
如何从 Oracle 迁移到 Greenplum 第二篇

在上周和大家分享的《如何从 Oracle 迁移到 Greenplum 第一篇》中,我们介绍了 Greenplum 和 Oracle 的产品对比,迁移效果的几个关键因素。今天我们将在该系列的第二篇内容里,从迁移场景和迁移过程两个方面为大家继续介绍如何从 Oracle 迁移到 Greenplum 。
一
迁移场景
如下图所示,大部分场景都可以直接迁移到 Greenplum,但也有部分场景(如高并发事务型场景)不太适合迁移到目前的 Greenplum 5.X 版本。
|
Oracle 中应用场景 |
Oracle 中响应时间 |
迁移到 Greenplum 建议 |
|
分析型场景 |
1 秒以上 |
此类应用完全可以迁移至 Greenplum,迁移后性能会有较明显提升 |
|
并发小查询场景 |
1 秒以内 |
并发小查询场景包括小表全表扫描和大表索引扫描场景,迁移至 Greenplum 性能在同一量级,但因为数据节点交互,延迟会略有增加 |
|
并发数据加载场景 |
1 秒以内 |
可以迁移至 Greenplum,需要将逐笔插入操作改为微批量插入,由于 Greenplum MPP 架构优势,加载性能会有较明显提升 |
|
低并发事务型场景 |
1 秒以内 |
可以迁移至 Greenplum,需要做适当业务改造,将逐笔操作改为微批量操作 |
|
高并发事务型场景 |
1 秒以内 |
不建议迁移到 Greenplum,由于数据跨节点的网络交互和锁的问题,会导致性能有较大的损失,甚至无法满足业务要求。请关注 Greenplum 的研发进展和新版本特性,Greenplum 社区正在不断增强高并发事务型特性。 |
Oracle 到 Greenplum 迁移场景建议
用 ELT 替代 ETL
ETL 做为构建数据仓库的重要一环,承担了数据从 OLTP 系统到 OLAP 系统时重要的抽取、转换和加载工作。在银行等金融用户中,一般都是通过在 ETL 服务器上部署专门的 ETL 工具(如 informatic 或 datastage),将数据抽取到数据仓库中进行复杂分析计算,再将算好的结果推回到 OLTP 系统以完成在线处理。一般的处理流程如下图所示:
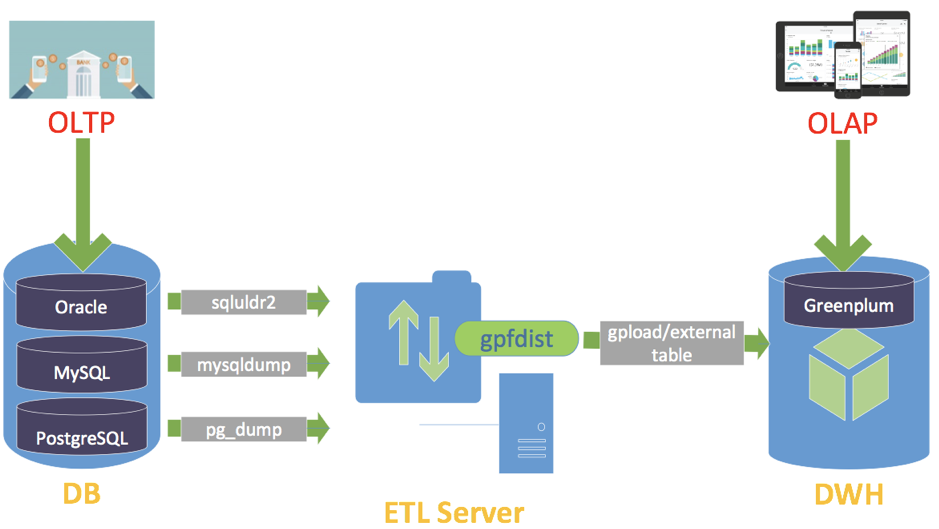
数据以 T-1 的方式加载到 Greenplum 集群
但受限于 ETL 服务器的硬件性能,在大数据量的抽取转换时性能较差,随着分布式数据库技术的发展和硬件计算能力的增强,越来越多的用户采用 ELT 的方式,将 ETL 中最为耗时的工作放在 OLAP 系统中完成。这样做,一方面减少了 ETL 服务器的工作负载,提升了数据的转换效率;另一方面可以利用数据库本身提供的丰富转换函数减少开发的工作量,如下图所示,转换过程可以在数据入库过程中完成,或者在库内完成,从而利用 MPP 并行的优势,提升转换性能。
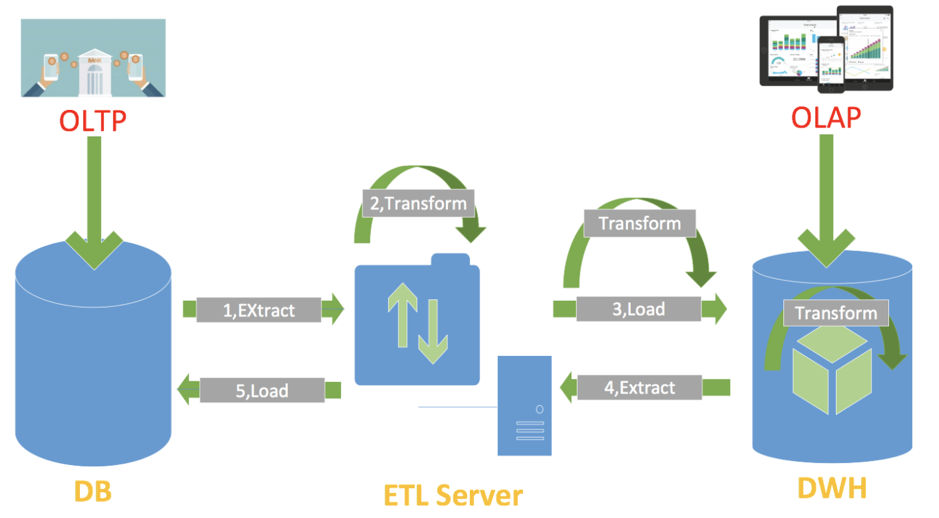
ETL 到 ELT
对于由 Oracle 到 Greenplum 的迁移,我们也推荐使用 ELT 的方式进行处理,如下图所示:
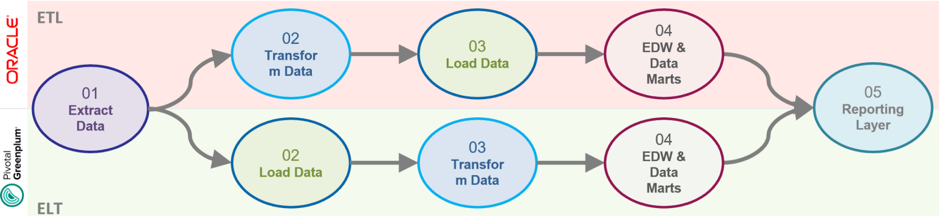
使用 ELT 流程代替 ETL
二
迁移过程
数据平台迁移主要包括元数据迁移、数据迁移、数据校验、应用验证、性能优化等阶段,关于性能优化可以参考最佳实践的文档。接下来主要介绍元数据迁移、数据迁移和数据校验。
一、元数据迁移
