
openGauss WDR报告详细解读
openGauss WDR报告详细解读
openGauss数据库自2020年6月30日开源至今已有10个月了,在这短短的10个月内,openGauss社区用户下载量已达13W+、issue合并2000+、发行商业版本6个。仅3月份就有11家企业完成CLA签署,包括虚谷伟业、云和恩墨、优炫软件、海量数据、柏睿数据、快立方,电信天翼云、东方通、宝兰德、新数科技、深信服,正式加入openGauss社区,越来越多的力量参与到社区建设中。4月24日,openGauss社区理事会筹备会议在深圳大学城召开,邀请到国内著名的数据库技术方向上的多个公司、组织和机构,包括华为、招商银行、中国电信、云和恩墨、海量数据、人大金仓、神舟通用、虚谷伟业、快立方、亚信、超图软件、深信服、哈工大等机构参与,为openGauss社区开放治理迈出了新的一步。
openGauss数据库在经历1.0.0/1.0.1/1.1.0三个版本的迭代发布后,于2021年3月31日发布openGauss 2.0.0版本,这是openGauss社区发布的第一个Release版本。深度融合华为在数据库领域多年的经验,结合企业级场景需求,持续构建竞争力特性。
作为一名从Oracle DBA转openGauss相关工作的“IT攻城狮”,在遇到性能诊断时念念不忘的还是以前经常使用的AWR报告,通过这份报告,DBA可以较为全面的分析出数据库的性能问题所在范围、为下一步的数据库性能优化和故障诊断提供有力支撑。很高兴在openGauss数据库中也看到了类似的功能,那就是openGauss的WDR报告。
本文针对openGauss 2.0.0的WDR报告进行详细解读,帮助大家梳理WDR报告的数据来源以及相关含义,以便在openGauss数据库的性能诊断工作中游刃有余。关于性能调优操作方法,由于涉及内容较多,这里就不再复述,再写下去就该被老板炒鱿鱼了。openGauss数据库归根结底,它的本质还是数据库软件,主流的数据库调优方法在openGauss数据库中也基本适用,大家仁者见仁、智者见智,根据WDR报告结合自己已有的数据库调优方法,完全可以满足openGauss绝大多数的性能调优工作。
干货内容如下:
1. 启用WDR报告的snapshot收集
$ gs_guc reload -N all -I all -c "enable_wdr_snapshot=on" postgres=# select name,setting from pg_settings where name like '%wdr%'; name | setting -----------------------------+--------- enable_wdr_snapshot | on -- 开启数据库监控快照功能 wdr_snapshot_interval | 60 -- 后台Snapshot线程执行监控快照的时间间隔 wdr_snapshot_query_timeout | 100 -- 快照操作相关的sql语句的执行超时时间 wdr_snapshot_retention_days | 8 -- 系统中数据库监控快照数据的保留天数2. WDR信息表
1> snapshot.snapshot 【记录当前系统中存储的WDR快照信息】
postgres=# \d snapshot.snapshot Table "snapshot.snapshot" Column | Type | Modifiers -------------+--------------------------+----------- snapshot_id | bigint | not null -- WDR快照序列号 start_ts | timestamp with time zone | -- WDR快照的开始时间 end_ts | timestamp with time zone | -- WDR快照的结束时间2> snapshot.tables_snap_timestamp【记录所有表的WDR快照信息】
postgres=# \d snapshot.tables_snap_timestamp Table "snapshot.tables_snap_timestamp" Column | Type | Modifiers -------------+--------------------------+----------- snapshot_id | bigint | not null -- WDR快照序列号 db_name | text | -- WDR snapshot对应的database tablename | text | -- WDR snasphot对应的table start_ts | timestamp with time zone | -- WDR快照的开始时间 end_ts | timestamp with time zone | -- WDR快照的结束时间3. WDR数据表
说明:WDR的数据表保存在snapshot这个schema下以snap_开头的表,其数据来源于dbe_perf这个schema内的视图
postgres=# select relname from pg_class where relname like '%snap_%'; ---------------------------------------------------------------------------------------------------------------- snapshot.tables_snap_timestamp -- 记录所有存储的WDR快照中数据库、表对象、数据采集的开始、结束时间 snapshot.snapshot -- 记录当前系统中存储的WDR快照数据的索引信息、开始、结束时间 snapshot.snapshot_pkey -- snapshot.snapshot表的primary key snapshot.snap_seq -- 序列 snapshot.snap_global_os_runtime -- 操作系统运行状态信息 snapshot.snap_global_os_threads -- 线程状态信息 snapshot.snap_global_instance_time -- 各种时间消耗信息(时间类型见instance_time视图) snapshot.snap_summary_workload_sql_count -- 各数据库主节点的workload上的SQL数量分布 snapshot.snap_summary_workload_sql_elapse_time -- 数据库主节点上workload(业务)负载的SQL耗时信息 snapshot.snap_global_workload_transaction -- 各节点上的workload的负载信息 snapshot.snap_summary_workload_transaction -- 汇总的负载事务信息 snapshot.snap_global_thread_wait_status -- 工作线程以及辅助线程的阻塞等待情况 snapshot.snap_global_memory_node_detail -- 节点的内存使用情况 snapshot.snap_global_shared_memory_detail -- 共享内存上下文的使用情况 snapshot.snap_global_stat_db_cu -- 数据库的CU命中情况,可以通过gs_stat_reset()进行清零 snapshot.snap_global_stat_database -- 数据库的统计信息 snapshot.snap_summary_stat_database -- 汇总的数据库统计信息 snapshot.snap_global_stat_database_conflicts -- 数据库冲突状态的统计信息 snapshot.snap_summary_stat_database_conflicts -- 汇总的数据库冲突状态的统计信息 snapshot.snap_global_stat_bad_block -- 表、索引等文件的读取失败信息 snapshot.snap_summary_stat_bad_block -- 汇总的表、索引等文件的读取失败信息 snapshot.snap_global_file_redo_iostat -- Redo(WAL)相关统计信息 snapshot.snap_summary_file_redo_iostat -- 汇总的Redo(WAL)相关统计信息 snapshot.snap_global_rel_iostat -- 数据对象IO统计信息 snapshot.snap_summary_rel_iostat -- 汇总的数据对象IO统计信息 snapshot.snap_global_file_iostat -- 数据文件IO统计信息 snapshot.snap_summary_file_iostat -- 汇总的数据文件IO统计信息 snapshot.snap_global_replication_slots -- 复制节点的信息 snapshot.snap_global_bgwriter_stat -- 后端写进程活动的统计信息 snapshot.snap_global_replication_stat -- 日志同步状态信息 snapshot.snap_global_transactions_running_xacts -- 各节点运行事务的信息 snapshot.snap_summary_transactions_running_xacts -- 汇总各节点运行事务的信息 snapshot.snap_global_transactions_prepared_xacts -- 当前准备好进行两阶段提交的事务的信息 snapshot.snap_summary_transactions_prepared_xacts -- 汇总的当前准备好进行两阶段提交的事务的信息 snapshot.snap_summary_statement -- SQL语句的全量信息 snapshot.snap_global_statement_count -- 当前时刻执行的DML/DDL/DQL/DCL语句统计信息 snapshot.snap_summary_statement_count -- 汇总的当前时刻执行的DML/DDL/DQL/DCL语句统计信息 snapshot.snap_global_config_settings -- 数据库运行时参数信息 snapshot.snap_global_wait_events -- event等待相关统计信息 snapshot.snap_summary_user_login -- 用户登录和退出次数的相关信息 snapshot.snap_global_ckpt_status -- 实例的检查点信息和各类日志刷页情况 snapshot.snap_global_double_write_status -- 实例的双写文件的情况 snapshot.snap_global_pagewriter_status -- 实例的刷页信息和检查点信息 snapshot.snap_global_redo_status -- 实例的日志回放情况 snapshot.snap_global_rto_status -- 极致RTO状态信息 snapshot.snap_global_recovery_status -- 主机和备机的日志流控信息 snapshot.snap_global_threadpool_status -- 节点上的线程池中工作线程及会话的状态信息 snapshot.snap_statement_responsetime_percentile -- SQL响应时间P80、P95分布信息 snapshot.snap_global_statio_all_indexes -- 数据库中的每个索引行、显示特定索引的I/O的统计 snapshot.snap_summary_statio_all_indexes -- 汇总的数据库中的每个索引行、显示特定索引的I/O的统计 snapshot.snap_global_statio_all_sequences -- 数据库中每个序列的每一行、显示特定序列关于I/O的统计 snapshot.snap_summary_statio_all_sequences -- 汇总的数据库中每个序列的每一行、显示特定序列关于I/O的统计 snapshot.snap_global_statio_all_tables -- 数据库中每个表(包括TOAST表)的I/O的统计 snapshot.snap_summary_statio_all_tables -- 汇总的数据库中每个表(包括TOAST表)的I/O的统计 snapshot.snap_global_stat_all_indexes -- 数据库中的每个索引行,显示访问特定索引的统计 snapshot.snap_summary_stat_all_indexes -- 汇总的数据库中的每个索引行,显示访问特定索引的统计 snapshot.snap_summary_stat_user_functions -- 汇总的数据库节点用户自定义函数的相关统计信息 snapshot.snap_global_stat_user_functions -- 用户所创建的函数的状态的统计信息 snapshot.snap_global_stat_all_tables -- 每个表的一行(包括TOAST表)的统计信息 snapshot.snap_summary_stat_all_tables -- 汇总的每个表的一行(包括TOAST表)的统计信息 snapshot.snap_class_vital_info -- 校验相同的表或者索引的Oid是否一致 snapshot.snap_global_record_reset_time -- 重置(重启,主备倒换,数据库删除)openGauss统计信息时间 snapshot.snap_summary_statio_indexes_name -- 表snap_summary_statio_all_indexes的索引 snapshot.snap_summary_statio_tables_name -- 表snap_summary_statio_all_tables的索引 snapshot.snap_summary_stat_indexes_name -- 表snap_summary_stat_all_indexes的索引 snapshot.snap_class_info_name -- 表snap_class_vital_info的索引 (66 rows) ----------------------------------------------------------------------------------------------------------------4. WDR报告创建
