ConcurrentHashMap 1.8为什么要使用CAS+Synchronized取代Segment+ReentrantLock
大家应该都知道ConcurrentHashMap在1.8的时候有了很大的改动,当然,我这里要说的改动不是指链表长度大于8就转为红黑树这种常识,我要说的是ConcurrentHashMap在1.8为什么用CAS+Synchronized取代Segment+ReentrantLock了
首先,我假设你对CAS,Synchronized,ReentrantLock这些知识很了解,并且知道AQS,自旋锁,偏向锁,轻量级锁,重量级锁这些知识,也知道Synchronized和ReentrantLock在唤醒被挂起线程竞争的时候有什么区别
首先我们说下1.8以前的ConcurrentHashMap是怎么保证线程并发的,首先在初始化ConcurrentHashMap的时候,会初始化一个Segment数组,容量为16,而每个Segment呢,都继承了ReentrantLock类,也就是说每个Segment类本身就是一个锁,之后Segment内部又有一个table数组,而每个table数组里的索引数据呢,又对应着一个Node链表.
那么这样的好处是什么呢?我先从老版本的添加流程说起吧,由于电脑里没有JDK1.7及以下的版本我没法给你看代码,所以使用文字描述的方式,首先,当我们使用put方法的时候,是对我们的key进行hash拿到一个整型,然后将整型对16取模,拿到对应的Segment,之后调用Segment的put方法,然后上锁,请注意,这里lock()的时候其实是this.lock(),也就是说,每个Segment的锁是分开的
其中一个上锁不会影响另一个,此时也就代表了我可以有十六个线程进来,而ReentrantLock上锁的时候如果只有一个线程进来,是不会有线程挂起的操作的,也就是说只需要在AQS里使用CAS改变一个state的值为1,此时就能对代码进行操作,这样一来,我们等于将并发量/16了.
好,说完了老版本的ConcurrentHashMap,我们再说说新版本的,请看下面的图:
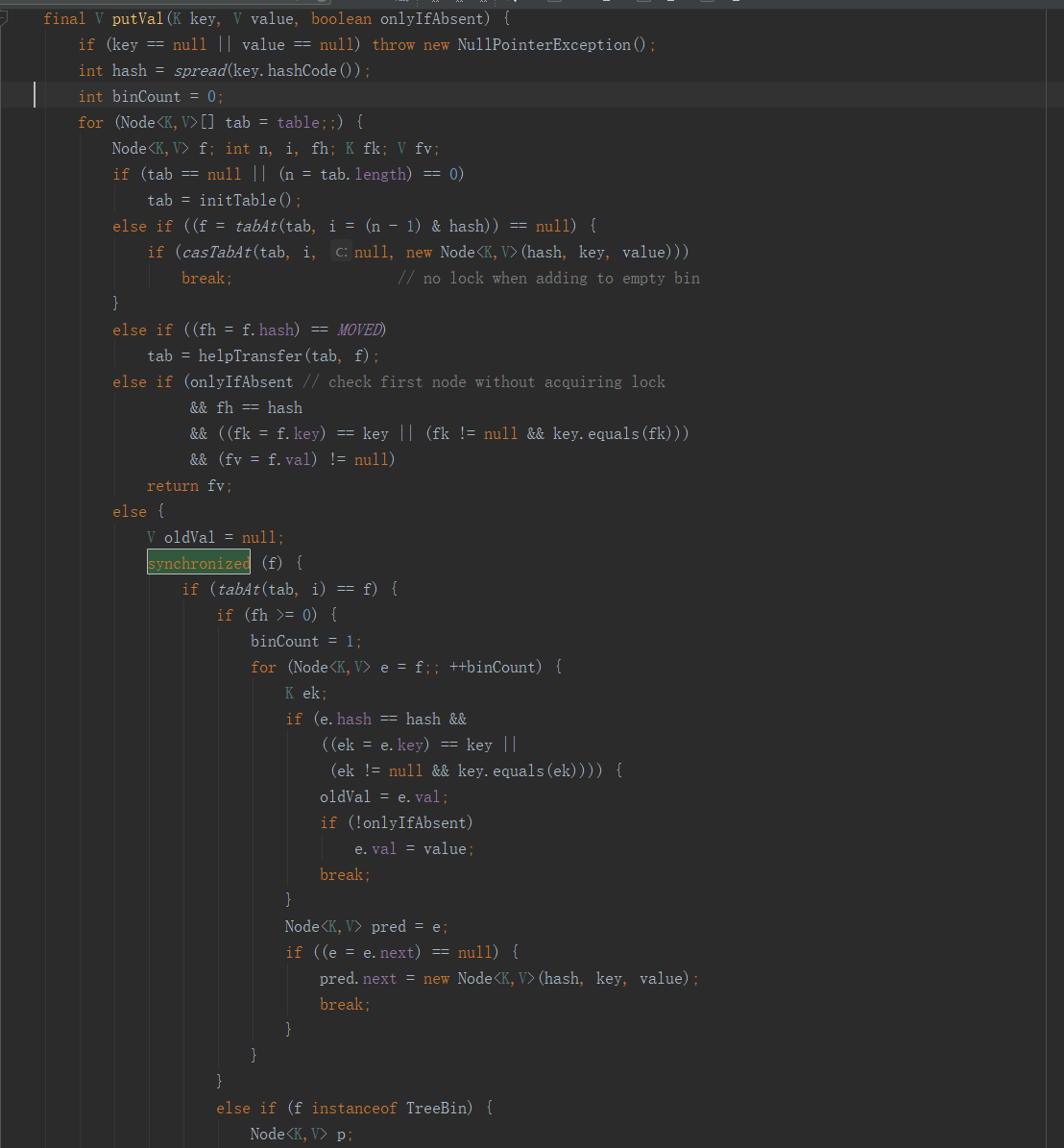
