数据并行和任务并行
OpenCL并行加减乘除示例——数据并行与任务并行
OpenCL并行加减乘除示例——数据并行与任务并行
==============================================================
目录结构
1、数据并行
2、任务并行
3、参考
==============================================================
关键词:OpenCL; data parallel; task parallel
数据并行化计算与任务并行化分解可以加快程序的运行速度。
如下基本算术例子,输入数组A和数组B,得到输出数组C,C的结果如图中output所示。
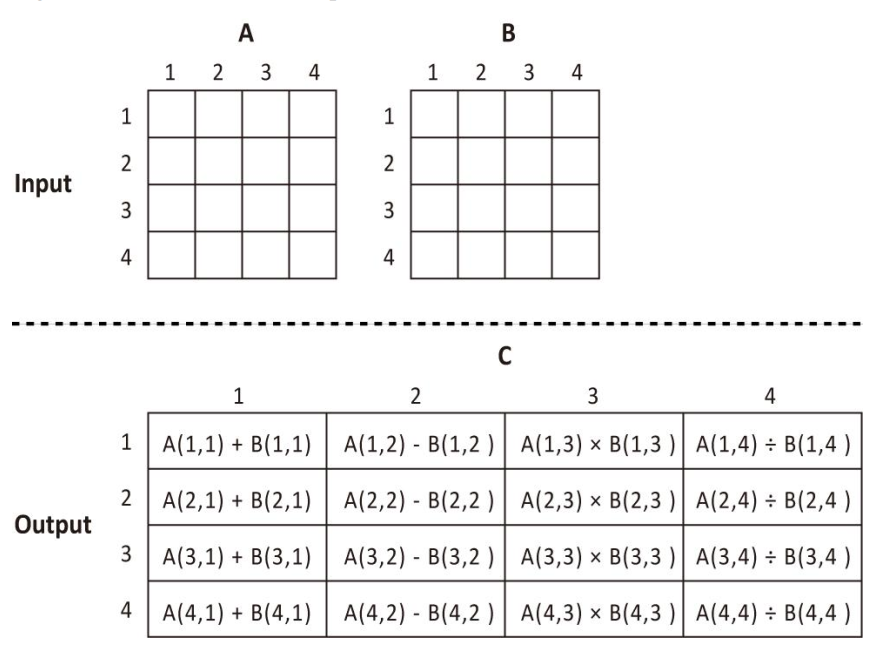
图1、加减乘除例子
我们可以通过以下代码计算结果,这块代码我们暂且称为功能函数:
-
float C[16];
-
-
int i;
-
-
for(i=0; i<4; i++)
-
-
{
-
-
C[i*4+0] = A[i*4+0] + B[i*4+0]; //task A
-
-
C[i*4+1] = A[i*4+1] - B[i*4+1];//task B
-
-
C[i*4+2] = A[i*4+2] * B[i*4+2];//task C
-
-
C[i*4+3] = A[i*4+3] / B[i*4+3];// task D
-
-
}
1、数据并行(data parallel)
可以发现每一个for循环都由加减乘除4个任务组成,分别为task A、task B、task C和task D。按时间顺序从0时刻开始执行i=0到i=3的4个计算单元,运行完成时间假设为T。
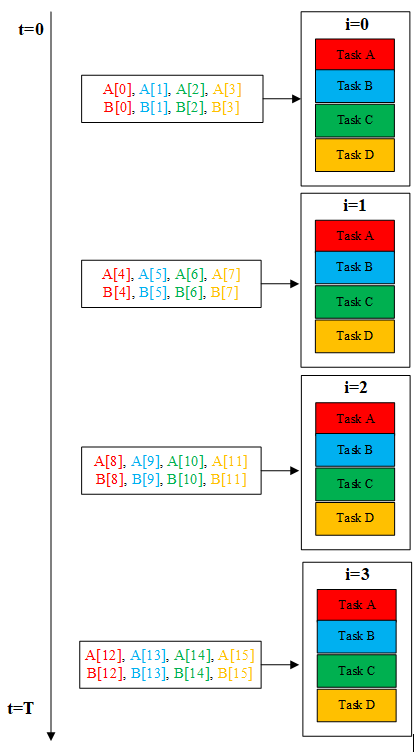
图2. 顺序执行图
从图2我们也可以看出,对于每个程序块,A,B的数据来源都不同,图中的颜色对应task的颜色,由于数据之间并没有依赖关系,所以在程序设计时可以使i=0,1,2,3四个程序块一起运行,将不同的数据给相同的处理函数同时运行,理想化得使运行时间缩减到T/4,如图3所示。这种办法对不同的数据使用相同的核函数,称为数据并行。
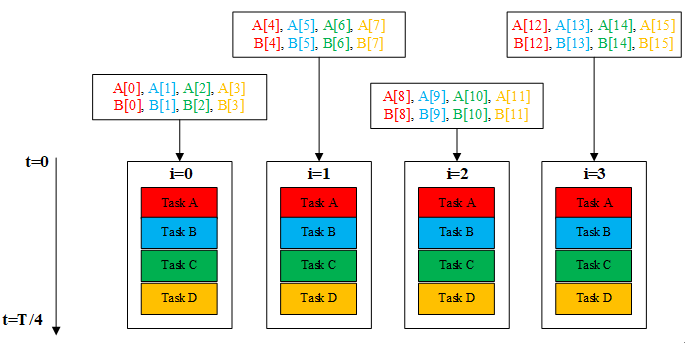
图3. 数据并行方法图
数据化并行使用的OpenCL的API函数是:clEnqueueNDRangeKernel()
以下是参考程序:
host.cpp:
-
-
-
-
-
-
-
-
-
//data parallel
-
int main()
-
{
-
cl_platform_id platform_id = NULL;
-
cl_device_id device_id = NULL;
-
cl_context context = NULL;
-
cl_command_queue command_queue = NULL;
-
cl_mem Amobj = NULL;
-
cl_mem Bmobj = NULL;
-
cl_mem Cmobj = NULL;
-
cl_program program = NULL;
-
cl_kernel kernel = NULL;
-
cl_uint ret_num_devices;
-
cl_uint ret_num_platforms;
-
cl_int ret;
-
-
int i, j;
-
float *A;
-
float *B;
-
float *C;
-
-
A = (float *)malloc(4 * 4 * sizeof(float));
-
B = (float *)malloc(4 * 4 * sizeof(float));
-
C = (float *)malloc(4 * 4 * sizeof(float));
-
-
FILE *fp;
-
const char fileName[] = "./dataParallel.cl";
-
size_t source_size;
-
char *source_str;
-
-
/* Load kernel source file */
-
fp = fopen(fileName, "r");
-
if (!fp) {
-
fprintf(stderr, "Failed to load kernel.гдn");
-
exit(1);
-
}
-
source_str = (char *)malloc(MAX_SOURCE_SIZE);
-
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
-
fclose(fp);
-
-
/* Initialize input data */
-
printf("Initialize input data");
-
for (i = 0; i < 4; i++) {
-
for (j = 0; j < 4; j++) {
-
A[i * 4 + j] = i * 4 + j + 1;
-
B[i * 4 + j] = j * 4 + i + 1;
-
}
-
}
-
printf("\n");
-
-
