GuassDB(for openGauss)集中式集群搭建及使用
详细流程查看 ( GaussDBInstaller_V1.0.3.2脚本安装使用说明书 ) 即可, 本文重点阐述实际安装过程中的要点。
1.系统及配置
安装GuassDB(for OpenGauss)时不管是分布式还是主备式, 都至少需要三台机器,每台机器要求如下。
1.1 官方推荐配置
硬件要求
| 项目 | 配置描述 |
|---|---|
| 内存 |
功能调试建议32GB以上。性能测试和商业部署时,CN和DN单实例部署,建议128GB以上。复杂的查询对内存的需求量比较高,在高并发场景下, 可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的并发。 |
| CPU |
功能调试最小1×8核2.0GHz。性能测试和商业部署时,CN和DN单实例部署,建议1×16核2.0GHz。CPU超线程和非超线程两种模式都支持。但是,集群各节点的设置需保持一致。 |
| 硬盘 |
用于安装集群的硬盘需最少满足如下要求: ● 至少1GB用于安装集群的应用程序包。 ● 每个主机需大约300MB用于元数据存储。 ● 预留70%以上的磁盘剩余空间用于数据存储。 ● 系统盘由两块盘组成RAID1 ● 数据盘组RAID10(总共24块硬盘,建议分2组,一组12块组raid10) ● LVM划分参考数据库拓扑中分区,一般部署多少个DN进程,则规划几个逻辑卷 |
| 网络要求 |
300兆以上以太网。 环境要求有3个可用IP。 建议网卡设置为双网卡冗余bond。有关网卡冗余bond的配置方法在本手册中不做介绍。请参考硬件厂商的手册或互联网上的方法进行配置。 集群网络如果配置bond,请保证bond模式一致,不一致的bond配置可能导致集群工作异常。 注:不推荐使用只有1个可用IP的环境,可能存在以下风险: ● 查询业务可用带宽被其他流量抢占(如主备数据同步),导致查询性能下降。 ● 主备数据同步可用带宽被其他流量抢占(如查询业务),导致主备同步性能下降。 ● 容灾集群同步可用带宽被其他流量抢占(如查询业务),导致灾备集群的同步性能下降,RPO和RTO变高。 ● 备份可用带宽被其他流量抢占(如查询业务),导致备份性能下降。 |
软件要求
| 软件类型 | 配置描述 |
|---|---|
| 操作系统 |
x86服务器支持Kylin V10 SP1(intel、hygon)。 ARM服务器支持Kylin V10 SP1(kunpeng、phytium)。 说明:只支持英文操作系统。 |
| 文件系统 |
● 剩余inode个数 > 15亿(推荐)。 |
| 工具 |
● Huawei JDK 1.8.0。 ● cgroup V1。 说明:因为数据库版本仅支持cgroup V1,暂不支持cgroup V2,KylinV10 SP1(intel)系统默认支持cgroup V2,可在/sys/fs/cgroup/blkio/目录下 查看是否存在blkio.weight文件,存在即表示操作系统已适配cgroup V1, 若不存在,数据库安装前系统需要适配cgroupV1。 |
| python版本 |
Kylin(X86):仅支持Python 3.7.9。 Kylin(arm):仅支持Python 3.7.4 |
1.2 本文配置
本文使用VMWare搭建三台虚拟机,供学习交流,可根据实际的学习、生产要求调整配置。本文配置及环境要求参考如下:
操作系统
本文使用 Kylin-Server-10-SP1-Release-Build20-20210518-x86_64.iso 光盘镜像文件 (银河麒麟高级服务器操作系统V10),搭建操作系统。可从银河麒麟官网获取操作系统镜像,官网地址: 银河麒麟操作系统 麒麟操作系统 国产操作系统 中标麒麟 开放麒麟 openKylin 麒麟软件官方网站
安装时务必选择英文系统
配置
- 内存
○ 经本地测试,5G内存时不可以, 9G内存时可用(*未测试中间值*).
