
架构师成长之路-多维监控体系_系统监控
架构师成长之路-多维监控体系_系统监控
监控入门:
- 识别监控对象:
- 监控对象的理解:CPU工作原理
- 监控对象的指标:CPU使用率、CPU负载 、CPU个数、 CPU上下文切换
- 确认告警基准线:怎么样才算故障?CPU负载多少才算高?
预中级监控需要做:
- 工具化和监控分离
- 监控对象的分类:
硬件监控(机房巡检、IPMI、SNMP)
系统监控(对象:CPU、内存、IO[磁盘、网络]、进程等)
服务监控(对象:各类服务[Nginx|Tomcat|RabbitMQ|Openstack|Mysql|*])
日志监控(方法:Elastic Stack)
网络监控(方法:第三方、Smokeping)
APM应用性能管理(工具:PINPoint)
流量监控(工具:Piwik、xx统计、xx分析)
其他监控(APP监控、安全监控、业务监控、舆论监控、xx监控) - 掌握一个监控工具:比如zabbix
中级监控需要做:
- 标准化监控(标准化的脚本、模板等等)
- 分布式监控(主动、被动、分布式)
- 自动化监控(自动发现、主动注册[Agent主动注册、Server通过API主动添加])
- 性能优化(数据采集、数据存储、数据查询)
- 二次开发(定制报表、API调用、xxx)
进阶监控需要做:
- 动态告警
- 智能告警:1.告警去重 2.去除依赖性
- 故障自愈
- 大规模监控
系统监控
1 系统监控_CPU
1.1 CPU三个重要的概念
[A] 上下文切换:
目前流行的CPU在同一时间内只能运行一个线程,超线程的处理器可以在同一时间运行多个线程(包括多核CPU),Linux内核会把多核 的处理器当作多个单独的CPU来识别。
一个标准的Linux内核可以支持运行50~50000个进程运行,对于普通的CPU,内核会调度和执行这些进程。每个进程都会分到CPU的时间片来运行,当一个进程用完时间片或者被更高优先级的进程抢占后,它会备份 到CPU的运行队列中,同时其他进程在CPU上运行。这个进程切换的过程被称作上下文切 换。过多的上下文切换会造成系统很大的开销。
[B] 运行队列(负载):
每个CPU都会维持一个运行队列,理想情况下,调度器会不断让队列中的进程运行。进程不是处在sleep状态就是runable状态。如果CPU过载,就会出现调度器跟不上系统的要求,导致可运行的进程会填满队列。队列愈大,程序执行时间就愈长。
补充:关于时间片和动态优先级
时间片对于CPU来说是很关键的参数,如果时间片太长,就会使系统的交互性能变差,用户感觉不到并行。如果太短,又会造成系统频繁的上下文切换,使性能 下降。对于IO Bound的系统来讲并不需要太长的 时间片,因为系统主要是IO操作;而对于CPU Bound的系统来说需要长的时间片以保持cache的有效性。
每一个进程启动的时候系统都会给出一个默认的优先级,但在运行过程中,系统会根据进程的运行状况不断调整优先级,内核会升高或降低进程的优先级(每次增加或降低5),判断标准是根据进程处于sleep状态的时间。
IO Bound进程大部分时间在sleep状态,所以内核会调高它的优先级,CPU Bound进程会被内核惩罚降低优先级。因此,如果一个系统上即运行IO Bound进程,又运行CPU Bound进程,会发现,IO Bound进程的性能不会下降,而CPU Bound进程性能会不断下降。
[C] CPU使用率:
CPU使用的百分比。对于上下文切换要结合CPU使用率来看,如果CPU使用满足上述分布,大量的上下文切换也是可以接受的。
补充:内核态与用户态
intel x86 CPU有四种不同的执行级别0-3,linux只使用了其中的0级和3级分别来表示内核态和用户态。
内核态与用户态是操作系统的两种运行级别。