4.1 创建snapshot
-- 当开启enable_wdr_snapshot参数时,数据库默认每小时自动执行一次snapshot操作。 -- 当然特定情况下,也可以手动使用函数创建snapshot,如:select create_wdr_snapshot(); postgres=# select * from snapshot.snapshot offset 20; snapshot_id | start_ts | end_ts -------------+-------------------------------+------------------------------- 21 | 2021-04-21 05:59:09.337877+08 | 2021-04-21 05:59:10.249162+08 22 | 2021-04-21 06:59:10.3209+08 | 2021-04-21 06:59:11.229808+08 23 | 2021-04-21 07:59:10.426882+08 | 2021-04-21 07:59:11.340277+08 24 | 2021-04-21 08:59:10.534251+08 | 2021-04-21 08:59:11.447762+08 25 | 2021-04-21 09:59:11.448225+08 | 2021-04-21 09:59:26.121124+084.2 查询数据库节点信息
postgres=# select * from pg_node_env; node_name | host | process | port | installpath | datapath | log_directory -----------+--------------+---------+-------+--------------+-------------------+--------------------------------- dn_6001 | 192.168.0.99 | 9442 | 26000 | /gaussdb/app | /gaussdb/data/db1 | /gaussdb/log/omm/pg_log/dn_60014.3 创建WDR Report[使用gsql客户端生成]
postgres=# \a \t \o WDR_20210421.html -- 打开格式化输出,输出WDR报告:WDR_20210421.html postgres=# select generate_wdr_report(24,25,'all','node','dn_6001'); -- 生成WDR报告 postgres=# \o \a \t -- 关闭格式化输出函数说明:generate_wdr_report()
-- 语法 select generate_wdr_report(begin_snap_id bigint, end_snap_id bigint, report_type cstring, report_scope cstring, node_name cstring); -- 选项: begin_snap_id:查询时间段开始的snapshot的id(表snapshot.snaoshot中的snapshot_id) end_snap_id: 查询时间段结束snapshot的id。默认end_snap_id大于begin_snap_id(表snapshot.snaoshot中的snapshot_id) report_type: 指定生成report的类型。例如,summary/detail/all,其中:summary[汇总数据]/detail[明细数据]/all[包含summary和detail] report_scope: 指定生成report的范围,可以为cluster或者node,其中:cluster是数据库级别的信息,node是节点级别的信息。 node_name: 当report_scope指定为node时,需要把该参数指定为对应节点的名称。当report_scope为cluster时,该值可以省略或者指定为空或NULL。node[节点名称]、cluster[省略/空/NULL]5. WDR报告解读
说明:为了使得WDR报告内容不空洞,本次在测试环境使用BenchmarkSQL对openGauss数据库进行压力测试。 本次解读的WDR报告样例来自于此时采集的snapshot数据。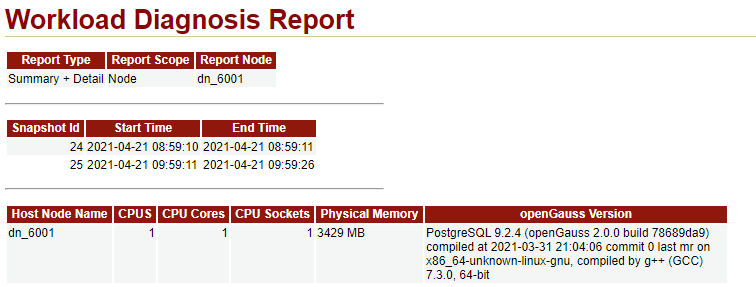
解读:
这一部分是WDR报告的概况信息,从这一部分我们能得到如下信息:
| 信息分类 | 信息描述 |
| 报告采集类型 | Summary + Detail,即汇总数据+明细数据 |
| Snapshot信息 | 使用snapshot_id为24和25的快照采集2021-04-21(08:59 ~ 09:59)的运行信息 |
| 硬件配置 | 1*1c/4g |
| 节点名 | dn_6001 |
| openGauss版本 | openGauss 2.0.0 |
相关代码:
第一部分,Report Type/Report Scope/Report Node内容来源于执行generate_wdr_report函数时输入的参数,详见源码“GenReport::ShowReportType(report_params* params)” 第二部分查询SQL:(变量ld-->snapshot_id) select snapshot_id as "Snapshot Id", to_char(start_ts, 'YYYY-MM-DD HH24:MI:SS') as "Start Time", to_char(end_ts, 'YYYY-MM-DD HH24:MI:SS') as "End Time" from snapshot.snapshot where snapshot_id = %ld or snapshot_id = %ld; 第三部分查询SQL:(变量ld-->snapshot_id) select 'CPUS', x.snap_value from (select * from pg_node_env) t, (select * from snapshot.snap_global_os_runtime) x where x.snap_node_name = t.node_name and x.snapshot_id = %ld and (x.snap_name = 'NUM_CPUS'); select 'CPU Cores', x.snap_value from (select * from pg_node_env) t, (select * from snapshot.snap_global_os_runtime) x where x.snap_node_name = t.node_name and x.snapshot_id = %ld and x.snap_name = 'NUM_CPU_CORES'; select 'CPU Sockets', x.snap_value from (select * from pg_node_env) t, (select * from snapshot.snap_global_os_runtime) x where x.snap_node_name = t.node_name and x.snapshot_id = %ld and x.snap_name = 'NUM_CPU_SOCKETS'; select 'Physical Memory', pg_size_pretty(x.snap_value) from (select * from pg_node_env) t, (select * from snapshot.snap_global_os_runtime) x where x.snap_node_name = t.node_name and x.snapshot_id = %ld and x.snap_name = 'PHYSICAL_MEMORY_BYTES'; select node_name as "Host Node Name" from pg_node_env; select version() as "openGauss Version";
解读:
这一部分是实例的效率百分比,目标值是100%,即越接近100%,数据库运行越健康。
Buffer Hit: 即数据库请求的数据在buffer中命中的比例,该指标越高代表openGauss在buffer中查询到目标数据的概率越高,数据读取性能越好。
Effective CPU: 即有效的CPU使用比例,该指标偏小则说明CPU的有效使用偏低,处于等待状态的比例可能较高。
WalWrite NoWait: 即WAL日志写入时不等待的比例,该指标接近100%,说明buffer容量充足,可以满足WAL写操作的需求,若指标值偏小则可能需要调大buffer容量。
Soft Parse: 即SQL软解析的比例,该指标接近100%,说明当前执行的SQL基本都可以在Buffer中找到,若指标值偏小则说明存在大量硬解析,需要分析原因,对DML语句进行适度优化。
Non-Parse CPU: 即非解析占用的CPU比例,该指标接近100%,说明SQL解析并没有占用较多的CPU时间。
相关代码:
-- 变量:ld指的是snapshot_id,手动执行以下SQL语句时请自行替换对应的snapshot_id select unnest(array['Buffer Hit %%', 'Effective CPU %%', 'WalWrite NoWait %%', 'Soft Parse %%', 'Non-Parse CPU %%']) as "Metric Name", unnest(array[case when s1.all_reads = 0 then 1 else round(s1.blks_hit * 100 / s1.all_reads) end, s2.cpu_to_elapsd, s3.walwrite_nowait, s4.soft_parse, s5.non_parse]) as "Metric Value" from (select (snap_2.all_reads - coalesce(snap_1.all_reads, 0)) as all_reads, (snap_2.blks_hit - coalesce(snap_1.blks_hit, 0)) as blks_hit from (select sum(coalesce(snap_blks_read, 0) + coalesce(snap_blks_hit, 0)) as all_reads, coalesce(sum(snap_blks_hit), 0) as blks_hit from snapshot.snap_summary_stat_database where snapshot_id = %ld) snap_1, (select sum(coalesce(snap_blks_read, 0) + coalesce(snap_blks_hit, 0)) as all_reads, coalesce(sum(snap_blks_hit), 0) as blks_hit from snapshot.snap_summary_stat_database where snapshot_id = %ld) snap_2 ) s1, (select round(cpu_time.snap_value * 100 / greatest(db_time.snap_value, 1)) as cpu_to_elapsd from (select coalesce(snap_2.snap_value, 0) - coalesce(snap_1.snap_value, 0) as snap_value from (select snap_stat_name, snap_value from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_stat_name = 'CPU_TIME') snap_1, (select snap_stat_name, snap_value from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_stat_name = 'CPU_TIME') snap_2) cpu_time, (select coalesce(snap_2.snap_value, 0) - coalesce(snap_1.snap_value, 0) as snap_value