Python学习笔记——基础篇【第二周】——解释器、字符串、列表、字典、主文件判断、对象
目录
1、Python介绍
2、Python编码
3、接受执行传参
4、基本数据类型常用方法
5、Python主文件判断
6、一切事物都是对象
7、 int内部功能介绍
8、float和long内部功能介绍
9、str内部功能介绍
10、上下文管理剖析
11、list内部功能介绍
12、tuple内部功能介绍
13、字典和列表
1、python介绍
| pyhton | 编译 | 执行 | 速度 | |
| cpython | print("alex xx") | c解释器 .pyc(字节码) | 机器码 cpu | |
| jphthon | print("alex xx") | java解释器 Java字节码 | 机器码 cpu | |
| irongpython | print("alex xx") | C#解释器 C#字节码 | 机器码 cpu | |
| pypy | print("alex xx") | 解释器 字节码 机器码 | cpu | 最快 |
注释:
1、代码执行的时候分两步:1、编译2、执行
2、pypy会在编译的时候直接把解释器+字节码+机器码一气合成直接进行完,所以在执行的时候回非常快
值得推荐的一本书:《python源码剖析》
解释器
上一步中执行 python /home/dev/hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
|
1
2
3
|
#!/usr/bin/env pythonprint "hello,world" |
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
2、python编码
ascii 2**8
unicode 2**16 至少16位
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...

3、接收执行传参(执行脚本传入参数)
引入模块
import sys (可以理解为python所有跟解释器相关的功能模块在sys.py里)
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
|
1
2
3
4
5
6
|
#!/usr/bin/env python# -*- coding: utf-8 -*-import sysprint sys.argv |
4、基本数据类型常用方法
字符串常用方法
| 字符串功能 | 用法 |
| 移除空白 | strip |
| 分割 | split |
| 长度 | len(obj) |
| 索引 | obj[1] |
| 切片 | obj[1:],obj[1:10] |
列表常用方法
l1 = [1,2,3,4,5]
l1 = list(1,2,3,4,5)
索引 index
切片 :
追加 append
删除 del remove pop
长度 len
循环 for, while(foreach)
break;continue;pass;return;exit
break 结束整个循环
continue 结束本次循环
pass 占位
return 针对方法和函数,终止
exit 程序整个退出
包含 “Alex” in ["shuaige"],
元祖:元祖的元素不可以修改
(11,22,33,44)
(11,22,{“k1”:"v1"})
元祖的元素的元素可以修改
t1 = (1,2,{"k1":"v1"})
del t1[0]
t1[1]=1
t1[2]["k1"]=2
print(t1)
创建元祖:
|
1
2
3
|
ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55)) |
字典
索引
新增 d[key] xx
删除 del d[key]
键、值、键值对
keys values items
for i in dict
循环
长度
5、python主文件判断
def f1()
pass
def f2()
pass
if __name__=="__main__":
f1()
python index.py

