

Efficient Estimation of Word Representations in Vector Space (2013)论文要点
论文链接:https://arxiv.org/pdf/1301.3781.pdf
参考:
A Neural Probabilistic Language Model (2003)论文要点 https://www.cnblogs.com/yaoyaohust/p/11310774.html
- 线性规律linear regularities: "king - man = queen - woman"
- 语法和语义规律syntactic and semantic regularities
1986年Hinton等人提出分布式表示。
典型的训练:
3-50轮,十亿级别样本,滑动窗口宽度N=10,向量维度D=50-200,隐层宽度H=500-1000,词典维度|V|=10^6
复杂度主要取决于隐层到输出层,即H*|V|
hierarchical softmax,输出层Huffman编码,计算复杂度|V| -> log|V|
考虑去掉隐层。
两种方式CBOW和Skip-gram
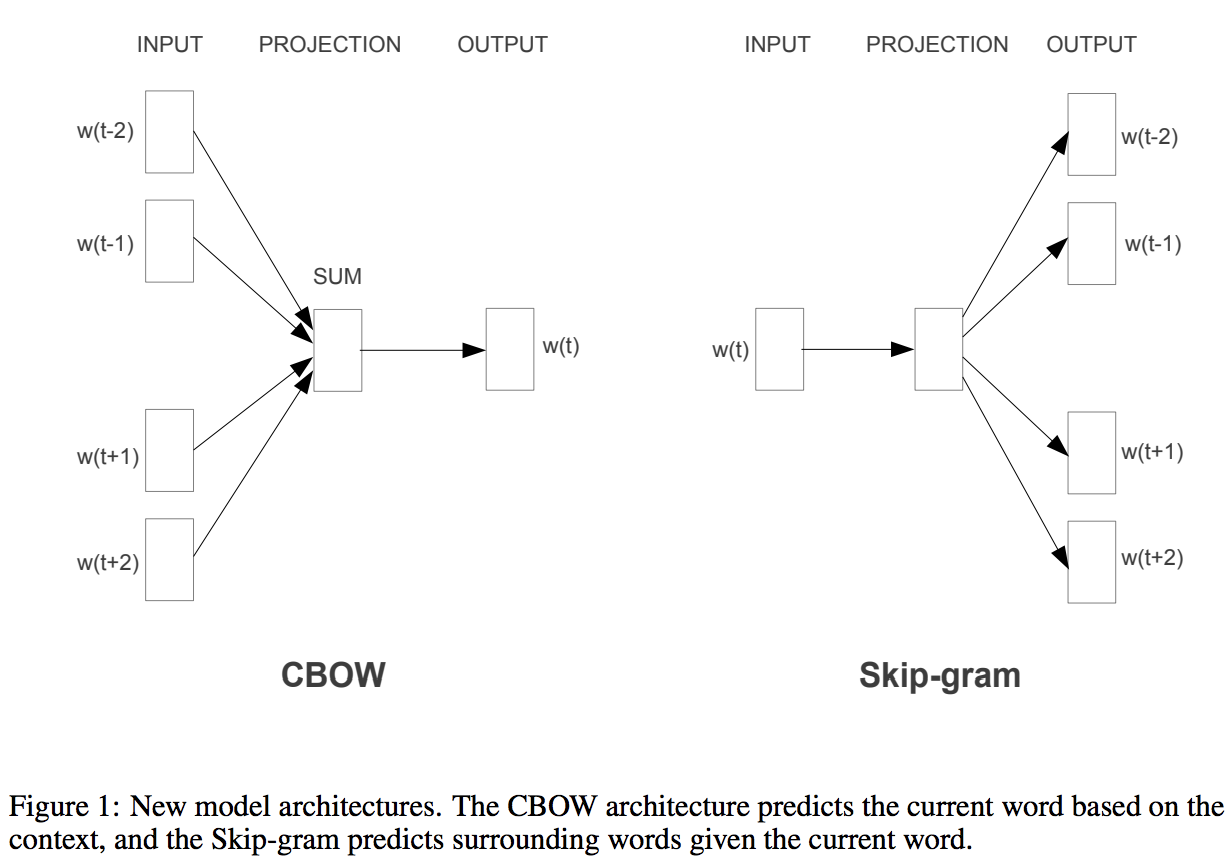
更多数据,更高维向量:
Google News:60亿tokens,100万常用词,3万极常用词
3轮迭代,学习率0.025且随时间衰减。

