

Python--scikit-learn
数据集 sklearn.datasets
- from sklearn.datasets import load_iris, fetch_20newsgroups
- 小数据集下载 load_xxx
- 大数据集下载 fetch_xxx
模型
KNN K-近邻算法
- 参考
- 距离计算
- k值选择
- kd树
- 维度:选择(剩余维度)方差大的维度
- 数据划分:选择当前维度的中位数,小于中位数的放左边,大于中位数的放右边
- from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
# 构造数据
x = [[1], [2], [10], [20]]
y = [0, 0, 1, 1]
# 训练模型
estimator = KNeighborsClassifier(n_neighbors=1)
estimator.fit(x, y)
# 数据预测
ret = estimator.predict([[0], [14]])
print('result: ', ret)
- 案例1
import pprint
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 获取数据 load_xxx
iris = load_iris()
# pprint.pprint(iris)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=1)
# 特征工程:对数据进行标准化处理
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 创建模型算法实例, knn
knn = KNeighborsClassifier(n_neighbors=5)
# 使用模型训练
knn.fit(x_train, y_train)
# 对测试集进行预测
y_predict = knn.predict(x_test)
print('预测结果:')
print(y_predict == y_test)
# 计算预测准确率
score = accuracy_score(y_test, y_predict)
# score = knn.score(x_test, y_test)
print('准确率:', score)
- 案例2 使用交叉验证
import pprint
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 获取数据 load_xxx
iris = load_iris()
# pprint.pprint(iris)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=1)
# 特征工程:对数据进行标准化处理
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 创建模型算法实例, knn
knn = KNeighborsClassifier()
# 指定超参数
param_grid = {'n_neighbors': [5, 1, 3]}
# 使用交叉验证
gs_cv = GridSearchCV(knn, param_grid=param_grid, cv=5)
# 使用模型训练
gs_cv.fit(x_train, y_train)
# 对测试集进行预测
y_predict = gs_cv.predict(x_test)
print('预测结果:')
print(y_predict == y_test)
# 计算预测准确率
score = gs_cv.score(x_test, y_test)
print('准确率:', score)
print('交叉验证最好的准确率:', gs_cv.best_score_)
print('交叉验证最好准确率的模型:', gs_cv.best_estimator_)
print('交叉验证过程中所有结果:')
pprint.pprint(gs_cv.cv_results_)
线性回归
-
from sklearn.linear_model import LinearRegression, SGDRegressor
- LinearRegression 使用的是正规方程
- coef_ 求得的线性回归系数
- intercept_ 偏置
- SGDRegressor 使用的是随机梯度下降
- LinearRegression 使用的是正规方程
-
岭回归
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
- 具有l2正则化的线性回归
- alpha:正则化力度,也叫 λ
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
- solver: 会根据数据自动选择优化方法
- sag: 如果数据集、特征都比较大,选择该随机梯度下降优化(SAG)
- normalize: 数据是否进行标准化
- normalize=False: 可以在fit之前调用preprocessing.StandardScaler标准化数据
- Ridge.coef_: 回归权重
- Ridge.intercept_: 回归偏置
- 相当于SGDRegressor(penalty='l2', loss="squared_loss"),不过SGDRegressor使用的优化方法是SGD,而Ridge可以使用SAG
- sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正则化的线性回归,可以进行交叉验证
- coef_: 回归系数
-
损失函数
-
优化方法
- 正规方程:使用公式直接计算系数W,适用于小规模数据
- 梯度下降:不断迭代计算,不一定能得到准确系数,适用于大规模数据
- 损失函数
- 学习率
- 全梯度下降算法(Full gradient descent),
- 随机梯度下降算法(Stochastic gradient descent),
- 小批量梯度下降算法(Mini-batch gradient descent),
- 随机平均梯度下降算法(Stochastic average gradient descent)
-
拟合
- 欠拟合
- 在训练集上表现不好,在测试集上表现不好
- 解决方法:
- 添加其他特征项
- 添加多项式特征
- 过拟合
- 在训练集上表现好,在测试集上表现不好
- 解决方法:
- 重新清洗数据集
- 增大数据的训练量
- 正则化
- 减少特征维度
- 正则化
- 通过限制高次项的系数进行防止过拟合
- L1正则化
