
MySQL迁移OpenGauss原理详解
MySQL迁移OpenGauss原理详解
原创MySQL迁移OpenGauss原理详解
通过本文,掌握MySQL和openGauss之间数据迁移和校验的实现原理,了解openGauss工具一体化平台Datakit,并能运用该平台进行数据迁移。
1. 数据迁移概述
1.1 数据迁移
数据迁移是指将数据从一个数据库迁移至另一个数据库,按照数据库类型来分类,可分为同构数据库之间的迁移和异构数据库之间的迁移。
- 按照数据的流向来分类,数据迁移分为数据导出和数据导入两种操作,通常会存在一种中间态文件,例如SOL文件、CSV文件等,中间态文件可保存在磁盘上,需要时再导入目标数据库中,可实现数据导出与导入的解耦。
- 按照迁移是否停止应用来分类,数据迁移分为冷迁移和热迁移。冷迁移即为停服迁移,其操作简单,但需停止业务,不适用于实时在线业务:热迁移对用户业务影响较小,业务应用无感知,但迁移过程相对比较复杂。
- 同构数据库迁移相对比较简单,可借助备份恢复技术(逻辑备份恢复和物理备份恢复)实现迁移。
- 异构数据库迁移相对比较复杂,需综合考虑异构数据库的兼容性、选型、应用改造成本、迁移成本、性能等众多因素。
- 主要介绍异构数据库(MySQL->openGauss)之间的热迁移。
1.2 数据迁移五部曲
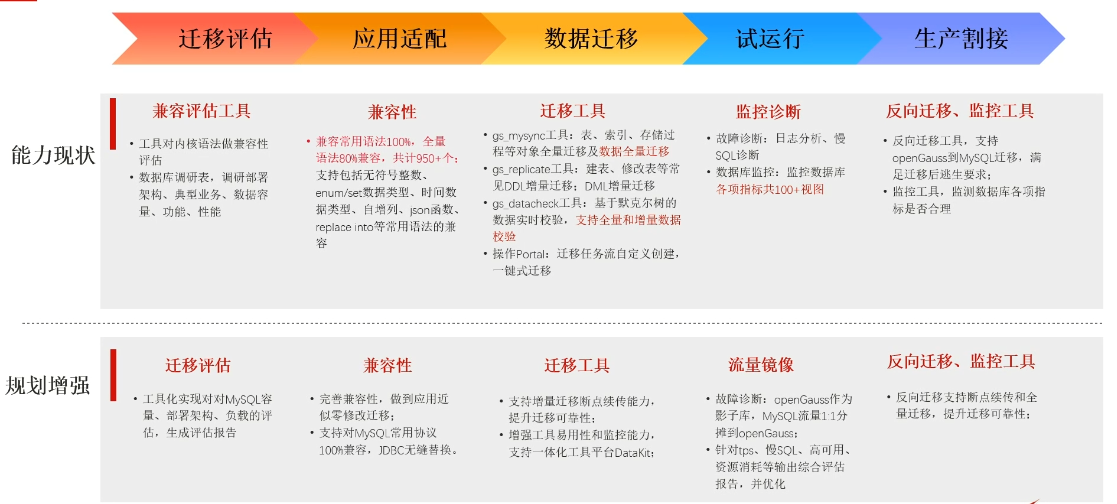
1.3 小结
本章节主要对数据迁移进行概述,并介绍了数据迁移的五步曲,包括迁移评估应用适配、数据迁移、试运行、生产割接五个步骤,并对openGauss现有具备的迁移能力进行总结。
2. openGauss迁移工具集
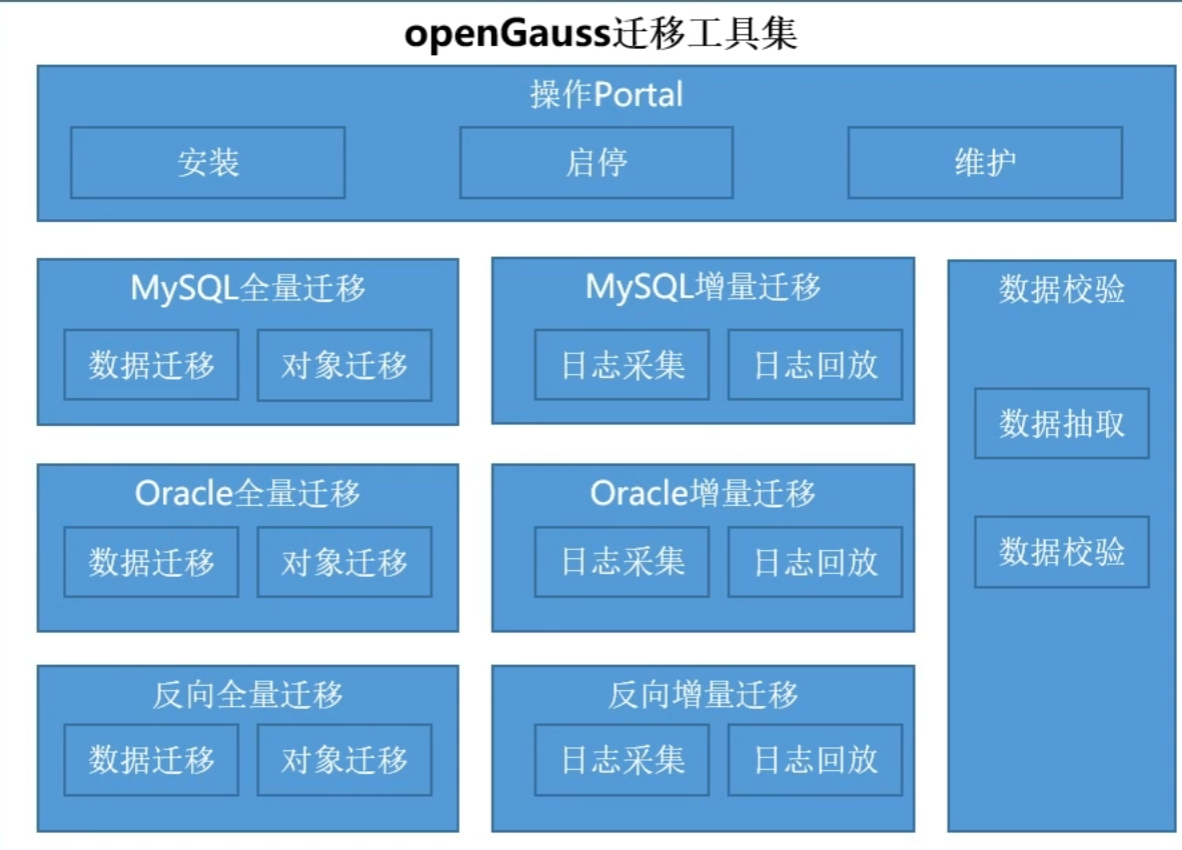
openGauss迁移工具集包含:
- 全量迁移工具:支持基于快照点的全量数据迁移和对象迁移,支持MySQL、Oracle、反向 (openGauss->MySQL) 等的全量迁移;
- 增量迁移工具:支持基于日志的增量数据和DDL操作迁移,支持MySQL、Oracle、反向 (openGauss->MySQL) 等的增量迁移;
- 数据校验:支持MySQL与openGauss之间的全量和增量数据校验;4.操作Portal:独立的命令行工具,采用JAVA程序开发,主要完成对上述工具的安装、启停、维护等:
安装:可以指定安装某个工具,也支持设定执行计划,例如: 安装MySQL全量迁移工具->安装MySQL增量迁移工具->安装数据校验工具操作Porta1支持按照该计划顺序完成操作;