Oracle 到 Greenplum 没有现成的迁移工具,可以借助部分自动化转换工具先将 Oracle 语法转换为 PostgreSQL 语法,再通过脚本替换,最终转换成 Greenplum 语法。Oracle 到 PostgreSQL 常用的迁移工具有 ora2pg 以及 AWS Schema Conversion Tool。ora2pg 为命令行工具,只能从 Oracle 转换到 PostgreSQL;而 AWS Schema Conversion Tool (简称 AWS SCT)是为了方便用户数据上云,由 AWS 提供的图形化自动转换工具,可以在本地部署安装,安装部署过程简单,能生成详细的分析报告,并且支持多种数据平台的语法转换。根据我们在用户环境的验证,大概可以完成将近 70% 的语法自动转化工作。
关于 AWS SCT 安装和使用,可参考如下链接:
https://docs.aws.amazon.com/zh_cn/SchemaConversionTool/latest/userguide/Welcome.html
1) 配置好 Oracle 和 PostgreSQL 的 URL 连接串后,SCT 会自动检索并进行分析,生成评估转换报告,如下图所示。从报告可以看出,100% 的存储对象(如表、序列、约束)都可以直接进行转换,而存储过程还需要不少工作。
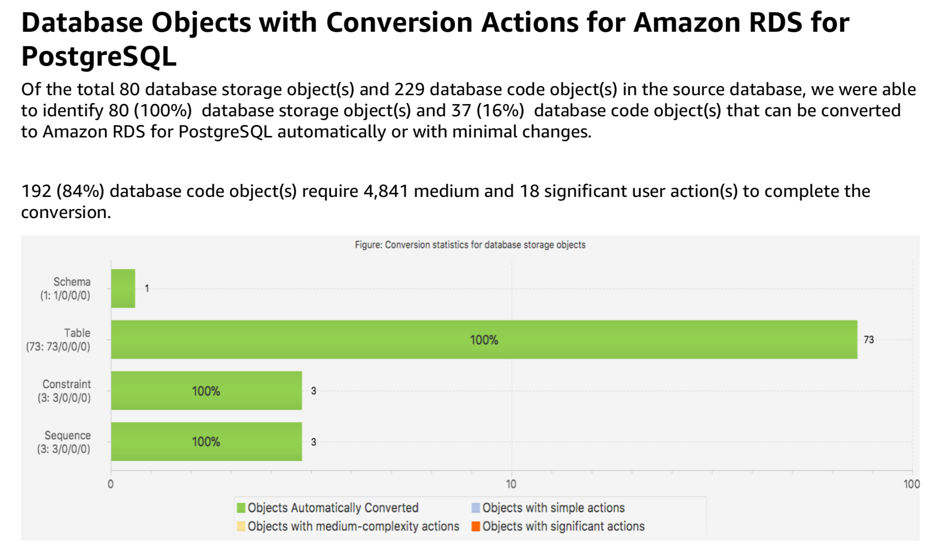
数据库存储对象转换评估报告
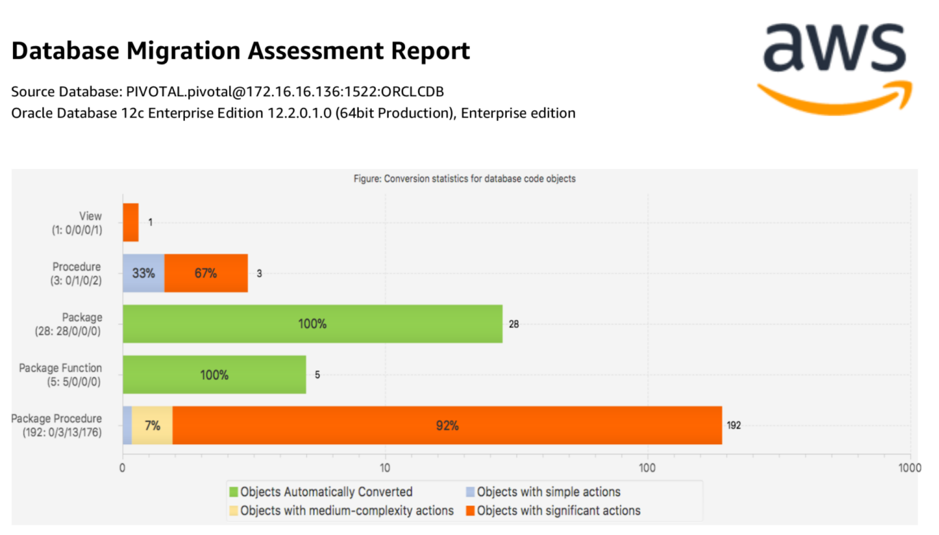
数据库代码转对象换评估报告
之后,我们点击应用就会在 PostgreSQL 数据库中创建对应的对象和函数。
SCT 会自动作类型转换,如果你想了解 Oracle 和 Greenplum 中不同数据类型具体的转换方式,可以参考下表:
|
Oracle |
Greenplum |
Comment |
|
VARCHAR2(n) |
VARCHAR(n) |
在 Oracle 中 n 代表的是字节数,在 Greenplum 中 n 代表的是字符数 |
|
CHAR(n) |
CHAR(n) |
同上 |
|
NUMBER(n,m) |
NUMERIC(n,m) |
number 可以转换成 numeric,但如果真实业务中数值类型可以用:smallint、 int 或 bigint 等替代,性能会有较大提升 |
|
NUMBER(4) |
SMALLINT |
_ |
|
NUMBER(9) |
INT |
_ |
|
NUMBER(18) |
BIGINT |
_ |
|
NUMBER(n) |
NUMERIC(n) |
如果 n>19,可以转换成 numerice 类型 |
|
DATE |
TIMESTAMP(0) |
Oracle 和 Greenplum 都有日期类似,但 Oracle 的日期类型会同时保存日期和时间,而 Greenplum 只保包存日期 |
|
TIMESTAMP WITH LOCAL TIME ZONE |
TIMESTAMPTZ |
注意:PostgreSQL 中 TIMESTAMPTZ 不等同于 Oralce 中的 TIMESTAMP WITH TIME ZONE |
|
CLOB |
TEXT |
PostgreSQL 中 TEXT 类型不能超过 1GB |
|
BLOB |
BYTEA(1 GB limit) |
在 Oracle 中 BLOB 用于存放非结构化的二进制数据类型,BLOB 最大可存储 128TB,而 PostgreSQL 中 BYTEA 类型最大可以存储 1GB,如果有更大的存储要求,可以使用 Large object 类型 |
Oracle 和 Greenplum 的字段类型映射表
2) 通过 pg_dump 导出元数据,命令如下:
pg_dump -s -n pivotal >pivotal.sql
3) 在 Greenplum 中导入元数据,命令如下:
psql –af pivotal.sql >import.log 2>&1
注意:如果是正式的项目迁移,需要根据之前的介绍,确定每张表的分布键和存储方式。如果只是做 POC 验证,可以先通过如下命令修改数据库参数,保证数据库采用建议的存储方式充分打散,然后再用上面语句进行恢复:
ALTER DATABASE pivotal SET gp_create_table_random_default_distribution=on;ALTER DATABASE pivotal SET gp_default_storage_options='appendonly=true,blocksize=32768,compresstype=zlib,compresslevel=5,checksum=true,orientation=row';
此外,还应注意以下事项:
1)在 Greenplum 中,所有的用户表都需要指定分布键。如果 Oracle 中有明确的业务主键,可以设其为分布键。如果没有,可以选择区分度高的字段作为分布键或者将分布方式设为 randomly。
2)在 Greenplum 中,如果因为业务需要指定主键字段,那么主键一定要包括分布键的所有字段,并与分布键定义的顺序一致,即如果主键是 (a,b,c),那分布键可以是 (a),(a,b),(a,b,c)。一般情况下,主键与分布键相同。
如下图所示,假如没有主键必须包括分布键的约束,c1 作主键、c2 作分布键。在插入第一条记录(1,2,3)时,根据 c2 字段计算哈希值后会把对应的记录存放在 p1 实例,在插入第二条记录(1,1,6)时,根据 c2 字段计算哈希值后会把对应的记录存放在 p2 实例。虽然在各个实例中,数据不会违反唯一性约束,但却违反了全局唯一性约束。
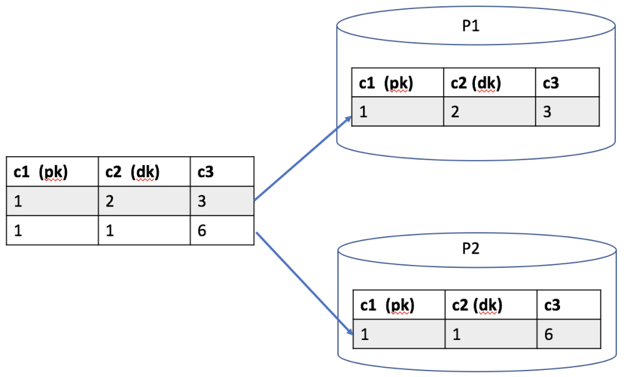
主键不包括分布键带来的问题
目前,Greenplum 版本要求分布键一定要是主键的左子集,否则会报如下错误:
pivotal=# CREATE TABLE test2(a int,b int,primary key (b,a)) DISTRIBUTED BY (a);ERROR: PRIMARY KEY and DISTRIBUTED BY definitions incompatibleHINT: When there is both a PRIMARY KEY, and a DISTRIBUTED BY clause, the DISTRIBUTED BY clause must be equal to or a left-subset of the PRIMARY KEY在即将发布的 Greenplum6.0 版本中,我们将该约束进一步放宽,只要分布键是主键的子集即可,在社区版本测试的结果如下图所示。
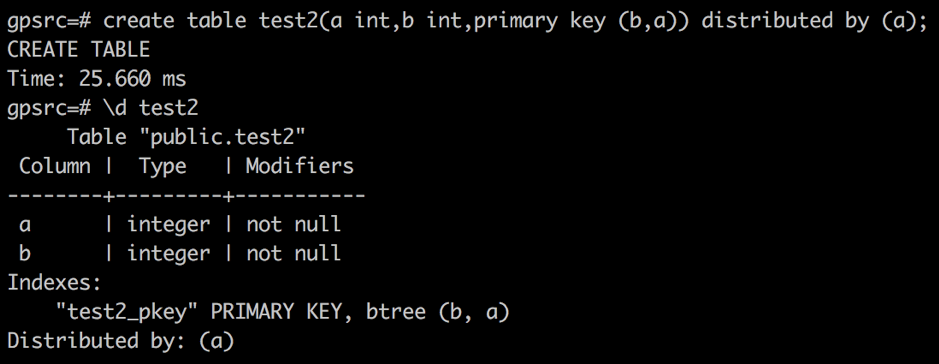
主键必须包括分布键
注意:对于 Greenplum 等分布式数据库,并不存在全局唯一的主键索引。要实现主键逻辑,都要借助分布键,要求主键必须包括分布键
3)Greenplum 中不支持外键约束,如果需要在 Greenplum 中做相关一致性数据约束,只能通过业务手段实现。 4)Greenplum 的每张表中最多只能有一个主键或者唯一约束。 5)Oracle 存储过程迁移到 Greenplum 时必须转换成函数。另外,在函数里面不能使用 begin 和 commit 做部分提交。在 Greenplum 中,默认函数作为一个完整的事务,如果函数在执行时报错,则整个事务会回滚。可以使用下图所示的方案进行改写。
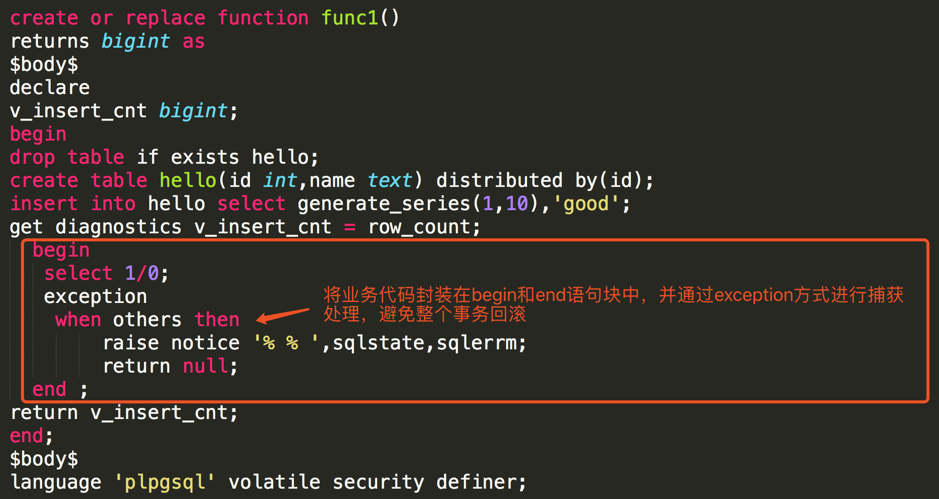