from (select snap_stat_name, snap_value from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_stat_name = 'DB_TIME') snap_1, (select snap_stat_name, snap_value from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_stat_name = 'DB_TIME') snap_2) db_time ) s2, (select (bufferAccess.snap_wait - bufferFull.snap_wait) * 100 / greatest(bufferAccess.snap_wait, 1) as walwrite_nowait from (select coalesce(snap_2.snap_wait) - coalesce(snap_1.snap_wait, 0) as snap_wait from (select snap_wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event = 'WALBufferFull') snap_1, (select snap_wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event = 'WALBufferFull') snap_2) bufferFull, (select coalesce(snap_2.snap_wait) - coalesce(snap_1.snap_wait, 0) as snap_wait from (select snap_wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event = 'WALBufferAccess') snap_1, (select snap_wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event = 'WALBufferAccess') snap_2) bufferAccess ) s3, (select round((snap_2.soft_parse - snap_1.soft_parse) * 100 / greatest((snap_2.hard_parse + snap_2.soft_parse)-(snap_1.hard_parse + snap_1.soft_parse), 1)) as soft_parse from (select sum(snap_n_soft_parse) as soft_parse, sum(snap_n_hard_parse) as hard_parse from snapshot.snap_summary_statement where snapshot_id = %ld ) snap_1, (select sum(snap_n_soft_parse) as soft_parse, sum(snap_n_hard_parse) as hard_parse from snapshot.snap_summary_statement where snapshot_id = %ld ) snap_2 ) s4, (select round((snap_2.elapse_time - snap_1.elapse_time) * 100 /greatest((snap_2.elapse_time + snap_2.parse_time)-(snap_1.elapse_time + snap_1.parse_time), 1)) as non_parse from (select sum(snap_total_elapse_time) as elapse_time, sum(snap_parse_time) as parse_time from snapshot.snap_summary_statement where snapshot_id = %ld ) snap_1, (select sum(snap_total_elapse_time) as elapse_time, sum(snap_parse_time) as parse_time from snapshot.snap_summary_statement where snapshot_id = %ld ) snap_2 ) s5; 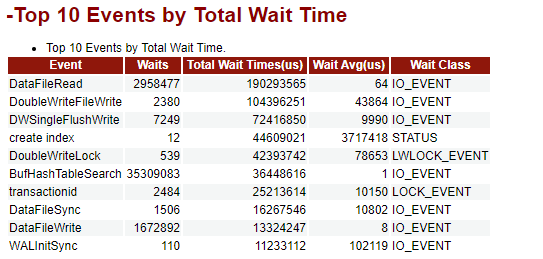
解读:
这一部分列出了数据库Top 10的等待事件、等待次数、总等待时间、平均等待时间、等待事件类型。
等待事件主要分为等待状态、等待轻量级锁、等待IO、等待事务锁这4类,详见下表所示:
- 等待状态列表
当wait_status为acquire lwlock、acquire lock或者wait io时,表示有等待事件。
正在等待获取wait_event列对应类型的轻量级锁、事务锁,或者正在进行IO。
- 轻量级锁等待事件列表
当wait_status值为acquire lwlock(轻量级锁)时对应的wait_event等待事件类型即为轻量级锁等待。
wait_event为extension时,表示此时的轻量级锁是动态分配的锁,未被监控。
|
wait_event类型 | |
|---|---|
- IO等待事件列表
当wait_status值为wait io时对应的wait_event等待事件类型即为IO等待事件。
- 事务锁等待事件列表
当wait_status值为acquire lock(事务锁)时对应的wait_event等待事件类型为事务锁等待事件。
| wait_event类型 | 类型描述 |
|---|---|
| relation | 对表加锁 |
| extend | 对表扩展空间时加锁 |
| partition | 对分区表加锁 |
| partition_seq | 对分区表的分区加锁 |
| page | 对表页面加锁 |
| tuple | 对页面上的tuple加锁 |
| transactionid | 对事务ID加锁 |
| virtualxid | 对虚拟事务ID加锁 |
| object | 加对象锁 |
| cstore_freespace | 对列存空闲空间加锁 |
| userlock | 加用户锁 |
| advisory | 加advisory锁 |
相关代码:
-- 说明:变量ld-->snapshot_id, 变量s-->node_name select snap_event as "Event", snap_wait as "Waits", snap_total_wait_time as "Total Wait Times(us)", round(snap_total_wait_time/snap_wait) as "Wait Avg(us)", snap_type as "Wait Class" from ( select snap_2.snap_event as snap_event, snap_2.snap_type as snap_type, snap_2.snap_wait - snap_1.snap_wait as snap_wait, snap_2.total_time - snap_1.total_time as snap_total_wait_time from (select snap_event, snap_wait, snap_total_wait_time as total_time, snap_type from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event != 'none' and snap_event != 'wait cmd' and snap_event != 'unknown_lwlock_event' and snap_nodename = '%s') snap_1, (select snap_event, snap_wait, snap_total_wait_time as total_time, snap_type from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_event != 'none' and snap_event != 'wait cmd' and snap_event != 'unknown_lwlock_event' and snap_nodename = '%s') snap_2 where snap_2.snap_event = snap_1.snap_event order by snap_total_wait_time desc limit 10) where snap_wait != 0;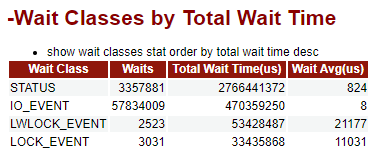
解读:
这一部分按照等待类型(STATUS、IO_EVENT、LWLOCK_EVENT、LOCK_EVENT),分类统计等待次数、总等待时间、平均等待时间。
相关代码:
-- 说明: 变量ld-->snapshot_id, 变量s-->node_name select snap_2.type as "Wait Class", (snap_2.wait - snap_1.wait) as "Waits", (snap_2.total_wait_time - snap_1.total_wait_time) as "Total Wait Time(us)", round((snap_2.total_wait_time - snap_1.total_wait_time) / greatest((snap_2.wait - snap_1.wait), 1)) as "Wait Avg(us)" from (select snap_type as type, sum(snap_total_wait_time) as total_wait_time, sum(snap_wait) as wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_nodename = '%s' and snap_event != 'unknown_lwlock_event' and snap_event != 'none' group by snap_type) snap_2 left join (select snap_type as type, sum(snap_total_wait_time) as total_wait_time, sum(snap_wait) as wait from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_nodename = '%s' and snap_event != 'unknown_lwlock_event' and snap_event != 'none' group by snap_type) snap_1 on snap_2.type = snap_1.type order by "Total Wait Time(us)" desc;
解读:
这一部分主机CPU的负载情况:CPU的平均负载、用户使用占比、系统使用占比、IO等待占比、空闲占比。
相关SQL:
select snap_2.cpus as "Cpus", snap_2.cores as "Cores", snap_2.sockets as "Sockets", snap_1.load as "Load Average Begin", snap_2.load as "Load Average End", round(coalesce((snap_2.user_time - snap_1.user_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%User", round(coalesce((snap_2.sys_time - snap_1.sys_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%System", round(coalesce((snap_2.iowait_time - snap_1.iowait_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%WIO", round(coalesce((snap_2.idle_time - snap_1.idle_time), 0) / greatest(coalesce((snap_2.total_time - snap_1.total_time), 0), 1) * 100, 2) as "%Idle" from (select H.cpus, H.cores, H.sockets, H.idle_time, H.user_time, H.sys_time, H.iowait_time, (H.idle_time + H.user_time + H.sys_time + H.iowait_time) AS total_time, H.load from (select C.cpus, E.cores, T.sockets, I.idle_time, U.user_time, S.sys_time, W.iowait_time, L.load from (select snap_value as cpus from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPUS')) AS C, (select snap_value