启停:可以指定运行某个工具,也支持设定执行计划,例如: 运行MySQL全量迁移->运行全量数据校验->运行MySQL增量迁移->运行增量数据校验->···,操作Porta1支持按照该计划顺序完成操作;
维护:操作Portal监控工具的运行情况,在监测到工具异常时能尝试恢复工具,支持采集工具运行进度
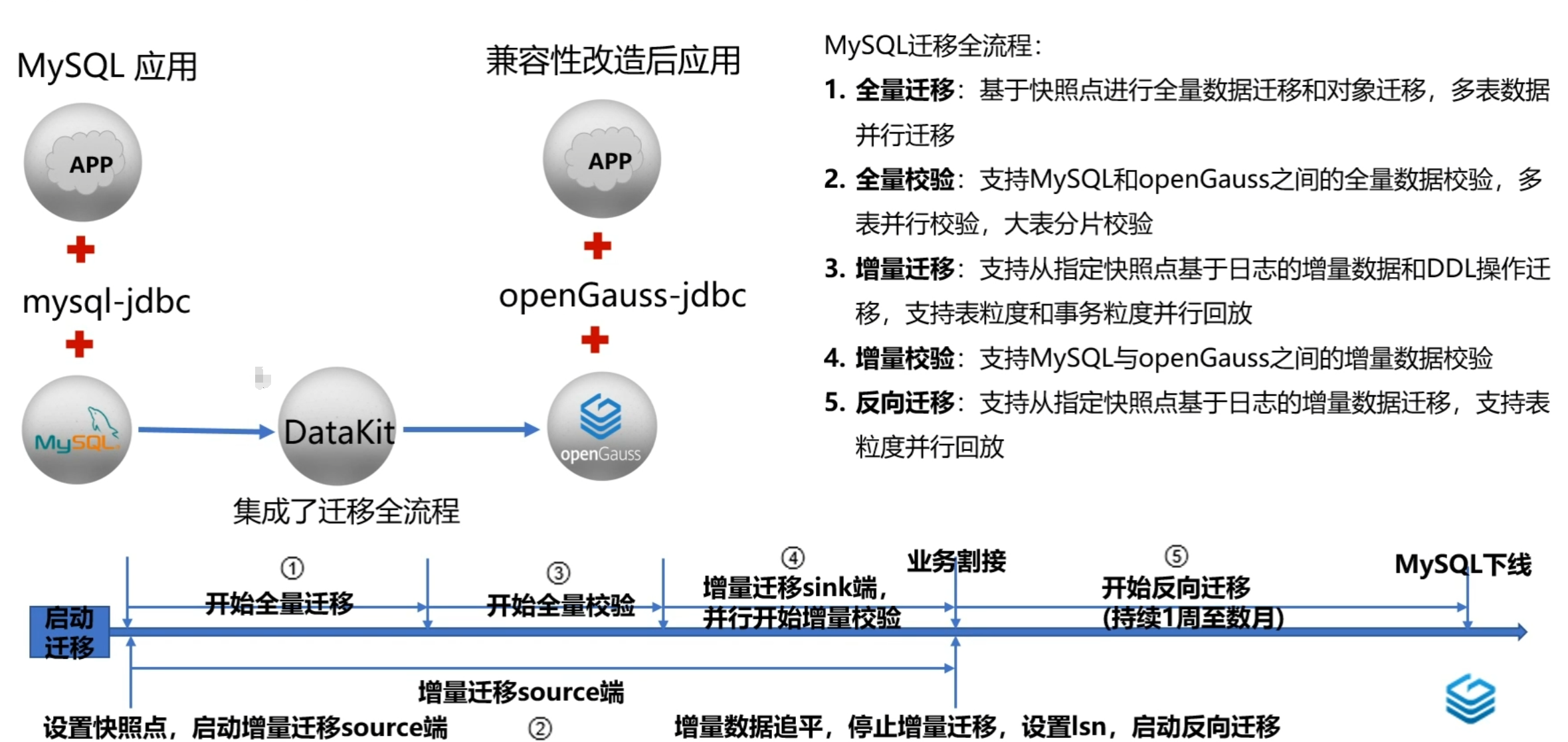
- DataKit平台:以UI界面展示MySQL迁移全流程,简单易操作,过程可观测。
2.1 全量迁移gs_mysync
- 全量迁移将MySQL端已有数据和对象迁移至openGauss端。当前openGauss社区官网提供全量迁移工具gs mysync,本质为chameleon工具,其由python语言开发
- 全量迁移支持的数据及对象:表、约束、索引、外键、表数据、函数、存储过程、触发器、视图。
- 全量迁移的性能:sysbench测试模型,10张无主键表,单表数据量500w,20个读写并发线程迁移,整体性能可达300M/s。
- 全量迁移实现原理: (1)采用多进程读写分离实现,生产者从MySQL侧读取数据写入CSV文件,消费者读取CSV文件写入openGauss,多个表并行处理 (2) 针对大表,会将其分成多个CSV文件,默认一个CSV文件2M (3) 迁移顺序:表结构->表数据->表索引
- 全量迁移实现逻辑: (1)记录全量迁移开始快照点 (2)创建目标schema及表结构,不包含索引(3)创建多个读写进程,主进程针对每个表创建一个读任务,加入读任务队列 (4)读写进程并行执行,读进程记录每个表的快照点,读取表数据存入多个csv文件;写进程同时copy csv文件至目标数据库 (5)数据迁移完成后创建索引 (6)所有任务完成后关闭读写进程
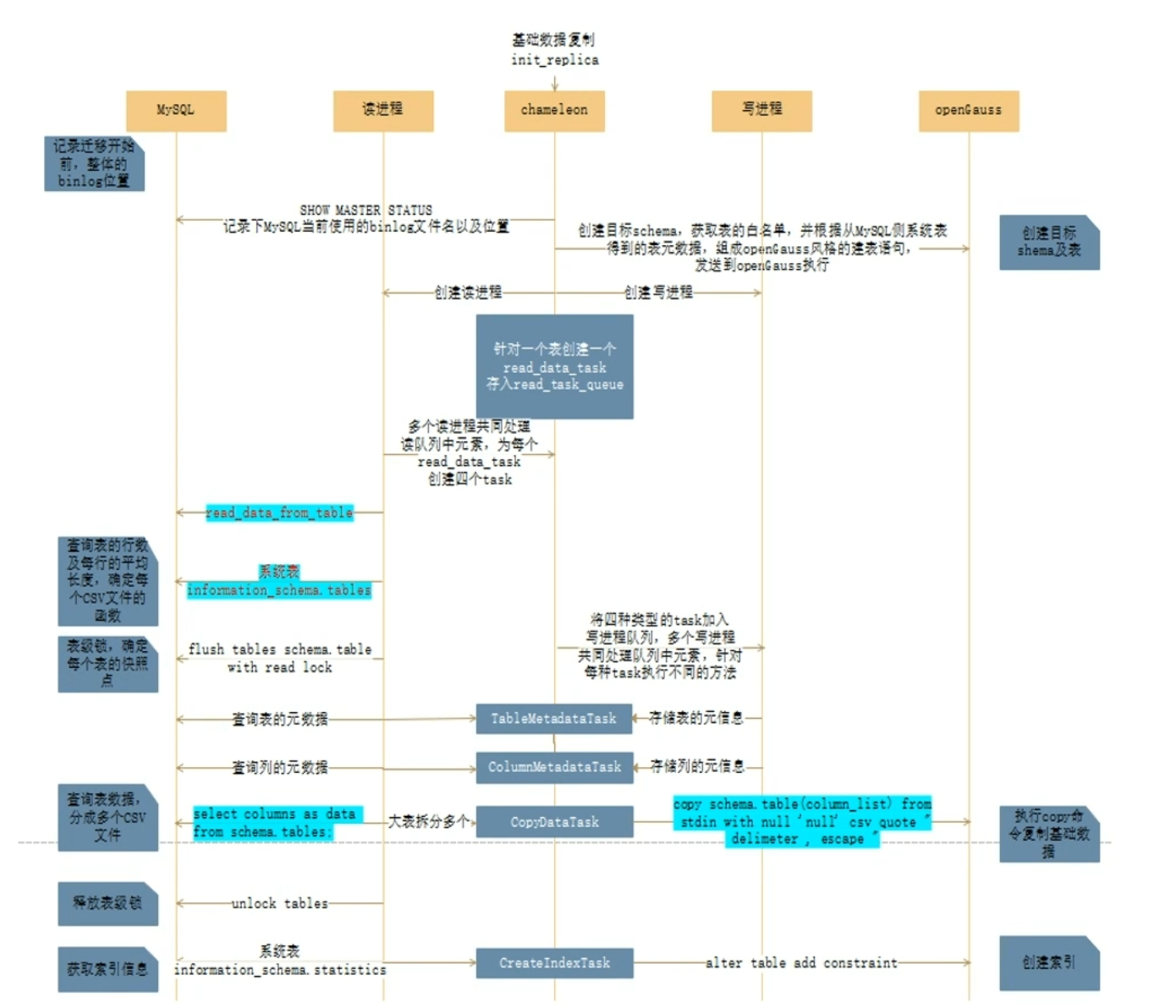
- 约束及限制 (1) openGauss端创建B兼容库进行迁移 CREATE DATABASE opengauss database WITH dbcompatibility='B' (2) 迁移时大小写严格保持一致为保证大小写-致,还移时需保证MySQL的大小写参数lower case table names和openGauss的大小写参数dlphin.lower case table names保持致。 其中0表示大小写敏感,1表示大小写不敏感。 对象迁移前需创建和MySQL对象所属definer同名的用户例如MySQL中view1所属的definer= mysql test @%,则在移前需在penGauss端创建5definer同名的用户'mysql test @%,并赋予一定的权限(至少对迁移后对象所处的schema要有创建权限),否则将导致对象迁移失败