在函数中实现部分提交
执行后输出结果如下图所示。

部分提交的结果输出
注意:函数本质上还是一个事务,通过 exception 捕获,只是屏蔽掉了异常。让函数继续执行,如果在之后又遇见异常,前面做的操作仍然会被回滚,如下例所示。如果不将函数最外层的 SQL 封装在单独的 begin……exception……end 块中,一旦出现异常,前面的操作仍然会被回滚。

外层 SQL 异常,导致前面操作回滚
解决办法就是拆成多个业务处理块,每个块中都做异常捕获,如下图所示。
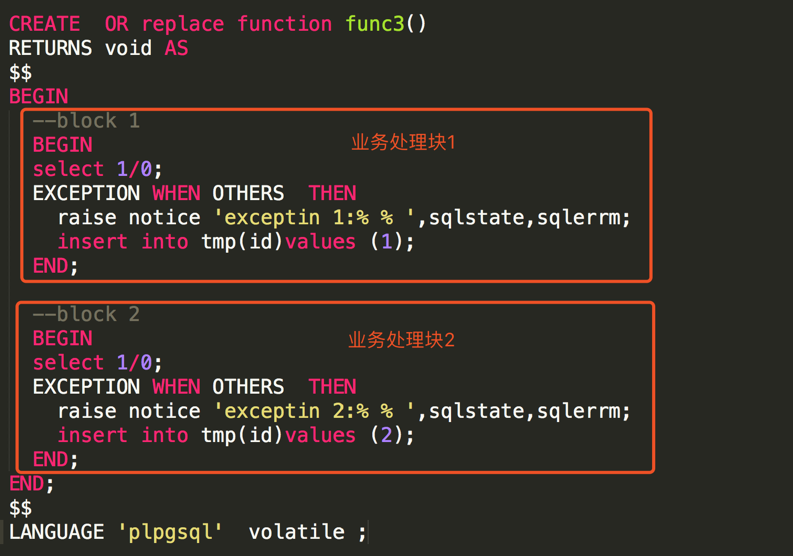
拆成多个语句块,避免操作回滚
如果要在函数中进行事务的控制,可以通过 dblink 的方式实现。Greenplum 5.x 版本之后,已经集成了 dblink 模块,首先通过如下命令安装 dblink 模块:
psql -af /usr/local/greenplum-db/share/postgresql/contrib/dblink.sql之后,通过 dblink 的方式实现函数中的事务控制,测试样例如下图所示:
注意:从 PostgreSQL 11 开始支持存储过程,可以实现 Oracle 同样的部分事务提交,随着 Greenplum 与 PostgreSQL 的不断融合,相信从 Oracle 迁移到 Greenplum 改写的工作量会越来越小。
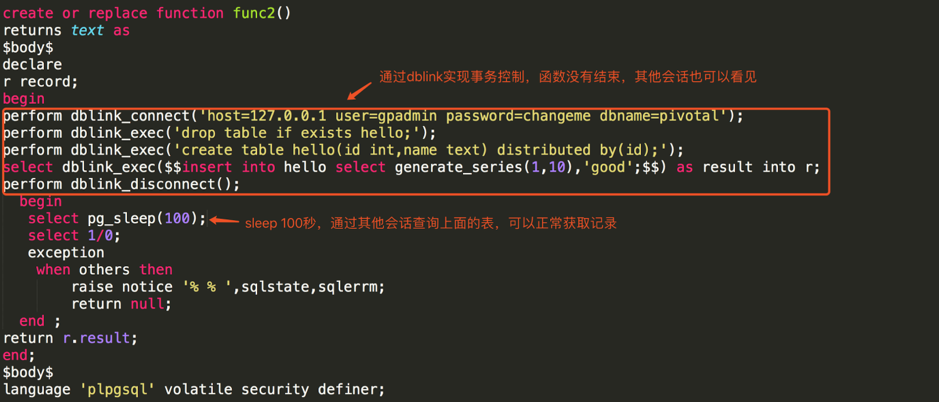
在函数中实现事务控制
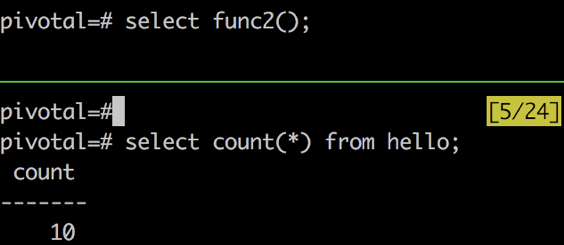
函数没有结束,其他会话也能看到已经提交的事务
二、数据迁移
数据迁移包括全量和增量数据迁移。进行全量迁移时,可以用 sqluldr2 工具先把数据以 csv 的格式导出,然后再通过 gpfdist 加载到 Greenplum 中。当然,也可以使用命名管道或者可执行外部表实现数据的不落地加载。但在真实业务场景中,通过管道会造成数据从 Oracle 导出到 Greenplum 紧耦合,一旦网络出现问题,会出现 pipe broken 的错误。另外,真实场景中不同表的加载作业一般不会有依赖,在数据导出的同时也会有数据导入,实测之后使用管道和文件落地后再加载性能并无太大差异,所以真实业务场景中大都采用文件落地的方式再导入到 Greenplum 中。
增量迁移一般借助 golden gate 等 cdc 软件尽量做到数据的实时捕获,再通过 gpfdist 加载到 Greenplum 中。曾经有用户以 250ms 的间隔通过 gpfdist 实时加载数据到 Greenplum 中,在 8 个计算节点的集群上速度可达到 200 万 /s。
具体步骤如下:
1)在 ETL 服务器上部署 sqludr 和 Oracle 用户端,命令如下:
wget http://www.onexsoft.com/software/sqluldr2linux64.zipvi $ORACLE_HOME/network/admin/tnsnames.ora
2)将数据导成 CSV 文件,命令如下:
export NLS_LANG="SIMPLIFIED CHINESE"_CHINA.ZHS16GBKsqluldr2 user='username'/'password'@tnsname query="select /* parallel(2) */ * from PICCPROD.T_CONTRACT_MASTER" text=CSV file="/data/ods/test.dat" log=/tmp/sqluldr2.log
3)创建外部表进行数据导入,命令如下:
CREATEcreate EXTERNALexternal TABLEtable ext.t_contract_master_ext (like t_contract_master) LOCATION('gpfdist://10.111.224.1:9999/T_CONTRACT_MASTER.dat') FORMAT 'CSV' (HEADER delimiter as ',') ENCODING 'GB18030' LOG ERRORS SEGMENT REJECT LIMIT 2 rows;
数据导入过程中常见问题总结如下:
问题一:"invalid byte sequence for encoding "GB18030": 0x00"
原因:PostgreSQL 不支持在文本字段中存储 NULL(\ 0x00)字符
解决办法:删除掉 NULL 字符,即
for i in *.dat;do tr < $i -d '\000' > nonull/$i & <&-;done问题二 :ERROR: Segment reject limit reached. Aborting operation. Last error was: character 0x809f of encoding "GB18030" has no equivalent in "UTF8" (seg21 slice1 10.111.224.3:40001 pid=11849)DETAIL: External table t_claim_case_ext, line 10862893 of file gpfdist://10.111.224.1:9999/T_CLAIM_CASE.dat
原因 :Oracle 原本数据库中有乱码,转换成 UTF8 的过程中报错
解决办法 :将原始文件中非 GB18030 编译的字符替换掉,即
/usr/local/bin/iconv -f GB18030 -t GB18030 --byte-subst="<0x%x>" T_CLAIM_CASE.dat具体字符集的介绍和转换过程可以参考如下链接:http://dewoods.com/blog/character-encodings-demystified
三、数据校验
完成新数据平台的搭建后,一般会和原有的数据平台并行运行一段时间,一方面是为了和原有平台进行业务和数据的比对,确保业务的正确性和连续性;另一方面,应用改造迁移是一个循序渐进的过程,在所有应用迁移完成前,原有数据平台还是要承担正常的业务访问。一般的做法是通过类似灰度发布的过程,开始的时候同时往两个平台写入数据,但只有原有数据平台对外提供业务访问,每天通过数据校验作业,比较两个平台的数据一致性。经过一段时间,确认数据没有问题后,再把对外访问的流量切换到新的数据平台,再经过一段时间撤除原有平台上的作业。
接下来以 Oracle 迁移到 Greenplum 为例介绍一下数据比对的方法。
首先,分别往 Oracle 和 Greenplum 中插入 Demo 数据:
--oracle
CREATE TABLE hello(id int,name varchar2(32),price number);INSERT INTO hello SELECT rownum,rownum,rownum*0.1 FROM dual Connect By Rownum <= 100;
--greenplum
CREATE TABLE hello(id int,name varchar(32),price numeric);INSERT INTO hello select i,i,i*0.1 FROM generate_series(1,100) i;方案 1,数据条数比对
