" } ] } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "UTF-8", "print": true } } } ], "setting": { "speed": { "channel": 5 } } } }
第二步:启动DataX
[root@hadoop3 datax]# cd /home/installed/datax/bin/ [root@hadoop3 bin]# python datax.py /home/test/dataxtest/stream2stream.json DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. 2019-09-09 16:14:17.345 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl 2019-09-09 16:14:17.356 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.161-b12 jvmInfo: Linux amd64 3.10.0-693.el7.x86_64 cpu num: 4 totalPhysicalMemory: -0.00G freePhysicalMemory: -0.00G maxFileDescriptorCount: -1 currentOpenFileDescriptorCount: -1 GC Names [PS MarkSweep, PS Scavenge] MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2019-09-09 16:14:17.375 [main] INFO Engine - { "content":[ { "reader":{ "name":"streamreader", "parameter":{ "column":[ { "type":"long", "value":"10" }, { "type":"string", "value":"hello,你好,世界-DataX" } ], "sliceRecordCount":10 } }, "writer":{ "name":"streamwriter", "parameter":{ "encoding":"UTF-8", "print":true } } } ], "setting":{ "speed":{ "channel":5 } } } 2019-09-09 16:14:17.404 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null 2019-09-09 16:14:17.406 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0 2019-09-09 16:14:17.406 [main] INFO JobContainer - DataX jobContainer starts job. 2019-09-09 16:14:17.409 [main] INFO JobContainer - Set jobId = 0 2019-09-09 16:14:17.431 [job-0] INFO JobContainer - jobContainer starts to do prepare ... 2019-09-09 16:14:17.432 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work . 2019-09-09 16:14:17.432 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work . 2019-09-09 16:14:17.433 [job-0] INFO JobContainer - jobContainer starts to do split ... 2019-09-09 16:14:17.433 [job-0] INFO JobContainer - Job set Channel-Number to 5 channels. 2019-09-09 16:14:17.434 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [5] tasks. 2019-09-09 16:14:17.435 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [5] tasks. 2019-09-09 16:14:17.467 [job-0] INFO JobContainer - jobContainer starts to do schedule ... 2019-09-09 16:14:17.485 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups. 2019-09-09 16:14:17.488 [job-0] INFO JobContainer - Running by standalone Mode. 2019-09-09 16:14:17.507 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [5] channels for [5] tasks. 2019-09-09 16:14:17.513 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated. 2019-09-09 16:14:17.513 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated. 2019-09-09 16:14:17.545 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] attemptCount[1] is started 2019-09-09 16:14:17.558 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] attemptCount[1] is started 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 2019-09-09 16:14:17.580 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] attemptCount[1] is started 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 2019-09-09 16:14:17.598 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[4] attemptCount[1] is started 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 2019-09-09 16:14:17.619 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 10 hello,你好,世界-DataX 2019-09-09 16:14:17.731 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[112]ms 2019-09-09 16:14:17.731 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] is successed, used[163]ms 2019-09-09 16:14:17.731 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] is successed, used[202]ms 2019-09-09 16:14:17.731 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] is successed, used[177]ms 2019-09-09 16:14:17.732 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[4] is successed, used[136]ms 2019-09-09 16:14:17.733 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks. 2019-09-09 16:14:27.511 [job-0] INFO StandAloneJobContainerCommunicator - Total 50 records, 950 bytes | Speed 95B/s, 5 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00% 2019-09-09 16:14:27.511 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks. 2019-09-09 16:14:27.511 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work. 2019-09-09 16:14:27.512 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work. 2019-09-09 16:14:27.512 [job-0] INFO JobContainer - DataX jobId [0] completed successfully. 2019-09-09 16:14:27.513 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /home/installed/datax/hook 2019-09-09 16:14:27.515 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00% [total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s 2019-09-09 16:14:27.516 [job-0] INFO JobContainer - PerfTrace not enable! 2019-09-09 16:14:27.516 [job-0] INFO StandAloneJobContainerCommunicator - Total 50 records, 950 bytes | Speed 95B/s, 5 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00% 2019-09-09 16:14:27.517 [job-0] INFO JobContainer - 任务启动时刻 : 2019-09-09 16:14:17 任务结束时刻 : 2019-09-09 16:14:27 任务总计耗时 : 10s 任务平均流量 : 95B/s 记录写入速度 : 5rec/s 读出记录总数 : 50 读写失败总数 : 0 [root@hadoop3 bin]#
1.9 使用DataX进行MySQL数据读写
1.9.1 MysqlReader插件文档
1.9.1.1 快速介绍
MysqlReader插件实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的sql语句将数据从mysql库中SELECT出来。
不同于其他关系型数据库,MysqlReader不支持FetchSize.