请注意Synchronized上锁的对象,请记住,Synchronized是靠对象的对象头和此对象对应的monitor来保证上锁的,也就是对象头里的重量级锁标志指向了monitor,而monitor呢,内部则保存了一个当前线程,也就是抢到了锁的线程.
那么这里的这个f是什么呢?它是Node链表里的每一个Node,也就是说,Synchronized是将每一个Node对象作为了一个锁,这样做的好处是什么呢?将锁细化了,也就是说,除非两个线程同时操作一个Node,注意,是一个Node而不是一个Node链表哦,那么才会争抢同一把锁.
如果使用ReentrantLock其实也可以将锁细化成这样的,只要让Node类继承ReentrantLock就行了,这样的话调用f.lock()就能做到和Synchronized(f)同样的效果,但为什么不这样做呢?
请大家试想一下,锁已经被细化到这种程度了,那么出现并发争抢的可能性还高吗?还有就是,哪怕出现争抢了,只要线程可以在30到50次自旋里拿到锁,那么Synchronized就不会升级为重量级锁,而等待的线程也就不用被挂起,我们也就少了挂起和唤醒这个上下文切换的过程开销.
但如果是ReentrantLock呢?它则只有在线程没有抢到锁,然后新建Node节点后再尝试一次而已,不会自旋,而是直接被挂起,这样一来,我们就很容易会多出线程上下文开销的代价.当然,你也可以使用tryLock(),但是这样又出现了一个问题,你怎么知道tryLock的时间呢?在时间范围里还好,假如超过了呢?
所以,在锁被细化到如此程度上,使用Synchronized是最好的选择了.这里再补充一句,Synchronized和ReentrantLock他们的开销差距是在释放锁时唤醒线程的数量,Synchronized是唤醒锁池里所有的线程+刚好来访问的线程,而ReentrantLock则是当前线程后进来的第一个线程+刚好来访问的线程.
如果是线程并发量不大的情况下,那么Synchronized因为自旋锁,偏向锁,轻量级锁的原因,不用将等待线程挂起,偏向锁甚至不用自旋,所以在这种情况下要比ReentrantLock高效
__EOF__

本文链接:https://www.cnblogs.com/yaphetsfang/p/11284203.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下