这是最简单和常用的方法,就是在 Greenplum 和 Oracle 中比分别统计出数据表的条数,然后进行比对。如果条数匹配,就认为两边数据是一致的。这种方法的优点是效率很高,缺点是不能完全保证数据的一致性。
以测试数据为例,分别在 Oracle 和 Greenplum 中执行以下命令:
select count(*) from hello;输出结果分别如下图所示。
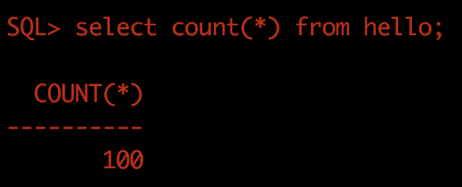
Oracle 中输出 count (*) 结果
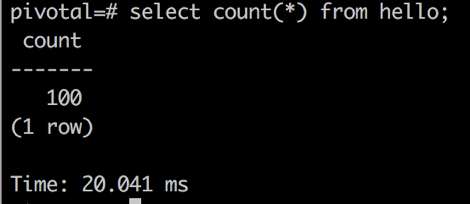
Greenplum 中输出 count (*) 结果
方案 2,数据条数比对 + 关键字段校验
在条数比对的基础上,再加上关键字段的校验,通过这种方法基本上可以确保数据的一致性。这种方法的缺点是需要业务方梳理相应的表,找出关键字段,对不同表写不同的比对语句。另外,也不能保证非比对字段的数据一致性。 以测试数据为例,分别在 Oracle 和 Greenplum 中执行以下命令:
select count(*),sum(price),avg(price) from hello;执行结果分别如下图所示。
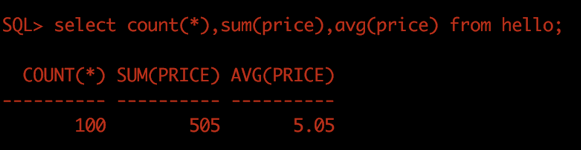
Oracle 输出特征值结果
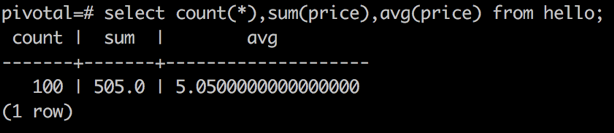
Greenplum 中输出特征值结果
方案 3,通过 md5 算法计算整表的 checksum
md5 算法有着非常悠久的历史,通常用来作为加密和验证数据文件是否被篡改的手段,并且具有跨平台和数据库的特点。很多数据库,如 PostgreSQL、MySQL、Oracle,都有对应的函数实现。
以测试数据为例,分别在 Oracle 和 Greenplum 中执行以下命令:
--Oracle
WITH foo AS (SELECT stragg(lower(standard_hash(id||name||to_char(price,'fm999999990.999999999'), 'MD5')) order by lower(standard_hash(id||name||to_char(price,'fm999999990.999999999'), 'MD5')) asc) AS total_md5 from hello ) SELECT lower(standard_hash(total_md5, 'MD5')) AS md5 FROM foo;--Greenplum
WITH foo AS (select string_agg(md5(id||name||to_char(price,'fm999999990.999999999')) order by md5(id||name||to_char(price,'fm999999990.999999999')) asc) AS total_md5 FROM hello) SELECT md5(total_md5) AS md5 FROM foo;
执行结果分别如下图所示。
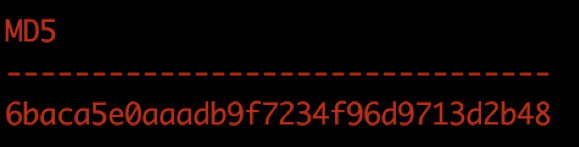
Oracle 中全字段算 md5 结果
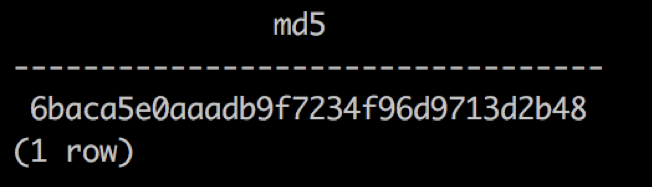
Greenplum 中全字段算 md5 结果
通过查询数据字典,将上述过程封装成 pl/pgsql 和 pl/sql 过程语言,就可以实现表的 md5 值计算。其优点是对应用入侵较小,具有通用性,可以做全字段比对;缺点是需要对数据进行排序,比对过程较慢,即使使用 Greenplum,最终 md5 值的计算也要汇总到 master 节点进行全局排序。而且,当表非常大时,string_agg 会报内存不足的错误。另外,如果有中文等特殊字符,要求 Oracle 和 Greenplum 有相同的数据库端编码,否则显示出的字符看起来一致,但由于底层字节码不同,也会导致 md5 值不一样。