- 当程序运行在3级特权级上时,就可以称之为运行在用户态,因为这是最低特权级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态;
- 当程序运行在0级特权级上时,就可以称之为运行在内核态。
运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。
当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态。
这两种状态的主要差别是:
- 处于用户态执行时,进程所能访问的内存空间和对象受到限制,其所处于占有的处理机是可被抢占的 ;
- 而处于核心态执行中的进程,则能访问所有的内存空间和对象,且所占有的处理机是不允许被抢占的。
补充:用户态和内核态的转换
1)用户态切换到内核态的3种方式
- 系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
- 异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
- 外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
2)具体的切换操作
从触发方式上看,可以认为存在前述3种不同的类型,但是从最终实际完成由用户态到内核态的切换操作上来说,涉及的关键步骤是完全一致的,没有任何区别,都相当于执行了一个中断响应的过程,因为系统调用实际上最终是中断机制实现的,而异常和中断的处理机制基本上也是一致的,关于它们的具体区别这里不再赘述。关于中断处理机制的细节和步骤这里也不做过多分析,涉及到由用户态切换到内核态的步骤主要包括:
- 从当前进程的描述符中提取其内核栈的ss0及esp0信息。
- 使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用户栈到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令。
- 将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。
1.2 确定服务类型
【A】CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
【B】IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
CPU密集型适合C语言多线程,I/O密集型适合脚本语言开发的多线程。
1.3 确定性能基准线
经验总结:
- 运行队列: 对于每一个CPU来说运行队列1~3
若1CPU,4核,负载不超过12 - CPU使用:如果CPU在满负荷运行,应该符合下列分布:
User Time用户态利用率:65%~70%
System Time内核态利用率:30%~35%
Idle空闲:0%~5% - 上下文切换:
1.4 CPU监控工具
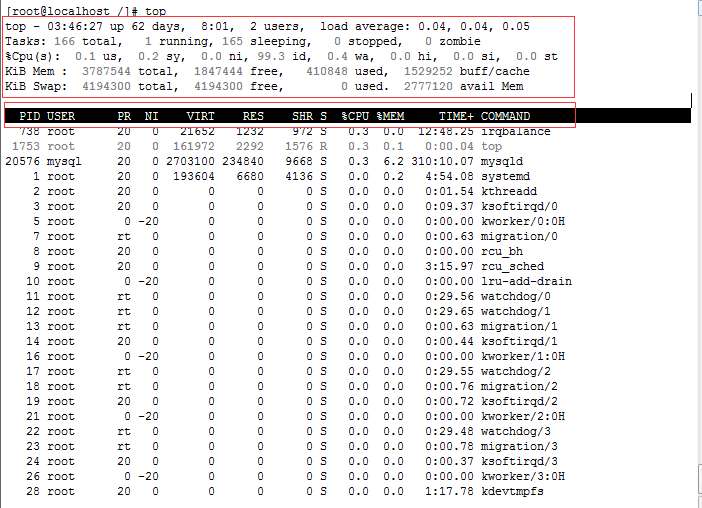
【A】top 命令
P CPU使用率排序
W 内存使用率排序
【B】sysstat工具包
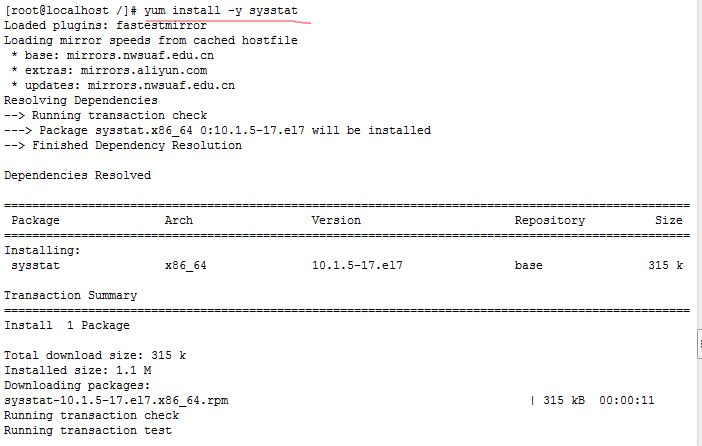
vmstat(Virtual Memory Statistics 虚拟内存统计) 命令用来显示Linux系统虚拟内存状态,也可以报告关于进程、内存、I/O等系统整体运行状态。
- -a:显示活跃和非活跃内存
- -f:显示从系统启动至今的fork数量 。
- -m:显示slabinfo
- -n:只在开始时显示一次各字段名称。
- -s:显示内存相关统计信息及多种系统活动数量。
- delay:刷新时间间隔。如果不指定,只显示一条结果。