printf("A array data:\n");
-
for (i = 0; i < 4; i++) {
-
for (int j=0; j<4; j++){
-
printf("%.2f\t",A[i*4+j]);
-
}
-
printf("\n");
-
}
-
-
printf("B array data:\n");
-
for (i = 0; i < 4; i++) {
-
for (int j=0; j<4; j++){
-
printf("%.2f\t",B[i*4+j]);
-
}
-
printf("\n");
-
}
-
-
clock_t start, finish;
-
double duration;
-
printf("DataParallel kernels tart to execute\n");
-
start = clock();
-
-
/* Get Platform/Device Information */
-
ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
-
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id,
-
&ret_num_devices);
-
-
/* Create OpenCL Context */
-
context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
-
-
/* Create command queue */
-
command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
-
-
/* Create Buffer Object */
-
Amobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4 * 4 * sizeof(float), NULL,
-
&ret);
-
Bmobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4 * 4 * sizeof(float), NULL,
-
&ret);
-
Cmobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4 * 4 * sizeof(float), NULL,
-
&ret);
-
-
/* Copy input data to the memory buffer */
-
ret = clEnqueueWriteBuffer(command_queue, Amobj, CL_TRUE, 0, 4 * 4 * sizeof(float),
-
A, 0, NULL, NULL);
-
ret = clEnqueueWriteBuffer(command_queue, Bmobj, CL_TRUE, 0, 4 * 4 * sizeof(float),
-
B, 0, NULL, NULL);
-
/* Create kernel program from source file*/
-
program = clCreateProgramWithSource(context, 1, (const char **)&source_str, (const
-
size_t *)&source_size, &ret);
-
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
-
-
/* Create data parallel OpenCL kernel */
-
kernel = clCreateKernel(program, "dataParallel", &ret);
-
-
/* Set OpenCL kernel arguments */
-
ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&Amobj);
-
ret = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&Bmobj);
-
ret = clSetKernelArg(kernel, 2, sizeof(cl_mem), (void *)&Cmobj);
-
-
size_t global_item_size = 4;
-
size_t local_item_size = 1;
-
-
/* Execute OpenCL kernel as data parallel */
-
ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL,
-
&global_item_size, &local_item_size, 0, NULL, NULL);
-
-
/* Transfer result to host */
-
ret = clEnqueueReadBuffer(command_queue, Cmobj, CL_TRUE, 0, 4 * 4 * sizeof(float),
-
C, 0, NULL, NULL);
