浅谈如何优化 Milvus 性能
浅谈如何优化 Milvus 性能

Milvus 是全球最快的向量数据库,在最新发布的 Milvus 2.2 benchmark[1] 中,Milvus 相比之前的版本,取得了 50% 以上的性能提升。值得一提的是,在 Master branch 的最新分支中,Milvus 的性能又更进一步,在 1M 向量串行执行的场景下取得了 3ms 以下的延迟,整体 QPS 甚至超过了 ElasticSearch 的 10 倍。那么,如何使用 Milvus 才能达到理想的性能呢?本文暂且不提社区大神贡献的黑科技优化,先聊聊使用 Milvus 过程中的一些经验,以及如何进行性能调优。
#经验1
合理的预计数据量,表数目大小,QPS 参数等指标
在部署 Milvus 之前,首先需要决定机器的资源、规格、以及一些依赖的资源,以下是你需要考虑的因素:
- 有多少张表?
- 每张表的数据量有多少?
- 每张表的 QPS 需求有多少?
- 是否需要存标量字段,如果有字符串,字符串的平均长度是多少?
- 是否有删除和流式插入,每天大概有多少比例的数据需要被更新?
基于以上因素,可以遵循以下经验结论:
- 节点资源占用可以通过 sizing tool[2] 进行计算,通常情况下 8G 内存可以支持超过 5m 的 128dim 向量数据和 1m 的 768dim 数据。
- 默认情况下,Milvus 会创建 256 个消息队列 topic。如果表数目比较少,可以调整 rootCoord.dmlChannelNum 减少 topic 数目降低消息队列负载。
- 默认情况下,每个 collection 会使用 2 个消息队列 topic(shard),如果写入非常大或者数据量极大,需要调整 collection 的 shard 数目。建议每个 shard 写入/删除不超过 10M/s,单个 shard 的数据量不大于 1B 向量,shard 数目过大也会影响写入性能,因此不建议单表超过 8 个 shard。
- 根据 benchmark[3] 结果计算需要的 CPU 资源。对于小数据量场景(小于5m),使用多副本可以扩展查询性能,但建议副本数目不要超过 10 个。对于中大数据量场景,通常扩容 querynode 就可以自动负载均衡,不需要使用多副本提升 QPS.
- 所有的标量字段目前也会加载进内存中,也会消耗内存,请在容量规划时预留原始数据类型两倍以上的内存。
- Milvus 在存储数据的过程中,存在较多冗余数据(https://github.com/milvus-io/milvus/issues/20453)。考虑到 Minio 的 2,4 纠删码存在两副本冗余,我们建议 Minio 至少包含 6 倍以上的数据的磁盘存储。同时 Pulsar/Kafka 需要包含近五天写入量三倍的存储。合理调整数据的保留时间和 GC 时间可以很大程度上减少磁盘的使用,默认情况下数据会被保留 5 天。个人建议适当缩短数据过期时间,但尽可能保留 1 天以上避免数据丢失或误删除。
- Etcd 作为 Milvus 的元信息存储和服务发现节点,请尽可能使用 ssd 磁盘并独立部署。通常 Etcd 的内存使用不会超过 4GB,通过调整参数可以较快地清理 etcd 中的历史版本减少内存使用。
- Pulsar/Kafka 作为 Milvus 的日志存储,其依赖的 zookeeper 集群对性能要求也比较高,建议使用 SSD 并独立部署。
#经验2
选择合适的索引类型和参数
索引的选择对于向量召回的性能至关重要,Milvus 支持了 Annoy,Faiss,HNSW,DiskANN 等多种不同的索引,用户可以根据对延迟、内存使用和召回率的需求进行选择。
索引的选择步骤一般如下:
1) 是否需要精确结果?