1.9.1.2 实现原理
简而言之,MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
对于用户配置Table、Column、Where的信息,MysqlReader将其拼接为SQL语句发送到Mysql数据库;对于用户配置querySql信息,MysqlReader直接将其发送到Mysql数据库。
1.9.1.3 功能说明
1.9.1.3.1 配置样例
• 配置一个从Mysql数据库同步抽取数据到本地的作业:
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "column": [ "id", "name" ], "splitPk": "db_id", "connection": [ { "table": [ "table" ], "jdbcUrl": [ "jdbc:mysql://127.0.0.1:3306/database" ] } ] } }, "writer": { "name": "streamwriter", "parameter": { "print":true } } } ] } }
• 配置一个自定义SQL的数据库同步任务到本地内容的作业:
{ "job": { "setting": { "speed": { "channel":1 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "connection": [ { "querySql": [ "select db_id,on_line_flag from db_info where db_id < 10;" ], "jdbcUrl": [ "jdbc:mysql://bad_ip:3306/database", "jdbc:mysql://127.0.0.1:bad_port/database", "jdbc:mysql://127.0.0.1:3306/database" ] } ] } }, "writer": { "name": "streamwriter", "parameter": { "print": false, "encoding": "UTF-8" } } } ] } }
1.9.1.3.2 参数说明
• jdbcUrl
描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MysqlReader可以依次探测ip的可连接性,直到选择一个合法的IP。
如果全部连接失败,MysqlReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。
jdbcUrl按照Mysql官方规范,并可以填写连接附件控制信息。具体请参看Mysql官方文档。
必选:是
默认值:无
• username
描述:数据源的用户名
必选:是
默认值:无
• password
描述:数据源指定用户名的密码
必选:是
默认值:无
• table
描述:所选取的需要同步的表。使用JSON的数组描述,因此支持多张表同时抽取。当配置为多张表时,用户自己需保证多张表是同一schema结构,MysqlReader不予检查表是否同一逻辑表。注意,table必须包含在connection配置单元中。
必选:是
默认值:无
• column
描述:所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如[’’]。
支持列裁剪,即列可以挑选部分列进行导出。
支持列换序,即列可以不按照表schema信息进行导出。
支持常量配置,用户需要按照Mysql SQL语法格式: [“id”, “table”, “1”, “‘bazhen.csy’”, “null”, “to_char(a + 1)”, “2.3” , “true”] id为普通列名,table为包含保留在的列名,1为整形数字常量,'bazhen.csy’为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。
必选:是
默认值:无
• splitPk
描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!
如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
必选:否
默认值:空
• where
描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。
必选:否
默认值:无
• querySql
描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。
必选:否
默认值:无
1.9.1.3.3 类型转换
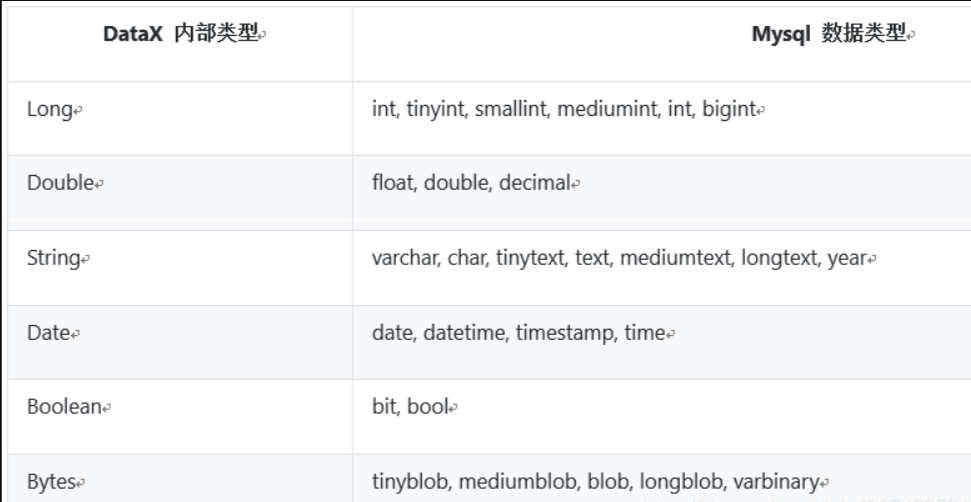
目前MysqlReader支持大部分Mysql类型,但也存在部分个别类型没有支持的情况,请注意检查你的类型。
下面列出MysqlReader针对Mysql类型转换列表:
请注意:
除上述罗列字段类型外,其他类型均不支持。
tinyint(1) DataX视作为整形。
year DataX视作为字符串类型