as cores from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_CORES')) AS E, (select snap_value as sockets from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_SOCKETS')) AS T, (select snap_value as idle_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IDLE_TIME')) AS I, (select snap_value as user_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'USER_TIME')) AS U, (select snap_value as sys_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'SYS_TIME')) AS S, (select snap_value as iowait_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IOWAIT_TIME')) AS W, (select snap_value as load from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'LOAD')) AS L ) as H ) as snap_2, (select H.cpus, H.cores, H.sockets, H.idle_time, H.user_time, H.sys_time, H.iowait_time, (H.idle_time + H.user_time + H.sys_time + H.iowait_time) AS total_time, H.load from (select C.cpus, E.cores, T.sockets, I.idle_time, U.user_time, S.sys_time, W.iowait_time, L.load from (select snap_value as cpus from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPUS')) AS C, (select snap_value as cores from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_CORES')) AS E, (select snap_value as sockets from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'NUM_CPU_SOCKETS')) AS T, (select snap_value as idle_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IDLE_TIME')) AS I, (select snap_value as user_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'USER_TIME')) AS U, (select snap_value as sys_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'SYS_TIME')) AS S, (select snap_value as iowait_time from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'IOWAIT_TIME')) AS W, (select snap_value as load from snapshot.snap_global_os_runtime where (snapshot_id = %ld and snap_node_name = '%s' and snap_name = 'LOAD')) AS L ) as H ) as snap_1 ;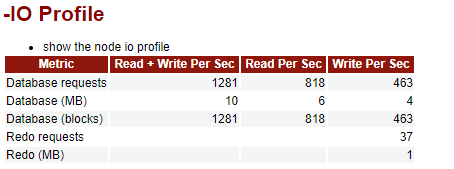
解读:
这一部分描述了openGauss在快照期间的IO负载情况。
Database requests: 即每秒IO请求次数,包括请求次数总和、读请求次数、写请求次数.
Database(blocks): 即每秒block请求数量,包含请求的block总和数量、读block的数量和写block的数量.
Database(MB): 即将block换算成容量(MB)[如:blocks * 8/1024],增加数据的可读性。
Redo requests和Redo(MB) 分别表示每秒redo的写请求次数和redo写的数据量。
相关代码:
-- 由于源码中相关SQL融合了C++程序语法,像我这种不做开发的DBA读起来有些难以理解【如:(phyblkwrt * %d) >> 20 这个段没有很好理解】。 -- 但是依旧不影响我们对这些数据采集方法的理解,相关SQL如下: -- 两个snapshot_id(24和25)期间,数据块的IO统计信息(数值除以3600即换算成以秒为单位的WDR数据) postgres=# select (snap_2.phytotal - snap_1.phytotal) as phytotal, (snap_2.phyblktotal - snap_1.phyblktotal) as phyblktotal, (snap_2.phyrds - snap_1.phyrds) as phyrds, (snap_2.phyblkrd - snap_1.phyblkrd) as phyblkrd, (snap_2.phywrts - snap_1.phywrts) as phywrts, (snap_2.phyblkwrt - snap_1.phyblkwrt) as phyblkwrt from (select (snap_phyrds + snap_phywrts) as phytotal, (snap_phyblkwrt + snap_phyblkrd) as phyblktotal, snap_phyrds as phyrds, snap_phyblkrd as phyblkrd, snap_phywrts as phywrts, snap_phyblkwrt as phyblkwrt from snapshot.snap_global_rel_iostat where snapshot_id = 24 and snap_node_name = 'dn_6001') snap_1, (select (snap_phyrds + snap_phywrts) as phytotal, (snap_phyblkwrt + snap_phyblkrd) as phyblktotal, snap_phyrds as phyrds, snap_phyblkrd as phyblkrd, snap_phywrts as phywrts, snap_phyblkwrt as phyblkwrt from snapshot.snap_global_rel_iostat where snapshot_id = 25 and snap_node_name = 'dn_6001') snap_2; phytotal | phyblktotal | phyrds | phyblkrd | phywrts | phyblkwrt ----------+-------------+---------+----------+---------+----------- 4626892 | 4626892 | 2955639 | 2955639 | 1671253 | 1671253 -- 两个snapshot_id(24和25)期间,redo的统计信息(数值除以3600即换算成以秒为单位的WDR数据) postgres=# select (snap_2.phywrts - snap_1.phywrts) as phywrts, (snap_2.phyblkwrt - snap_1.phyblkwrt) as phyblkwrt from (select sum(snap_phywrts) as phywrts, sum(snap_phyblkwrt) as phyblkwrt from snapshot.snap_global_file_redo_iostat where snapshot_id = 24 and snap_node_name = 'dn_6001') snap_1, (select sum(snap_phywrts) as phywrts, sum(snap_phyblkwrt) as phyblkwrtfrom snapshot.snap_global_file_redo_iostat where snapshot_id = 25 and snap_node_name = 'dn_6001') snap_2; phywrts | phyblkwrt ---------+----------- 132721 | 509414
解读:
这一部分描述了节点内存的变化信息,通过这些变化信息,我们可以了解到在两次快照期间,数据库的内存变化情况,作为数据库性能分析或异常分析的参考。数据来源于snapshot.snap_global_memory_node_detail。
这部分分别描述了: 内存的类型 以及 对应的起始大小和终止大小。
这里没有采集到数据的原因: 测试环境内存太小,导致启动时将memory protect关闭了,从而导致无法查询dbe_perf.global_memory_node_detail视图。 而WDR的内存统计数据(snapshot.snap_global_memory_node_detail)则来源于该视图。
另外,请确保disable_memory_protect=off。
关于这部分Memory Type常见类型如下:
| Memory 类型 | 说明 |
|---|---|
| max_process_memory | openGauss实例所占用的内存大小 |
| process_used_memory | 进程所使用的内存大小 |
| max_dynamic_memory | 最大动态内存 |
| dynamic_used_memory | 已使用的动态内存 |
| dynamic_peak_memory | 内存的动态峰值 |
| dynamic_used_shrctx | 最大动态共享内存上下文 |
| dynamic_peak_shrctx | 共享内存上下文的动态峰值 |
| max_shared_memory | 最大共享内存 |
| shared_used_memory | 已使用的共享内存 |
| max_cstore_memory | 列存所允许使用的最大内存 |
| cstore_used_memory | 列存已使用的内存大小 |
| max_sctpcomm_memory | sctp通信所允许使用的最大内存 |
| sctpcomm_used_memory | sctp通信已使用的内存大小 |
| sctpcomm_peak_memory | sctp通信的内存峰值 |
| other_used_memory | 其他已使用的内存大小 |
| gpu_max_dynamic_memory | GPU最大动态内存 |
| gpu_dynamic_used_memory | GPU已使用的动态内存 |
| gpu_dynamic_peak_memory | GPU内存的动态峰值 |
| pooler_conn_memory | 链接池申请内存计数 |
| pooler_freeconn_memory | 链接池空闲连接的内存计数 |
| storage_compress_memory | 存储模块压缩使用的内存大小 |
| udf_reserved_memory | UDF预留的内存大小 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select snap_2.snap_memorytype as "Memory Type", snap_1.snap_memorymbytes as "Begin(MB)", snap_2.snap_memorymbytes as "End(MB)" from (select snap_memorytype, snap_memorymbytes from snapshot.snap_global_memory_node_detail where (snapshot_id = %ld and snap_nodename = '%s') and (snap_memorytype = 'max_process_memory' or snap_memorytype = 'process_used_memory' or snap_memorytype = 'max_shared_memory' or snap_memorytype = 'shared_used_memory')) as snap_2 left join (select snap_memorytype, snap_memorymbytes from snapshot.snap_global_memory_node_detail where (snapshot_id = %ld and snap_nodename = '%s') and (snap_memorytype = 'max_process_memory' or snap_memorytype = 'process_used_memory' or snap_memorytype = 'max_shared_memory' or snap_memorytype = 'shared_used_memory')) as snap_1 on snap_2.snap_memorytype = snap_1.snap_memorytype;