- 理解:直接把高次项前面的系数变为0
- Lasso回归
- L2正则化
- 理解:把高次项前面的系数变成特别小的值
- 岭回归
- 正则化线性模型
- Ridge Regression 岭回归
- Lasso 回归
- Elastic Net 弹性网络
- Early stopping
- 欠拟合
-
简单案例
from sklearn.datasets import load_iris
from sklearn.metrics import mean_squared_error, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
import joblib
def liner_demo():
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.fit_transform(x_test)
# estimator = LinearRegression()
estimator = SGDRegressor()
estimator.fit(x_train, y_train)
log(estimator, x_test, y_test)
# 保存模型
joblib.dump(estimator, 'iris_linear_demo.pkl')
# 加载模型
estimator_loaded = joblib.load('iris_linear_demo.pkl')
log(estimator_loaded, x_test, y_test)
def log(estimator, x_test, y_test):
print('回归系数:', estimator.coef_)
print('偏置:', estimator.intercept_)
# 预测
y_predict = estimator.predict(x_test)
print('预测结果:', y_predict)
# 计算误差
error = mean_squared_error(y_test, y_predict)
print('误差:', error)
liner_demo()
逻辑回归
- 实际是一个二分类模型
- 逻辑回归的输入是线性回归的输出
- 激活函数 sigmoid函数
- 把整体的值映射到[0,1]
- 再设置一个阈值,进行分类判断
- 损失函数
- 对数似然损失函数
- 真实值分为0、1两种
- 优化:提升原本属于1类别的概率,降低原本是0类别的概率
- sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C = 1.0)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 默认: 'liblinear';用于优化问题的算法。
- 对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
- 对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
- penalty:正则化的种类
- C:正则化力度
- LogisticRegression方法相当于 SGDClassifier(loss="log", penalty=" "),SGDClassifier实现了一个普通的随机梯度下降学习。而使用LogisticRegression(实现了SAG)
- solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
- 分类评估
- 混淆矩阵
- TP FN
- FP TN
- TP:预测为正样本,实际为正样本 (猜对了)
- FN:预测为负样本,实际为正样本 (猜错了)
- FP:预测为正样本,实际为负样本 (猜错了)
- TN:预测为负样本,实际为负样本 (猜对了)
- TP + TN 就是预测正确的数量
- 准确率(对不对):(TP + TN) / (TP + FN + FP + TN)
- 精确率(准不准):TP / (TP + FP)
- 召回率(全不全):TP / (TP + FN)
- F1-score:反映模型的稳健性
- roc曲线和auc指标
- roc曲线
- 通过tpr和fpr来进行图形绘制,然后绘制之后,行成一个指标auc
- TPR: TP / (TP + FN)
- FPR: FP / (FP + TN)
- auc (范围:0 ~ 1)
- Area Under roc Curve, 就是ROC曲线的积分,也是ROC曲线下面的面积
- 越接近1,效果越好
- 越接近0,效果越差
- 越接近0.5,效果就是胡说
- from sklearn.metrics import roc_auc_score
- roc_auc_score(y_true, y_score)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
- y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
- 注意:
- 这个指标主要用于评价不平衡的二分类问题
- roc曲线
- 混淆矩阵
- 处理样本不平衡问题
- 过拟合:通过过采样(oversampling)增加样本较少的类别的样本数量
- 随机过采样:随机复制已有样本
- SMOTE(Synthetic Minority Oversampling Technique, 合成少数类过采样技术): 取两点直线之间的点作为新样本
- 欠拟合:通过欠采样(under_sample)减少样本较多的类别的样本数量
- 随机欠采样
- pip install imbalanced-learn
- 随机过采样:from imblearn.over_sampling import RandomOverSampler
- SMOTE: from imblearn.over_sampling import SMOTE
- 随机欠采样:from imblearn.under_sampling import RandomUnderSampler
- 过拟合:通过过采样(oversampling)增加样本较少的类别的样本数量
决策树
- 一棵由多个判断节点组成的树
- sklearn.tree.DecisionTreeClassifier(criterion='gini', max_depth=None, random_state=None)
- 到处文件,可用于可视化决策树:sklearn.tree.export_graphviz(estimator, out_file='tree.dot', feature_names=['特征1', '特征2', ...])
