项目案例(爬取网易新闻)
案例需求
爬取网易新闻基于文字的新闻,板块包括国内、国际、军事、航空等四个板块
获取指定板块超链接
import scrapy class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['news.163.com'] start_urls = ['https://news.163.com/'] def parse(self, response): lis=response.xpath("//div[@class='ns_area list']/ul/li") indexs=[3,4,6,7] li_list=[] for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath("./a/@href").extract_first() title=li.xpath("./a/text()").extract_first() print(title+":"+url)
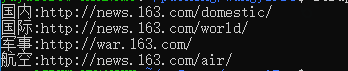
从页面中提取需要内容
此处并未提取到内容,因实际内容是动态加载的,所以直接用xpath解析不出内容


# -*- coding: utf-8 -*- import scrapy class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['news.163.com'] start_urls = ['https://news.163.com/'] def parse(self, response): lis=response.xpath("//div[@class='ns_area list']/ul/li") indexs=[3,4,6,7] li_list=[] for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath("./a/@href").extract_first() title=li.xpath("./a/text()").extract_first() print(title+":"+url) #对每个板块对应的url发起请求,获取页面数据(标题,缩略图,关键字,发布时间,url) yield scrapy.Request(url=url,callback=self.parseSecond) def parseSecond(self,response): div_list=response.xpath("//div[@class='data_row news_article clearfix']") for div in div_list: head=div.xpath(".//div[@class='news_title']/h3/a/text()").extract_first() url = div.xpath(".//div[@class='news_title']/h3/a/@href").extract_first() img_url=div.xpath("./a/img/@src").extract_first() tag=",".join(div.xpath(".//div[@class='news_tag']/div//text()")) time=div.xpath(".//div[@class='news_tag']/span/text()").extract_first()
重写中间件,使用浏览器进行数据下载
wangyi.py爬虫文件
# -*- coding: utf-8 -*- import scrapy from selenium import webdriver class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['news.163.com'] start_urls = ['https://news.163.com/'] def __init__(self): #实例化一个浏览器,只需要执行一次 self.bro=webdriver.Chrome(executable_path="/home/yaya/paChong/wangyiPro/wangyiPro/spiders/chromedriver.exe") def closed(self,spider): #实现父类方法,爬虫结束时调用 print("爬虫结束") self.bro.quit() def parse(self, response): lis=response.xpath("//div[@class='ns_area list']/ul/li") indexs=[3,4,6,7] li_list=[] for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath("./a/@href").extract_first() title=li.xpath("./a/text()").extract_first() #对每个板块对应的url发起请求,获取页面数据(标题,缩略图,关键字,发布时间,url) yield scrapy.Request(url=url,callback=self.parseSecond) def parseSecond(self,response): # div_list=response.xpath('//div[@class="data_row news_article clearfix"]')ndi_main div_list = response.xpath('//div[@class="ndi_main"]/div') print(len(div_list)) for div in div_list: head=div.xpath(".//div[@class='news_title']/h3/a/text()").extract_first() url = div.xpath(".//div[@class='news_title']/h3/a/@href").extract_first() img_url=div.xpath("./a/img/@src").extract_first() tag=",".join(div.xpath(".//div[@class='keywords']//a/text()").extract()) time=div.xpath(".//div[@class='news_tag']/span/text()").extract_first() print(head) print(url) print(img_url) print(tag) print(time)
重写下载中间件
from scrapy.http import HtmlResponse class WangyiproDownloaderMiddleware(object): def process_request(self, request, spider): return None #拦截到响应对象,即下载器传递给spider的响应对象 def process_response(self, request, response, spider): #request:响应对象对应的请求对象 #response:拦截到的响应对象 #spider:爬虫文件中对应的爬虫类实例 if request.url in ["http://news.163.com/domestic/","http://news.163.com/world/","http://war.163.com/","http://news.163.com/air/"]: spider.bro.get(url=request.url) page_text=spider.bro.page_source with open("./domestic.html","w",encoding="utf8") as fp: fp.write(page_text) #自己封装response,并返回 return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding="utf-8",request=request) else: return response
在配置文件中开启下载中间件
DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543, }
测试中间件作用情况:
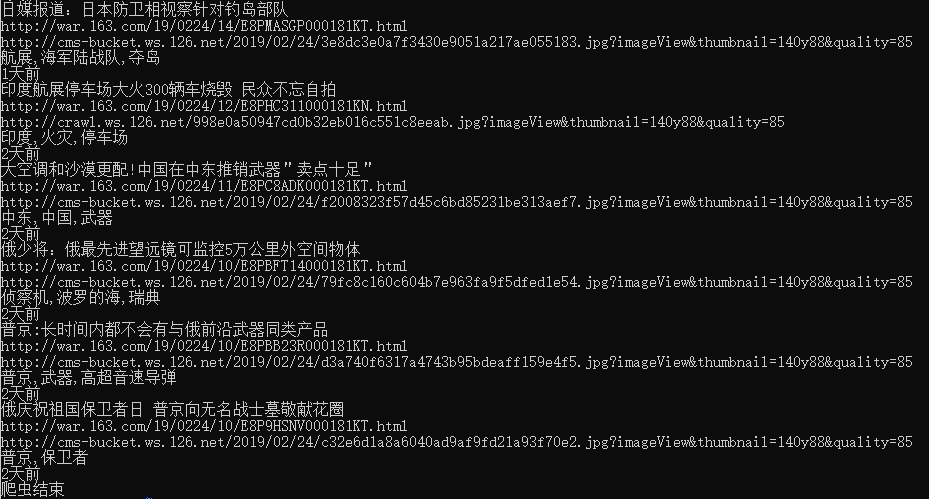
获取新闻内容
编写items.py,添加所需字段
import scrapy class WangyiproItem(scrapy.Item): head = scrapy.Field() tag = scrapy.Field() url = scrapy.Field() img_url = scrapy.Field() title=scrapy.Field() content=scrapy.Field()
爬虫文件中添加对应页面解析函数
import scrapy from selenium import webdriver from wangyiPro.items import WangyiproItem class WangyiSpider(scrapy.Spider): name = 'wangyi' #allowed_domains = ['news.163.com'] start_urls = ['https://news.163.com/'] def __init__(self): #实例化一个浏览器,只需要执行一次 self.bro=webdriver.Chrome(executable_path="/home/yaya/paChong/wangyiPro/wangyiPro/spiders/chromedriver.exe") def closed(self,spider): #实现父类方法,爬虫结束时调用 print("爬虫结束") self.bro.quit() def parse(self, response): lis=response.xpath("//div[@class='ns_area list']/ul/li") indexs=[3,4,6,7] li_list=[] for index in indexs: li_list.append(lis[index]) #获取四个板块中的链接和文字标题 for li in li_list: url=li.xpath("./a/@href").extract_first() title=li.xpath("./a/text()").extract_first() #对每个板块对应的url发起请求,获取页面数据(标题,缩略图,关键字,发布时间,url) yield scrapy.Request(url=url,callback=self.parseSecond,meta={"title":title}) def parseSecond(self,response): #解析每个类页面中的新闻链接和相关信息 div_list = response.xpath('//div[@class="ndi_main"]/div') for div in div_list: head=div.xpath(".//div[@class='news_title']/h3/a/text()").extract_first() url = div.xpath(".//div[@class='news_title']/h3/a/@href").extract_first() img_url=div.xpath("./a/img/@src").extract_first() tag=",".join(div.xpath(".//div[@class='keywords']//a/text()").extract()) time=div.xpath(".//div[@class='news_tag']/span/text()").extract_first() #实例化item对象,将解析到的值存储到item中 item=WangyiproItem() item["head"]=head item["url"]=url item["img_url"]=img_url item["tag"]=tag item["title"] = response.meta["title"] yield scrapy.Request(url=url,callback=self.getContent,meta={"item":item}) def getContent(self,response): #解析新闻文本内容 item=response.meta.get("item") content_list=response.xpath("//div[@class='post_text']/p/text()").extract() content="\n".join(content_list) item["content"]=content yield item
在pipelines文件中做输出测试
class WangyiproPipeline(object): def process_item(self, item, spider): print(item["title"]) print(item["content"]) return item
在setting中开启管道文件
ITEM_PIPELINES = { 'wangyiPro.pipelines.WangyiproPipeline': 300, }