-
-
//end of execution
-
finish = clock();
-
duration = (double)(finish - start) / CLOCKS_PER_SEC;
-
printf("\n%f seconds\n", duration);
-
-
/* Display Results */
-
printf("Calculation result:\n");
-
for (i = 0; i < 4; i++) {
-
for (j = 0; j < 4; j++) {
-
printf("%7.2f\t", C[i * 4 + j]);
-
}
-
printf("\n");
-
}
-
-
-
/* Finalization */
-
ret = clFlush(command_queue);
-
ret = clFinish(command_queue);
-
ret = clReleaseKernel(kernel);
-
ret = clReleaseProgram(program);
-
ret = clReleaseMemObject(Amobj);
-
ret = clReleaseMemObject(Bmobj);
-
ret = clReleaseMemObject(Cmobj);
-
ret = clReleaseCommandQueue(command_queue);
-
ret = clReleaseContext(context);
-
-
free(source_str);
-
-
free(A);
-
free(B);
-
free(C);
-
system("pause");
-
return 0;
-
}
kernel.cl:
-
__kernel void dataParallel(__global float* A, __global float* B, __global float* C)
-
{
-
int base = 4*get_global_id(0);
-
C[base+0] = A[base+0] + B[base+0];
-
C[base+1] = A[base+1] - B[base+1];
-
C[base+2] = A[base+2] * B[base+2];
-
C[base+3] = A[base+3] / B[base+3];
-
}
2、任务并行(task parallel)
另外还有一种就是任务并行化,可以使所有功能函数内部的语句并行执行,即任务并行化,如本文中的功能函数可以分解为“加减乘除”这四个任务,可以产生“加减乘除”四个核函数,让四个函数同时执行,如下图所示。
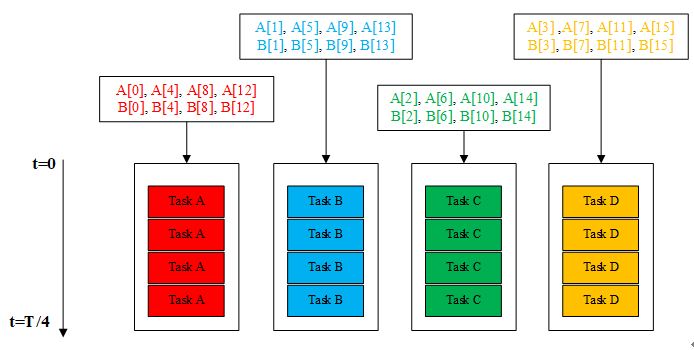
图4、任务并行方法图
以图4中的红色核函数为例,执行的是数组A和数组B中第一列的加法运行,此加法核函数随着时间运行,分别执行了A[0] + B[0]、A[4] + B[4]、A[8] + B[8]和A[12] + B[12]。
数据化并行使用的OpenCL的API函数是:clEnqueueTask()
以下是参考程序:
host.cpp:
-
// taskparallel.cpp : 定义控制台应用程序的入口点。
-
//
-
-
-
-
-
-
-
-
int main()
-
{
-
cl_platform_id platform_id = NULL;
-
cl_device_id device_id = NULL;
-
cl_context context = NULL;
-
cl_command_queue command_queue = NULL;
-
cl_mem Amobj = NULL;
-
cl_mem Bmobj = NULL;
-
cl_mem Cmobj = NULL;
-
cl_program program = NULL;
-
cl_kernel kernel[4] = {NULL, NULL, NULL, NULL};
-
cl_uint ret_num_devices;
-
cl_uint ret_num_platforms;
-
cl_int ret;
-
-
int i,j;
-
float *A, *B, *C;
-
-
A = (float *) malloc(4*4*sizeof(float));
-
B = (float *) malloc(4*4*sizeof(float));
-
C = (float *) malloc(4*4*sizeof(float));
-
-
FILE *fp;
-
const char fileName[] = "./taskParallel.cl";
-
size_t source_size;
-
char *source_str;
-
-
//load kernel source file
-
fp = fopen(fileName, "rb");
-
if(!fp) {
-
fprintf(stderr, "Failed to load kernel\n");
-
exit(1);
-
}
-
-
source_str = (char *)malloc(MAX_SOURCE_SIZE);