- 硬盘大小(系统剩余空间)
○ <20G时, 禁止安装
○ 20~50G时, 需要手动确认来继续进行
○ 50G以上时, 无需确认, 自动执行
软件要求
- Jdk1.8
- python3.7.9 (X86)
- expect
- openssl
- ifconfig
- VMWare(可选)
- xshell(可选)
2.软件安装
2.1 虚拟机环境搭建
本文采用虚拟机方式搭建操作系统。其主要步骤如下。
1.从VMWare 官网下载软件: VMware 中国 - 交付面向企业的数字化基础 | CN ,经测试,如果VMWare版本过低,可能会导致无法安装麒麟虚拟机,本文使用的虚拟机版本为:VMware Workstation 16 Player。
2.在VMWARE中新建虚拟机。虚拟机搭建过程不赘述,这里仅说明需要注意的地方。
- 选择自定义方式
- 光盘驱动选择 Kylin-Server-10-SP1-Release-Build20-20210518-x86_64.iso 光盘镜像文件
- 客户机操作系统选择Linux,版本为CentOS8 64位
- 处理器数量至少为2个,每个处理器内核数量至少4个(经测试,集中式单处理器核数最少为3个)
- 内存至少为9G
- 网络类型为NAT
- 磁盘大小至少为50G
- 其余内容保持默认即可
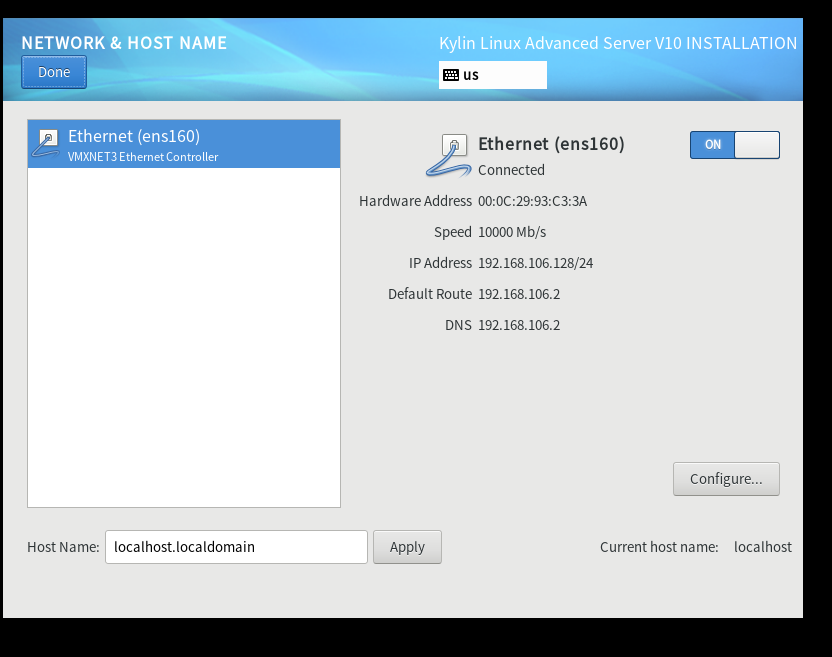
- 网络必须选择打开(参考下图)
- 无需创建操作系统的用户(后续步骤将使用脚本自动创建)。
将虚拟机关机。从搭建好的虚拟机复制,搭建三台虚拟机。
将虚拟机关机。从搭建好的虚拟机复制,搭建三台虚拟机。