解读:
这一部分描述了数据库各种状态所消耗的时间,关于Stat Name的解释如下:
| Stat Name | 说明 |
|---|---|
| DB_TIME | 作业在多核下的有效时间花销 |
| CPU_TIME | CPU的时间花销 |
| EXECUTION_TIME | 执行器内的时间花销 |
| PARSE_TIME | SQL解析的时间花销 |
| PLAN_TIME | 生成Plan的时间花销 |
| REWRITE_TIME | SQL重写的时间花销 |
| PL_EXECUTION_TIME | plpgsql(存储过程)执行的时间花销 |
| PL_COMPILATION_TIME | plpgsql(存储过程)编译的时间花销 |
| NET_SEND_TIME | 网络上的时间花销 |
| DATA_IO_TIME | IO上的时间花销 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select t2.snap_node_name as "Node Name", t2.snap_stat_name as "Stat Name", (t2.snap_value - coalesce(t1.snap_value, 0)) as "Value(us)" from (select * from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_node_name = '%s') t1 right join (select * from snapshot.snap_global_instance_time where snapshot_id = %ld and snap_node_name = '%s') t2 on t1.snap_stat_name = t2.snap_stat_name order by "Value(us)" desc limit 200;


解读:
这一部分分别从SQL执行时间、SQL消耗CPU的时间、SQL返回的行数、SQL扫描的行数、SQL执行的次数、SQL物理读的次数、SQL逻辑读的次数等多维度对两次快照期间的SQL执行情况进行统计。
关于表中列的含义,如下所示:
| 列名称 | 备注 |
|---|---|
| Unique SQL Id | 归一化的SQL ID, 即SQL唯一标识 |
| User Name | 执行SQL的用户 |
| Logical Read | 逻辑读,即Buffer的块访问次数 |
| Calls | SQL的调用次数 |
| Min Elapse Time(us) | SQL在内核中的最小运行时间(单位:微秒) |
| Max Elapse Time(us) | SQL在内核中的最大运行时间(单位:微秒) |
| Total Elapse Time(us) | SQL在内核中的总运行时间 (单位:微秒) |
| Avg Elapse Time(us) | SQL在内核中的平均运行时间(单位:微秒) |
| Returned Rows | SELECT返回的结果集行数 |
| Tuples Read | SQL扫描的总行数(包括顺序扫描和随机扫描) |
| Tuples Affected | SQL删除的行数 |
| Physical Read | 物理读,即下盘读取block进入buffer的次数 |
| CPU Time(us) | SQL消耗的CPU时间(单位:微秒) |
| Data IO Time(us) | IO上的时间花费(单位:微秒) |
| Sort Count | SQL排序执行的次数 |
| Sort Time(us) | SQL排序执行的时间(单位:微秒) |
| Sort Mem Used(KB) | 排序过程中使用的work memory大小(单位:KB) |
| Sort Spill Count | 排序过程中发生落盘写文件的次数 |
| Sort Spill Size(KB) | 排序过程中发生落盘写文件的大小(单位:KB) |
| Hash Count | hash执行的次数 |
| Hash Time(us) | hash执行的时间(单位:微秒) |
| Hash Mem Used(KB) | hash过程中使用的work memory大小(单位:KB) |
| Hash Spill Count | hash过程中发生落盘写文件的次数 |
| Hash Spill Size(KB) | hash过程中发生落盘写文件的大小(单位:KB) |
| SQL Text | SQL语句内容 |
Tips:Top200显得有些冗余,多余的SQL信息并没有太大用处,反而降低了可读性,希望将来能优化到Top20,。
相关代码:
-- 由于多个SQL统计信息的SQL语句类似,这里仅列举SQL执行时间的统计SQL,其他的类似。 -- 说明:%s代表node_name,%ld代表snapshot_id select t2.snap_unique_sql_id as "Unique SQL Id", t2.snap_user_name as "User Name", (t2.snap_total_elapse_time - coalesce(t1.snap_total_elapse_time, 0)) as "Total Elapse Time(us)", (t2.snap_n_calls - coalesce(t1.snap_n_calls, 0)) as "Calls", round("Total Elapse Time(us)"/greatest("Calls", 1), 0) as "Avg Elapse Time(us)", t2.snap_min_elapse_time as "Min Elapse Time(us)", t2.snap_max_elapse_time as "Max Elapse Time(us)", (t2.snap_n_returned_rows - coalesce(t1.snap_n_returned_rows, 0)) as "Returned Rows", ((t2.snap_n_tuples_fetched - coalesce(t1.snap_n_tuples_fetched, 0)) + (t2.snap_n_tuples_returned - coalesce(t1.snap_n_tuples_returned, 0))) as "Tuples Read", ((t2.snap_n_tuples_inserted - coalesce(t1.snap_n_tuples_inserted, 0)) + (t2.snap_n_tuples_updated - coalesce(t1.snap_n_tuples_updated, 0)) + (t2.snap_n_tuples_deleted - coalesce(t1.snap_n_tuples_deleted, 0))) as "Tuples Affected", (t2.snap_n_blocks_fetched - coalesce(t1.snap_n_blocks_fetched, 0)) as "Logical Read", ((t2.snap_n_blocks_fetched - coalesce(t1.snap_n_blocks_fetched, 0)) - (t2.snap_n_blocks_hit - coalesce(t1.snap_n_blocks_hit, 0))) as "Physical Read", (t2.snap_cpu_time - coalesce(t1.snap_cpu_time, 0)) as "CPU Time(us)", (t2.snap_data_io_time - coalesce(t1.snap_data_io_time, 0)) as "Data IO Time(us)", (t2.snap_sort_count - coalesce(t1.snap_sort_count, 0)) as "Sort Count", (t2.snap_sort_time - coalesce(t1.snap_sort_time, 0)) as "Sort Time(us)", (t2.snap_sort_mem_used - coalesce(t1.snap_sort_mem_used, 0)) as "Sort Mem Used(KB)", (t2.snap_sort_spill_count - coalesce(t1.snap_sort_spill_count, 0)) as "Sort Spill Count", (t2.snap_sort_spill_size - coalesce(t1.snap_sort_spill_size, 0)) as "Sort Spill Size(KB)", (t2.snap_hash_count - coalesce(t1.snap_hash_count, 0)) as "Hash Count", (t2.snap_hash_time - coalesce(t1.snap_hash_time, 0)) as "Hash Time(us)", (t2.snap_hash_mem_used - coalesce(t1.snap_hash_mem_used, 0)) as "Hash Mem Used(KB)", (t2.snap_hash_spill_count - coalesce(t1.snap_hash_spill_count, 0)) as "Hash Spill Count", (t2.snap_hash_spill_size - coalesce(t1.snap_hash_spill_size, 0)) as "Hash Spill Size(KB)", LEFT(t2.snap_query, 25) as "SQL Text" from (select * from snapshot.snap_summary_statement where snapshot_id = %ld and snap_node_name = '%s') t1 right join (select * from snapshot.snap_summary_statement where snapshot_id = %ld and snap_node_name = '%s') t2 on t1.snap_unique_sql_id = t2.snap_unique_sql_id and t1.snap_user_id = t2.snap_user_id order by "Total Elapse Time(us)" desc limit 200;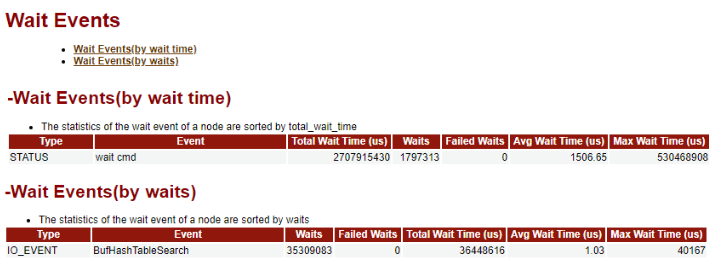
解读:
这一部分分别从等待时长、等待次数这两个维度对等待事件进行统计。
表格中列的含义即就是列的英文翻译,这里就不再复述了。
具体的等待事件的介绍详见前文:“Top 10 Events by Total Wait Time”部分的内容,这里也不再复述。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id,无论从哪个维度统计,基本的SQL语句差异不大,这里仅列举"by wait time"的SQL示例select t2.snap_type as "Type", t2.snap_event as "Event", (t2.snap_total_wait_time - coalesce(t1.snap_total_wait_time, 0)) as "Total Wait Time (us)", (t2.snap_wait - coalesce(t1.snap_wait, 0)) as "Waits", (t2.snap_failed_wait - coalesce(t1.snap_failed_wait, 0)) as "Failed Waits", (case "Waits" when 0 then 0 else round("Total Wait Time (us)" / "Waits", 2) end) as "Avg Wait Time (us)", t2.snap_max_wait_time as "Max Wait Time (us)" from (select * from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_nodename = '%s' and snap_event != 'unknown_lwlock_event' and snap_event != 'none') t1 right join (select * from snapshot.snap_global_wait_events where snapshot_id = %ld and snap_nodename = '%s' and snap_event != 'unknown_lwlock_event' and snap_event != 'none') t2 on t1.snap_event = t2.snap_event order by "Total Wait Time (us)" desc limit 200;
解读:
这一部分根据Heap block的命中率排序统计用户表的IO活动状态。