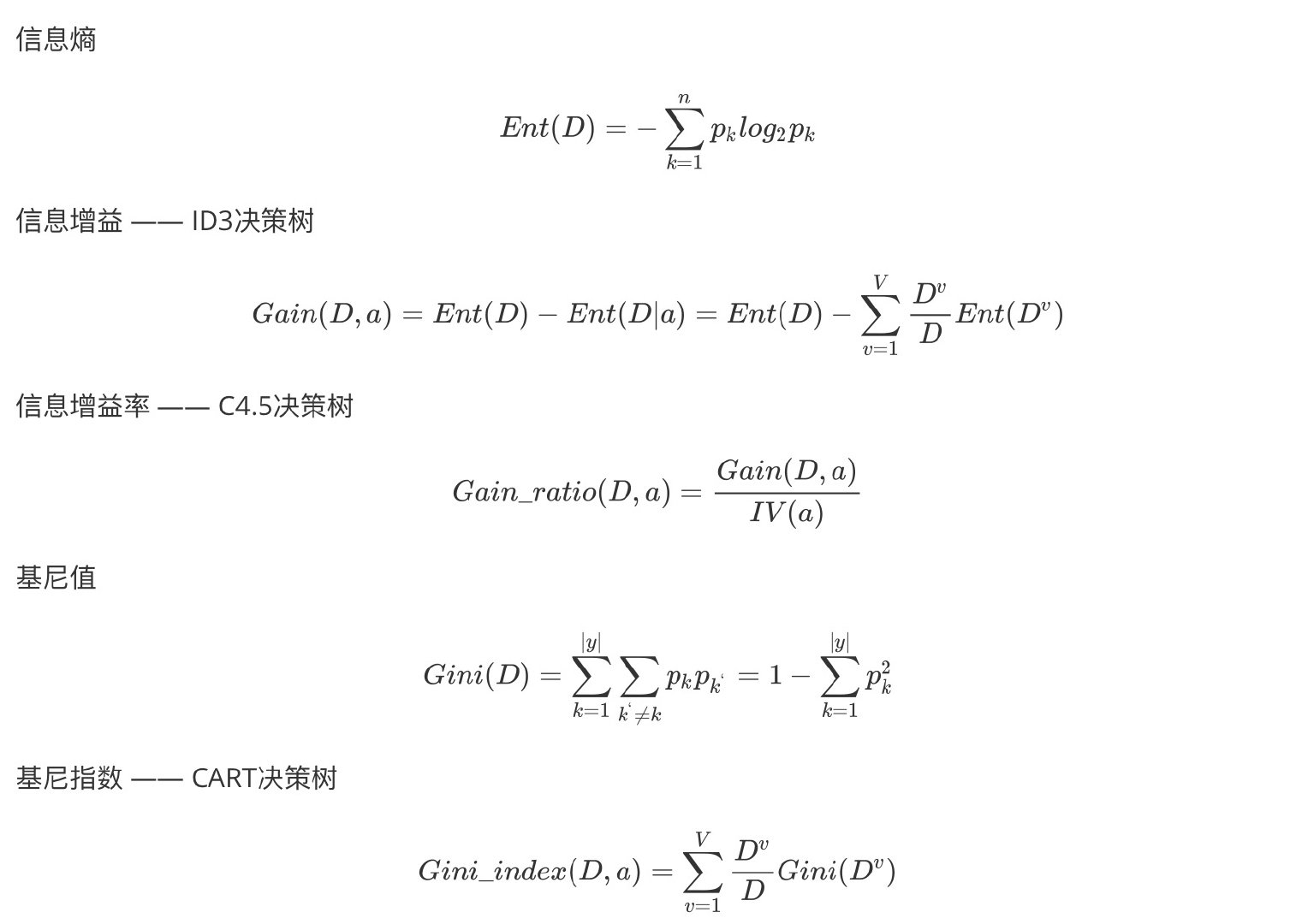
熵
- 越有序或越集中,熵值越低;越混乱或者分散,熵值越高。
- 信息增益
- 以某特征划分数据集前后的熵的差值
- 熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合的划分效果的好坏
- 信息增益越大,使用对于特征划分集合效果越明显
- 信息增益就是ID3算法的特征选择指标
- 信息增益率
- 信息增益Gain(D, a)和属性a对应的"固有值"(intrinsic value) 比值:Gain(D, a) / IV(a)
- C4.5 决策树算法 使用信息增益率来选择最优划分属性,使用后剪枝
- 基尼指数
- CART 决策树使用"基尼指数" (Gini index)来选择划分属性
- CART 是Classification and Regression Tree的简称,这是一种著名的决策树学习算法,分类和回归任务都可用
- 二叉树模型
- 基尼值 Gini(D)
- 基尼指数 Gini_index(D)
- Gini(D)值越小,数据集D的纯度越高
- 一般,选择使划分后基尼系数最小的属性作为最优化分属性
- CART 决策树使用"基尼指数" (Gini index)来选择划分属性
剪枝
- 剪枝原因【了解】
- 噪声、样本冲突,即错误的样本数据
- 特征即属性不能完全作为分类标准
- 巧合的规律性,数据量不够大。
- 预剪枝
- 在构建树的过程中,同时剪枝
- 限制节点最小样本数
- 指定数据高度
- 指定熵值的最小值
- 在构建树的过程中,同时剪枝
- 后剪枝
- 把一棵树,构建完成之后,再进行从下往上的剪枝,需要较大内存开销
特征工程
- 将任意数据(如文本或图像)转换为可用于机器学习的数字特征
- 特征提取分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取
- 字典特征提取:sklearn.feature_extraction.DictVectorizer
- 文本特征提取
- 词频特征(英文):sklearn.feature_extraction.text.CountVectorize
- 处理中文,需要先对每篇文章用jieba库进行分词,然后对得到的词列表用空格进行拼接,后面词频特征就跟英文一样了
- tfidf: sklearn.feature_extraction.text.TfidfVectorizer
- tf: 词频,某一个给定的词语在该文件中出现的比率
- idf: 逆向文档频率,由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
- tfidf = tf * idf
回归决策树
- from sklearn.tree import DecisionTreeRegressor
- 在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树
集成学习
-
通过建立几个模型来解决单一预测问题
-
机器学习两个核心任务【知道】
- 1.解决欠拟合问题
- 弱弱组合变强
- boosting
- 2.解决过拟合问题
- 互相遏制变壮
- Bagging
- 1.解决欠拟合问题
-
bagging集成过程【知道】
- Bagging + 决策树/线性回归/逻辑回归/深度学习…
- 步骤
- 1.采样 — 从所有样本里面,采样一部分
- 2.学习 — 训练弱学习器
- 3.集成 — 使用平权投票
-
boosting
- 随着学习的积累从弱到强
- 代表算法:Adaboost,GBDT,XGBoost,LightGBM
-
bagging和boosting的区别
- 区别一:数据方面
- Bagging:对数据进行采样训练;
- Boosting:根据前一轮学习结果调整数据的重要性。
- 区别二:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进行加权投票。
- 区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行,学习有先后顺序。
- 区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
- Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
- 区别一:数据方面