方案 4,将每行计算出的 md5 值转换为 4 组数值类型,最终将 sum 后的结果作为整表的 checksum 值
由于 md5 是 128 位的十六进制编码,需要转换为 4 组 32 位编码的数值类型。通过这种方式,不需要进行全局排序,性能大大提升,另外也克服了 string_agg 和 md5 函数对内存使用的限制,但中文等特殊字符的编码限制仍然存在。
以测试数据为例,在 Oracle 下运行以下命令:
--Oracle
WITH foo AS (SELECT standard_hash(''||id||name||to_char(price,'fm999999990.999999999'),'MD5') AS hash FROM hello),foo1 as (SELECT sum(to_number(substr(hash, 1, 8),'xxxxxxxx')) AS hash_p1,sum(to_number(substr(hash, 9, 8),'xxxxxxxx')) AS hash_p2,sum(to_number(substr(hash, 17, 8),'xxxxxxxx')) AS hash_p3,sum(to_number(substr(hash, 25, 8),'xxxxxxxx')) AS hash_p4 FROM foo)SELECT lower(standard_hash(sum(hash_p1)||sum(hash_p2)||sum(hash_p3)||sum(hash_p4),'MD5')) AS md5 FROM foo1;
运行结果如下图所示。
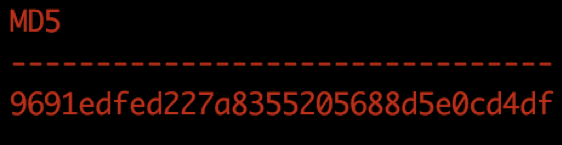
Oracle 中经过性能优化后算 md5 结果
在 Greenplum 下运行以下命令:
--Greenplum
WITHwith foo ASas (SELECTselect md5(''||id||name||to_char(price,'fm999999990.999999999')) ASas hash FROMfrom hello),foo1 ASas (SELECTselect sum(('x' || substring(hash, 1, 8))::bit(32)::bigint) ASas hash_p1,sum(('x' || substring(hash, 9, 8))::bit(32)::bigint) as hash_p2,sum(('x' || substring(hash, 17, 8))::bit(32)::bigint) ASas hash_p3,sum(('x' || substring(hash, 25, 8))::bit(32)::bigint) ASas hash_p4 FROMfrom foo)SELECTselect md5(''||sum(hash_p1)||sum(hash_p2)||sum(hash_p3)||sum(hash_p4)) ASas md5 FROMfrom foo1;运行结果如下图所示。
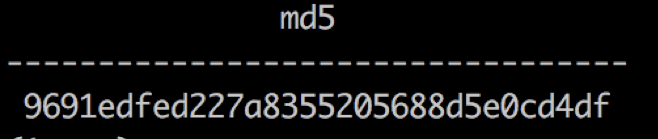
Greenplum 中经过性能优化后算 md5 结果
如果发现表的数据不一致,接下来要定位到具体的记录。当数据量非常大时,通过人工或外部程序进行比对都不太现实,这时候可以利用 Greenplum 强大的并行计算能力,通过两表关联来比对每行的 md5 值,找出具体的差异。