2.2 脚本环境准备
2.2.1.依赖安装
使用xshell或者其它方式连接三台虚拟机。登录root账户。
对三台虚拟机节点都要检查、安装如下软件。
执行如下命令检查是否安装expect软件。若成功回显出版本则说明安装成功。
如果没有安装,执行如下命令即可安装。
脚本生成证书依赖于openssl软件,要求环境已成功安装openssl。
可执行以下命令,检查openssl是否安装成功。若成功回显出版本则说明安装成功。
可执行以下命令,检查ifconfig是否安装成功。
若成功回显出版本则说明安装成功。
2.2.2 资源文件准备
解压GaussDBInstaller.tar.gz
将安装包统一放到GaussDBInstaller/pkgDir目录下,安装包要求必须包含以下3个安装包:(以V500R002C10SPC510B001集中式为例):
– GaussDB_Kernel_V500R002C10SPC510B001_X86_Centralized_AGENT_PAC KAGE.tar.gz
– GaussDB_Kernel_V500R002C10SPC510B001_X86_Centralized_SERVER_PAC KAGE.tar.gz
– DBS-GaussDBforOpenGauss-Adaptor_1.1.0.1660530672.tar.gz
配置/GaussDBInstaller目录下的install_cluster.conf文件,主要是对ip进行配置。注意这里集中式环境的默认端口是30170,分布式集群的默认端口则是8000,经测试,分布式集群不可以使用端口30170。