只有 Faiss 的 Flat 索引支持精确结果,但需要注意 Flat 索引检索速度很慢,查询性能通常比其他 Milvus 支持的索引类型低两个数量级以上,因此只适合千万级数据量的小查询(Flat on GPU 已经在路上了,敬请期待)
2)数据量是否能加载进内存?
对于大数据量,内存不足的场景,Milvus 提供两种解决方案:
- DiskANN
- DiskANN 依赖高性能的磁盘索引,借助 NVMe 磁盘缓存全量数据,在内存中只存储了量化后的数据。
- DiskANN 适用于对于查询 Recall 要求较高,QPS 不高的场景。
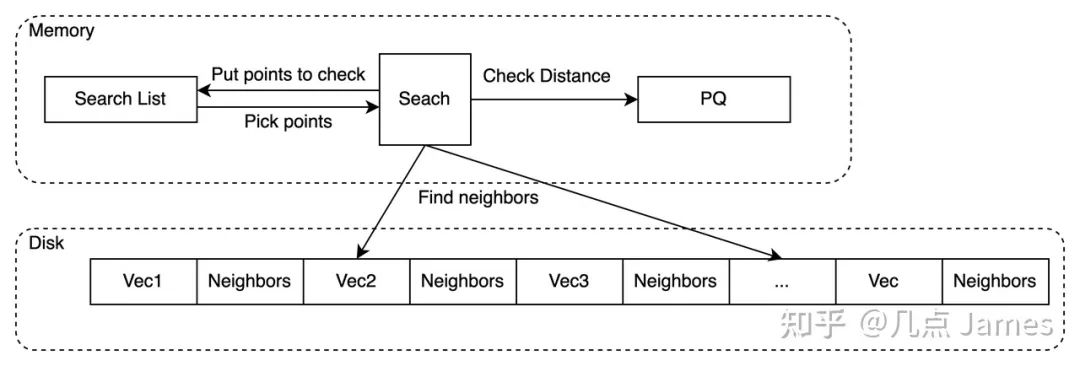
DiskANN示意图
DiskANN 的关键参数:
search_list: search_list 越大,recall 越高而性能越差。search_list 的大小不应该小于 K。而对于较小的 K,推荐把 search_list 和 K 的比值设置得相对大一些, 这个比值随着 K 增大可以逐渐靠近 1。
- IVF_PQ
- 对于精确度要求不高的场景或者性能要求极高的场景。
- IVF PQ 的核心是两个算法,IVF + PQ 量化,其中量化可以大幅减少向量的占用内存量。
IVF 参数
nlist:一般建议 nlist = 4*sqrt(N),对于 Milvus 而言,一个 Segment 默认是 512M 数据,对于 128dim 向量而言,一个 segment 包含 100w 数据,因此最佳 nlist 在 1000 左右。
nprobe:nprobe 可以 Search 时调整搜索的数据量,nprobe 越大,recall 越高,但性能越差。具体的 nprobe 需要根据查询的精度要求决定,从 nprobe = 16 开始会是一个不错的尝试。
PQ 参数
M: 向量做 PQ 的分段数目,一般建议设置为向量维数的 1/4,M 取值越小内存占用越小,查询速度越快,精度也变得更加低。
Nbits: 每段量化器占用的 bit 数目,默认为 8,不建议调整。
3) 构建索引和内存资源是否充足
性能优先,选择 HNSW 索引
- HNSW 索引是目前 Milvus 支持的性能最快的索引,我们的测试报告也是基于 HNSW 作为测试依据。
- HNSW 内存的开销较高,通常需要原始向量的 1.5 - 2 倍以上内存。
HNSW 参数
M:表示在建表期间每个向量的边数目,M 越大,内存消耗越高,在高维度的数据集下查询性能会越好。通常建议设置在 8-32 之间。
ef_construction:控制索引时间和索引准确度,ef_construction 越大构建索引越长,但查询精度越高。要注意 ef_construction 提高并不能无限增加索引的质量,常见的 ef_constructio n 参数为 128。
ef: 控制搜索精确度和搜索性能,注意 ef 必须大于 K。
资源优先,选择 IVF_FLAT 或者 IVF_SQ8 索引
IVF 索引在 Milvus 分片之后也能拿到比较不错的召回率,其内存占用和建索引速度相比 HNSW 都要低很多
IVF_SQ8 相比 IVF,将向量数据从 float32 转换为了 int8,可以减少 4 倍的内存用量,但对召回率有较大影响,如果要求 95% 以上的召回精度不建议使用。
IVF 类索引的参数跟 IVFPQ 类似,这里就不做过多的介绍了。
检索时,Milvus 的查询一致性也会对查询造成较大影响。通常情况,对于一致性要求较高的场景,建议使用最终一致性或者有界一致,默认情况下 Milvus 选择有界一致性,窗口为 3s。
#经验3
合理选择流式插入和批量导入