bit DataX属于未定义行为。
1.9.1.4 约束限制
1 主备同步数据恢复问题
主备同步问题指Mysql使用主从灾备,备库从主库不间断通过binlog恢复数据。由于主备数据同步存在一定的时间差,特别在于某些特定情况,例如网络延迟等问题,导致备库同步恢复的数据与主库有较大差别,导致从备库同步的数据不是一份当前时间的完整镜像。
针对这个问题,我们提供了preSql功能,该功能待补充。
2 一致性约束
Mysql在数据存储划分中属于RDBMS系统,对外可以提供强一致性数据查询接口。例如当一次同步任务启动运行过程中,当该库存在其他数据写入方写入数据时,MysqlReader完全不会获取到写入更新数据,这是由于数据库本身的快照特性决定的。关于数据库快照特性,请参看MVCC Wikipedia
上述是在MysqlReader单线程模型下数据同步一致性的特性,由于MysqlReader可以根据用户配置信息使用了并发数据抽取,因此不能严格保证数据一致性:当MysqlReader根据splitPk进行数据切分后,会先后启动多个并发任务完成数据同步。由于多个并发任务相互之间不属于同一个读事务,同时多个并发任务存在时间间隔。因此这份数据并不是完整的、一致的数据快照信息。
针对多线程的一致性快照需求,在技术上目前无法实现,只能从工程角度解决,工程化的方式存在取舍,我们提供几个解决思路给用户,用户可以自行选择:
使用单线程同步,即不再进行数据切片。缺点是速度比较慢,但是能够很好保证一致性。
关闭其他数据写入方,保证当前数据为静态数据,例如,锁表、关闭备库同步等等。缺点是可能影响在线业务。
3 数据库编码问题
Mysql本身的编码设置非常灵活,包括指定编码到库、表、字段级别,甚至可以均不同编码。优先级从高到低为字段、表、库、实例。我们不推荐数据库用户设置如此混乱的编码,最好在库级别就统一到UTF-8。
MysqlReader底层使用JDBC进行数据抽取,JDBC天然适配各类编码,并在底层进行了编码转换。因此MysqlReader不需用户指定编码,可以自动获取编码并转码。
对于Mysql底层写入编码和其设定的编码不一致的混乱情况,MysqlReader对此无法识别,对此也无法提供解决方案,对于这类情况,导出有可能为乱码。
4 增量数据同步
MysqlReader使用JDBC SELECT语句完成数据抽取工作,因此可以使用SELECT…WHERE…进行增量数据抽取,方式有多种:
数据库在线应用写入数据库时,填充modify字段为更改时间戳,包括新增、更新、删除(逻辑删)。对于这类应用,MysqlReader只需要WHERE条件跟上一同步阶段时间戳即可。
对于新增流水型数据,MysqlReader可以WHERE条件后跟上一阶段最大自增ID即可。
对于业务上无字段区分新增、修改数据情况,MysqlReader也无法进行增量数据同步,只能同步全量数据。
5 Sql安全性
MysqlReader提供querySql语句交给用户自己实现SELECT抽取语句,MysqlReader本身对querySql不做任何安全性校验。这块交由DataX用户方自己保证。
FAQ
Q: MysqlReader同步报错,报错信息为XXX
A: 网络或者权限问题,请使用mysql命令行测试:
mysql -u<username> -p<password> -h<ip> -D<database> -e "select * from <表名>"
如果上述命令也报错,那可以证实是环境问题,请联系你的DBA。
1.9.2 DataX MySQLWriter
1 快速介绍
MysqlWriter 插件实现了写入数据到 Mysql 主库的目的表的功能。在底层实现上, MysqlWriter 通过 JDBC 连接远程 Mysql 数据库,并执行相应的 insert into … 或者 ( replace into …) 的 sql 语句将数据写入 Mysql,内部会分批次提交入库,需要数据库本身采用 innodb 引擎。
MysqlWriter 面向ETL开发工程师,他们使用 MysqlWriter 从数仓导入数据到 Mysql。同时 MysqlWriter 亦可以作为数据迁移工具为DBA等用户提供服务。
2 实现原理
MysqlWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的 writeMode 生成
• insert into…(当主键/唯一性索引冲突时会写不进去冲突的行)
或者
• replace into…(没有遇到主键/唯一性索引冲突时,与 insert into 行为一致,冲突时会用新行替换原有行所有字段) 的语句写入数据到 Mysql。出于性能考虑,采用了 PreparedStatement + Batch,并且设置了:rewriteBatchedStatements=true,将数据缓冲到线程上下文 Buffer 中,当 Buffer 累计到预定阈值时,才发起写入请求。
注意:目的表所在数据库必须是主库才能写入数据;整个任务至少需要具备 insert/replace into…的权限,是否需要其他权限,取决于你任务配置中在 preSql 和 postSql 中指定的语句。
3 功能说明
3.1 配置样例
• 这里使用一份从内存产生到 Mysql 导入的数据。