-
source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
-
fclose(fp);
-
-
//initialize input data
-
for(i=0; i<4; i++) {
-
for(j=0; j<4; j++) {
-
A[i*4+j] = i*4+j+1;
-
B[i*4+j] = j*4+i+1;
-
}
-
}
-
-
//print A
-
printf("\nA initilization data: \n");
-
for(i=0; i<4; i++) {
-
for(j=0; j<4; j++) {
-
printf("%.2f\t", A[i*4+j]);
-
}
-
printf("\n");
-
}
-
-
//print B
-
printf("\nB initilization data: \n");
-
for(i=0; i<4; i++) {
-
for(j=0; j<4; j++) {
-
printf("%.2f\t", B[i*4+j]);
-
}
-
printf("\n");
-
}
-
-
clock_t start, finish;
-
double duration;
-
printf("TaskParallel kernels start to execute\n");
-
start = clock();
-
-
-
//get platform/device information
-
ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
-
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT,1,&device_id, &ret_num_devices);
-
-
//create opencl context
-
context = clCreateContext(NULL, 1,&device_id, NULL, NULL, &ret);
-
-
//create command queue
-
command_queue = clCreateCommandQueue(context, device_id, CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE, &ret);
-
-
//create buffer object
-
Amobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4*4*sizeof(float), NULL,&ret);
-
Bmobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4*4*sizeof(float), NULL,&ret);
-
Cmobj = clCreateBuffer(context, CL_MEM_READ_WRITE, 4*4*sizeof(float), NULL,&ret);
-
-
//copy input data to memory buffer
-
ret = clEnqueueWriteBuffer(command_queue, Amobj, CL_TRUE, 0, 4*4*sizeof(float), A, 0, NULL, NULL);
-
ret = clEnqueueWriteBuffer(command_queue, Bmobj, CL_TRUE, 0, 4*4*sizeof(float), B, 0, NULL, NULL);
-
-
//create kernel from source
-
program = clCreateProgramWithSource(context, 1, (const char **)&source_str, (const size_t *)&source_size, &ret);
-
ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
-
-
//create task parallel
-
kernel[0] = clCreateKernel(program, "add_parallel", &ret);
-
kernel[1] = clCreateKernel(program, "sub_parallel", &ret);
-
kernel[2] = clCreateKernel(program, "mul_parallel", &ret);
-
kernel[3] = clCreateKernel(program, "div_parallel", &ret);
-
-
//set opencl kernel arguments
-
for (i=0; i<4; i++) {
-
ret = clSetKernelArg(kernel[i], 0, sizeof(cl_mem), (void *) &Amobj);
-
ret = clSetKernelArg(kernel[i], 1, sizeof(cl_mem), (void *) &Bmobj);