Mivus 原生支持流批一体,同时支持流式写入和批式写入(BulkInsert)两种模式。绝大多数用户在最初接触 Milvus 的时候,都会选择流式写入,这种方式实时性较好,同时也避免了批式写入小文件带来的 Compaction 压力。
如果有大量离线写入的场景,建议使用 BulkInsert,原因是 BulkInsert 不会对查询性能造成太大的影响,并且也大大减少了流式写入对消息队列产生的压力。如何合理选择流式还是批式写入呢:
- 单次写入超过 100MB 以上,建议选择批式写入
- 希望尽可能减少写入对线上查询的影响,建议选择批式写入
- 希望写入实时可见,建议选择流式写入
- 单次写入小于 10MB 以下,建议选择流式写入
在选择好写入方式的基础上,还有几个经验需要关注:
- 尽可能批量写入,整体吞吐会更高,建议每次写入的大小控制在 10M
- 单个 Shard 的流式写入量不建议超过 10M/s
- Datanode 多于 Shard 的情况下,部分 DataNode 可能无法获得负载
- 导入目前支持的文件大小上限是 1GB,接下来会支持更大的导入文件大小上限
- 不建议频繁导入小文件,会给 compaction 带来比较大的压力
#经验4
谨慎使用标量过滤,删除特性等特性
作为数据库,Milvus 支持了删除、标量过滤、TimeTravel 等高级特性。如果不了解底层原理,使用这些高级功能可能会对稳定性和性能造成比较严重的影响,以下是一些使用注意事项:
- Milvus 使用的是前过滤,即先做标量过滤生成 Bitset,在向量检索的过程中基于 Bitset 去除掉不满足条件的 entity。对于 HNSW 这一类的图索引而言,标量过滤并不会加速查询,反而可能导致性能变差。特别是对于过滤性很强的条件(比如 PK=1 这种全局唯一的条件),标量过滤甚至会导致单次查询的时间长于爆搜。针对这种情况,用户也可以选择通过后过滤的方式绕过,先基于 Milvus 查出 TopK 的数据,再基于其他数据库进行过滤。
- 对于过滤条件相对比较确定的场景,使用 Partition 把数据进行物理分区,在查询的时候指定 Partition 性能更好。
- Milvus 的删除是标记删除,在 compaction 时会清理,因此删除的数据依然会占据内存。大量删除也会造成查询性能下降,同时大量 compaction 可能造成建索引压力变大等一系列影响。在需要大量频繁删除的场景,可能需要进行一些 compaction 参数的调整,保证删除的数据能够被及时清理。
- Milvus 支持了数据自动过期功能(TTL),可以定时清理过期数据。
- 如果需要全量更新一个 Collection 的数据,推荐使用新建表 + 导入数据 + Alias 切换的方案。
- 制定 Output field 时,如果要获取标量字段,会从对象存储上获取,吞吐和延迟都会受到较大影响。
当然,Milvus 后续的版本会对以上能力做针对性的优化,尤其是删除和标量过滤的场景。Milvus 新一代的标量执行引擎也已经在开发中,欢迎大家参与给出更多有建设性的意见。
#经验5
部署监控并观察集群情况
可观测性是用户在生产环境落地非常重要的一部分,Milvus 2.2 重新梳理监控指标并且校正了指标的正确性,我们强烈建议你的生产集群部署监控[4]并且在上线之前进行性能测试。
Milvus 监控 Panel
除了每个节点的CPU使用率,内存使用量信息,以下是一些建议你关注的监控指标:
Proxy
查询延迟:milvus_proxy_sq_latency/milvus_proxy_collection_sq_latency
写入/删除延迟:milvus_proxy_mutation_latency
写入流量:milvus_proxy_receive_bytes_count
查询返回流量:milvus_proxy_send_bytes_count
QueryNode