以测试数据为例,命令如下:
WITH oracle_checksum AS (SELECT id,md5(textin(record_out(foo2))) AS row_md5 FROM ora_hello AS foo2),gp_checksum AS (SELECT id,md5(textin(record_out(foo3))) AS row_md5 FROM gp_hello AS foo3),compare_result AS (SELECT oracle_checksum.id AS ora_id ,oracle_checksum.row_md5 AS ora_md5,gp_checksum.id AS gp_id,gp_checksum.row_md5 AS gp_md5 FROM oracle_checksum full outer join gp_checksum on oracle_checksum.row_md5=gp_checksum.row_md5)SELECT * FROM compare_result WHERE ora_md5 is null or gp_md5 is null;
总之,用户可以根据具体的业务要求和数据平台选择不同的数据比对方案。一般来说,选择方案 2 的用户较多,因为该方案不依赖底层数据平台,也不依赖具体数据库端的编码,数据一致性和性能都能得到较好的保证。但缺点是,在一些特殊情况下并不能保证数据完全一致,在 Greenplum 数据库中可以将方案 4 封装成如下的 checksum 函数来判断表中数据是否发生变化,从而扩展出更多的应用场景。 在 8 个计算节点的 Greenplum 真实用户环境下,计算 1.5 亿记录的 checksum 值只需要 10 秒。
CREATE OR REPLACE FUNCTION checksum(tablename character varying)RETURNS text AS$BODY$DECLARE v_tablename varchar := $1; v_md5 varchar; v_check_sql varchar;BEGIN v_check_sql := $$with foo as (select md5(textin(record_out(foo2))) as hash FROM $$||v_tablename ||$$ as foo2), foo1 as (select sum(('x' || substring(hash, 1, 8))::bit(32)::bigint) as hash_p1,sum(('x' || substring(hash, 9, 8))::bit(32)::bigint) as hash_p2,sum(('x' || substring(hash, 17, 8))::bit(32)::bigint) as hash_p3,sum(('x' || substring(hash, 25, 8))::bit(32)::bigint) as hash_p4 from foo) select md5(''||sum(hash_p1)||sum(hash_p2)||sum(hash_p3)||sum(hash_p4)) from foo1;$$; EXECUTE v_check_sql INTO v_md5; RETURN v_md5;END;$BODY$LANGUAGE 'plpgsql' immutable ;
下周,我们将在第三篇中,为大家分析 Oracle 迁移到 Greenplum 的特殊场景。
本文摘录自 Greenplum 官方教材《Greenplum:从大数据战略到实现》,点击阅读原文获取购买链接。