-
随机森林
- 随机森林 = Bagging + 决策树
- sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- 流程:
- 1.随机选取m条数据
- 2.随机选取k个特征
- 3.训练决策树
- 4.重复1-3
- 5.对上面的若决策树进行平权投票
- 注意:
- 1.随机选取样本,且是有放回的抽取
- 2.选取特征的时候吗,选择m<<M
- M是所有的特征数
- 包外估计
- 如果进行有放回的对数据集抽样,会发现,总是有一部分样本选不到;
-
GBDT Gradient Boosting Decision Tree,梯度提升树
聚类算法
-
一种典型的无监督学习算法,
-
主要用于将相似的样本自动归到一个类别中
-
计算样本和样本之间的相似性,一般使用欧式距离
-
sklearn.cluster.KMeans(n_clusters=8)
- K : 初始中心点个数(计划聚类数)
- means:求中心点到其他数据点距离的平均值
- 步骤:
- 随机设置K个特征空间内的点作为初始的聚类中心;
- 对于其他每个点计算到K个中心的距离(一般为欧式距离),未知的点选择最近的一个聚类中心点作为标记类别,
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值),
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程。
- 注意:
- 由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢
- 优点:
- 1.原理简单(靠近中心点),实现容易
- 2.聚类效果中上(依赖K的选择)
- 3.空间复杂度o(N),时间复杂度o(IKN)
- 缺点:
- 1.对离群点,噪声敏感 (中心点易偏移)
- 2.很难发现大小差别很大的簇及进行增量计算
- 3.结果不一定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
-
kmean的优化方法
| 优化方法 | 思路 |
| ------------------ | ----------------- |
| Canopy+kmeans | Canopy粗聚类配合kmeans |
| kmeans++ | 距离越远越容易成为新的质心 |
| 二分k-means | 拆除SSE最大的簇 |
| k-medoids | 和kmeans选取中心点的方式不同 |
| kernel kmeans | 映射到高维空间 |
| ISODATA | 动态聚类,可以更改K值大小 |
| Mini-batch K-Means | 大数据集分批聚类 | -
评估方法:from sklearn.metrics import calinski_harabaz_score
- sse The sum of squares due to error
- 误差平方和的值越小越好
- 肘部法 Elbow method
- 下降率突然变缓时即认为是最佳的k值
- SC系数 Silhouette Coefficient 凝聚度(Cohesion)和分离度(Separation)
- 取值为[-1, 1],其值越大越好
- CH系数 Calinski-Harabasz Index
- 分数s高则聚类效果越好
- CH需要达到的目的:用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
- sse The sum of squares due to error
-
特征降维
- 在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
- 降维的两种方式
- 特征选择
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数:皮尔逊相关系数,斯皮尔曼相关系数
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 主成分分析
- 特征选择
- 低方差特征过滤
- 把方差比较小的列进行剔除
- api:sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- 删除所有低方差特征
- 注意,参数threshold一定要进行值的指定
- 皮尔逊相关系数
- 通过具体值的大小进行计算
