

A Neural Probabilistic Language Model (2003)论文要点
论文链接:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
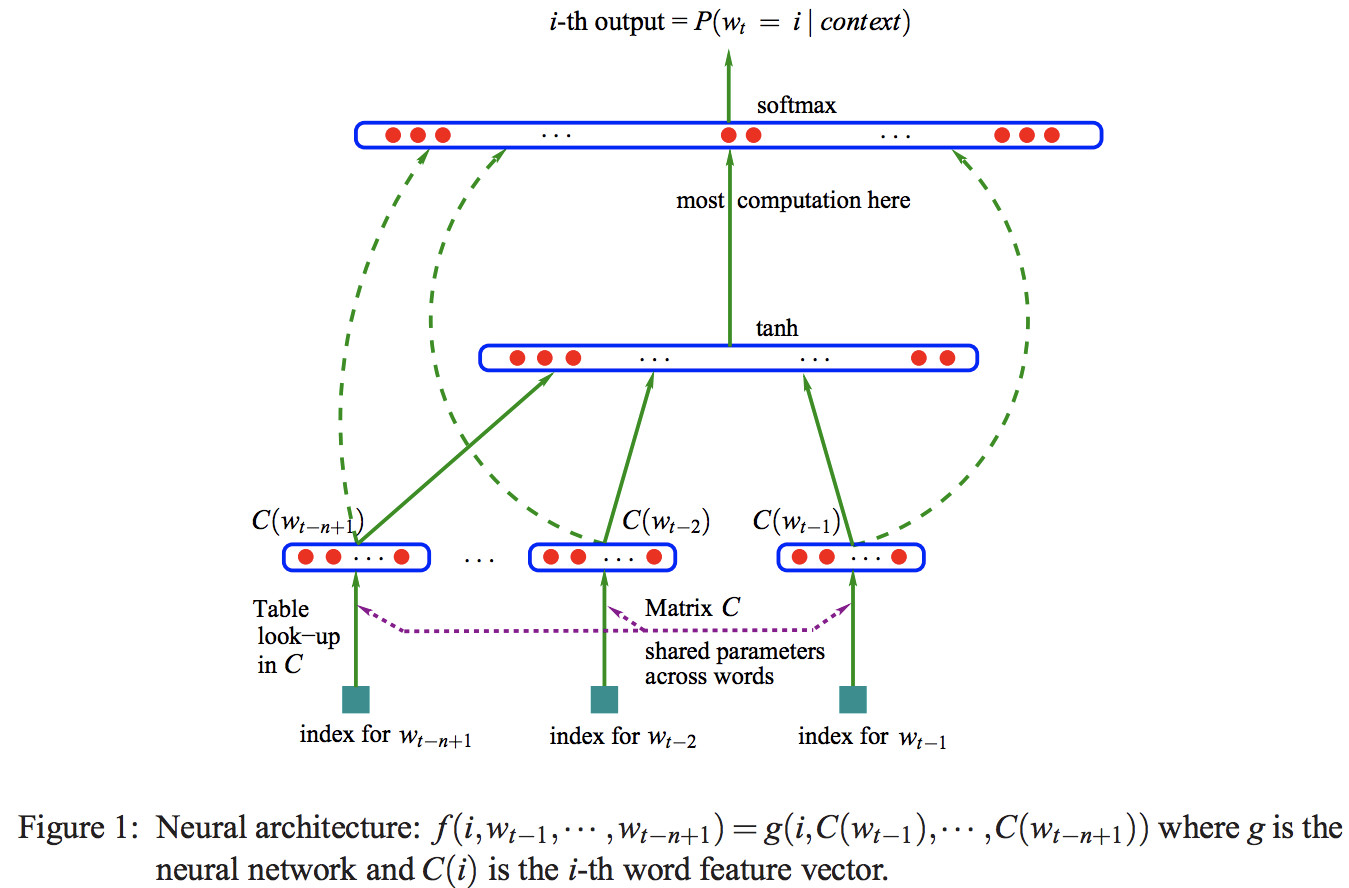
解决n-gram语言模型(比如tri-gram以上)的组合爆炸问题,引入词的分布式表示。
通过使得相似上下文和相似句子中词的向量彼此接近,因此得到泛化性。
相对而言考虑了n-gram没有的更多的上下文和词之间的相似度。
使用浅层网络(比如1层隐层)训练大语料。

feature vector维度通常在100以内,对比词典大小通常在17000以上。

C是全局共享的向量数组。
最大化正则log似然函数:
非归一化的log似然:![]()
![]()
hidden units num = h
word feature vector dimension = m
context window width = n
output biases b: |V|
hidden layer biases d: h
hidden to output weights U: |V|*h
word feature vector to output weights W: |V|*(n-1)*m
hidden layer weights H: h*(n-1)*m
word reature vector group C: |V|*m
Note that in theory, if there is a weight decay on the weights W and H but not on C, then W and H could converge towards zero while C would blow up. In practice we did not observe such behavior when training with stochastic gradient ascent.
每次训练大部分参数不需要更新。
训练算法:



可改进点:
1. 分成子网络并行训练
2. 输出词典|V|改成树结构,预测每层的条件概率:计算量|V| -> log|V|
3. 梯度重视特别的样本,比如含有歧义词的样本
4. 引入先验知识(词性等)
5. 可解释性
6. 一词多义(一个词有多个词向量)