-
ret = clSetKernelArg(kernel[i], 2, sizeof(cl_mem), (void *) &Cmobj);
-
}
-
-
//execute opencl kernels
-
for(i=0; i<4; i++) {
-
ret = clEnqueueTask(command_queue, kernel[i], 0, NULL, NULL);
-
}
-
-
//copy result to host
-
ret = clEnqueueReadBuffer(command_queue, Cmobj, CL_TRUE, 0, 4*4*sizeof(float), C, 0, NULL, NULL);
-
-
//end of execution
-
finish = clock();
-
duration = (double)(finish - start) / CLOCKS_PER_SEC;
-
printf("\n%f seconds\n", duration);
-
-
//display result
-
printf("\nC result: \n");
-
for(i=0; i<4; i++) {
-
for(j=0; j<4; j++) {
-
printf("%.2f\t", C[i*4+j]);
-
}
-
printf("\n");
-
}
-
printf("\n");
-
-
//free
-
ret = clFlush(command_queue);
-
ret = clFinish(command_queue);
-
ret = clReleaseKernel(kernel[0]);
-
ret = clReleaseKernel(kernel[1]);
-
ret = clReleaseKernel(kernel[2]);
-
ret = clReleaseKernel(kernel[3]);
-
ret = clReleaseProgram(program);
-
ret = clReleaseMemObject(Amobj);
-
ret = clReleaseMemObject(Bmobj);
-
ret = clReleaseMemObject(Cmobj);
-
ret = clReleaseCommandQueue(command_queue);
-
ret = clReleaseContext(context);
-
-
free(source_str);
-
free(A);
-
free(B);
-
free(C);
-
-
system("pause");
-
return 0;
-
}
-
kernel.cl:
-
__kernel void add_parallel(__global float *A, __global float *B, __global float *C)
-
{
-
int base = 0;
-
-
for(int i=0;i<4;i++)
-
{
-
C[base+i*4] = A[base+i*4] + B[base+i*4];
-
}
-
//C[base+0] = A[base+0] + B[base+0];
-
//C[base+4] = A[base+4] + B[base+4];
-
//C[base+6] = A[base+8] + B[base+8];
-
//C[base+12] = A[base+12] + B[base+12];
-
}
-
-
__kernel void sub_parallel(__global float *A, __global float *B, __global float *C)
-
{
-
int base = 1;
-
-
for(int i=0;i<4;i++)
-
{
-
C[base+i*4] = A[base+i*4] - B[base+i*4];
-
}
-
}
-
-
__kernel void mul_parallel(__global float *A, __global float *B, __global float *C)
-
{
-
int base=2;
-
for(int i=0; i<4; i++)
-
{
-
C[base+i*4] = A[base+i*4]*B[base+i*4];
-
}
-
}
-
-
-
__kernel void div_parallel(__global float *A, __global float *B, __global float *C)
-
{
-
int base = 3;
-
for(int i=0; i<4; i++)
-
{
-
C[base+i*4] = A[base+i*4] / B[base+i*4];
-
}
-
}
3、参考
例子及程序来自《The OpenCL Programming Book》,以上例子其实还可以并行化,只要需要足够多的并行度,完全可以利用16个任务一起算,即让加减乘除四个任务里的四个按时间执行的任务同时计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号