

大数据生产环境 sqoop datax
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法————数据同步工具就应运而生了。此次我们选择两款生产环境常用的数据同步工具进行讨论
Sqoop
通常数据开发岗位的朋友都会较早的接触这款工具,因为Sqoop的设计初衷就是在Hadoop和DB(关系型数据库)、大型机(Oracle服务机)之间搭建桥梁,斩断数据同步的隔阂。该项目起步于2009年,最早是Hadoop的一个三方模块的存在,后来社区开发者为了能够快速部署和使用,同时也为了开发人员能够更快速的迭代开发,最终成为Apache基金会的顶级项目。
核心机制
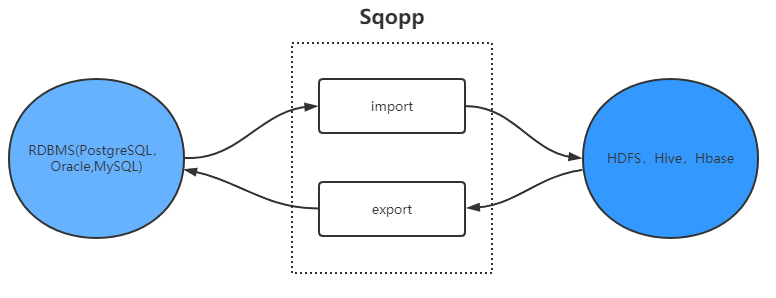
Sqoop是基于MR的分布式数据同步工具,使用MR完成数据的导入和导出,依赖计算框架的能力,可以实现并行操作以及容错能力
-
导入
在读取数据库文件时,sqoop底层逐行读取,导入过程的输出是一组文件,其中包含导入的表或数据集副本,因为
底层使用的是MR并行处理,所以这一过程会产生多个文件(序列化二进制文件或逗号分割的文本文件)。导入的过程
由JAVA类控制,此类可将数据与序列化文件进行序列化和反序列化。同时开放的接口可以使用其他工具解析分隔记录
数据。 -
导出
当MR或Hive生成的查询处理结果生成结果集时,可以使用其导入关系型数据库。Sqoop将HDFS文件并行读取一组文本文件,将它们解析记录,并将它们插入到数据库表中作为新行,供外部程序或用户进行查询。
特点
- 分布式可水平扩展
- 运行模式基于MR
- 依赖hadoop生态圈,某些业务场景下限制多
- 负载默认均匀分布,若不人为修改,某些状况下会导致负载倾斜
- 对压缩文件支持不友好
- 启动速度相对较慢
DataX
DataX是阿里开源的一个异构数据源离线同步工具,用于在关系型数据库、HDFS、Hive、ODPS(阿里云组件)、HBase、DRDS、ADS、TableStore(OTS)、FTP等各种异构数据源之间做稳定高效的数据同步。从官方给出的定义不难看出这一数据同步框架面向更多数据场景,目前离线同步数据源已支持DB2、Kafka等工具。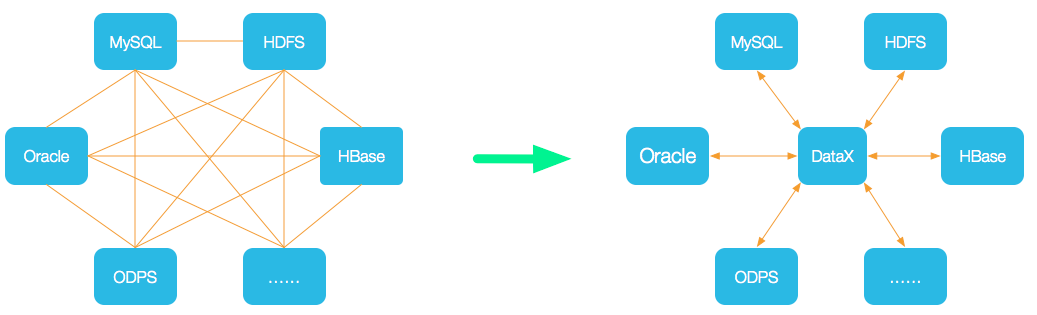
由上图可知,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
框架设计

DataX在设计之初就将同步理念抽象成框架+插件的形式.框架负责内部的序列化传输,缓冲,并发,转换等而核心技术问题,数据的采集(Reader)和落地(Writer)完全交给插件执行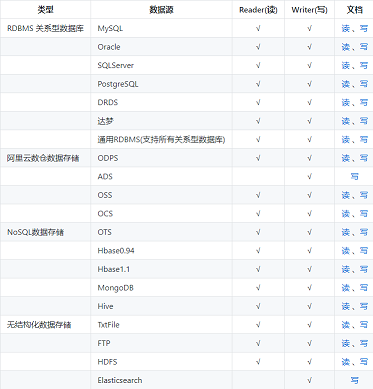
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。经过不停的迭代,当前DataX已经有了比较全面的插件体系,包括主流的RDBMS,NOSQL以及大数据计算系统
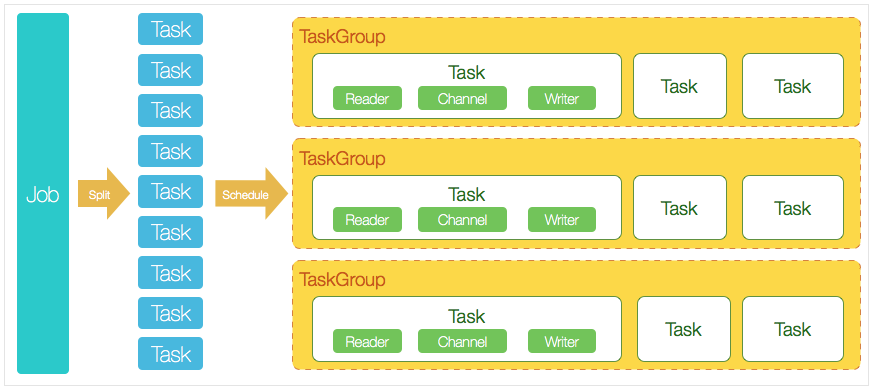
核心模块介绍:
1.DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
2.DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3.切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4.每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5.DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非
特点
- 单线程多进程,不支持分布式
- 数据转换功能丰富,可在传输过程中脱敏、过滤
- 传输速度可控,具备信息统计功能
- 可以进行数据校验
总结
对比两者的特点,不难发现Sqoop依赖于Hadoop生态对HDFS、Hive支持友善,在处理数仓大表的速度相对较快,但不具备统计和校验能力。而DataX无法分布式部署,可以在传输过程中进行过滤,并且可以统计传输数据的信息,因此在业务场景复杂(表结构变更)更适用,同时对于不同的数据源支持更好。且DataX的开源版本目前只支持单机部署,需要依赖调度系统实现多客户端,同时不支持自动创建表和分区。