JS动态加载更多数据
重写下载中间件,模拟浏览器滚动到最底部
class WangyiproDownloaderMiddleware(object): def process_request(self, request, spider): return None #拦截到响应对象,即下载器传递给spider的响应对象 def process_response(self, request, response, spider): #request:响应对象对应的请求对象 #response:拦截到的响应对象 #spider:爬虫文件中对应的爬虫类实例 if request.url in ["http://news.163.com/domestic/","http://news.163.com/world/","http://war.163.com/","http://news.163.com/air/"]: spider.bro.get(url=request.url) #将滚轮滚动到最底部 js="window.scrollTo(0,document.body.scrollHeight)" spider.bro.execute_script(js) #如果没有获取到更多的数据,这里给浏览器一定的加载时间 #time.sleep(3 page_text=spider.bro.page_source with open("./domestic.html","w",encoding="utf8") as fp: fp.write(page_text) #自己封装response,并返回 return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding="utf-8",request=request) else: return response

selenium应用到scrapy框架流程总结
- 在爬虫文件中导入webdriver类
- 在爬虫类的构造方法中,进行浏览器实例化操作,实例化一次即可
- 在爬虫类的closed方法中进行浏览器关闭操作
- 在下载中间件process_response方法中进行浏览器的自动化操作
基于RedisSpider分布式爬取
- 代码修改
- 导包from scrapy_redis.spiders import RedisSpider
- 将项目父类修改成RedisSpider
- 将起始URL列表注释,并添加一个redis_key的属性(调度队列的名称)
- redis数据库配置文件(redis.conf)修改
- 修改绑定地址bind 127.0.0.1,指定其他电脑可访问的地址
- 关闭保护模式protected-mode no
- 开启redis数据库服务 redis-server redis.conf
- 对项目settings.py进行配置
- 配置redis服务器的IP和端口REDIS_HOST="127.0.0.1",REDIS_PORT=6379
# 是否允许暂停,即程序意外宕机重启后从上次意外退出的地方重新爬取 SCHEDULER_PERSIST = True #Redis服务器地址,代码拷贝到其他服务器后,爬取的数据将保存到如下地址的redis服务器中 REDIS_HOST="192.168.1.1" #Redis服务器端口 REDIS_PORT=6379
- 修改默认调度器为可共享调度器和去重队列
# 使用scrapy-redis组件的去重队列进行去重操作 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler"
- 修改默认管道为可共享管道
#使用组件封装的管道,不使用原生的管道 ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300, }
- 配置redis服务器的IP和端口REDIS_HOST="127.0.0.1",REDIS_PORT=6379
- 执行爬虫文件scrapy runspider wangyi.py
- 向调度器队列中放入一个起始url
- 打开redis客户端
- 查看爬取数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号