拷贝json文件到脚本解压后的目录GaussDBInstaller下,只需要根据自己部署的实际情况选择其中一个json文件即可。本文选择3节点的集中式quorum协议的3_nodes_centralized.json

json文件要重命名为install_cluster.json。json文件的ip也需要改为节点ip。注意本文每个节点仅有一个ip,因此每个组件的ip,dataip和vitualip设置为同一个IP地址即可。
在任意一台节点根路径下新建/data,将GaussDBInstaller复制到节点/data下。最终的目录结构会如下图所示。
2.3 执行脚本
2.3.1 执行前置
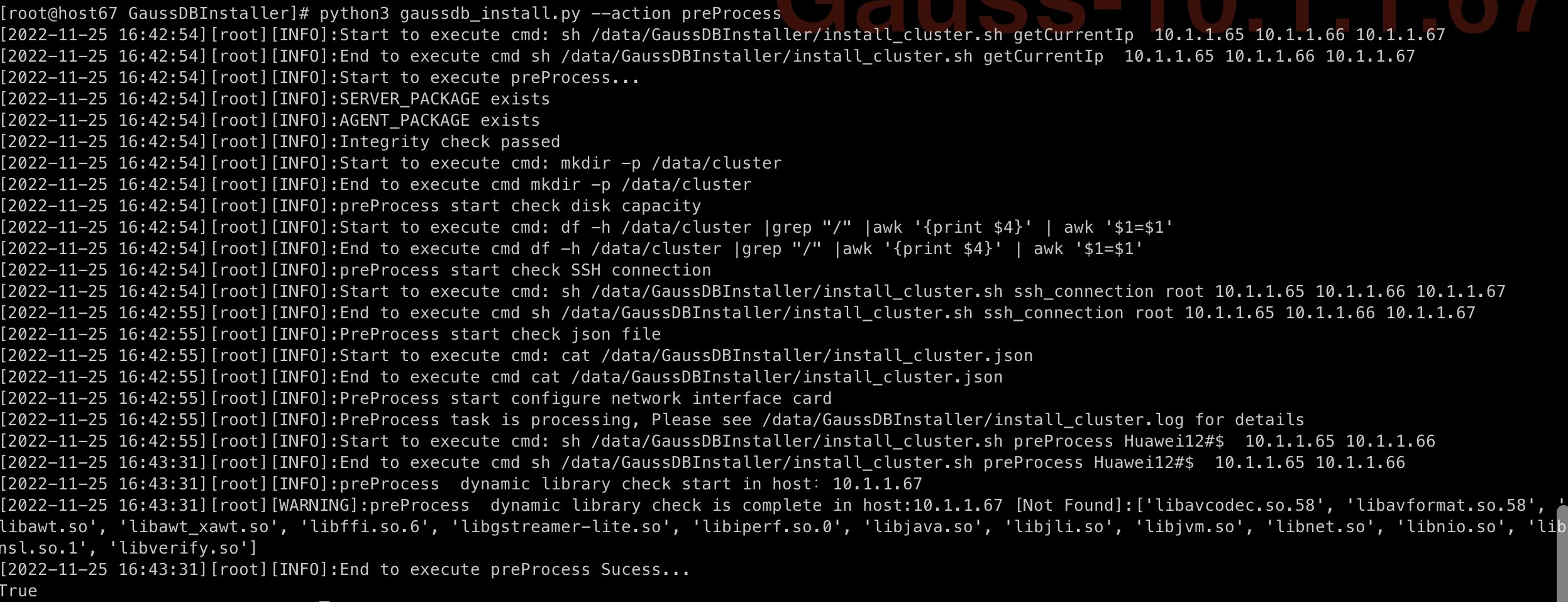
执行gaussdb_install.py脚本,该脚本命令会利用expect远程ssh连接集群中其他节点,将GaussDBInstaller发送到另外两台节点。
python3 gaussdb_install.py --action preProcess
如果脚本执行成功,会显示提示信息,如下图所示。
检查另外两台节点是否具有GaussDBInstaller,且结构与当前节点组织一致。
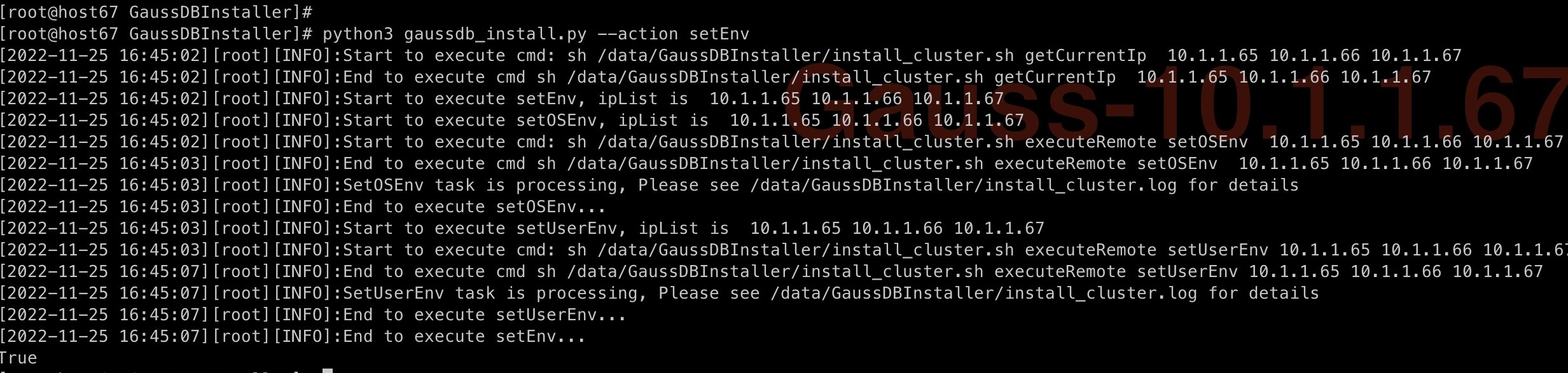
2.3.2 配置环境
执行如下脚本命令,配置环境变量。
执行结果如下则说明成功。
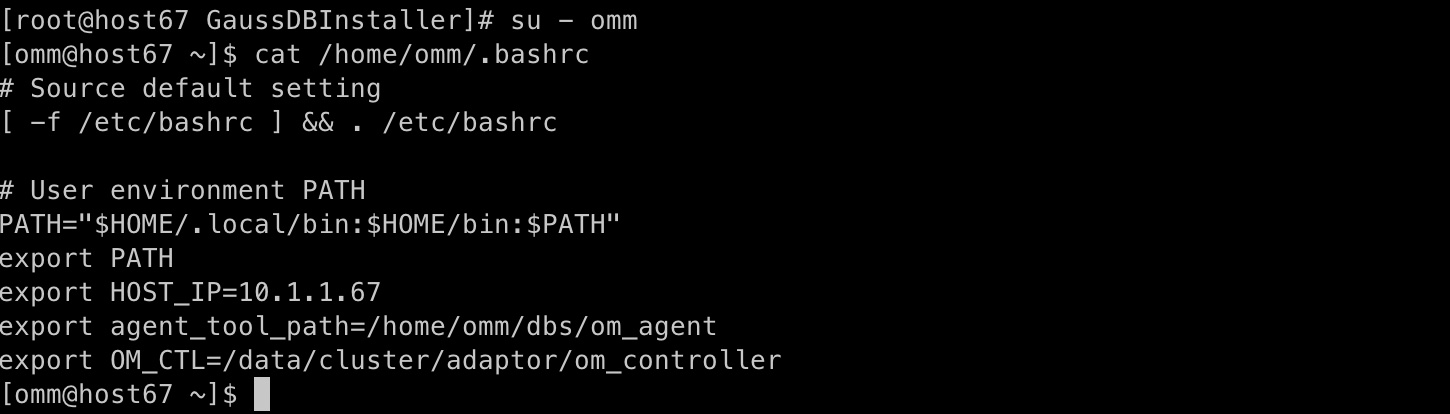
执行后检查:远程登录到待安装实例所有节点,执行下面命令
cat /home/omm/.bashrc
查看cat命令的回显是否包含以下信息:
export HOST_IP= 当前主机ip
export agent_tool_path=
export OM_CTL=
执行结果如下。
2.3.3 生成证书
执行如下脚本命令生成证书。
python3 gaussdb_install.py --action genCertificate
执行结果如下。
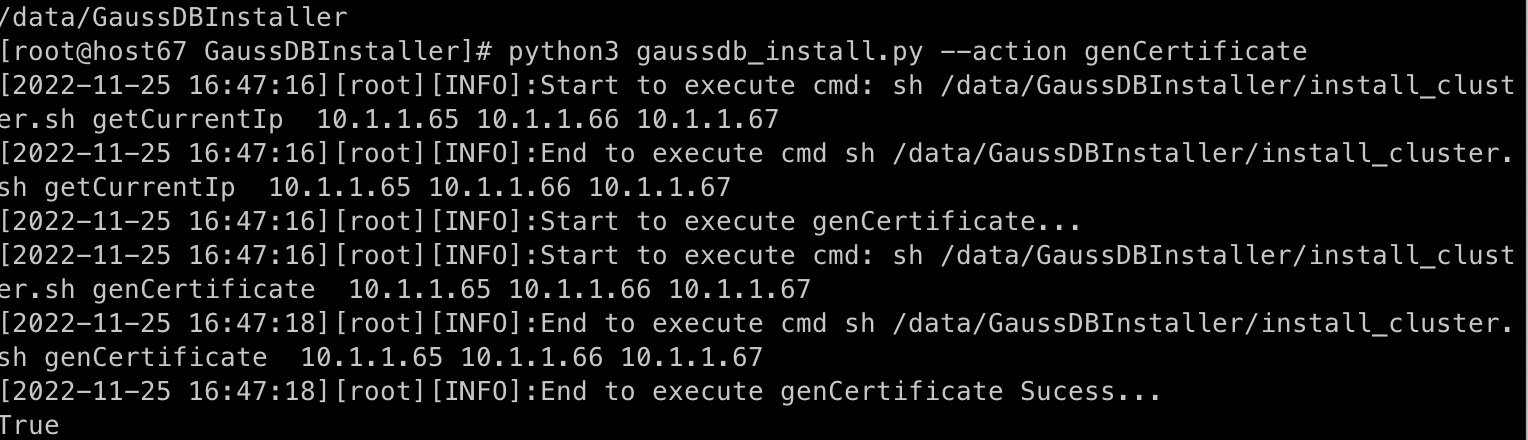
执行后检查:查看/home/omm/sslcrt下是否有ca.pem、server.key、server.pem文件存在,存在即执行成功。

2.3.4 安装OmAgent
执行如下脚本命令安装OmAgent。

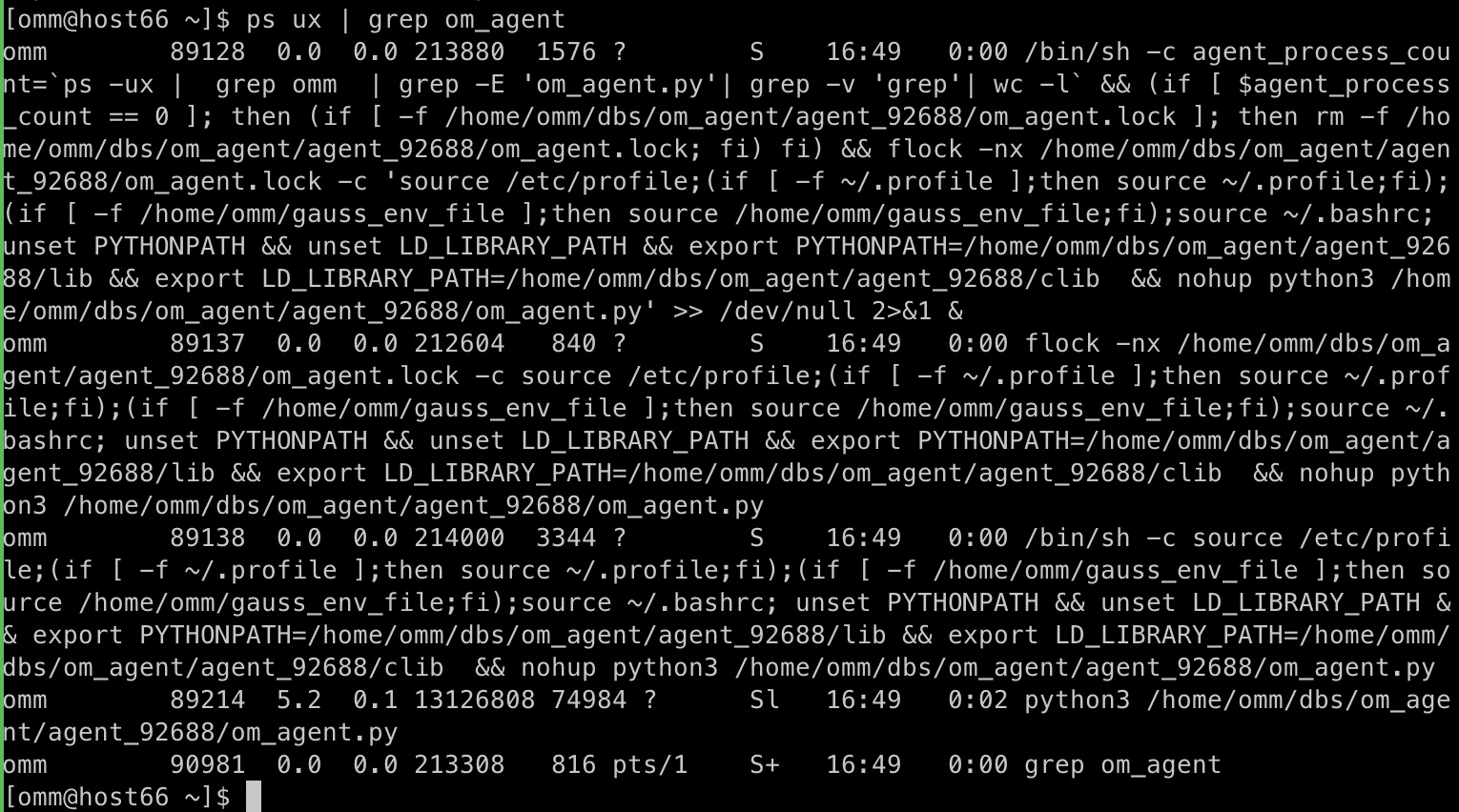
远程登录到待安装实例所有节点,执行下面命令检查OmAgent是否安装成功。
ps ux | grep om_agent
安装成功可以看到如下信息。
2.3.5 预安装
执行如下脚本命令预安装。
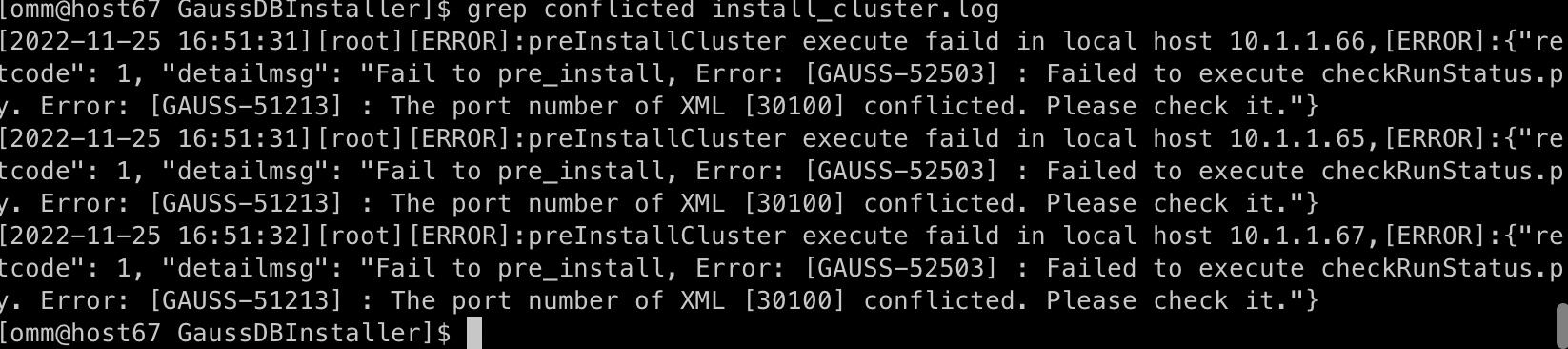
执行后检查
vim install_cluster.log
查找如下图日志【preInstallCluster execute successfully in local host 节点ip】,所有节点都找到对应日志,即执行成功
2.3.6 安装
执行如下脚本命令安装。
执行结果如下。
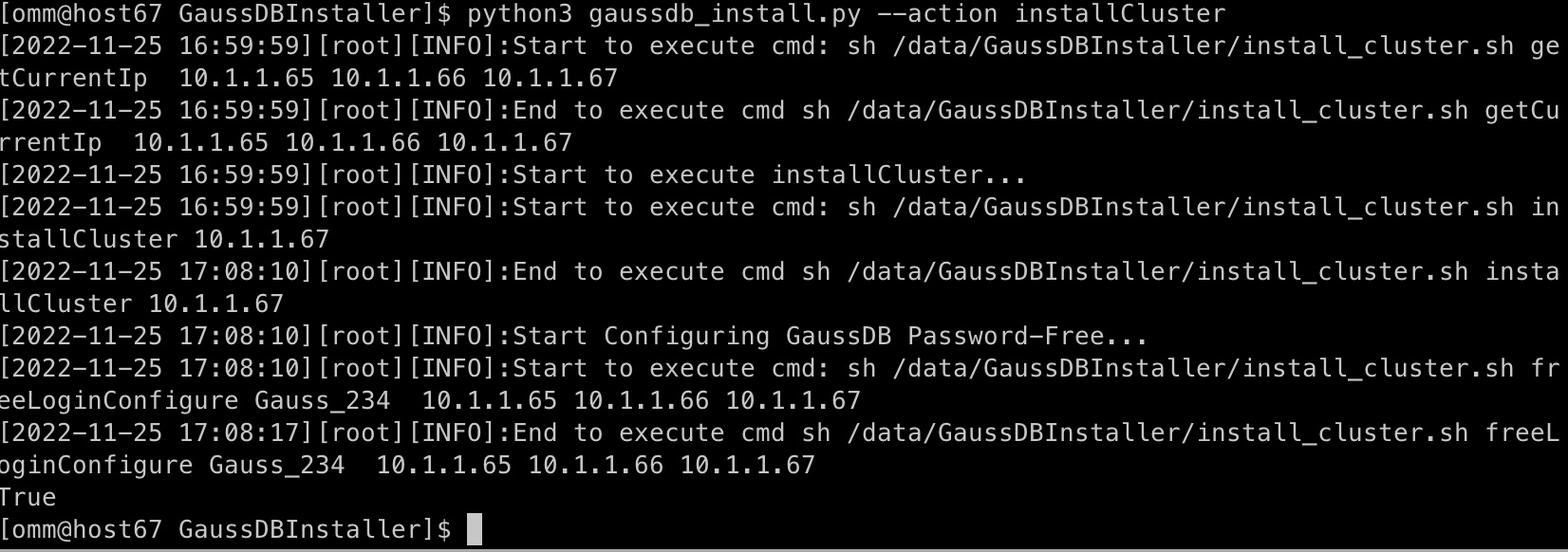
查找install_cluster.log,
如下图日志有cluster state is normal即证明实例安装成功.