- 使用指南 https://gitee.com/opengauss/openGauss-tools-chameleon/blob/master/chameleon%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97.md
2.2 增量迁移gs_replicate
- 增量迁移将MySQL端产生的增量数据(JD操作及DDL)迁移至openGauss端。当前openGauss社区官网提吾言开发。供增量迁移工具gs replicate,其由Java语言开发
- 实增量迁移实现原理:基于debezium+kafk (1) debezium mysql connector的source端,监控mysO格式写入到kafka;数据库的binlog日志,并将数据(DDL和DML操作)以AV AVRO格式数据(DDL和DML操作),并组装为事务,在o(2) debezium mysql connector的sink端,从kafka读取oenGauss端按照事务粒度并行回放,从而完成数据(DDL和DML操作)从mysql在线迁移至openGauss端 (3)由于该方案严格保证事务的顺序性,因此将DDL]DML路由在kafka的一个topic下,且该topic的分区数只能为1(参数num.partitions=1),从而保证source端推送到kafka,和sink端从kafka拉取数据都是严格保序的
- 利用sysbench对MyS梁作系统下,针对混合IUD场景,10张表50个线程 (insert-30戈程,update-10线程,delete-10线程),在迁移性能可达3w tpssink端日志回放双并行增量迁移并行机制:source端日志解析Source端并行原理
- 开源组件mysql-binlog-connector-java用于解Tmysql端的binlog日志为event,原始实现方案为串于解析,通过对源代码进行修改,支持并行解析event事件,以提高debezium mysql connector作为source端的性能
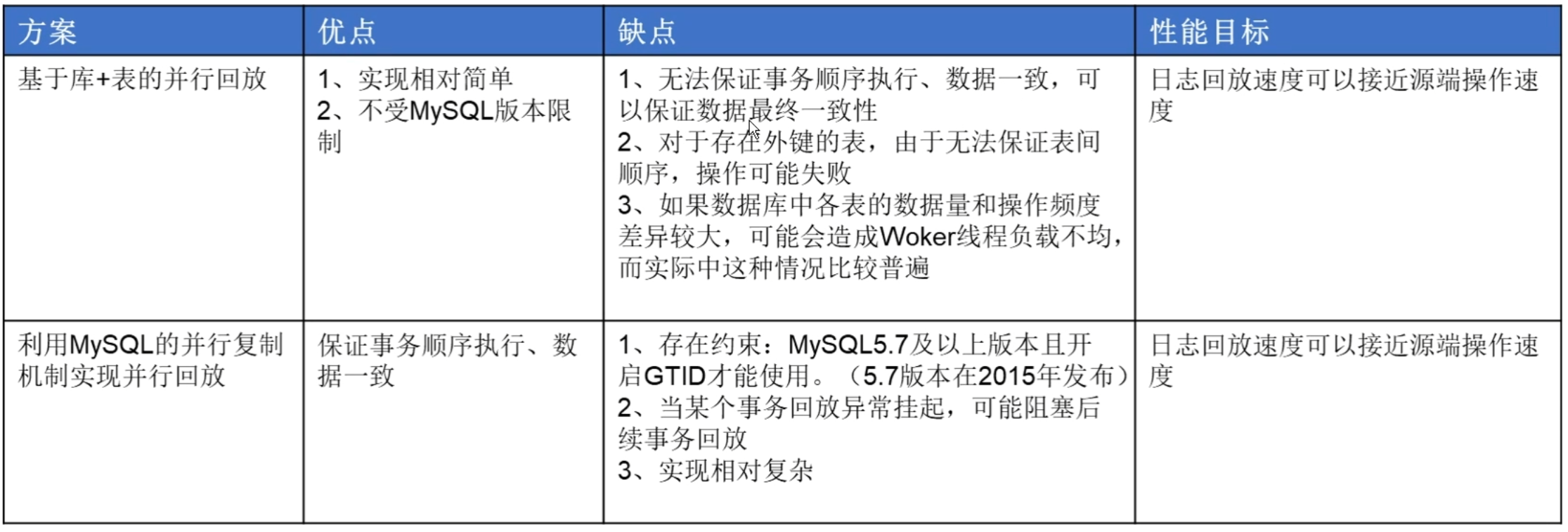
- 提供两种并行回放的机制 (1)事务粒度并行回放:基于MySQL的主备并于复制机制实现并行回放 行回放
(2)表级粒度并行回放:基于表粒度并行实现
- 事务粒度并行回放:基于MySQL的主备并行复制机制实现并行回放
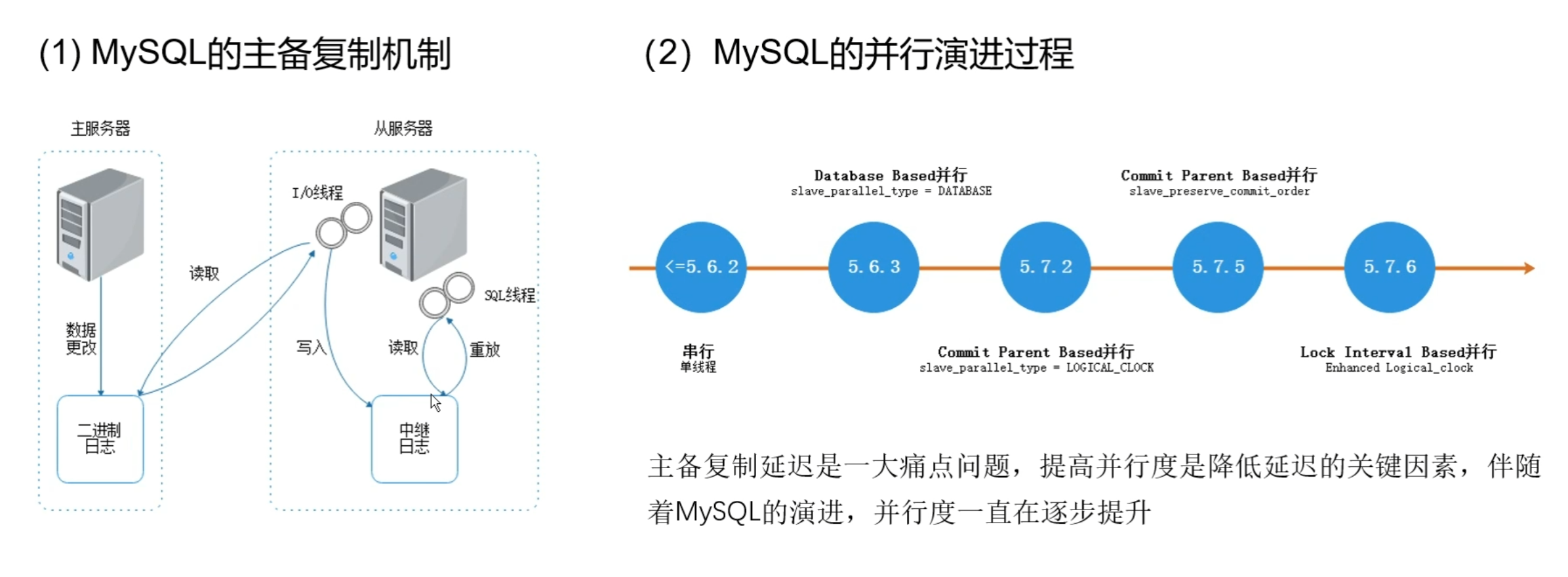
- 事务粒度并行回放:基于MySQL的主备并行复制机制实现并行回放