数据来源于snapshot.snap_global_statio_all_indexes表和snapshot.snap_global_statio_all_tables表。
该表相关列的介绍如下:
| 列名 | 描述 |
|---|---|
| DB Name | 数据库名 |
| Schema Name | 模式名 |
| Table Name | 表名 |
| %Heap Blks Hit Ratio | 数据块读取缓存命中率=heap_blks_hit/(heap_blks_read+heap_blks_hit)*100 |
| Heap Blks Read | 从该表中读取的磁盘块数 |
| Heap Blks Hit | 此表缓存命中数 |
| Idx Blks Read | 从表中所有索引读取的磁盘块数 |
| Idx Blks Hit | 表中所有索引命中缓存数 |
| Toast Blks Read | 此表的TOAST表读取的磁盘块数(如果存在) |
| Toast Blks Hit | 此表的TOAST表命中缓冲区数(如果存在) |
| Tidx Blks Read | 此表的TOAST表索引读取的磁盘块数(如果存在) |
| Tidx Blks Hit | 此表的TOAST表索引命中缓冲区数(如果存在) |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT table_io.db_name as "DB Name", table_io.snap_schemaname as "Schema Name", table_io.snap_relname as "Table Name", table_io.heap_blks_hit_ratio as "%Heap Blks Hit Ratio", table_io.heap_blks_read as "Heap Blks Read", table_io.heap_blks_hit as "Heap Blks Hit", idx_io.idx_blks_read as "Idx Blks Read", idx_io.idx_blks_hit as "Idx Blks Hit", table_io.toast_blks_read as "Toast Blks Read", table_io.toast_blks_hit as "Toast Blks Hit", table_io.tidx_blks_read as "Tidx Blks Read", table_io.tidx_blks_hit as "Tidx Blks Hit" FROM (select t2.db_name, t2.snap_schemaname , t2.snap_relname , (case when ((t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) + (t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))) = 0 then 0 else round((t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))/ ((t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) + (t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0))) * 100, 2) end ) as heap_blks_hit_ratio, (t2.snap_heap_blks_read - coalesce(t1.snap_heap_blks_read, 0)) as heap_blks_read, (t2.snap_heap_blks_hit - coalesce(t1.snap_heap_blks_hit, 0)) as heap_blks_hit, (t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as idx_blks_read, (t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as idx_blks_hit, (t2.snap_toast_blks_read - coalesce(t1.snap_toast_blks_read, 0)) as toast_blks_read, (t2.snap_toast_blks_hit - coalesce(t1.snap_toast_blks_hit, 0)) as toast_blks_hit, (t2.snap_tidx_blks_read - coalesce(t1.snap_tidx_blks_read, 0)) as tidx_blks_read, (t2.snap_tidx_blks_hit - coalesce(t1.snap_tidx_blks_hit, 0)) as tidx_blks_hit from (select * from snapshot.snap_global_statio_all_tables where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') t1 right join (select * from snapshot.snap_global_statio_all_tables where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') t2 on t1.snap_relid = t2.snap_relid and t2.db_name = t1.db_name and t2.snap_schemaname = t1.snap_schemaname ) as table_io LEFT JOIN (select t2.db_name , t2.snap_schemaname , t2.snap_relname, (t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as idx_blks_read, (t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as idx_blks_hit from (select * from snapshot.snap_global_statio_all_indexes where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') t1 right join (select * from snapshot.snap_global_statio_all_indexes where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') AND snap_schemaname !~ '^pg_toast') t2 on t1.snap_relid = t2.snap_relid and t2.snap_indexrelid = t1.snap_indexrelid and t2.db_name = t1.db_name and t2.snap_schemaname = t1.snap_schemaname) as idx_io on table_io.db_name = idx_io.db_name and table_io.snap_schemaname = idx_io.snap_schemaname and table_io.snap_relname = idx_io.snap_relname order by "%%Heap Blks Hit Ratio" asc limit 200;
解读:
这一部分根据索引缓存命中率,统计用户索引IO活动信息。
数据来源于snapshot.snap_global_statio_all_indexes表。
相关列信息如下:
| 列名 | 介绍 |
|---|---|
| DB Name | 数据库名 |
| Schema Name | 模式名 |
| Table Name | 表名 |
| Index Name | 索引名 |
| %Idx Blks Hit Ratio | 索引缓冲命中率=“Idx Blks Hit”/(“Idx Blks Hit”+“Idx Blks Read”)*100 |
| Idx Blks Read | 从索引中读取的磁盘块数 |
| Idx Blks Hit | 索引命中缓存数 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select t2.db_name as "DB Name", t2.snap_schemaname as "Schema Name", t2.snap_relname as "Table Name", t2.snap_indexrelname as "Index Name", (case when ((t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) + (t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0))) = 0 then 0 else round((t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0))/((t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) + (t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0))) * 100, 2) end) as "%Idx Blks Hit Ratio", (t2.snap_idx_blks_read - coalesce(t1.snap_idx_blks_read, 0)) as "Idx Blks Read", (t2.snap_idx_blks_hit - coalesce(t1.snap_idx_blks_hit, 0)) as "Idx Blks Hit" from (select * from snapshot.snap_global_statio_all_indexes where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') t1 right join (select * from snapshot.snap_global_statio_all_indexes where snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') t2on t1.snap_relid = t2.snap_relid and t2.snap_indexrelid = t1.snap_indexrelid and t2.db_name = t1.db_name and t2.snap_schemaname = t1.snap_schemaname order by "%Idx Blks Hit Ratio" asc limit 200;
解读:
此处存在缺陷,统计的数据有问题,个人认为SQL语句需要修改,详见“相关代码”。
这一部分描述的是后台写操作的统计信息,数据来源于snapshot.snap_global_bgwriter_stat表。
具体内容如下:
| 列名 | 数据获取相关函数 | 说明 |
|---|---|---|
| Checkpoints Timed | pg_stat_get_bgwriter_timed_checkpoints() | 执行的定期检查点数 |
| Checkpoints Require | pg_stat_get_bgwriter_requested_checkpoints() | 执行的需求检查点数 |
| Checkpoint Write Time(ms) | pg_stat_get_checkpoint_write_time() | 检查点操作中,文件写入到磁盘消耗的时间(单位:毫秒) |
| Checkpoint Sync Time(ms) | pg_stat_get_checkpoint_sync_time() | 检查点操作中,文件同步到磁盘消耗的时间(单位:毫秒) |
| Buffers Checkpoint | pg_stat_get_bgwriter_buf_written_checkpoints() | 检查点写缓冲区数量 |
| Buffers Clean | pg_stat_get_bgwriter_buf_written_clean() | 后端写线程写缓冲区数量 |
| Maxwritten Clean | pg_stat_get_bgwriter_maxwritten_clean() | 后端写线程停止清理Buffer的次数 |
| Buffers Backend | pg_stat_get_buf_written_backend() | 通过后端直接写缓冲区数 |
| Buffers Backend | Fsync pg_stat_get_buf_fsync_backend() | 后端不得不执行自己的fsync调用的时间数(通常后端写进程处理这些即使后端确实自己写) |
| Buffers Alloc | pg_stat_get_buf_alloc() 分配的缓冲区数量 | |