2.3.7 查看实例状态
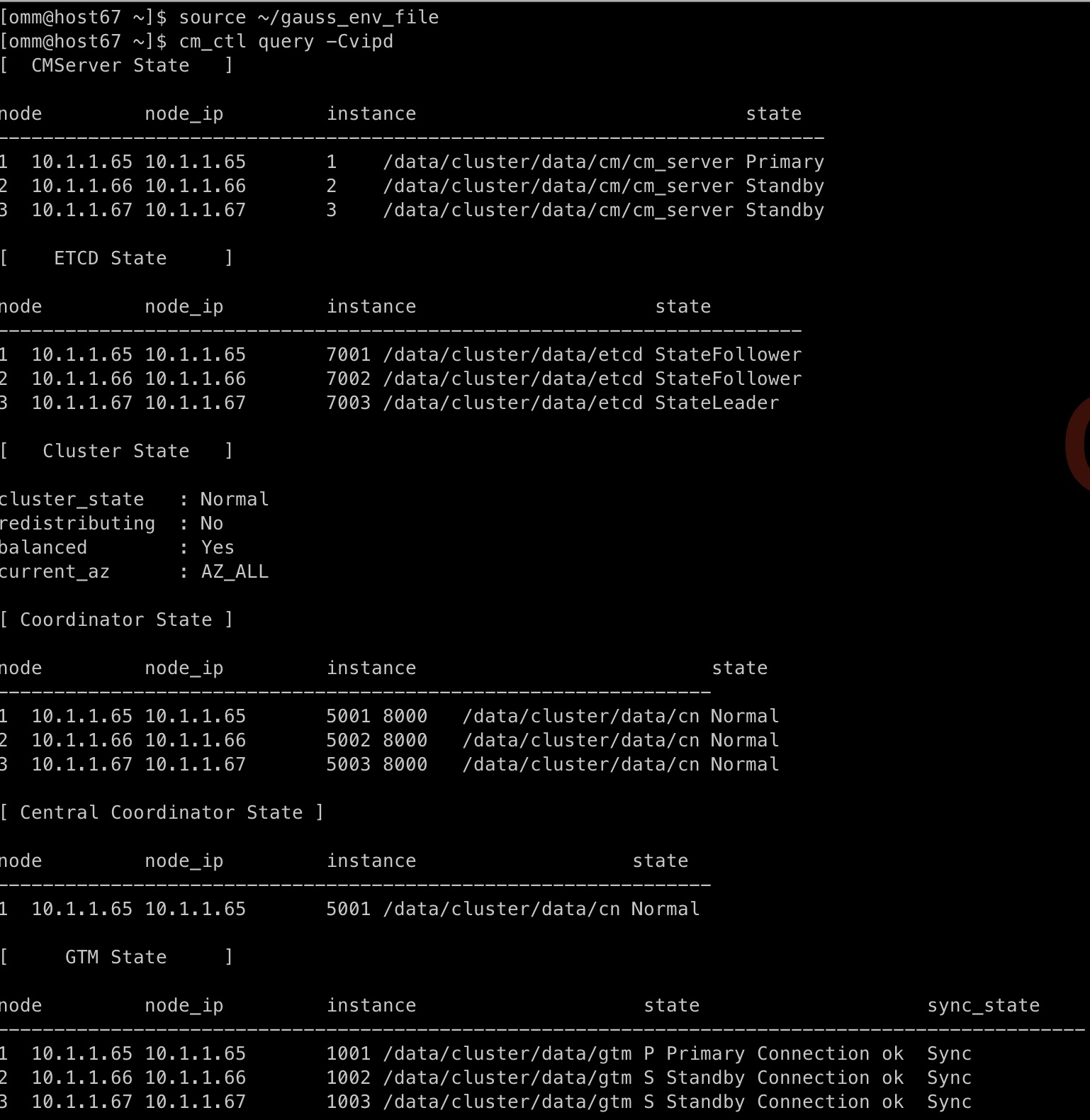
查看集群状态执行命令
cm_ctl query -Cvipd
查看集群状态是否成功,如下图,如果状态是Normal,则实例安装成功。
2.3.8 hostIp获取错误
在虚拟机环境下, 可能会出现hostname为bogon的情况, 会导致hostIp获取错误.