- 事务粒度并行回放:基于MySQL的主备并行复制机制实现并行回放
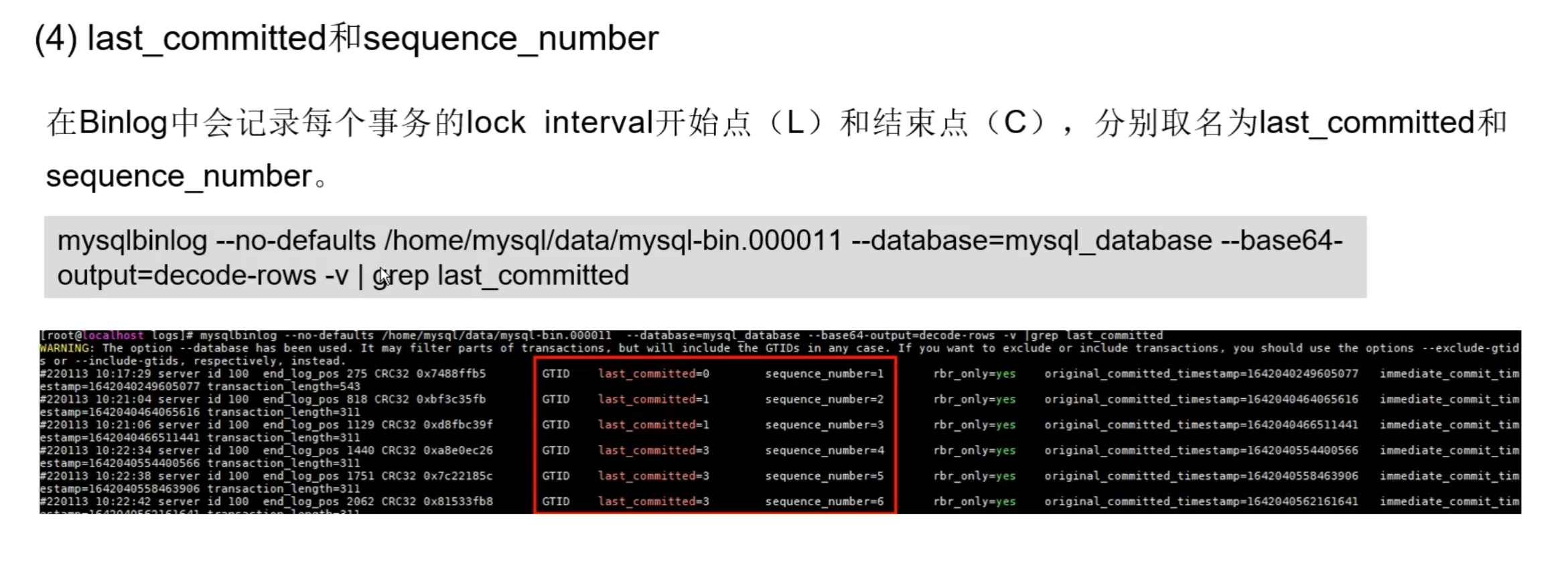
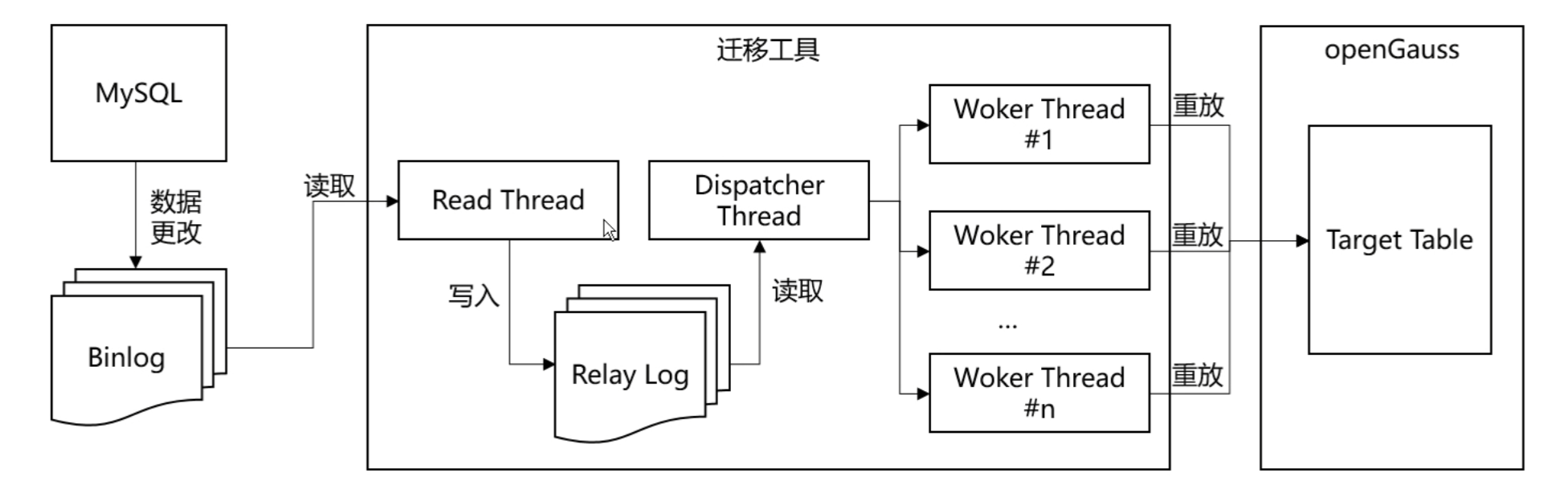
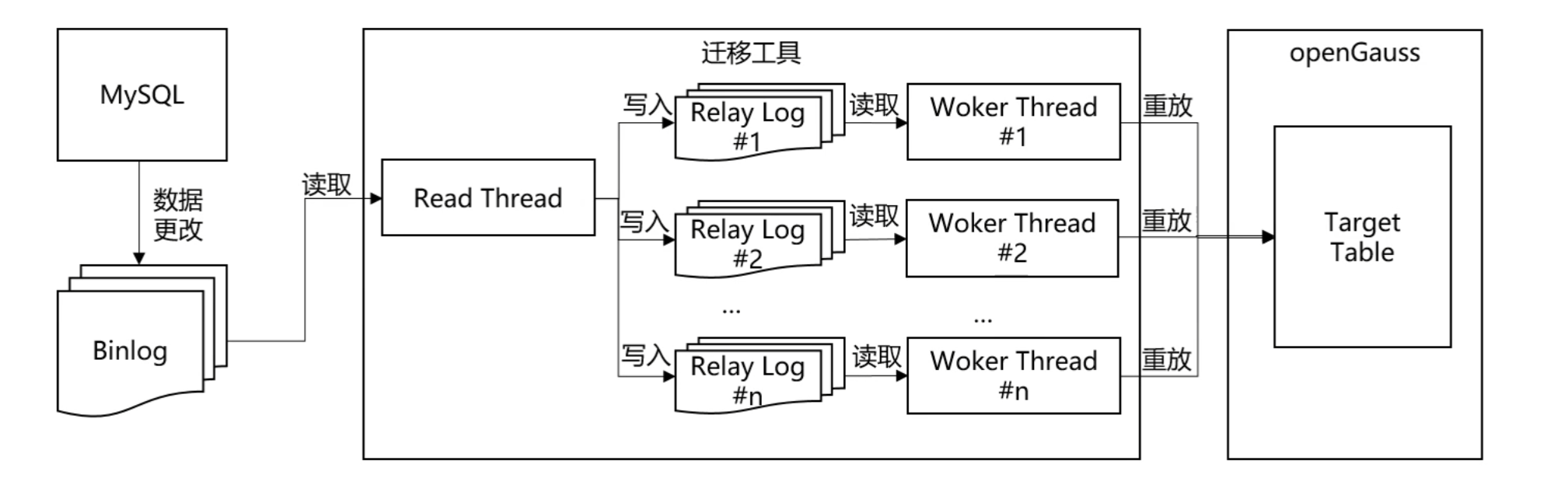
- 启动一个 Dispatcher线程负责分发待回放日志。每获取一条日志,需判断它是否能与当前正在回放的事务并行执行,判断规则为:如果所有正在回放的事务的最小sequence number大于该事务的last committed,那么该事务就可以并发执行。
- 如果能并行则直接从Woker线程组中寻找一个空闲线程处理,如果不能并行则等待,直到满足条件后,再从Woker线程组中寻找一个空闲线程处理。
- 如果没有空闲Woker线程,需要等待,直到有事务回放完释放Worker线程。
- 两种并行方案对比
- 约束及限制 (1)MySQL5.7及以上版本; (2) MySQL参数配置: log bin=on binlog format=row binglog_row_image=full gtid mode=on #若未开启该参数,则sink端按照事务顺序串行回放,会降低在线迁移性能 (3)支持DML和DDL迁移,在线迁移直接透传DDL,于openGauss和MySQL不兼容的语法,DDL迁移会报错
- 使用指南
https://gitee.com/openGauss/debezium/blob/master/README.md
- 增量迁移与全量迁移的配合
(1)启动全量迁移全量迁移使用chameleon完成,全量迁移启动后,可在openGauss端的表sch chameleon.t replica batch中查询到全量迁移的快照点,单个表的快照点存储在 sch chameleon.t replica tables中。
(2)启动source端
启动source端开始前,需首先启动zookeeper,kafka,并注册schema。查询到全量迁移的快照点后,即可在source端的配置文件mysa-source.properties中配置全量迁移的快照点,并启动source端,无需等待全量迁移结末后才可启动source端。全量迁移启动后,即可启动source端,这样可以尽可能减少source端的时延,以达到减少迁移延迟的目的。启动source端后,针对全量迁移的表,若对其的DML事务位于表的快照点之前,将跳过对应的DML操作,避免数据出现重复,可保证迁移过程中数据不丢失,不重复。
(3)全量迁移结束,启动sink端
