

ELK
ELK简介
ELK 是三个开源软件的缩写,分别为:Elasticsearch、Logstash 以及 Kibana,它们都是开源软件。不过现在还新增了一个 Beats,它是一个轻量级的日志收集处理工具(Agent),Beats 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具,目前由于原本的 ELK Stack 成员中加入了 Beats 工具所以已改名为 Elastic Stack。
根据 Google Trend 的信息显示,Elastic Stack 已经成为目前最流行的集中式日志解决方案。
Elastic Stack 包含:
- Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 Elasticsearch 上去。
- Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats 在这里是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。
ELK Stack (5.0版本之后)--> Elastic Stack == (ELK Stack + Beats)。
目前 Beats 包含六种工具:
- Packetbeat: 网络数据(收集网络流量数据)
- Metricbeat: 指标(收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat: 日志文件(收集文件数据)
- Winlogbeat: windows 事件日志(收集 Windows 事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
ELK 简单架构图:

ElasticSearch:(存储数据信息,搜索组件)
由于elasticsearch是用Java语言编写的需要跑在Java虚拟机上,所以在安装elasticsearch之前需要安装Java的JDK包。版本至少要在1.80版本上的包。
#yum install java-1.8.0-openjdk-devel
官方软件下载:https://www.elastic.co/products
如果需要下载以前的版本点击下面。
ElasticSearch 5的程序环境
配置文件:
/etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/jvm.options /etc/elasticsearch/log4j2.properties Unit File:elasticsearch.service
程序文件:
/usr/share/elasticsearch/bin/elasticsearch /usr/share/elasticsearch/bin/elasticsearch-keystore: /usr/share/elasticsearch/bin/elasticsearch-plugin:管理插件程序
下载安装elasticsearch
#wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.10.rpm #下载rpm的包 #yum install java-1.8.0-openjdk-devel #安装JDK的包 #rpm -ivh elasticsearch-5.6.10.rpm #将下载下来的包安装,由于此包没有依赖所以使用rpm安装就可以 #systemctl start elasticsearch #启动服务 #/etc/elasticsearch/elasticsearch.ym #修改配置文件 测试使用,主要设置网络: network.host: 192.168.130.7 #本机Ip http.port: 9200 #监听端口
#vim /etc/elasticsearch/jvm.options
-Xms1g #虚拟机内存
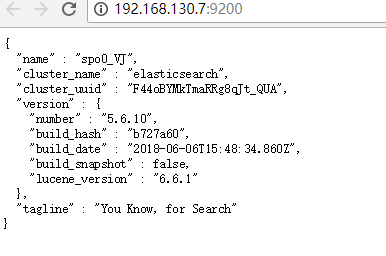
-Xmx1g # curl http://192.168.130.7:9200/ 测试
安装插件
使用git安装elasticsearch-head # yum install -y npm # git clone git://github.com/mobz/elasticsearch-head.git # cd elasticsearch-head # npm install # npm run start 检查端口是否起来 netstat -antp |grep 9100
浏览器访问测试是否正常 http://IP:9100/
实验:实现两个elasticsearch节点
nod01:(192.168.130.7)
#vim /etc/hostname #修改主机名 node1 #vim /etc/hosts #解析DNS 192.168.130.7 node1 #yum install java-1.8.0-openjdk-devel #安装JDK的包 #rpm -ivh elasticsearch-5.6.10.rpm #将下载下来的包安装,由于此包没有依赖所以使用rpm安装就可以 systemctl daemon-reload #包装好后执行此命令 vim /etc/elasticsearch/jvm.options #修改配置文件;jdk的配置文件 -Xms1g -Xmx1g #占用内存设置选项,两个的值必须设为相同 vim /etc/elasticsearch/elasticsearch.yml #修改主配置文件 cluster.name: myelssss #设定是否在同一个集群的标识;可自定义名称 node.name:node1 #当前节点的IP地址,此处做了dns解析可以用做节点的名称 #node.attr.rack: r1 (节点处于哪个机架上的设置,系统会识别机架,不将数据的主切片和从切片放到同一个机架上,本实验中不需要设置) path.data: /data/myels #数据存放的路径;可以自定义,或者将目录挂载到存储设备上 path.logs: /data/logs #日志存放的路径 network.host: 192.168.130.7 #当前主机的IP地址 http.port: 9200 #启用端口号 discovery.zen.ping.unicast.hosts: [“192.168.130.7″,http.port: 9200″192.168.130.8”] #定义集群的成员 discovery.zen.minimum_master_nodes: 2 #mkdir /data/myels #mkdir /data/logs #创建存放数据和日志的文件夹 #chown elasticsearch: /data/* #将刚创建的文件夹的属主和数组都改为elasticsearch所有 #systemctl start elasticsearch #启动服务
nod02:(192.168.130.8)
#vim /etc/hostname #修改主机名 node2 #vim /etc/hosts #解析DNS 192.168.130.8 node2 #yum install java-1.8.0-openjdk-devel #安装JDK的包 #rpm -ivh elasticsearch-5.6.10.rpm #将下载下来的包安装,由于此包没有依赖所以使用rpm安装就可以 systemctl daemon-reload #包装好后执行此命令 vim /etc/elasticsearch/jvm.options #修改配置文件;jdk的配置文件 -Xms1g -Xmx1g #占用内存设置选项,两个的值必须设为相同 vim /etc/elasticsearch/elasticsearch.yml #修改主配置文件 cluster.name: myelssss #设定是否在同一个集群的标识;可自定义名称 node.name:node1 #当前节点的IP地址,此处做了dns解析可以用做节点的名称 #node.attr.rack: r1 (节点处于哪个机架上的设置,系统会识别机架,不将数据的主切片和从切片放到同一个机架上,本实验中不需要设置) path.data: /data/myels #数据存放的路径;可以自定义,或者将目录挂载到存储设备上 path.logs: /data/logs #日志存放的路径 network.host: 192.168.130.8 #当前主机的IP地址 http.port: 9200 #启用端口号 discovery.zen.ping.unicast.hosts: [“192.168.130.8″,http.port: 9200″192.168.130.7”] #定义集群的成员 discovery.zen.minimum_master_nodes: 2 #mkdir /data/myels #mkdir /data/logs #创建存放数据和日志的文件夹 #chown elasticsearch: /data/* #将刚创建的文件夹的属主和数组都改为elasticsearch所有 #systemctl start elasticsearch #启动服务
下载并安装Logstach(高度插件化服务程序)
官网:https://www.elastic.co/products/logstash
集中,转换,存储
高度插件化程序
三类核心插件:输入插件(指定数据源抽取数据),过滤器插件,输出插件(处理后的结果保留到不同位置)
多个logstash从本地日志文件中收集日志-->可在此添加消息队列-->发送到logstash server(过滤器插件过滤)-->elasticsearch
三类插件
- Input plugins(获取数据)
- Output plugins(保存数据位置)
- Filter plugins(不同数据加工功能)
- Grok filter plugin(非文档转换为文档格式,日志就不是K/V键值对格式)