6、一切事物都是对象

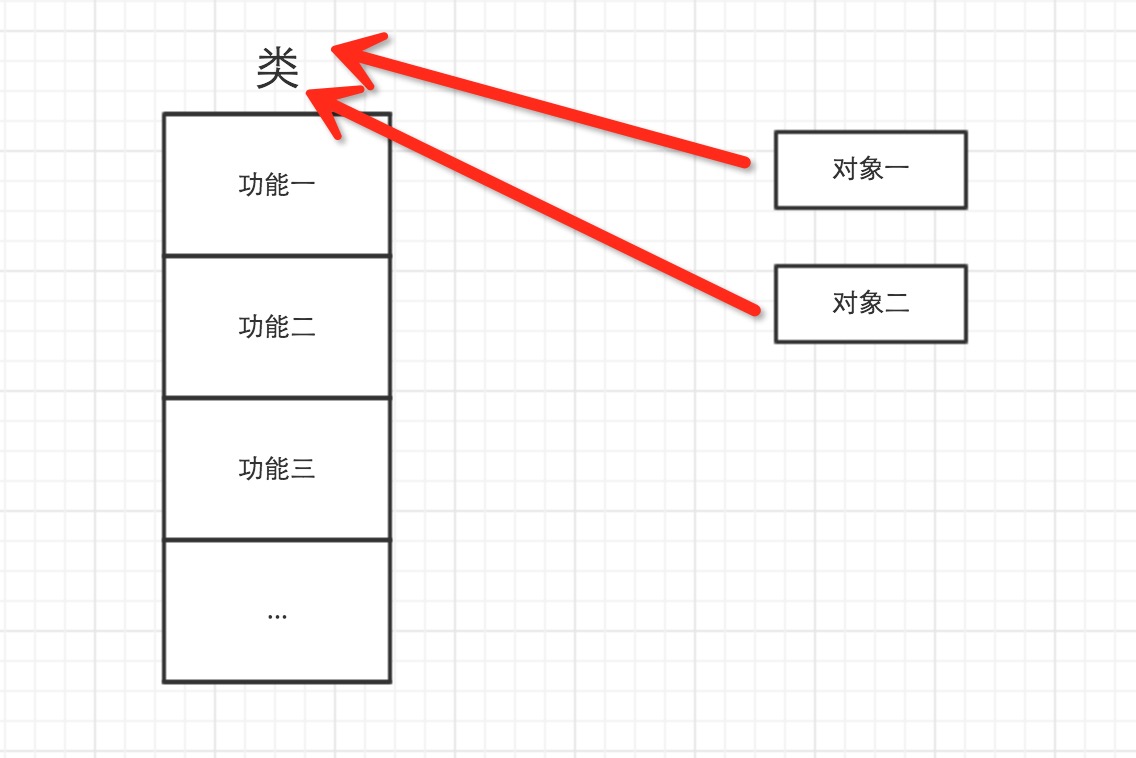
所以,以下这些值都是对象: "wupeiqi"、38、['北京', '上海', '深圳'],并且是根据不同的类生成的对象。
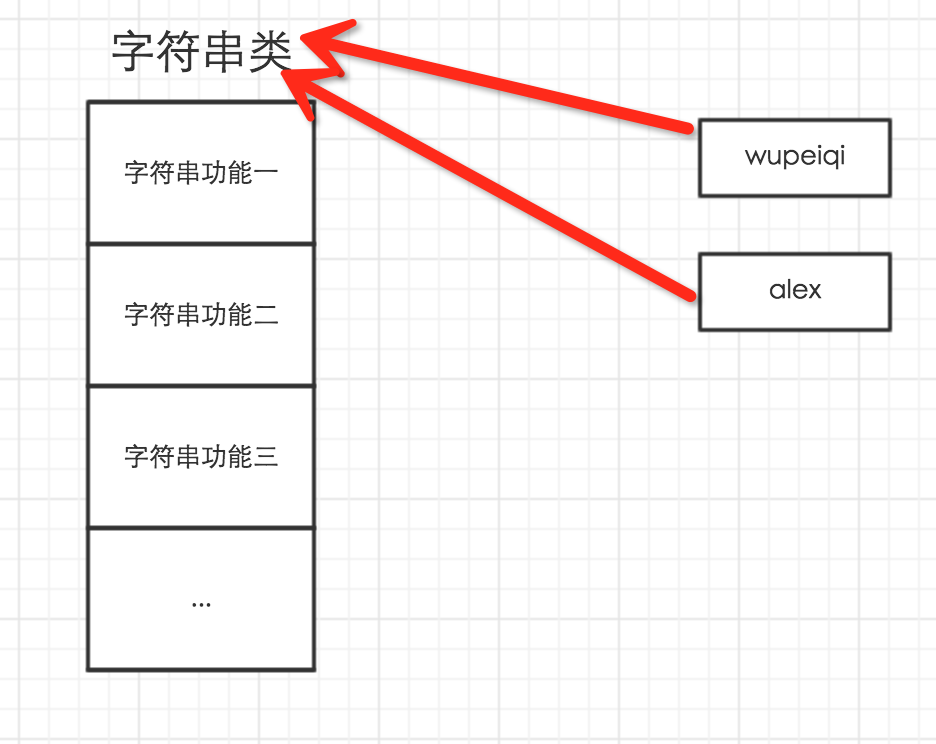


对于python,一切事物都是对象,对象是基于类创建的
l1 = [11,22,33] #list
prit(type(l1))
代码效果图:

#dic = {k1':'v1',‘k2’:‘v’}
dic =dict(k1='v1',k2='v2')
new_dict = dic.fromkeys(['k1','k2','k3'],'v1')
print(new dict)
上下文管理剖析
with
7、int内部功能介绍
整数
如: 18、73、84
每一个整数都具备如下功能:
 int
int代码效果图:
创建一个对象,查看对象是哪个类创建的

abs返回绝对值
1、age.__abs__()
2、abs(-19)

add加

共95页,每页显示10页
几页
1、95/10
2、余数95%10
if 余数>0:
95/10+1
else:
95/10
以上可用divmod替换,应用场景(做网页时用于分页显示 )

是否等于19

浮点类型
地板除
和print(5//6)结果一样

divmod和rdivmod

![]()
重要的知识点:divmod(除法)、abs(绝对值)、add(加)

8、float和long内部功能介绍
folat 和long和int内部功能基本一样
长整型
可能如:2147483649、9223372036854775807
每个长整型都具备如下功能:
long浮点型
如:3.14、2.88
每个浮点型都具备如下功能:
float
9、str内部功能介绍:
字符串
如:'wupeiqi'、'alex'
str就是字符串