等待全量迁移结束后,即可启动sink端回放数据。
若在全量迁移未结束时,就启动sink端,将会导致数据乱序,属于不合理的操作步骤,实际操作过程应避免不合理的操作。
2.3 反向增量迁移gs_replicate
反向增量迁移工具介绍
- Source端实现原理
获得二进制流式数据,进行解析反向增量迁移source端在源库建立逻辑复制槽和发布订阅,
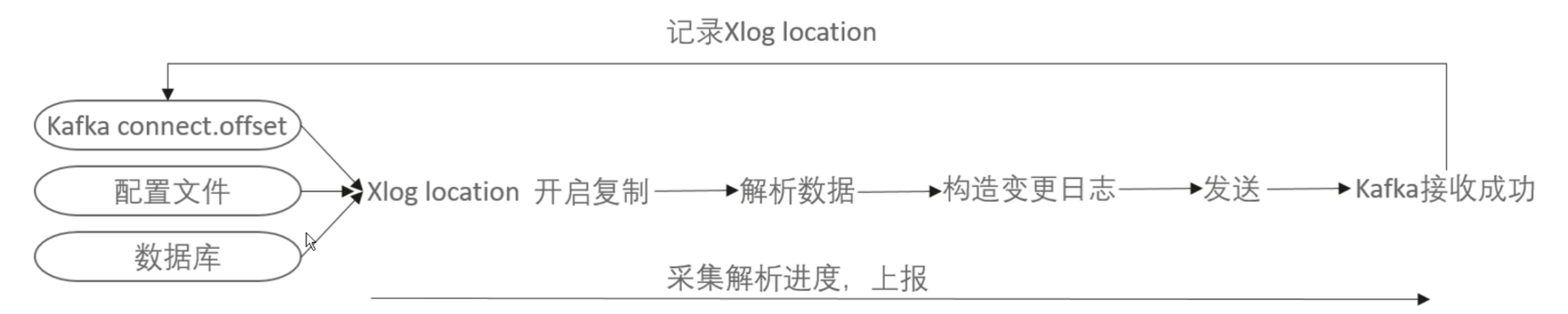
source端支持从自定义的Xlog位置开始复制,在一个迁移任务中,正向增量迁移结束时会输出Xlog位置,反向增量迁移从该位置开始复制,保证了迁移任务由正向同步切换至反向同步的过程中数据不重不漏。
- Sink端实现原理
反向增量迁移sink端从kafka抽取变更记录,按表并行构造sql语句并连接到目标库执行。
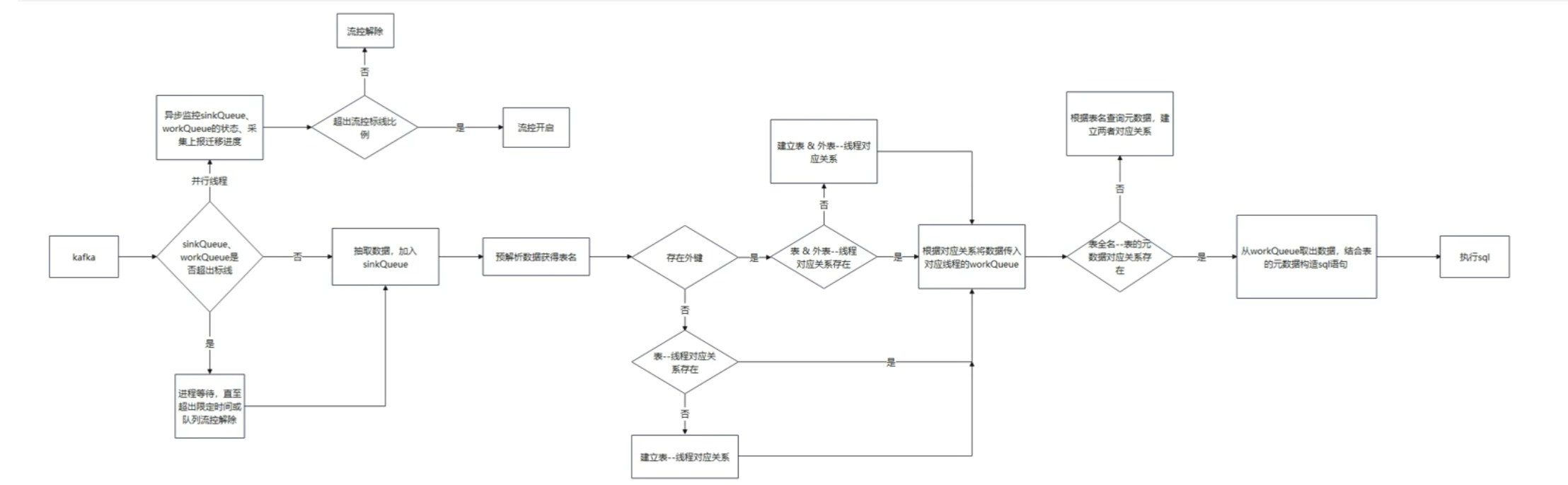
Sink端从kaka抽取变更记录时,同时监控内存中待回放数据量的大小,若数据量过大,则暂停抽取,直至待处理数据量减少到一定程度。分发数据时,不同表的变更记录优先在不同的线程中执行,若表之间有依赖,则在同一个线程执行。对于执行失败的sgl语句,工具会定时输出到本地文件。
- 约束与限制
(1)openGauss需开启逻辑复制功能,修改GUC参数wal level=logical,且仅限拥有REPLICATION权限的用户进行操作;
(2)需要调整数据库节点下的pg_hba.cnf以允许复制(这里的值取决于实际的网络配置及用于连接的用户);

(3)openGauss的库与逻辑复制槽一一对应,当待迁移的库发生变化时,需重新配置逻辑复制槽的名字;
(4)反向增量迁移暂不支持对DDL操作的迁移;
(5)支持的源端库需openGauss 3.0.0及以上版本。
2.4 校验工具gs datacheck
校验工具实现原理
- 校验工具 gs datacheck 采用JDBC方式抽取数据
- 对表原始数据进行Hash计算,并将中间态数据暂存到kafka Topic中。
- 使用源端和目标端的中间态数据同时构建两颗Merkle树并进行比较,从而实现了对源端数据库和目标端数据库数据一致性校验。
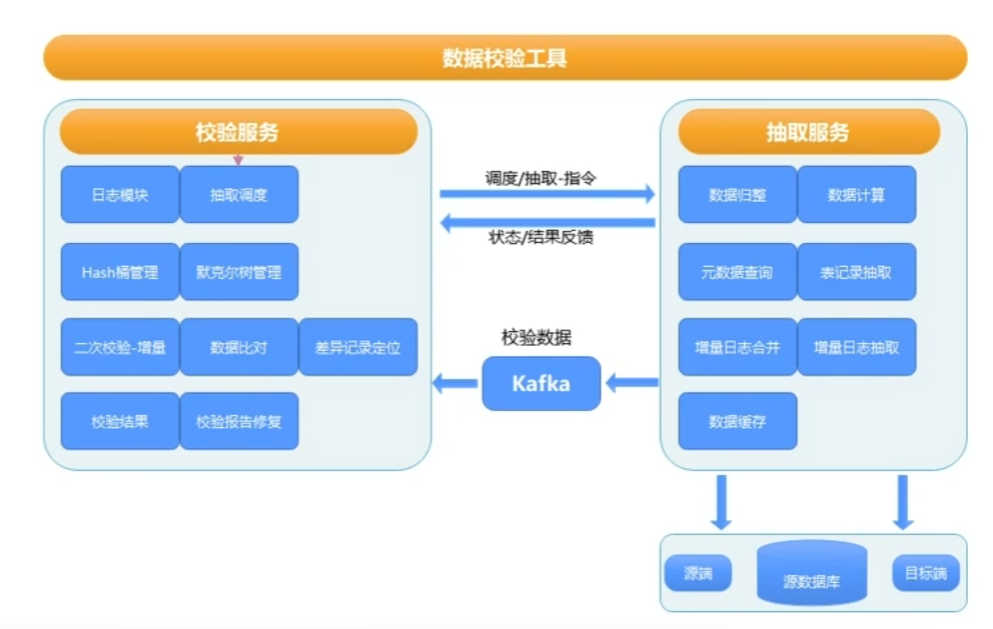
技术框架采用 SpringBoot 、 kafka中间件、debezium
开源社区地址: https://gitee.com/openGauss/openGauss-tools-datachecker-performance
