警惕Oracle数据库性能“隐形杀手”
警惕Oracle数据库性能“隐形杀手”
先通报一下上海站的培训情况(培训详情请见:<老虎刘oracle性能优化上海站培训开始接受报名>):
培训时间:
10.19~10.20 (周末两天)
培训地点:
上海市临汾路818号4楼(已确定)
目前还有10多个名额,离培训只有一周的时间,机会不容错过。
下一站培训地点目前仍未确定,目前已经创建的报名意向群有成都、杭州、深圳、武汉、东北(大连或沈阳),到达一定人数后开启正式报名(入群只是意向不代表正式报名),报名人数够20即可开班。有意向的朋友可以加微信 ora_service ,备注培训意向及所在城市
正文开始
Oracle 的11g版本正式发布到今天已经10年有余,最新版本也已经到了20c,但是Direct Path Read(直接路径读)导致性能问题的案例仍时有发生,很多12c的用户还是经常遇到这个问题,所以有必要把这个事情再跟大家讲一遍,通过2个典型案例加深理解。
早在2012年,盖国强大师就撰写文章,介绍了direct path read这个11g版本推出的新特性:
https://www.eygle.com/archives/2012/05/oracle_11g_direct_path_read.html ;也有人把关闭这个功能作为“最佳实践”,我建议先多了解一些具体情况再决定。
Direct path read的目的是让一些不常使用的大表数据(冷数据),在全表扫描时,每次都从磁盘读到用户的私有内存(PGA),而不要去挤占有限的、宝贵的、频繁使用的数据(热数据)所在的共享内存(SGA-bufer cache)。
热数据只在第一次访问时从磁盘读,读到SGA的buffer cache后,再次访问会直接从内存读,效率高、对存储压力小。
试想一个表被频繁全表扫描访问(缺少索引或业务设计不合理),一开始表还不算太大,会放到共享内存,只需要少量的磁盘读,这时对存储压力不大;随着记录数的不断增加,达到了一个参数设置的阀值和条件后,就会使用direct path read,频繁的磁盘读就会造成存储的巨大压力,出现严重的性能问题。