可执行python3脚本确认Ip是否正常
hostname = socket.gethostname()
hostIp = socket.gethostbyname(hostname)
print(hostname, hostIp)
解决办法
修改hostname名称为任意值
经测试, 修改/etc/hostname无法生效
可考虑在/etc/profile中加入 hostname servernameXXX , 并执行source /etc/profile
3.GaussDB的使用
3.1 命令行交互
使用如下命令即可登录数据库。
su - omm
gsql -p 30100 -d postgres
# 登录其他账号需指定用户名
gsql -Uroot -p 30100 -d postgres
3.2 图形化界面使用
3.2.1 Data Studio
Data Studio是一款用于连接数据库的客户端工具,有着丰富的GUI界面,能够管理数据库和数据库对象,编辑、运行、调试SQL脚本,查看执行计划等。Data Studio工具可运行在32位或64位windows操作系统上,解压软件包后免安装即可使用。
其下载方法有两种:
- 通过登录GaussDB(DWS) 管理控制台。通过访问以下地址登录GaussDB(DWS) 管理控制台: https://console.huaweicloud.com/dws
- 下载源代码 自行编译 ,代码及安装说明: https://gitee.com/opengauss/DataStudio 。官网未对编译环境有要求, 但目前仅在windows环境下编译成功, Mac未成功, Linux下未测试。
由于官方安装包无法较为便捷的获取,本文基于 Windows平台,选择第二种方式。
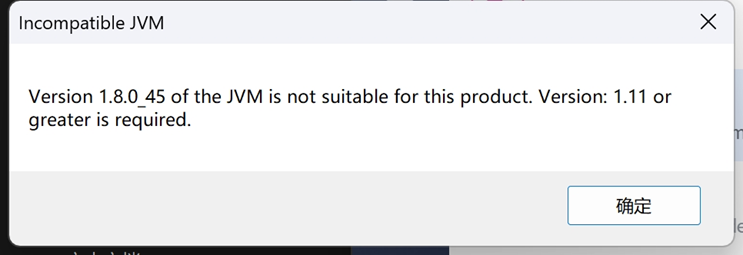
在编译过程中可能遇到问题,启动报 Incompatible JVM,而此时系统环境变量已经是 JDK11了, 但还是报JVM版本不对
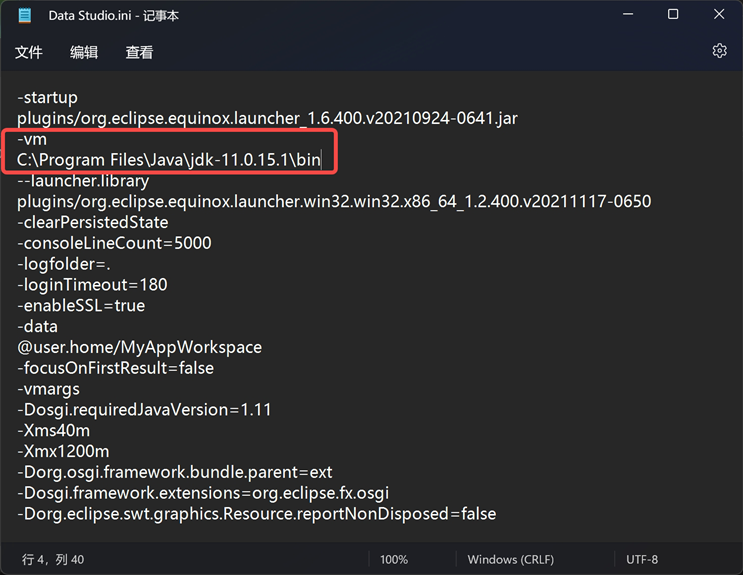
解决方法:在Data Studuo.ini文件中指定JDK11目录, 如
C:\Program Files\Java\jdk-11.0.15.1\bin
通过如下网址可以获得Data Studio的详细教程:Data Studio数据库集成开发工具_数据仓库服务 GaussDB(DWS)_工具指南_华为云 (huaweicloud.com)
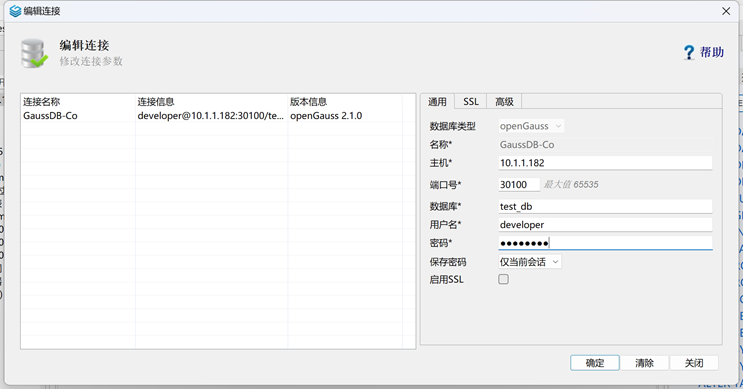
下载安装后。新建数据库连接。
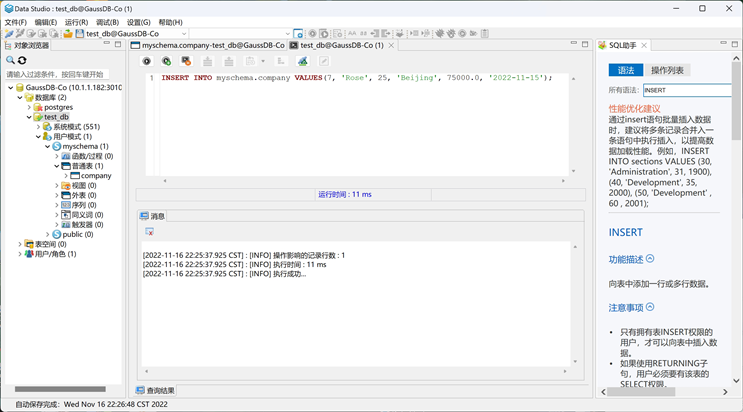
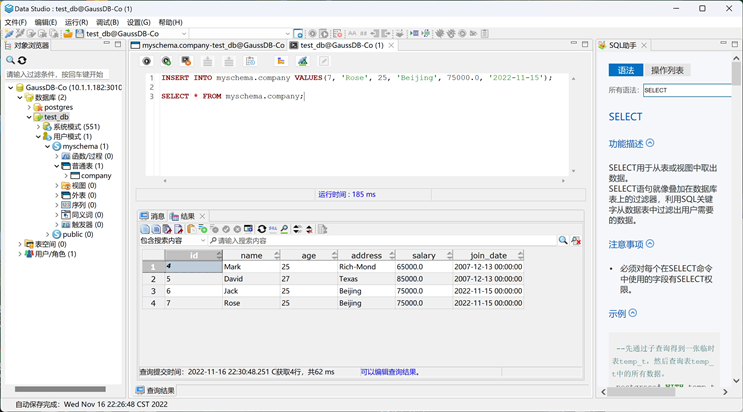
执行对应的SQL,结果如下图所示。
还可以使用DBeaver,支持平台: Windows, Linux, MacOS。
经测试,DataGrip能连接成功, 但很多地方都有问题, 无法正常使用.