- 全量数据校验 将MySQL源端和openGauss目标端数据通过分片方式抽取出来后进行规整,计算(hash),并将数据推送到kaka暂存Check服务即校验服务提取kafka中的数据,并对提取到的数据进行校验。输出校验结果,将校验结果输出到指定路径的文件中。
- 增量数据校验 通过debezium监控源端数据库的数据变更记录
源端抽取服务按照一定的频率(时间+数量两个纬度)处理监听到的变更记录,对变更记录进行统计合并。将合并结果发送给数据Check服务。
Check服务会对上次校验结果与当前增量数据进行合并
根据合并之后的结果,Check服务发起增量数据抽取、校验、并将校验结果输出到指定路径文件
- 规则过滤 新增了表、行、列三种类别的过滤规则
- 全量校验流程
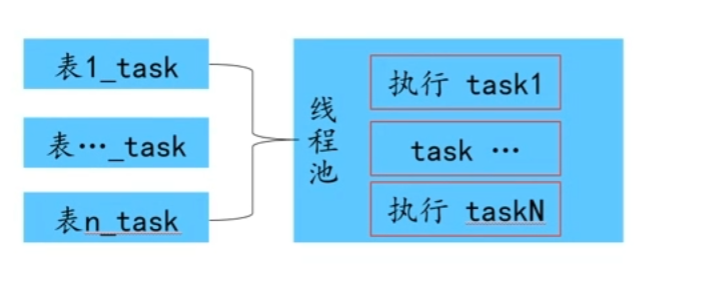
查询源端和目标端元数据信息information schematables,information schema.columns,获取全部待校验表信息根据待校验表构建抽取任务和校验任务
对表记录数较小的表采用全表查询方式,对于大表则自动分解为多次抽取(通过where条件划分多个分片)。
将表数据抽取后进行规整(标准化处理),计算(hash),并将最终处理后的Hash数据推送到kafka暂存。表记录数较少则将topic为单一topic分区,记录数较多则将数据存储在topic多个分区。
抽取服务会给每张表分别创建一个topic,且源端和宿端分别使用不同的topic。
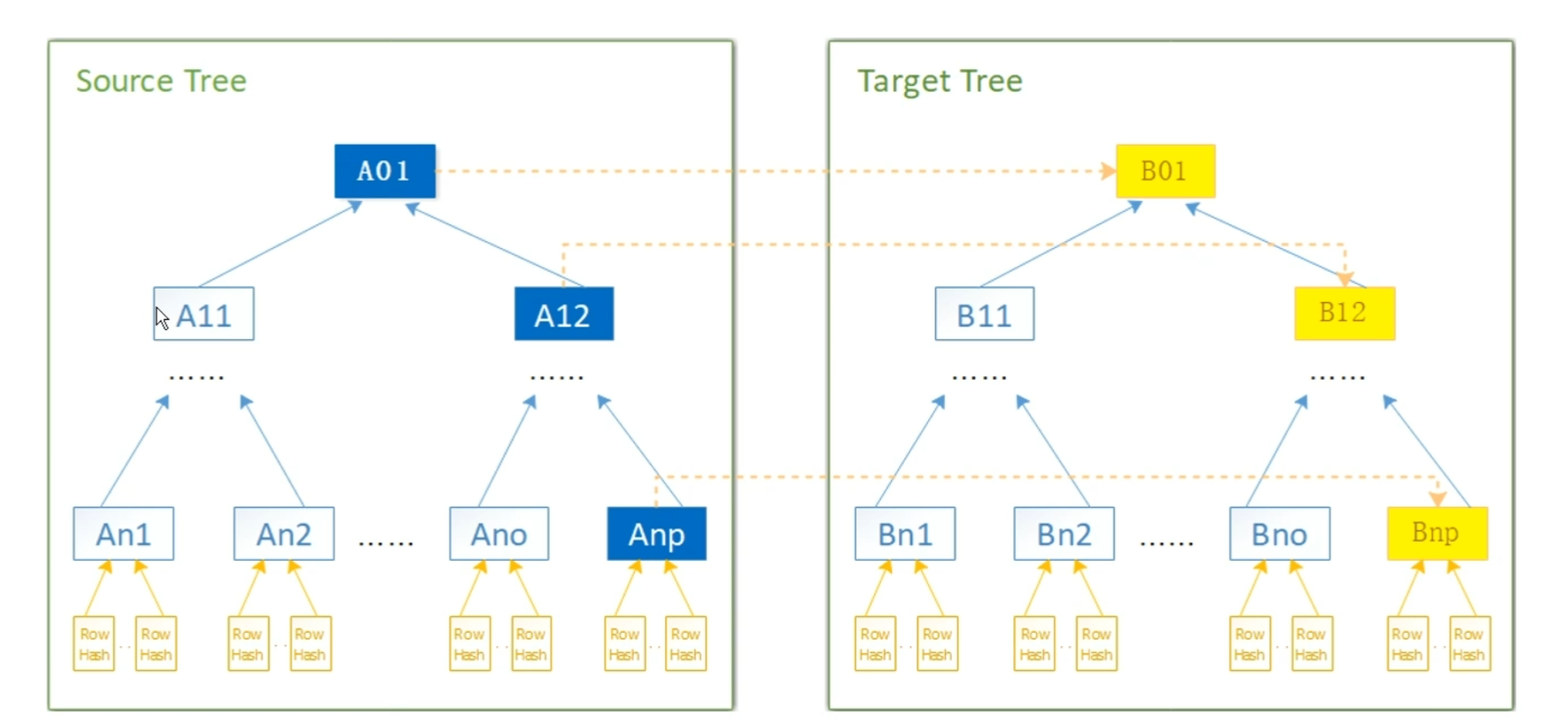
Check服务以表为单位提取kafka中的数据进行校验。获取指定表源端和目标端Topic数据,分别构建两棵默克尔树。默克尔树构建成功后,通过对比两颗默克尔树完成表数据校验。
输出校验结果,将校验结果输出到指定路径的文件中。
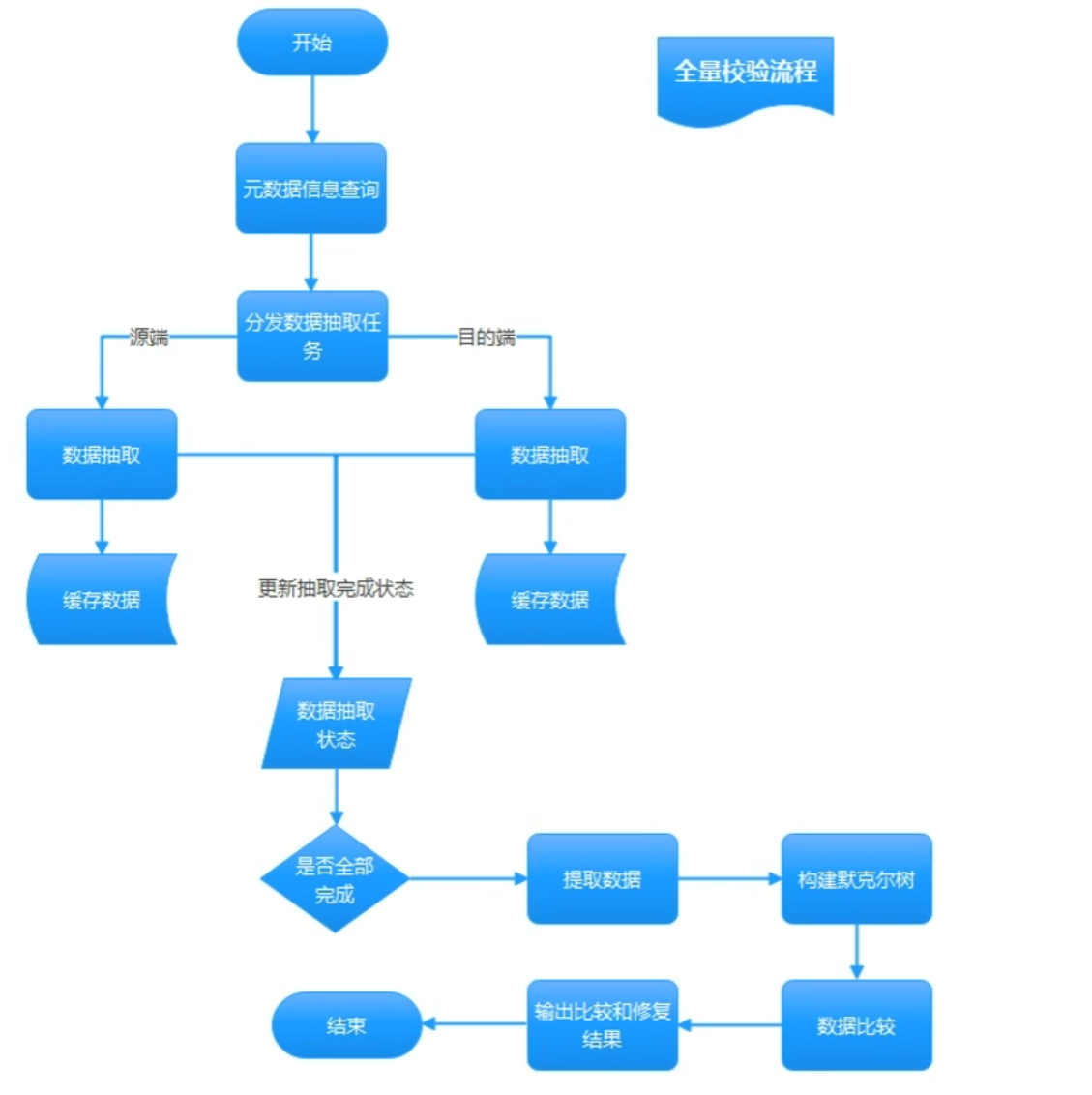
- 数据抽取服务,是根据表元数据信息构建数据抽取任务。通过JDBC方式从数据库抽取表数据,并对数据进行规整和计算并将计算结果以表为单位,存储在kafka中。每张表创建一个topic。
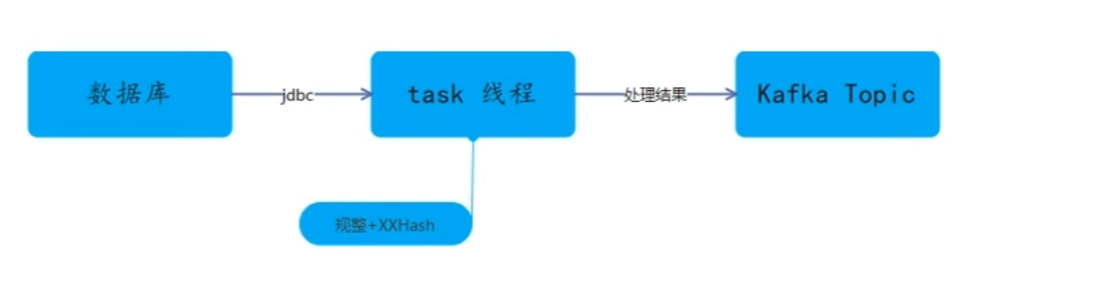
- 多表之间并行抽取,单个表根据数据量大小判断是否开启并行抽取。 当表记录数大于指定记录阀值时,自动对当前任务进行分片,开启并行抽取。
- 数据校验HASH算法:采用xxHash算法 中性能最优XXH3算法 xXHash 是一种极快的哈希算法,在 RAM 速度限制下运行。它成功完成了评估哈希函数的碰撞、分散和随机性质量的SMHasher测试套件。代码是高度可移植的并且哈希值在所有平台上都是相同的。xXHash目前有4种实现:XXH32、XXH64、XXH128、XXH3 性能最优的是XXH3.