| Stats Reset | pg_stat_get_bgwriter_stat_reset_time() | 这些统计被重置的时间 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select (snap_2.snap_checkpoints_timed - coalesce(snap_1.snap_checkpoints_timed, 0)) AS "Checkpoints Timed", (snap_2.snap_checkpoints_req - coalesce(snap_1.snap_checkpoints_req, 0)) AS "Checkpoints Require", (snap_2.snap_checkpoint_write_time - coalesce(snap_1.snap_checkpoint_write_time, 0)) AS "Checkpoint Write Time(ms)", (snap_2.snap_checkpoint_sync_time - coalesce(snap_1.snap_checkpoint_sync_time, 0)) AS "Checkpoint Sync Time(ms)", (snap_2.snap_buffers_checkpoint - coalesce(snap_1.snap_buffers_checkpoint, 0)) AS "Buffers Checkpoint", (snap_2.snap_buffers_clean - coalesce(snap_1.snap_buffers_clean, 0)) AS "Buffers Clean", (snap_2.snap_maxwritten_clean - coalesce(snap_1.snap_maxwritten_clean, 0)) AS "Maxwritten Clean", (snap_2.snap_buffers_backend - coalesce(snap_1.snap_buffers_backend, 0)) AS "Buffers Backend", (snap_2.snap_buffers_backend_fsync - coalesce(snap_1.snap_buffers_backend_fsync, 0)) AS "Buffers Backend Fsync", (snap_2.snap_buffers_alloc - coalesce(snap_1.snap_buffers_alloc, 0)) AS "Buffers Alloc", to_char(snap_2.snap_stats_reset, 'YYYY-MM-DD HH24:MI:SS') AS "Stats Reset" from (select * from snapshot.snap_global_bgwriter_stat where snapshot_id = %ld and snap_node_name = '%s') snap_2 LEFT JOIN (select * from snapshot.snap_global_bgwriter_stat where snapshot_id = %ld and snap_node_name = '%s') snap_1 on snap_2.snapshot_id = snap_1.snapshot_id --错误点:snap_2.snapshot_id = snap_1.snapshot_id ? 这其实还是同一个snapshot and snap_2.snap_node_name = snap_1.snap_node_name and snap_2.snap_stats_reset = snap_1.snap_stats_reset limit 200; -- 统计信息应该是2次snapshot之间的数据,而以上SQL并不能正确输出相关数据。个人觉得可以删除LEFT JOIN连接。 -- 建议修改如下: select (snap_2.snap_checkpoints_timed - coalesce(snap_1.snap_checkpoints_timed, 0)) AS "Checkpoints Timed", (snap_2.snap_checkpoints_req - coalesce(snap_1.snap_checkpoints_req, 0)) AS "Checkpoints Require", (snap_2.snap_checkpoint_write_time - coalesce(snap_1.snap_checkpoint_write_time, 0)) AS "Checkpoint Write Time(ms)", (snap_2.snap_checkpoint_sync_time - coalesce(snap_1.snap_checkpoint_sync_time, 0)) AS "Checkpoint Sync Time(ms)", (snap_2.snap_buffers_checkpoint - coalesce(snap_1.snap_buffers_checkpoint, 0)) AS "Buffers Checkpoint", (snap_2.snap_buffers_clean - coalesce(snap_1.snap_buffers_clean, 0)) AS "Buffers Clean", (snap_2.snap_maxwritten_clean - coalesce(snap_1.snap_maxwritten_clean, 0)) AS "Maxwritten Clean", (snap_2.snap_buffers_backend - coalesce(snap_1.snap_buffers_backend, 0)) AS "Buffers Backend", (snap_2.snap_buffers_backend_fsync - coalesce(snap_1.snap_buffers_backend_fsync, 0)) AS "Buffers Backend Fsync", (snap_2.snap_buffers_alloc - coalesce(snap_1.snap_buffers_alloc, 0)) AS "Buffers Alloc", to_char(snap_2.snap_stats_reset, 'YYYY-MM-DD HH24:MI:SS') AS "Stats Reset" from (select * from snapshot.snap_global_bgwriter_stat where snapshot_id = %ld and snap_node_name = '%s') snap_2, (select * from snapshot.snap_global_bgwriter_stat where snapshot_id = %ld and snap_node_name = '%s') snap_1 limit 200;
解读:[本次实验环境是单机,没有复制槽数据]
这一部分描述的是复制槽的相关信息。数据来源于:snapshot.snap_global_replication_slots表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| Slot Name | 复制槽名称 |
| Slot Type | 复制槽类型 |
| DB Name | 数据库名称 |
| Active | 是否为激活状态 |
| Xmin | 事务标识,最早的事务ID(txid) |
| Restart Lsn | 事务槽开始复制时的LSN信息,用来判断哪些事务需要被复制 |
| Dummy Standby | 是否为假备 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT snap_slot_name as "Slot Name", snap_slot_type as "Slot Type", snap_database as "DB Name", snap_active as "Active", snap_x_min as "Xmin", snap_restart_lsn as "Restart Lsn", snap_dummy_standby as "Dummy Standby" FROM snapshot.snap_global_replication_slots WHERE snapshot_id = %ld and snap_node_name = '%s' limit 200;
解读:[本次实验环境是单机,没有复制槽数据]
这一部分描述事务槽详细的状态信息,数据源于snapshot.snap_global_replication_stat表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| Thread Id | 线程ID |
| Usesys Id | 用户OID |
| Usename | 用户名 |
| Application Name | 应用程序名称 |
| Client Addr | 客户端地址 |
| Client Hostname | 客户端主机名 |
| Client Port | 客户端端口 |
| Backend Start | 程序启动时间 |
| State | 日志复制状态【追赶状态/一直的流状态】 |
| Sender Sent Location | 日志发送的位置 |
| Receiver Write Location | 日志接收端write的位置 |
| Receiver Flush Location | 日志接收端flush的位置 |
| Receiver Replay Location | 日志接收端replay的位置 |
| Sync Priority | 同步复制的优先级(0表示异步复制) |
| Sync State | 同步状态【异步复制/同步复制/潜在同步复制】 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT snap_pid as "Thread Id", snap_usesysid as "Usesys Id", snap_usename as "Usename", snap_application_name as "Application Name", snap_client_addr as "Client Addr", snap_client_hostname as "Client Hostname", snap_client_port as "Client Port", snap_backend_start as "Backend Start", snap_state as "State", snap_sender_sent_location as "Sender Sent Location", snap_receiver_write_location as "Receiver Write Location", snap_receiver_flush_location as "Receiver Flush Location", snap_receiver_replay_location as "Receiver Replay Location", snap_sync_priority as "Sync Priority", snap_sync_state as "Sync State" FROM snapshot.snap_global_replication_stat WHERE snapshot_id = %ld and snap_node_name = '%s' limit 200;
解读:
这一部分描述用户表状态的统计信息,数据源于snapshot.snap_global_stat_all_tables表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| DB Name | 数据库名称 |
| Schema | 模式名称 |
| Relname | 表名称 |
| Seq Scan | 顺序扫描的次数 |
| Seq Tup Read | 顺序扫描获取的活跃行数 |
| Index Scan | 索引扫描次数 |
| Index Tup Fetch | 索引扫描获取的活跃行数 |
| Tuple Insert | 插入的行数 |
| Tuple Update | 更新的行数 |
| Tuple Delete | 删除的行数 |
| Tuple Hot Update | HOT(Heap Only Tuple)更新行数备注:HOT更新指,如果更新后的新行和旧行位于同一个数据块内,则旧行会有一个指针指向新行,这样就不用更新索引了,通过索引访问到旧行数据,进而访问到新行数据。 |
| Live Tuple | 活跃行数(估值) |
| Dead Tuple | 死行数(估值) |
| Last Vacuum | 最后一次手动Vacuum的时间(不包含VACUUM FULL) |
| Last Autovacuum | 最后一次autovacuum的时间 |
| Last Analyze | 最后一次手动Analyze表的时间 |
| Last Autoanalyze | 最后一次autovacuum线程Analyze表的时间 |
| Vacuum Count | 手动vacuum的次数(不包含VACUUM FULL) |
| Autovacuum Count | autovacuum的次数 |
| Analyze Count | 手动Analyze的次数 |