# yum install java-1.8.0-openjdk-devel #下载JDK # wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.8.rpm #下载相关包 # rpm -ivh logstash-5.6.8.rpm #安装logstash /usr/share/logstash默认路径 #vim /etc/profile.d/logstash.sh #路径加载到系统环境搜索变量中 export PATH=/usr/share/logstash/bin :$PATH #exec bash #重行启动bash #logstash --help #启动很慢 #cd /etc/logstash #vim /conf.d/test1.conf #编辑测试配置文件,输入什么输出什么 input { stdin{} } output { stdout{ } } #logstash -f test.conf -t #指定配置文件并检查 #logstash -f test.conf #启动
kibana下载安装
自我独立的web服务器
默认监听端口:5600
工作与http协议
搜索,数据聚合
图形界面展示
# wget ftp://172.20.0.1/pub/Sources/7.x86_64/elasticstack/kibana-5.6.8-x86_64.rpm #下载相关包 # rpm -ivh kibana-5.6.8-x86_64.rpm #安装kibana # cd /etc/kibana/ /etc/kibana]# ls kibana.yml /etc/kibana]# vim kibana.yml #修改配置文件 server.port: 5601 #监听于5601 server.host: "0.0.0.0" #监听本机所有地址 elasticsearch.url: "http://172.20.81.7:9200" #elasticsearch所在主机
http://172.20.81.81:5601进入图形界面配置
页面使用:Discover
可视化:Visualize
面板:Dashboard
filebeat
rides在中间做消息队列