- 过滤规则分为三类,表过滤规则,行过滤规则,以及列过滤规则。 (1)表规则,即添加表的黑白名单,通过黑白名单(正则表达式)过滤是否校验那些表 (2)行规则,即对指定范围的表添加行记录筛选,获取表的部分数据进行数据校验。 (3)列规则,即对指定表添加列字段过滤规则,只校验当前表的部分字段数据。 (4)表和行过滤规则是根据正则表达式进行匹配,列过滤规则是根据表名进行匹配,过滤规则在抽取服务加载元数据信息时进行触发,并执行。
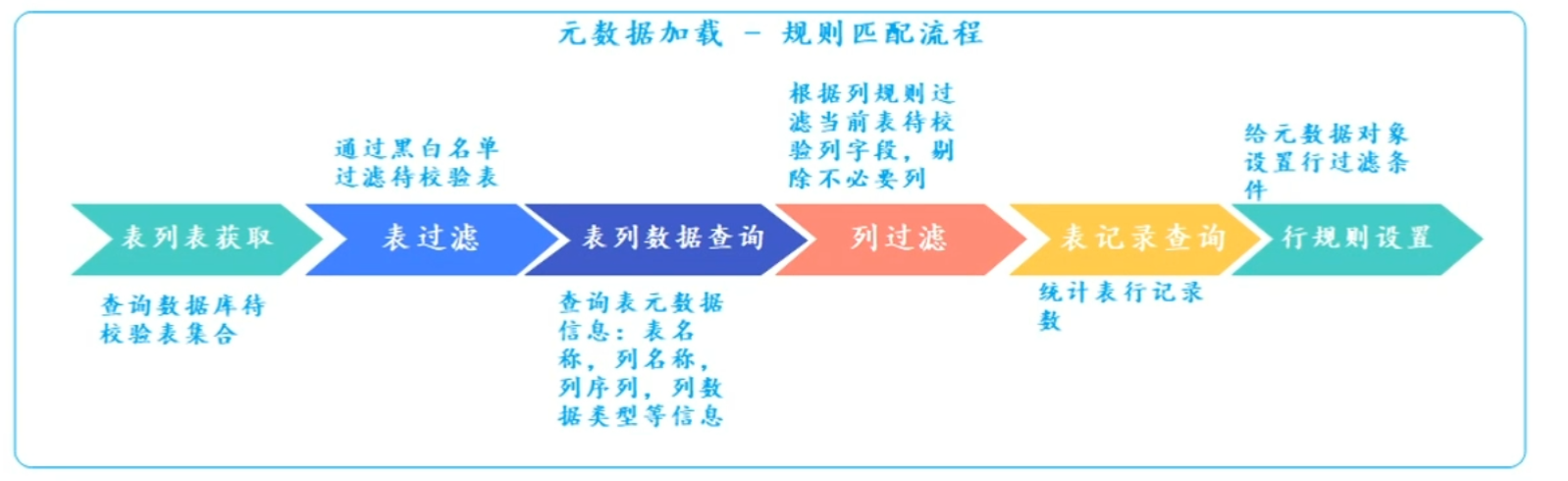
- 默克尔树 (1) Merkle Tree是一种树,大多数是二叉树,也可以是多叉树。 (2) Merkle tree的叶子节点的Value是数据集合的单元数据或者单元数据的HASH。非叶子节点的Value是根据它下面的叶子节点值,按照HASH算法计算得出的。创建Merkle tree是O(n)的复杂度,树高是loa(n)+1。
(3)两个节点间数据进行比对时,从Merkle tree的根节点进行对比,根节点一致不再做任何处理:不一样,遍历Merkle tree定位不一致的节点。定位速度快定位的时间复杂度是O(log(n))。
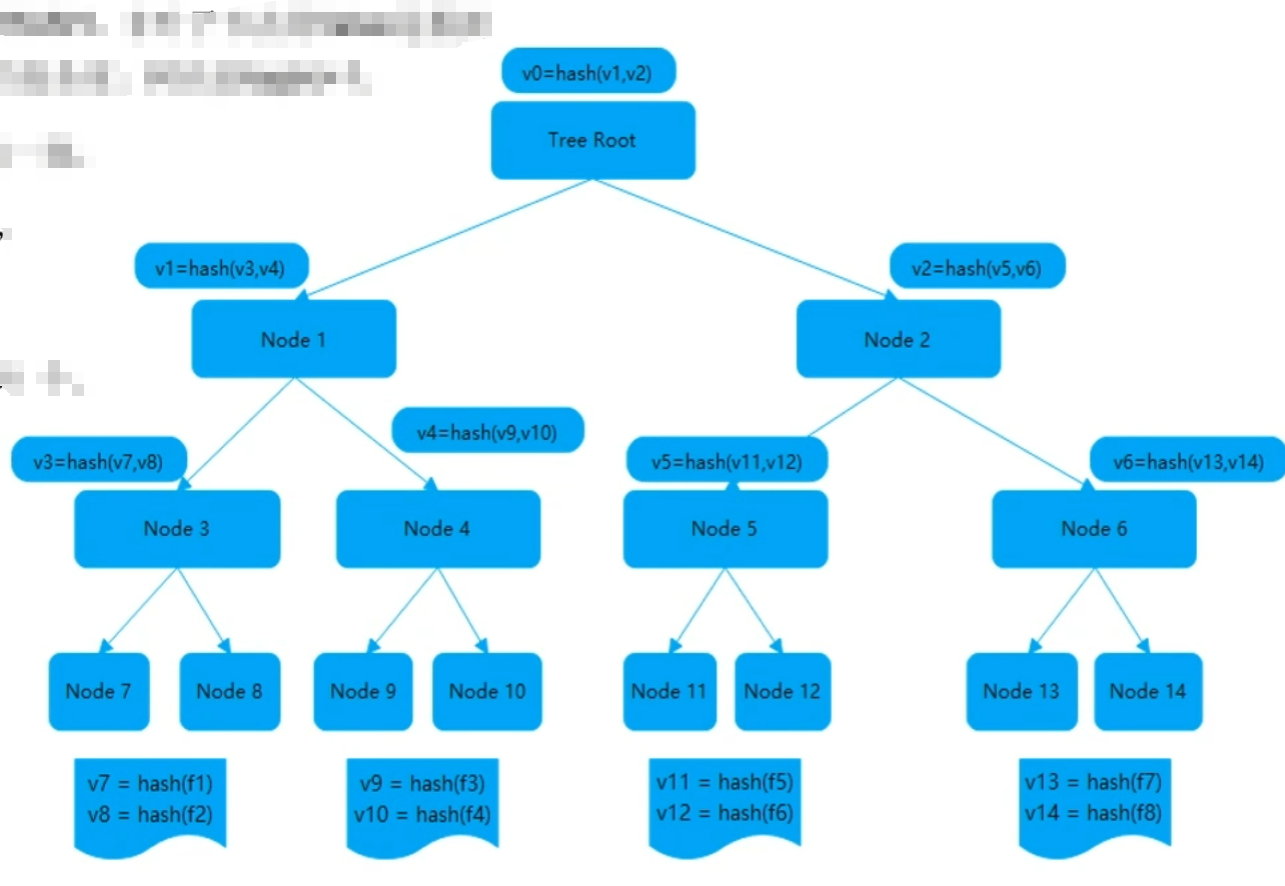
- 默克尔树节点比较
- 默克尔树节点构建
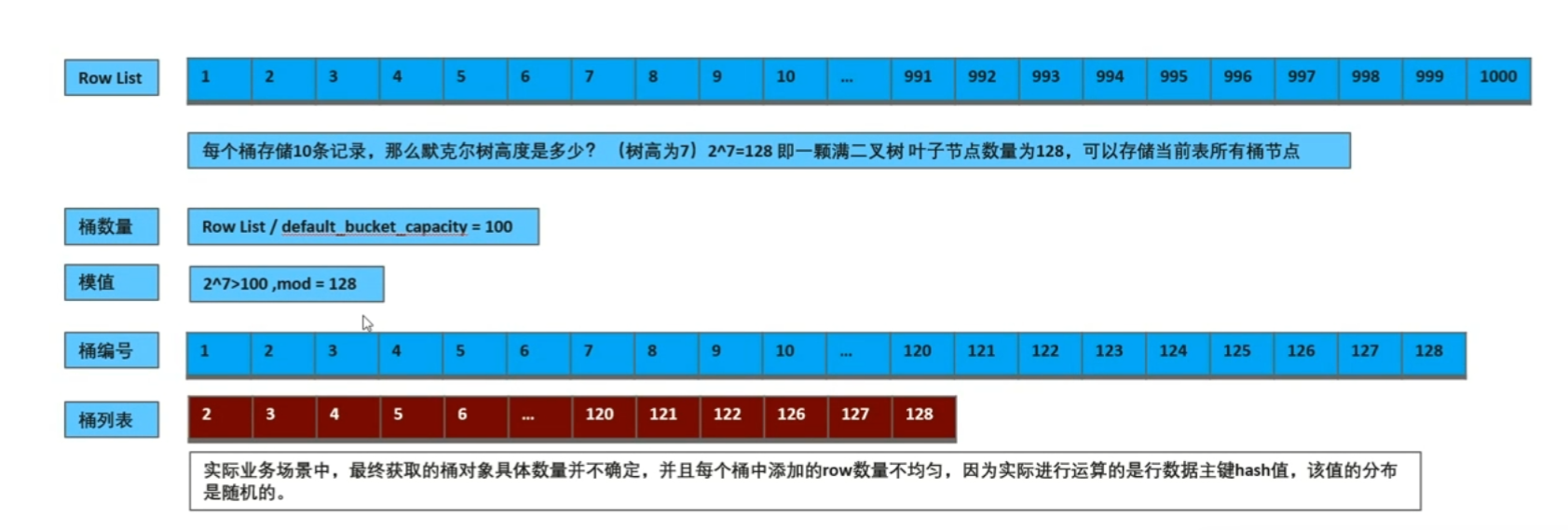
由于表记录数量不确定性(表可能100条记录,或者100万条记录)树最高不能超过15层,叶子节点不能超过32768个,那么100万记录如何校验? 这时候有了分桶概念,分桶就是将100万数据按照Hash规则将数据分散到32768个叶子节点中,那么每人节点会有个在诸容器,我们定义为桶。分散数据到各个桶的过程,我们定义为分桶。
分桶是由默克尔树高度限制所决定,默克尔树高度在不超过15层时(当树高为15时,满二叉树叶子节点32768个),性能会比较好当树高度超过15层后会导致树构建以及遍历性能下降。
数据分桶,将拉取的数据根据数据主键Hash值进行模运算,将数据分别添加到不同的桶中。
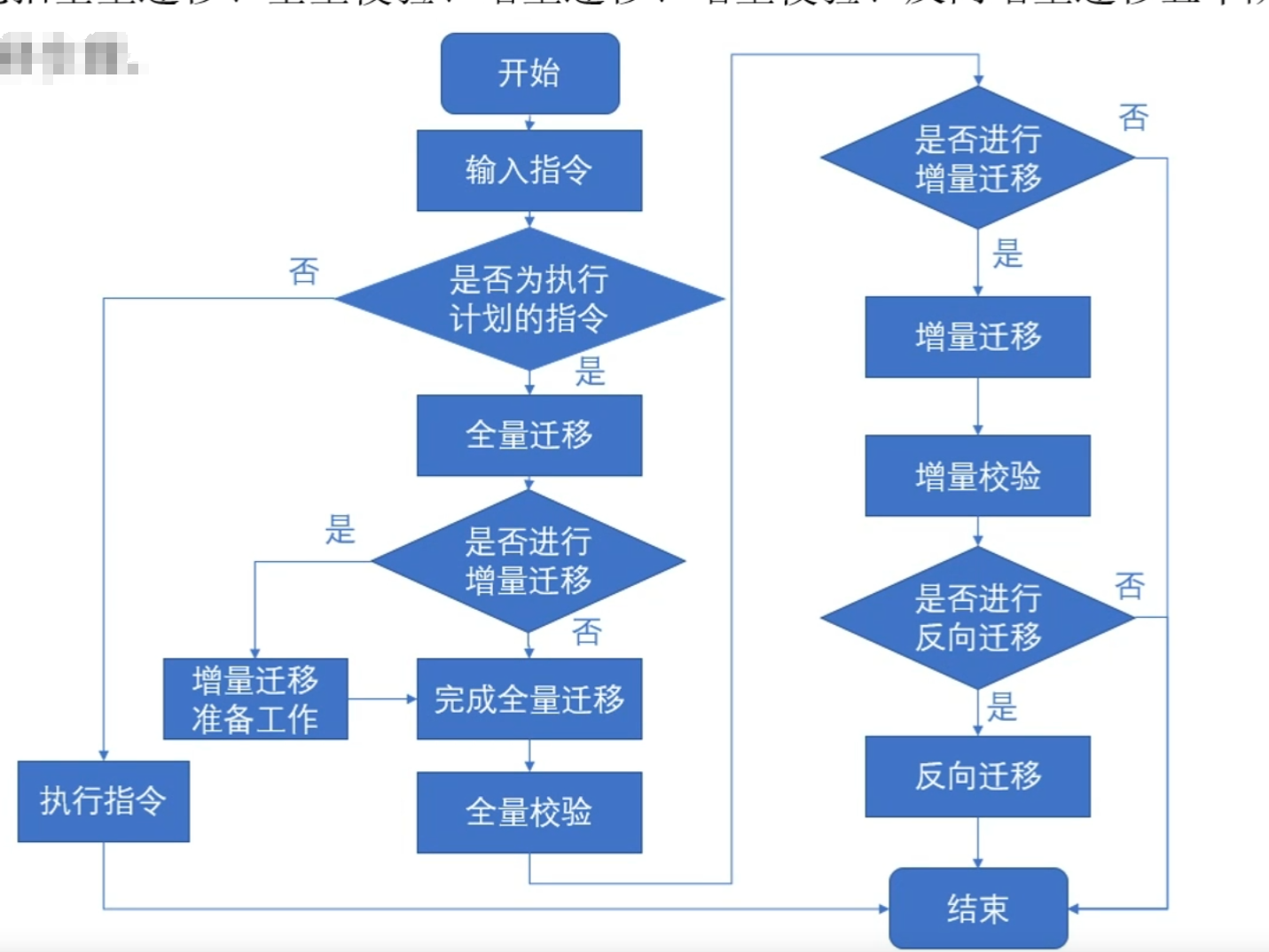
- 一键式迁移工具gsrep_portal介绍
键式迁移工具gs rep portal集成了全量迁移、增量迁移、反向迁移、数据校验的工具。gs rep portal支持键式安装上述工具,并设定迁移任务。gs rep_portal可以根据用户设定的迁移任务的执行计划顺序去调用相应工具完成每个迁移步骤,并能展示每个步骤的状态、进度、异常原因等。