| Autoanalyze Count | autovacuum线程Analyze表的次数 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT snap_2.db_name as "DB Name", snap_2.snap_schemaname as "Schema", snap_2.snap_relname as "Relname", (snap_2.snap_seq_scan - coalesce(snap_1.snap_seq_scan, 0)) as "Seq Scan", (snap_2.snap_seq_tup_read - coalesce(snap_1.snap_seq_tup_read, 0)) as "Seq Tup Read", (snap_2.snap_idx_scan - coalesce(snap_1.snap_idx_scan, 0)) as "Index Scan", (snap_2.snap_idx_tup_fetch - coalesce(snap_1.snap_idx_tup_fetch, 0)) as "Index Tup Fetch", (snap_2.snap_n_tup_ins - coalesce(snap_1.snap_n_tup_ins, 0)) as "Tuple Insert", (snap_2.snap_n_tup_upd - coalesce(snap_1.snap_n_tup_upd, 0)) as "Tuple Update", (snap_2.snap_n_tup_del - coalesce(snap_1.snap_n_tup_del, 0)) as "Tuple Delete", (snap_2.snap_n_tup_hot_upd - coalesce(snap_1.snap_n_tup_hot_upd, 0)) as "Tuple Hot Update", snap_2.snap_n_live_tup as "Live Tuple", snap_2.snap_n_dead_tup as "Dead Tuple", to_char(snap_2.snap_last_vacuum, 'YYYY-MM-DD HH24:MI:SS') as "Last Vacuum", to_char(snap_2.snap_last_autovacuum, 'YYYY-MM-DD HH24:MI:SS') as "Last Autovacuum", to_char(snap_2.snap_last_analyze, 'YYYY-MM-DD HH24:MI:SS') as "Last Analyze", to_char(snap_2.snap_last_autoanalyze, 'YYYY-MM-DD HH24:MI:SS') as "Last Autoanalyze", (snap_2.snap_vacuum_count - coalesce(snap_1.snap_vacuum_count, 0)) as "Vacuum Count", (snap_2.snap_autovacuum_count - coalesce(snap_1.snap_autovacuum_count, 0)) as "Autovacuum Count", (snap_2.snap_analyze_count - coalesce(snap_1.snap_analyze_count, 0)) as "Analyze Count", (snap_2.snap_autoanalyze_count - coalesce(snap_1.snap_autoanalyze_count, 0)) as "Autoanalyze Count" FROM (SELECT * FROM snapshot.snap_global_stat_all_tables WHERE snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') AND snap_schemaname !~ '^pg_toast') snap_2 LEFT JOIN (SELECT * FROM snapshot.snap_global_stat_all_tables WHERE snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') AND snap_schemaname !~ '^pg_toast') snap_1 ON snap_2.snap_relid = snap_1.snap_relid AND snap_2.snap_schemaname = snap_1.snap_schemaname AND snap_2.snap_relname = snap_1.snap_relname AND snap_2.db_name = snap_1.db_name order by snap_2.db_name, snap_2.snap_schemaname limit 200;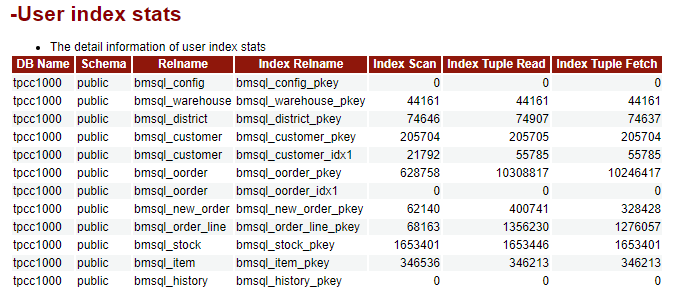
解读:
这一部分描述用户索引状态的统计信息,数据源于snapshot.snap_global_stat_all_indexes表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| DB Name | 数据库名称 |
| Schema | 模式名称 |
| Relname | 表名称 |
| Index Relname | 索引名称 |
| Index Scan | 索引扫描次数 |
| Index Tuple Read | 索引扫描返回的索引条目数 |
| Index Tuple Fetch | 索引扫描获取的活跃行数 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT snap_2.db_name as "DB Name", snap_2.snap_schemaname as "Schema", snap_2.snap_relname as "Relname", snap_2.snap_indexrelname as "Index Relname", (snap_2.snap_idx_scan - coalesce(snap_1.snap_idx_scan, 0)) as "Index Scan", (snap_2.snap_idx_tup_read - coalesce(snap_1.snap_idx_tup_read, 0)) as "Index Tuple Read", (snap_2.snap_idx_tup_fetch - coalesce(snap_1.snap_idx_tup_fetch, 0)) as "Index Tuple Fetch" FROM (SELECT * FROM snapshot.snap_global_stat_all_indexes WHERE snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') snap_2 LEFT JOIN (SELECT * FROM snapshot.snap_global_stat_all_indexes WHERE snapshot_id = %ld and snap_node_name = '%s' and snap_schemaname NOT IN ('pg_catalog', 'information_schema', 'snapshot') and snap_schemaname !~ '^pg_toast') snap_1 ON snap_2.snap_relid = snap_1.snap_relid and snap_2.snap_indexrelid = snap_1.snap_indexrelid and snap_2.snap_schemaname = snap_1.snap_schemaname and snap_2.snap_relname = snap_1.snap_relname and snap_2.snap_indexrelname = snap_1.snap_indexrelname and snap_2.db_name = snap_1.db_name order by snap_2.db_name, snap_2.snap_schemaname limit 200;
解读:
这一部分描述坏块的统计信息,数据源于snapshot.snap_global_stat_bad_block表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| DB Id | 数据库OID |
| Tablespace Id | 表空间OID |
| Relfilenode | relation的filenode号 |
| Fork Number | fork编号 |
| Error Count | error数量 |
| First Time | 坏块第一次出现的时间 |
| Last Time | 坏块最近一次出现的时间 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id SELECT snap_2.snap_databaseid AS "DB Id", snap_2.snap_tablespaceid AS "Tablespace Id", snap_2.snap_relfilenode AS "Relfilenode", snap_2.snap_forknum AS "Fork Number", (snap_2.snap_error_count - coalesce(snap_1.snap_error_count, 0)) AS "Error Count", snap_2.snap_first_time AS "First Time", snap_2.snap_last_time AS "Last Time" FROM (SELECT * FROM snapshot.snap_global_stat_bad_block WHERE snapshot_id = %ld and snap_node_name = '%s') snap_2 LEFT JOIN (SELECT * FROM snapshot.snap_global_stat_bad_block WHERE snapshot_id = %ld and snap_node_name = '%s') snap_1 ON snap_2.snap_databaseid = snap_1.snap_databaseid and snap_2.snap_tablespaceid = snap_1.snap_tablespaceid and snap_2.snap_relfilenode = snap_1.snap_relfilenode limit 200;
解读:
这一部分描述的是数据库参数配置信息,数据源于snapshot.snap_global_config_settings表。
信息内容如下所示:
| 列名 | 描述 |
|---|---|
| Name | 参数名称 |
| Abstract | 参数的简单描述 |
| Type | 参数类型(bool/enum/integer/real/string) |
| Curent Value | 参数当前值 |
| Min Value | 最小参数值 |
| Max Value | 最大参数值 |
| Category | 参数逻辑组 |
| Enum Values | 参数枚举值 |
| Default Value | 启动时的默认参数值 |
| Reset Value | 重置时的默认参数值 |
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select snap_name as "Name", snap_short_desc as "Abstract", snap_vartype as "Type", snap_setting as "Curent Value", snap_min_val as "Min Value", snap_max_val as "Max Value", snap_category as "Category", snap_enumvals as "Enum Values", snap_boot_val as "Default Value", snap_reset_val as "Reset Value" FROM snapshot.snap_global_config_settings WHERE snapshot_id = %ld and snap_node_name = '%s';
解读:
这一部分描述的是SQL语句的详细信息,数据来源于snapshot.snap_summary_statement表。
Unique SQL Id: 即SQL的唯一识别ID
SQL Text: 即SQL的具体内容。
相关代码:
-- 说明:%s代表node_name,%ld代表snapshot_id select (t2.snap_unique_sql_id) as "Unique SQL Id", (t2.snap_query) as "SQL Text" from snapshot.snap_summary_statement t2 where snapshot_id = %ld and snap_node_name = '%s';小结:
关于openGauss WDR报告的梳理和解读就到这里,这些内容对于刚刚接触openGauss的老DBA已经足够了,只要读懂WDR报告的数据计算方法和含义即意味着看懂了这份WDR报告内容,剩下的数据库优化工作完全可以参照已有的数据库优化经验操作。当然了,“小白”DBA也完全可以参照网络上大佬们分享的数据库优化案例以及类似Oracle等主流数据库的AWR报告解读,学习openGauss的WDR报告,从而执行openGauss数据库相关的优化工作