- count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
- -d:显示磁盘相关统计信息。
- -p:显示指定磁盘分区统计信息
- -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
- -V:显示vmstat版本信息。
mpstat:其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
- -P {|ALL} 表示监控哪个CPU,cpu在[0,cpu个数-1]中取值
- internal 相邻的两次采样的间隔时间
- count采样的次数,count只能和delay一起使用
- 当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。

2 系统监控_内存
分成页 每页4KB
2.1 内存两个重要的概念
[A] 内存寻址:
内存寻址是指CPU允许支持的内存大小。双通道内存技术其实是一种内存控制和管理技术,它依赖于芯片组的内存控制器发生作用,在理论上能够使两条同等规格内存所提供的带宽增长一倍。当计算机面临大量的数据流时,32位的寄存器和指令集不能及时进行相应的处理运算。
- 32位处理器一次只能处理32位,也就是4个字节的数据;
- 64位处理器一次就能处理64位,即8个字节的数据。
计算机管理内存的基本方式有两种:段式管理和页式管理。
- CPU段式管理:段式管理的基本原理是指把一个程序分成若干个段(segment)进行存储,每个段都是一个逻辑实体(logical entity)。一个用户 作业或进程所包含的段对应一个二维线形虚拟空间,程序通过分段(segmentation)划分为多个模块,故可以对程序的各个模块分别编写和编译。段式管理程序以段为单位分配内存,然后通过地址影射机构把段式虚拟地址转换为虚拟地址。
- CPU页式管理:页式管理的基本原理将各进程的虚拟空间划分成若干个长度相等的页(一般为4K),页式管理把内存空间按页的大小划分成片或者页面(page frame),然后把页式虚拟地址与内存地址建立一一对应页表,并用相应的硬件地址变换机构,来解决离散地址变换问题。
而在使用80x86微处理器时,内存地址分为三个不同的地址:逻辑地址,线性地址,物理地址。
-
逻辑地址:包含在机器语言指令中用来指定一个操作数或一条指令的地址,每个逻辑地址都由一个段和偏移量组成,表示为[段标识符:段内偏移量]。例如,在C/C++程序中我们使用指针对变量地址操作,该地址就是逻辑地址(准确的应该说是逻辑地址的段内偏移量)。对应上述段式管理,逻辑地址是段式管理转换前的程序地址。
- 线性地址:也称为虚拟地址,它是一个32位无符号整数,故可以用来表达高达4GB的地址。线性地址同逻辑地址一样也是不真实的地址。对应上述页式管理,线性地址是页式管理转换前的地址。
- 物理地址:用于内存芯片级内存单元寻址,与处理器和CPU连接的地址总线相对应。一般情况下,我们说的计算机内存条中的内存就是它(虽然不准确)。
- 首先将给定一个逻辑地址,CPU要利用其段式内存管理单元,先将每个逻辑地址转换成一个线程地址,
- 再利用其页式内存管理单元,转换为最终物理地址。
[B] 内存空间:
内存是计算机系统中一个主要部件, 用于保存进程运行时的程序和数据,也称可执行存储器。在计算机中,内存空间一般是指主存储器空间(物理地址空间)或系统为一个用户程序分配内存空间。扩展内存空间的方法一般有增加内存大小和虚拟内存。
2.2 内存监控工具
free命令

3 系统监控_硬盘
IOPS: IOPS(Input/Output Operations Per Second)是一个用于计算机存储设备(如硬盘(HDD)、固态硬盘(SSD)或存储区域网络(SAN))性能测试的量测方式,可以视为是每秒的读写次数。