列出类所有的成员(进行详细功能查看)

name = str('eric') #默认会执行类的__init__的方法
每个字符串都具备如下功能:
str注:编码;字符串的乘法;字符串和格式化
capitalize首字母大写

casefold将首字母变成小写

# name='eric' #print(type(name)) #查看类名称 # print(dir(name)) #查看类成员 #print(20*"*")
#字符串居中,用星号填充 name="erci" result=name.center(20,"*") print(result) #查字符串中的某个字符出现的次数 name="asdf;qwewrfergfasdssddddddf" result=name.count('df') print(result) #查看字符串中的某字符在特定的区间出现的次数 name="asdf;qwedfwrfergfasdssddddddf" result=name.count('df',6,10) #0和10的起始和结束位置 print(result) #编码转换,python3不用直接走Unicode过程 name ='李杰' result = name.encode('gbk') print(result) #看看某个字符串是不是以某个字符结尾的 name = "alex" result = name.endswith('e',0.3) print(result) #查看是否以ex结尾
#将tab转化为tab键
name = "a\tlex"
result = name.expandtabs()
print(len(result))
#查找字符串中的某个字符
name = "alex"
#result = name.find('e') #找不存在的付显式-1
result = name.index('e') #找不存在的字符会报错
print(result)
#format做字符串格式化
name ="alec {0} as {1}"
result=name.format('sb','eric')
print(result)
#format做字符串格式化
name ="alec {0} as {1}"
result =name.format('sb','eric')
print(result)
name ="alec {name} as {id}"
result=name.format(name='sb',id='eric')
print(result)
#join用来做拼接
li = ['s','b','a','l','e','x']
result="".join(li)
print(result)
li = ['s','b','a','l','e','x']
result="_".join(li)
print(result)
l_just 放左边
r_just 放右边
lstrip 去左边空格
rstrip 去右边空格
translate(self, table, deletechars=None):
转换,需要先做一个对应表,最后一个表示删除字符集合
intab = "aeiou"
outtab = "12345"
trantab = maketrans(intab, outtab)
str = "this is string example....wow!!!"
print str.translate(trantab, 'xm')
#partition分割成三部分
name = "alexissb"
result = name.partition('is')
print(result)
rfind从右开始找
rindex从向左找
rsplit 从右开始指定字符分割字符串
startwith 以什么开头
endwith 以什么结尾
str = "this is string example....wow!!!";
print str.startswith( 'this' );
print str.startswith( 'is', 2, 4 );
print str.startswith( 'this', 2, 4 );
#swapcase 大小写转换
name ="Eric"
result=name.swapcase()
print(result)
title首字母变大写
replace替换

replace只替换前两个

splitlines换行

除了splitlines可以做到,也可以用以下方法

字符串中,就几个常用split(换行)、strip(去空格)、replace(替换)、join(拼接)
10-上下文管理剖析

执行顺序

11、list内部功能介绍
li = list([1,2,3])
li = list((1,2,3)) #两种列表写法
注:带下划线的(1是没有用2是内置的一些功能)
append #在list尾部再添加一个元素
clear #把列表清空
copy #深coby 不管有多少层都会coby
#浅coby 浅浅的把第一层coby
count 判断某个元素出现的次数
extend 合并两个列表,也可以是列表和元祖合并(扩展)
li=list([1,2,3])
print(li)
代码效果图:

li.extend([11,22]) 列表
#li.extend((11,22,)) 元祖 print(li)
代码效果图:

index #获取下标(索引)
insert #指定下标,随意放进列表某一位置
li.insert(0,'aelx') #第0个位置放一个aelx
代码效果图

pop #移除某一项,去列表拿某个值,删除并获取到这个值
ret = li.pop(0)
print(li)
代码效果图:

print(ret) #删除并获取某个值
代码效果图:

remove 删除
li = [11,11,2,22,2]
print (li)
li.remove(11) #移除列表中的第一个11
print (li)
代码效果图:

reverse 反转
li = [11,22,33,44,55]
print(li)
li.reverse()
print(li)
代码效果图:

sort 排序
12、tuple和内部功能介绍
写元祖或者列表,后面必须带逗号

13、字典和列表
如:{'name': 'wupeiqi', 'age': 18} 、{'host': '2.2.2.2', 'port': 80]}
ps:循环时,默认循环key
每个字典都具备如下功能:
dict
字典是无序的
两种写法

fromkeys用法

get用法


用get出现之后,不会报错,出现none值

get也可以赋值

get只赋空值

dic中keys、values、item用法和结果对比

for k,v in dic.item():打印键、值、键值对

pop 字典中拿走一个

'''
练习:元素分类
有如下值集合
[11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
'''
# all_list=[11,22,33,44,55,66,77,88,99,90]
# dic ={}
# l1=[]
# l2=[]
# for i in all_list:
# if i >66:
# l1.append(i)
# else:
# l2.append(i)
# dic['k1']=l1
# dic['k2']=l2
# {'k1':[66,77,88,99,90],'k2':[11,22,33,44,55]}
all_list=[11,22,33,44,55,66,77,88,99,90]
dic ={}
for i in all_list:
if i>66:
if "k1" in dic.keys():
dic['k1'].append(i)
else:
dic['k1']=[i,]
else:
#dic = {'k2':[11,22]}
if "k2" in dic.keys():
dic['k2'].append(i)
else:
dic['k2']=[i,]
#dic={}
#dic={'k2':[11,]}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号