爬虫--汇总
基础知识
IO编程
进程、线程、协程
网络编程
HTTP/HTTP
HTML
CSS
JavaScript
技能
表单参数加密
各种验证码
IP封禁
字体反爬
Cookie检测,账号封禁
人机检测
抓取
一般就是进行http请求,为了欺骗对方服务器,需要尽可能的模拟人类使用浏览器的行为。这里就涉及到一些点:User-Agent,Cookie,同一个IP访问频率等。
发起http请求的库有:urllib2/urllib;httplib/urllib;Requests。其中Requests是第三方库,比较常用。
抓取的内容:网页,图片,音频,视频等。
动态网站的抓取:这类网站通过ajax技术来获取数据,然后再把数据加载到页面中。因此,直接抓取浏览器上输入的网址是获取不到数据的。一般通过以下方式进行抓取:1)直接从javascript中采集加载的数据;2)直接加载浏览器中已经加载好的数据。
直接从javascript中采集加载的数据就需要再到ajax请求,然后分析请求参数特征,手动构造参数进行数据请求,分析返回结果,提取出有效数据。这种方式难点在于参数的构造,现在很多网站还对参数进行了加密处理,构建难度很大,需要有一地的js逆向功底才有可能破解。这种方式的优点是效率快。
直接加载浏览器中已经加载好的数据,这种方式就是通过第三方模块模拟浏览器或者操作浏览器完成页面加载后,直接从页面的html中提取有效数据。常用模块有PhantomJS,Selenium。
PhantomJS是一个基于WebKit的服务器端JavaScript API,原生支持各种Web标准:DOM处理,CSS选择器,JSON,Canvas和SVG,一个真正的布局和渲染引擎,可以看作是一个没有界面的浏览器。可用于页面自动化、网络检测、页面截屏和无界面测试等。有浏览器的功能,有因为没有界面而更加快速,占更小的内存。
Selenium可以对浏览器进行控制,包括Chrome,Safari,Firefox,PhantomJS等。Python+Selenium+PhantomJS组合,PhantomJS负责渲染解析JavaScript,Selenium负责驱动浏览器与Python对接,Python负责做后期处理。
PhantomJS
Selenium
PC端和移动端应用的抓取
Http Analyzer
一款实时捕捉分析HTTP/HTTPS协议数据的工具。
Wireshark
捕捉机器上的某一网卡的网络包。
Charles
mitmprox、mitmdump、mitmweb
appium
解析

XPath
CSS选择器
正则
JSON
BeautifulSoup4
html解析模块,支持多种解析器

安装:pip install beautifulsoup4
使用:from bs4 import BeautifulSoup
lxml
安装:pip install lxml
使用:from lxml import etree
使用XPath进行解析。
存储
JSON文件
CSV文件
媒体文件
可使用urllib.urlretrieve函数下载文件并保存到本地目录。
Email提醒
SQLite
MySQL
MongoDB

分析
分布式
Redis
scrapy_redis
MongoDB集群
框架
Scrapy
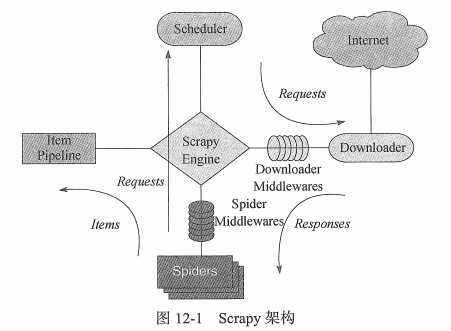
通过命令创建项目:
scrapy startproject 项目名称
切换到项目目录
scrapy genspider 爬虫名称 域名
爬虫类继承scrapy.Spider
默认是通过start_urls指定初始请求。可以通过覆盖start_requests(sefl)方法,定制初始请求。
可以使用xpath,css选择器,正则进行解析。
PySpider
案例
微信朋友圈
使用appium采集朋友圈数据
京东app
mitmdum、appium配合采集商品和评论数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号