3.3 使用java开发
相关jar包在如下网页获取 https://support.huaweicloud.com/intl/en-us/qs-opengauss/opengauss_jdbc_connect.html
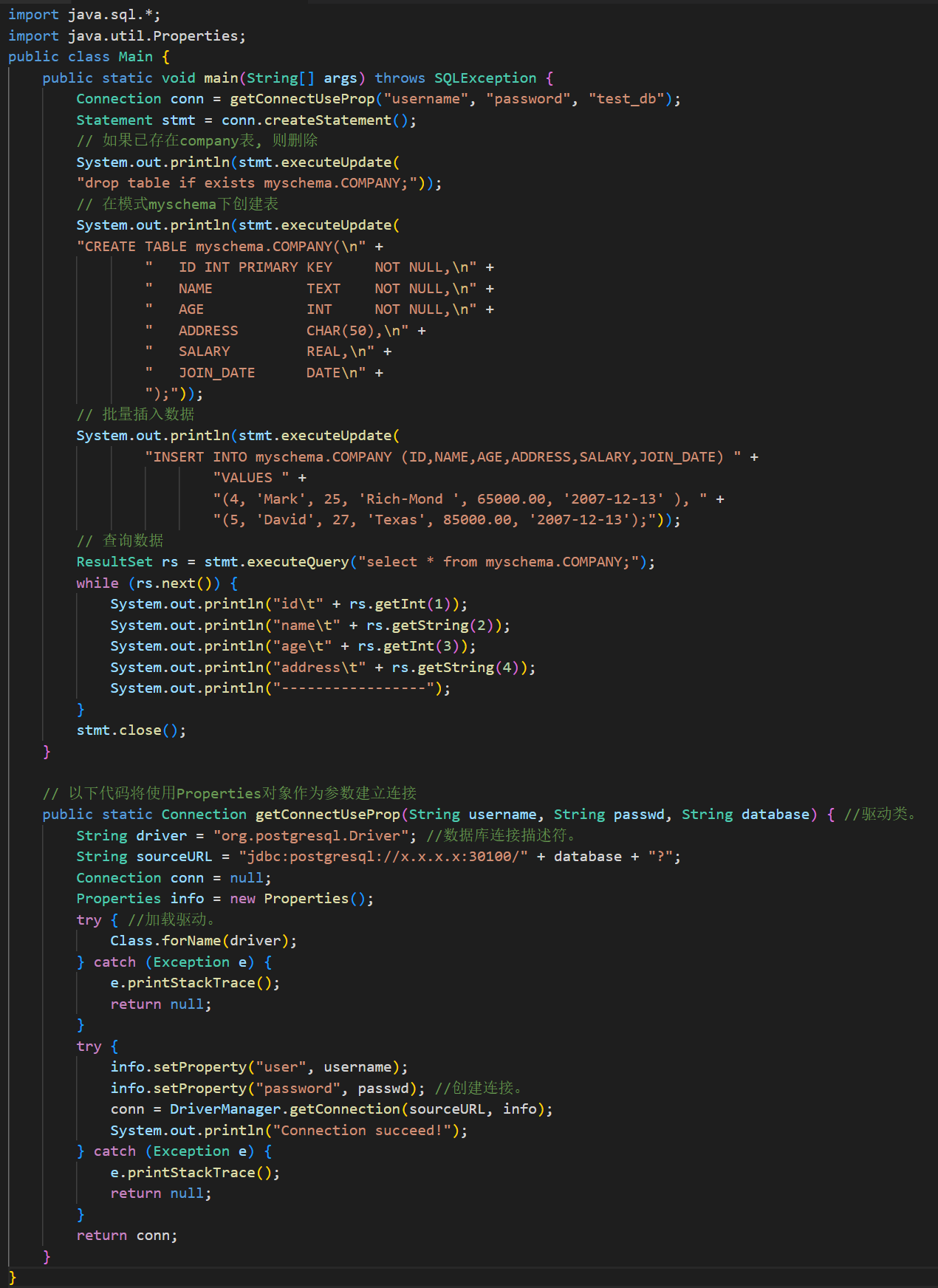
下面是使用Java连接GaussDB, 并进行如下操作的代码:
- 如已存在company表, 则删除
- 创建表
- 批量添加数据
- 查询数据并展示