- 相对复杂
- api:from scipy.stats import pearsonr
- 返回值,越接近|1|,相关性越强;越接近0,相关性越弱
- 斯皮尔曼相关系数
- 通过等级差进行计算
- 比皮尔逊相关系数简单
- api:from scipy.stats import spearmanr
- 返回值,越接近|1|,相关性越强;越接近0,相关性越弱
- pca 主成分分析
- 定义:高维数据转换为低维数据,然后产生了新的变量
- api:sklearn.decomposition.PCA(n_components=None)
- n_components
- 整数 -- 表示降低到几维
- 小数 -- 保留百分之多少的信息
- n_components
朴素贝叶斯算法
- 联合概率:包含多个条件,且所有条件同时成立的概率
- 记作:P(A,B)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
- 记作:P(A|B)
- 相互独立:如果P(A, B) = P(A)P(B),则称事件A与事件B相互独立。
- 贝叶斯公式
- P(A|B) = P(B|A) * P(A) / P(B)
- 朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式
- 拉普拉斯平滑系数α,避免出现概率为0的情况
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
SVM 支持向量机 (supported vector machine)
- SVM是一种二类分类模型
- 它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器
- 1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
- 2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
- 3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机
- 硬间隔
- 只有在数据是线性可分离的时候才有效
- 对异常值非常敏感
- 软间隔
- 尽可能在保持最大间隔宽阔和限制间隔违例之间找到良好的平衡
- C值越大,惩罚力度越大,间隔宽度越小,间隔违例数量越少
- C值越小,惩罚力度越小,间隔宽度越大,间隔违例数量越多
- from sklearn.svm import SVC
- SVM的损失函数
- 0/1损失函数
- Hinge损失函数
- Logistic损失函数
- 核函数
- 将原始输入空间映射到新的特征空间,从而,使得原本线性不可分的样本可能在核空间可分。
- 常见核函数
- 线性核
- 多项式核
- RBF核(高斯核)常用
- Sigmoid核
- SVM回归是让尽可能多的实例位于预测线上,同时限制间隔违例(也就是不在预测线距上的实例)。
- klearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC,扩展为三个支持向量回归方法:SVR、NuSVR、LinearSVR
- SVM的优点:
- 在高维空间中非常高效;
- 即使在数据维度比样本数量大的情况下仍然有效;
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的;
- 通用性:不同的核函数与特定的决策函数一一对应;
- SVM的缺点:
- 如果特征数量比样本数量大得多,在选择核函数时要避免过拟合;
- 对缺失数据敏感;
- 对于核函数的高维映射解释力不强
EM算法 Expectation-Maximum 期望最大化
- 它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM)等等。
- 最初是为了解决数据缺失情况下的参数估计问题
- EM算法是一种迭代优化策略,它的计算方法中每一次迭代都分两步:
- 其中一个为期望步(E步)
- 另一个为极大步(M步)
- 极大似然估计
- 根据已知条件,通过极大似然估计,求出未知参数;
- 极大似然估计就是用来估计模型参数的统计学方法。
- EM算法基本流程
- 1) 初始化参数;
- 2) 计算分布;
- 3) 重新估计参数;
- 4) 重复1-3步,直到参数不发生变化为止
HMM 隐马尔可夫模型(Hidden Markov Model)