{ "job": { "setting": { "speed": { "channel": 1 } }, "content": [ { "reader": { "name": "streamreader", "parameter": { "column" : [ { "value": "DataX", "type": "string" }, { "value": 19880808, "type": "long" }, { "value": "1988-08-08 08:08:08", "type": "date" }, { "value": true, "type": "bool" }, { "value": "test", "type": "bytes" } ], "sliceRecordCount": 1000 } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "root", "password": "root", "column": [ "id", "name" ], "session": [ "set session sql_mode='ANSI'" ], "preSql": [ "delete from test" ], "connection": [ { "jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk", "table": [ "test" ] } ] } } } ] } }
3.2 参数说明
• jdbcUrl
o 描述:目的数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true o 注意:1、在一个数据库上只能配置一个 jdbcUrl 值。这与 MysqlReader 支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况) o 2、jdbcUrl按照Mysql官方规范,并可以填写连接附加控制信息,比如想指定连接编码为 gbk ,则在 jdbcUrl 后面追加属性 useUnicode=true&characterEncoding=gbk。具体请参看 Mysql官方文档或者咨询对应 DBA。 o 必选:是 o 默认值:无
• username
o 描述:目的数据库的用户名
o 必选:是
o 默认值:无
• password
o 描述:目的数据库的密码
o 必选:是
o 默认值:无
• table
o 描述:目的表的表名称。支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。
o 注意:table 和 jdbcUrl 必须包含在 connection 配置单元中
o 必选:是
o 默认值:无
• column
o 描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。如果要依次写入全部列,使用表示, 例如: "column": [""]。 o **column配置项必须指定,不能留空!** o o 注意:1、我们强烈不推荐你这样配置,因为当你目的表字段个数、类型等有改动时,你的任务可能运行不正确或者失败 o 2、 column 不能配置任何常量值 o 必选:是 o 默认值:否
• session
o 描述: DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
o 必须: 否
o 默认值: 空
• preSql
o 描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, ... datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:"preSql":["delete from 表名"],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称 o 必选:否 o 默认值:无
• postSql
o 描述:写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
o 必选:否
o 默认值:无
• writeMode
o 描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句 o 必选:是 o 所有选项:insert/replace/update o 默认值:insert
• batchSize
o 描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
o 必选:否
o 默认值:1024
3.3 类型转换
类似 MysqlReader ,目前 MysqlWriter 支持大部分 Mysql 类型,但也存在部分个别类型没有支持的情况,请注意检查你的类型。
下面列出 MysqlWriter 针对 Mysql 类型转换列表:
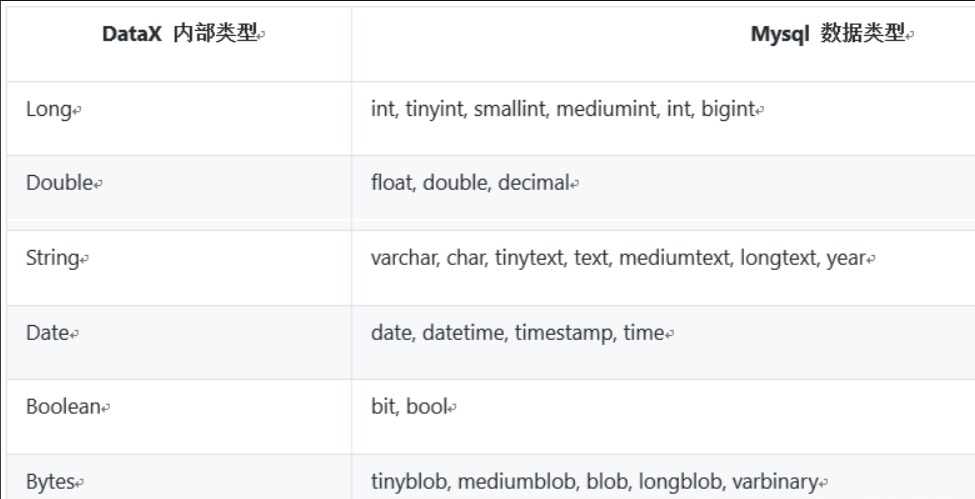
• bit类型目前是未定义类型转换
FAQ
Q: MysqlWriter 执行 postSql 语句报错,那么数据导入到目标数据库了吗?