加载的数据量:milvus_querynode_entity_num
查询请求排队时间:milvus_querynode_sq_queue_latency
单个 Segment 的查询时间:milvus_querynode_sq_segment_latency
IndexNode
构建索引的时间:milvus_indexnode_build_index_latency
DataNode
Flush 花费的时间:milvus_datanode_save_latency
Compaction 花费的时间:milvus_datanode_compaction_latency
#经验6
一些常见的参数调整
想要使得 Milvus 跑得更快更稳,针对自己的使用场景、硬件资源情况进行一些定制化的调整自然是不可避免的,你可以从了解以下参数开始:
Segment 大小:Segment 大小越大,查询性能越好,构建索引越慢,负载越不容易均衡。Milvus 默认选择 512M Segment 大小主要是考虑到了内存比较少的机型。对于内存在 8G-16G 的用户,建议 Segment 大小调整到 1024M,16G 以上的机型可以调整到 2G。
Segment seal portion: 当 Growing Segment 达到 Segment 大小 * seal portion 后,流式数据就会被转换为批数据。通常情况下建议 Growing segment 的大小控制在 100-200M 左右,调小这个值有助于降低流式写入场景下的查询延迟。
DataNode Segment SyncPeriod: Milvus 会定时将数据 Sync 到对象存储,Sync 越频繁故障恢复速度越快,但过于频繁的 sync 会导致 Milvus 生产大量小文件,给对象存储造成较大压力。
Quota 相关的参数:目前支持限制 Milvus 的写入、删除流量、查询的 QPS,以及内存的保护,当触发性能问题时,也要观察是否是因为触发了相应的限流。
#结尾
强烈推荐更新社区的 LTS 版本,包含了大量性能优化和稳定性 Fix,凝结了社区几百名贡献者的心血,大部分用户踩到的坑其实新版本都已经修复解决。如果你对云计算、分布式、数据库、向量检索、高性能计算这些领域感兴趣,欢迎加入 Milvus 社区和社区背后的公司 Zilliz,以下是社区正在推进的一些项目:
1)接入 Google 的 ScaNN 索引,优化 Milvus 向量执行引擎 Knowhere 的性能
2)10 亿向量的查询/加载性能优化
3)支持 RangeSearch
4)改进 Milvus 的标量执行引擎,支持更加复杂的标量数据类型,降低标量的内存开销。
5)改进 Partition 算法,支持动态增加/减少 partition 个数
6)支持 Faiss,HNSW,Milvus 1.0 迁移 Milvus 2.0
7) Cpp,Rust,Restful API 的开发和完善
....
如果你在使用 Milvus 或者调优的过程中遇到任何困难,也欢迎来社区开 issue 或者加入我们的 Milvus 微信交流群。Enjoy it!
点击「阅读原文」 即可体验如何提升 Milvus 性能!
参考资料
[1]Milvus 2.2 benchmark: https://milvus.io/docs/benchmark.md
[2]sizing tool: https://milvus.io/tools/sizing/
[3]benchmark: https://milvus.io/docs/benchmark.md
[4]部署监控: https://milvus.io/docs/monitor.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号