- 是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程
- 其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别
- 马尔科夫链
- 状态空间中从一个状态到另一个状态转换的随机过程
- 该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
- 什么样的问题可以用HMM模型解决
- 基于序列的,比如时间序列;
- 问题中包含两类数据,一类是可以观测到的观测序列;另一类是不能观察到的隐藏状态序列。
- HMM模型的两个重要假设
- 齐次马尔科夫链假设
- 观测独立性假设
- HMM模型的三个基本问题
- 评估观察序列概率:前向后向的概率计算
- 预测问题,也称为解码问题维特:比(Viterbi)算法
- 模型参数学习问题:鲍姆-韦尔奇(Baum-Welch)算法
- pip install hmmlearn
- GaussianHMM和GMMHMM是连续观测状态的HMM模型
- MultinomialHMM是离散观测状态的模型, 可以使用MultinomialHMM模型实现维特比算法
- "startprob_"参数对应我们的隐藏状态初始分布Π,
- "transmat_"对应我们的状态转移矩阵A,
- "emissionprob_"对应我们的观测状态概率矩阵B。
- score() 得到前向算法的概率的以自然对数为底的对数,可以使用math.exp(score)得到具体的概率值
XGBoost Extreme Gradient Boosting 极端梯度提升树
- XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost
- XGBoost在绝大多数的回归和分类问题上表现的十分顶尖
- pip install xgboost
lightGBM
- 基于Histogram(直方图)的决策树算法
- Lightgbm 的Histogram(直方图)做差加速
- 带深度限制的Leaf-wise的叶子生长策略
- 直接支持类别特征
- 直接支持高效并行
训练
-
步骤:
1.获取数据
2.数据基本处理
2.1 确定特征值,目标值
2.2 缺失值处理
2.3 数据集划分
3.特征工程(字典特征抽取)
4.机器学习(使用各种算法进行训练,比如:决策树)
5.模型评估 -
数据集划分:
- from sklearn.model_selection import train_test_split, LeaveOneOut, KFold, StratifiedKFold
- LeaveOneOut 留一法
- 分层采样的KFold,分层采样,即训练集,测试集中每种类别的数据的占比与整体数据中的占比保持一致
-
特征工程
- 通过一些转换函数将特征数据转换成更加适合算法模型的特征数据的过程
- 归一化:通过对原始数据进行变换,把数据映射到一个区间内,默认是[0, 1]
- from sklearn.preprocessing import MinMaxScaler
- 转换方法:fit_transform()
- 标准化:通过对原始数据进行变换,把数据变换到均值为0,标准差为1的数据
- from sklearn.preprocessing import StandardScaler
- 转换方法:fit_transform()
- x` = x - mean / σ
- from sklearn.preprocessing import StandardScaler
-
交叉验证
- 训练集再次划分为:训练集+验证集
-
网格搜索
- 超参数,比如knn的k
- from sklearn.model_selection import GridSearchCV
-
模型保存和加载
- 旧版本的scikit-learn是:sklearn.externals import joblib
- 保存:joblib.dump(estimator, '模型文件名称.pkl')
- 加载:estimator = joblib.load('模型文件名称.pkl')
- 新版本的scikit-learn没有joblib模块了,需要安装独立的joblib包
- pip install joblib
- 旧版本的scikit-learn是:sklearn.externals import joblib