A: DataX 导入过程存在三块逻辑,pre 操作、导入操作、post 操作,其中任意一环报错,DataX 作业报错。由于 DataX 不能保证在同一个事务完成上述几个操作,因此有可能数据已经落入到目标端。
Q: 按照上述说法,那么有部分脏数据导入数据库,如果影响到线上数据库怎么办?
A: 目前有两种解法,第一种配置 pre 语句,该 sql 可以清理当天导入数据, DataX 每次导入时候可以把上次清理干净并导入完整数据。第二种,向临时表导入数据,完成后再 rename 到线上表。
Q: 上面第二种方法可以避免对线上数据造成影响,那我具体怎样操作?
A: 可以配置临时表导入
1.10 Mysql2Hive
接下来将mysql数据库中的数据写入hive的案例:
mysql数据库和表准备:
CREATE DATABASE `complaint_report` DEFAULT CHARACTER SET utf8; USE `complaint_report`; DROP TABLE IF EXISTS `sys_complaint_threshold_value`; CREATE TABLE `sys_complaint_threshold_value` ( `id` BIGINT(10) NOT NULL AUTO_INCREMENT, `threshold_type` VARCHAR(16) DEFAULT NULL, `threshold_name` VARCHAR(32) DEFAULT NULL, `threshold_value` SMALLINT(2) DEFAULT '0', `threshold_key` VARCHAR(32) DEFAULT NULL, `operator_msg` VARCHAR(32) DEFAULT NULL, `operator_scope` VARCHAR(16) DEFAULT NULL, `create_date` DATETIME DEFAULT NULL, `create_user` VARCHAR(32) DEFAULT NULL, `update_date` DATETIME DEFAULT NULL, `update_user` VARCHAR(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
Hive中创建库test_db和表sys_complaint_threshold_value:
CREATE DATABASE `complaint_report` DEFAULT CHARACTER SET utf8; USE `complaint_report`; DROP TABLE IF EXISTS `sys_complaint_threshold_value`; CREATE TABLE `sys_complaint_threshold_value` ( `id` BIGINT(10) NOT NULL AUTO_INCREMENT, `threshold_type` VARCHAR(16) DEFAULT NULL, `threshold_name` VARCHAR(32) DEFAULT NULL, `threshold_value` SMALLINT(2) DEFAULT '0', `threshold_key` VARCHAR(32) DEFAULT NULL, `operator_msg` VARCHAR(32) DEFAULT NULL, `operator_scope` VARCHAR(16) DEFAULT NULL, `create_date` DATETIME DEFAULT NULL, `create_user` VARCHAR(32) DEFAULT NULL, `update_date` DATETIME DEFAULT NULL, `update_user` VARCHAR(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
编写json文件:
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "123456", "column": [ "id", "threshold_type", "threshold_name", "threshold_value" ], "splitPk": "id", "connection": [ { "table": [ "sys_complaint_threshold_value" ], "jdbcUrl": [ "jdbc:mysql://192.168.106.158:3306/complaint_report" ] } ] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS":"hdfs://hadoop1:9000", "fileType":"orc", "path":"/user/hive/warehouse/test_db.db/sys_complaint_threshold_value", "fileName":"sys_complaint_threshold_value", "column":[ { "name":"id", "type":"BIGINT" }, { "name":"threshold_type", "type":"STRING" }, { "name":"threshold_name", "type":"STRING" }, { "name":"threshold_value", "type": "INT" } ], "writeMode": "append", "fieldDelimiter": "\t", "compress":"NONE" } } } ] } }
然后执行datax命令:
cd /home/installed/datax/bin/ python datax.py /home/test/dataxtest/mysql2hdfs.json
然后到hive中查看状态:
hive> use test_db; OK Time taken: 0.045 seconds hive> drop table if exists sys_complaint_threshold_value; OK Time taken: 1.739 seconds hive> CREATE TABLE `sys_complaint_threshold_value`( > `id` bigint, > `threshold_type` string, > `threshold_name` string, > `threshold_value` int > ) > ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' > STORED AS ORC; OK Time taken: 0.254 seconds hive> select * from sys_complaint_threshold_value; OK 5 tag 疑似虚假值 70 7 tag 职业索赔人值 81 8 tag 职业索赔人值 80 4 tag 聚类相关值 70 2 tag 疑似重复值 84 3 tag 聚类相关值 85 1 remind 疑似重复值 85 6 tag 重大风险值 60 Time taken: 0.221 seconds, Fetched: 8 row(s) hive>