2.5 迁移工具总结

本章节主要介绍了MySQL迁移全流程中五个关键步骤: 全量迁移、全量校验、增量迁移、增量校验、反向迁移的实现原理,接着介绍了一键式迁移portal,并对迁移工具集进行总结。
3. 工具一体化平台DataKit
3.1 DataKit介绍
- Datakit定位为openGauss的数据全生命周期生产力工具,支持数据全生命管理,覆盖openGauss安装部署数据开发、智能运维、数据迁移等阶段Debezium反向增量迁移工具支持将openGauss数据库的增量数据实时同步至MySQL数据库。
- DataKit是openGauss的一个工具集,采用B/S(即Browser/Server,浏览器/服务器)软件架构,提供基础的服务器、数据库实例等软硬件资源管理能力;同时支持通过按需部署功能插件扩展能力,目前社区提供安装部署数据迁移、数据开发、智能运维等功能插件
- Datakit也是一个丁具开发平台,支持用户根据插件接口和规范实现自己的特有功能。功能插件支持动态加载到DataKit上运行,也支持从Datakit上动态卸载。插件支持调用平台和其他插件的开放接口获取相应数据和功能,以实现快速构建特色功能
- 包括:数据迁移插件提供了MySQL迁移所需的所有能
- 迁移任务管理:用户可以通过配置迁移任务将单个或多个源端数据源中的数据迁移至目标数据源日志和错误信息,并进行相应的处理
- 迁移过程监控:用户可以实时查看迁移进度l行,以提高迁移效率
- 并发执行:用户可以创建多个迁移任务并行
- 资源动态分配:系统能够根据最大化利用原,合理分配运行机器,以实现多任务并行迁移 迁模式包括离线模式和在线模式,其中离线模式包括全量迁移、全量校验两个阶段,在线模式包括全量迁移、全量校验增量迁移、增量校验、反向迁移五个阶段
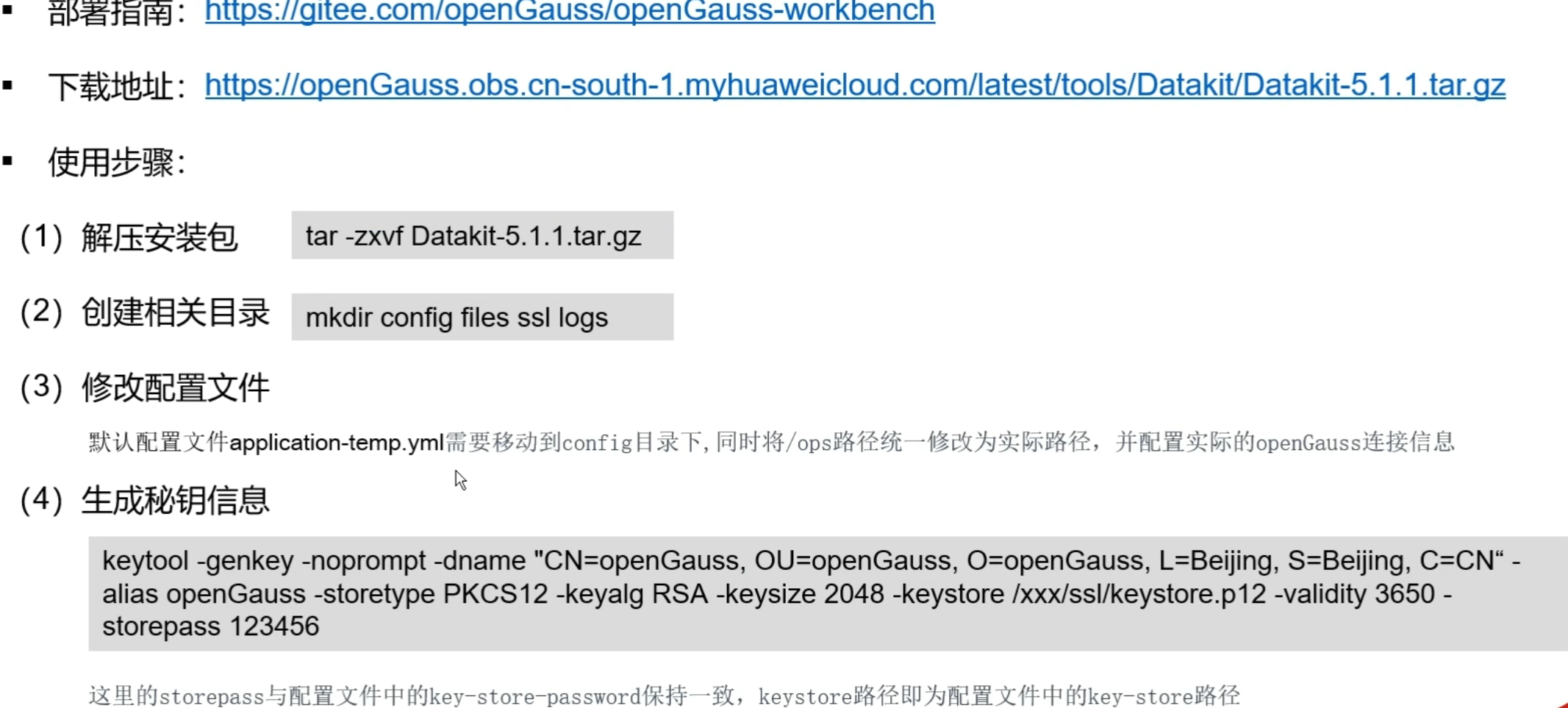
3.2 DataKit部署
3.3 Datakit实现MySQL迁移全流程
MySQL全流程迁移包括全量迁移、全量校验、增量迁移、增量校验、反向增量迁移五个阶段,可通过DataKit平台完成一键式迁移。
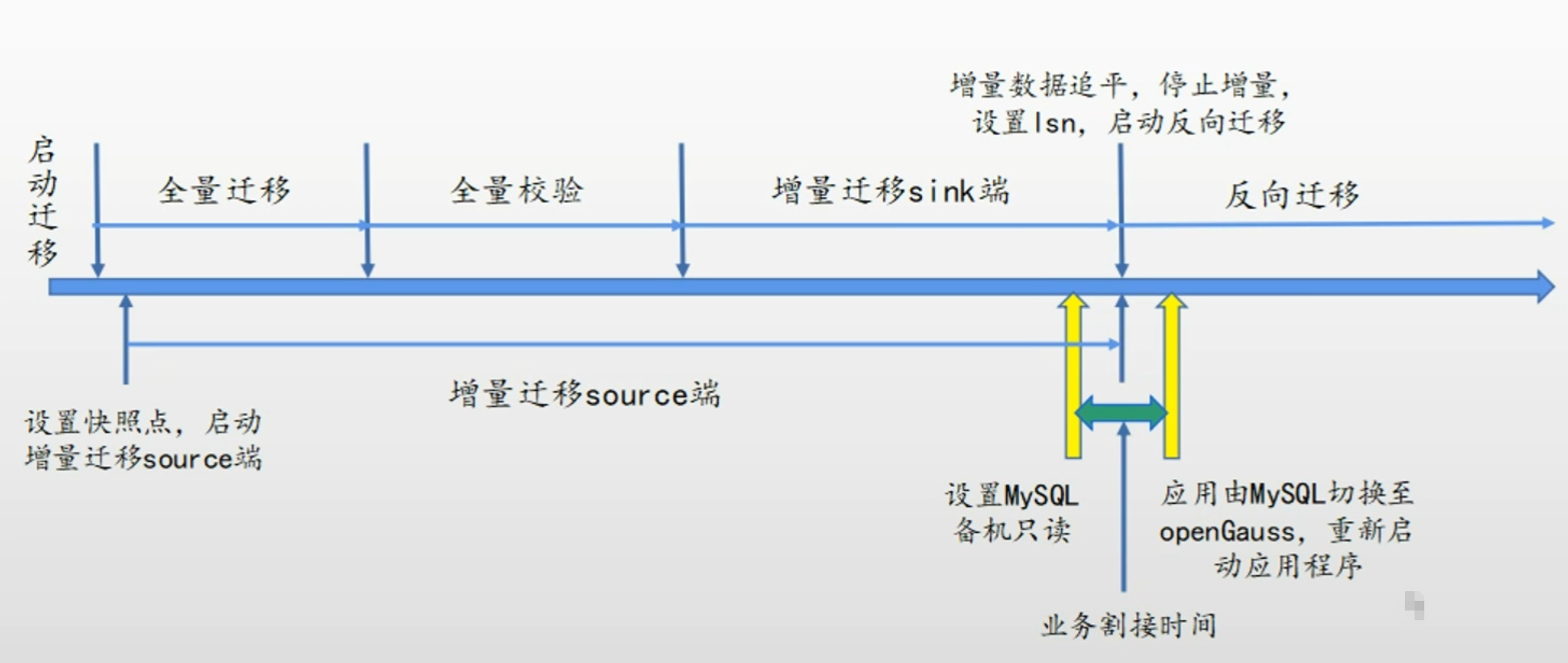
本章节主要介绍了工具一体化平台Datakit的能力,接着讲述了Datakit的部署方式,着重介绍了如何用DataKit实现MySQL迁移全流程。
4. MySQL迁移全流程demo
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。