随机访问(随机IO)、顺序访问(顺序IO)
- 随机访问的特点是每次IO请求的数据在磁盘上的位置跨度很大(如:分布在不同的扇区),因此N个非常小的IO请求(如:1K),必须以N次IO请求才能获取到相应的数据。
- 顺序访问的特点跟随机访问相反,它请求的数据在磁盘的位置是连续的。当系统发起N个非常小的IO请求(如:1K)时,因为一次IO是有代价的,系统会取完整的一块数据(如4K、8K),所以当第一次IO完成时,后续IO请求的数据可能已经有了。这样可以减少IO请求的次数。这也就是所谓的预取。
随机访问和顺序访问同样是有应用决定的。如数据库、小文件的存储的业务,大多是随机IO。而视频类业务、大文件存取,则大多为顺序IO。
选取合理的观察指标:
以上各指标中,不用的应用场景需要观察不同的指标,因为应用场景不同,有些指标甚至是没有意义的。
- 随机访问和IOPS: 在随机访问场景下,IOPS往往会到达瓶颈,而这个时候去观察Throughput,则往往远低于理论值。
- 顺序访问和Throughput:在顺序访问的场景下,Throughput往往会达到瓶颈(磁盘限制或者带宽),而这时候去观察IOPS,往往很小。
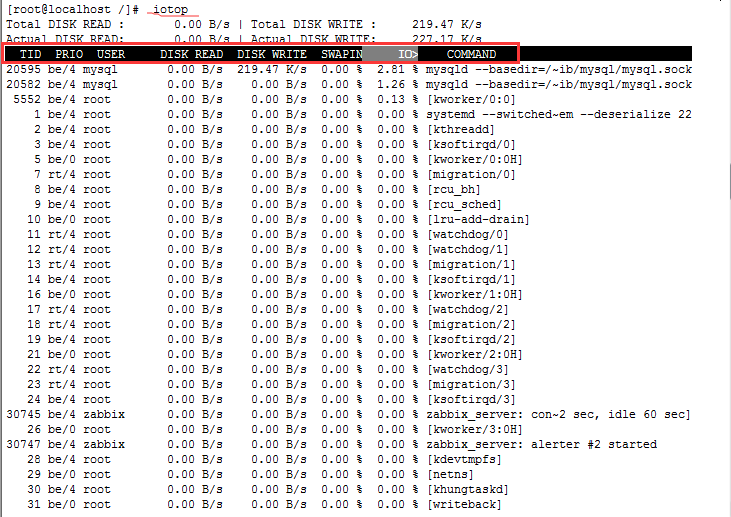
iotop 命令:监控硬盘IO的使用情况

4 系统监控_网络
iftop命令 查看实时的网络流量,监控TCP/IP连接等
由于安装好的EPEL没有iftop,所以无法使用yum install iftop直接安装,所以测试的时候采用编译安装。
yum install flex byacc libpcap ncurses ncurses-devel libpcap-devel wget http://www.ex-parrot.com/pdw/iftop/download/iftop-0.17.tar.gz tar zxvf iftop-0.17.tar.gz cd iftop-0.17 ./configure make && make install
常用的参数:
- -i 设定监测的网卡,如:# iftop -i eth1
- -B 以bytes为单位显示流量(默认是bits),如:# iftop -B
- -n 使host信息默认直接都显示IP,如:# iftop -n
- -N 使端口信息默认直接都显示端口号,如: # iftop -N
- -F 显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
- -h (display this message),帮助,显示参数信息
- -p 使用这个参数后,中间的列表显示的本地主机信息,出现了本机以外的IP信息;
- -b 使流量图形条默认就显示;
- -f 这个暂时还不太会用,过滤计算包用的;
- -P 使host信息及端口信息默认就都显示;
- -m 设置界面最上边的刻度的最大值,刻度分五个大段显示,例:# iftop -m 100M

上图说明:
- 最上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。
- 中间的<= =>这两个左右箭头,表示的是流量的方向。
- TX:发送流量
- RX:接收流量
- TOTAL:总流量
- Cumm:运行iftop到目前时间的总流量
- peak:流量峰值
- rates:分别表示过去 2s 10s 40s 的平均流量
....
作者:CARLOS_CHIANG
出处:http://www.cnblogs.com/yaoyaojcy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
posted on 2019-01-03 15:11 CARLOS_KONG 阅读(779) 评论(0) 编辑 收藏 举报