从共享内存读到直接路径读,这个变化在不频繁的全表扫描时是起到积极作用的;如果业务不合理(一个大表正常情况不会有频繁的全表扫描)、或者缺少索引(这个是比较多的情况),频繁的大表全表扫描就会在某个触发点上对数据库性能做出致命一击,导致业务瘫痪。
两个典型案例:
案例1:
某银行业务数据库A夜间跑批业务突然变慢,查了很长时间,对top sql也做了“优化”(清除历史数据,虽然是比较初级优化手段,但是也最有效,如果数据需要保留就不行),仍未解决。
因为是5~6套数据库共享一套存储,而且表现在存储响应时间慢,开始对其他几套库进行排查,发现其中一套数据库B在这段时间内IO消耗突增。
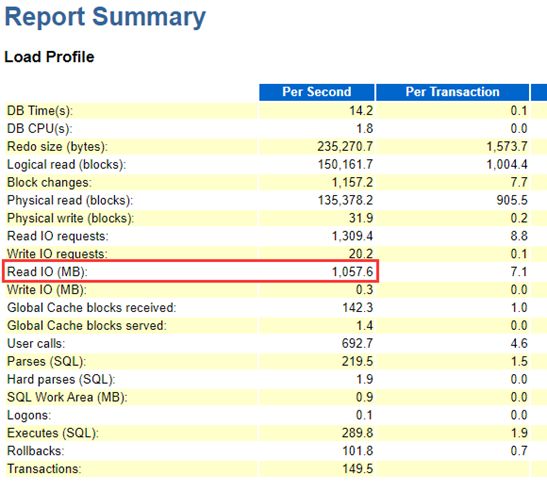
故障时段AWR报告显示如下:
Load Profile:
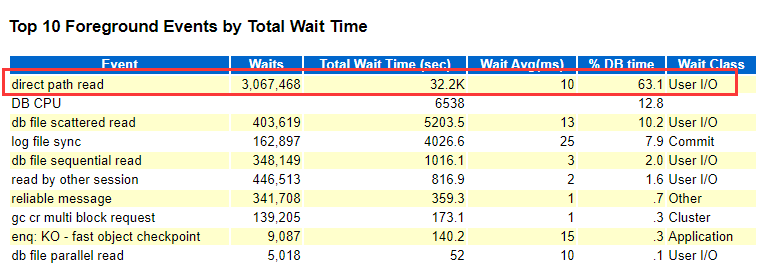
Top events:
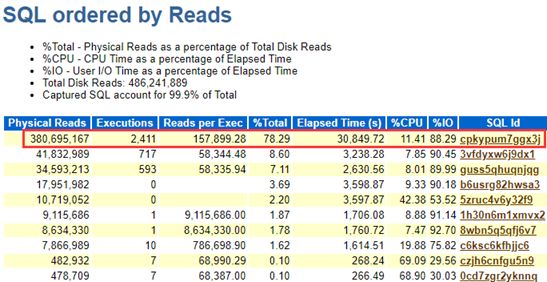
Top Read SQL:
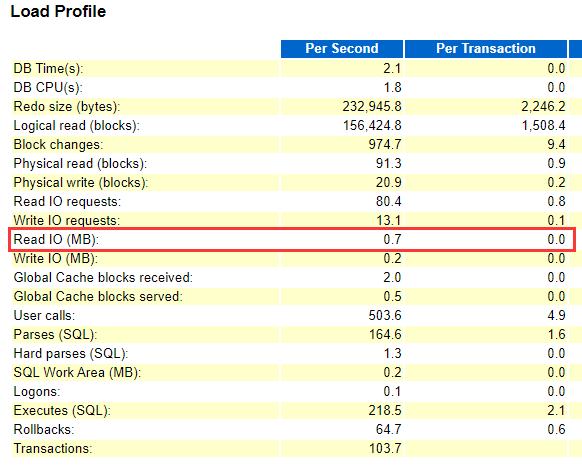
数据库B之前正常时段AWR 情况:
(awr对比是分析系统性能问题的一个重要手段,建议定期保存awr基线)
Load Profile(Read IO相差1000多倍 1057.6M vs 0.7M):
Top events:direct path read只占 DB time 的0.1% (故障时段63.1%):
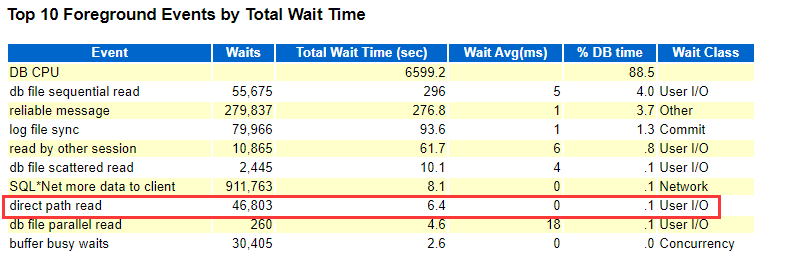
Top Read SQL:消耗较少物理读
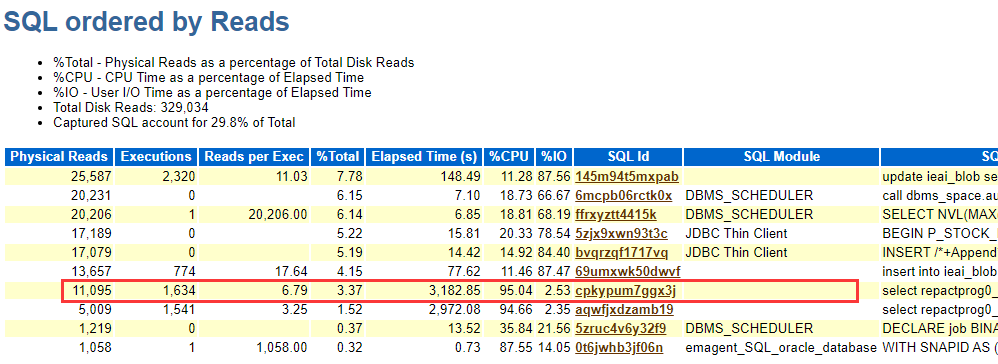
通过对比发现是一个SQL的物理读突增导致存储整体下降,影响到存储上的其他数据库。
对该TOP SQL分析发现,sql执行频繁,执行计划没有改变(下图红框内第一列,一直是全表扫描),但是某天夜间突然Disk Reads次数(下图中间部分)暴增,这个时间正是数据库A跑批业务出问题的时间段,下面是sqlhc收集到的sql执行历史信息:

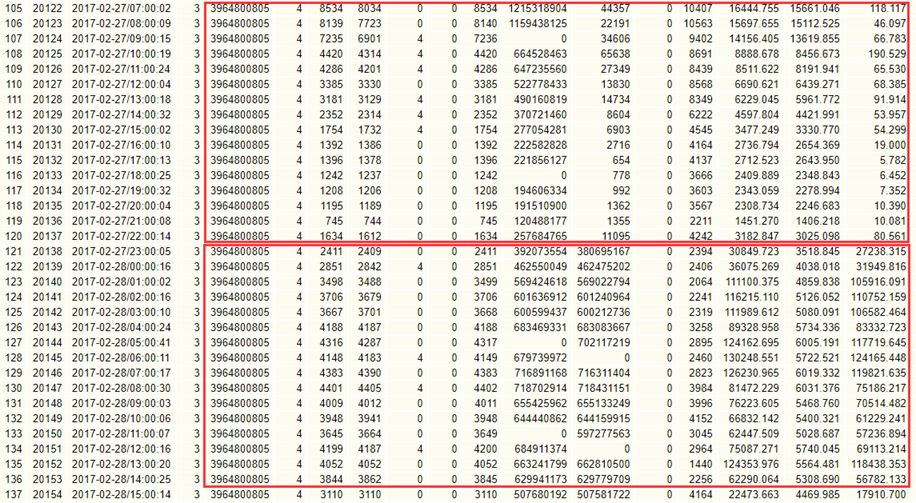
该SQL逻辑比较简单,2个谓词条件的单表查询,只需要创建一个简单索引,即可避免全表扫描。创建索引后,一切恢复正常。
根因分析:
出现问题如果不把导致问题的根本原因找到,那么很有可能下次还会再发生。根因分析需要有一定深度的技术水平才能做到,很多时候故障只是临时解决,根因未找到前还会不断发生。
有个隐含参数_serial_direct_read,决定dirrect path read的使用方式,默认是auto(共有false, true, never, auto, always几个选项),auto方式下有下面几个已知触发条件:
-
表大小超过 _small_table_threshold 隐含参数设置的阀值
-
表在buffer cache块数低于50%
-
表脏块数低于的25%
上面几个条件,只要有一个不满足,都不会使用Direct path read。频繁使用的大表,达到_small_table_threshold 阀值后,因为仍有大量数据在buffer cache,不会立即触发Direct path read,但是如果遇到其他大表挤占了buffer cache,buffer cache块数低于50%,就满足了触发条件。
(注:另外还有一个参数_very_large_object_threshold,默认值500,即表大小超过5倍_db_block_buffers时,也会选择direct path read,这里不多解释)
上面SQL的触发时间点是统计信息收集时段,表数据块在buffer cache的量减少,触发了Direct path read后,就很难再回到从前了。除非对表“瘦身”,简单的delete还不行,必须是高水位的降低(truncate或delete +shrink)。文章最后有改参数的方法。
案例2:
这是一个来自网上的案例,某业务系统数据库升级,重启后IO负载超高(注意:重启不一定包治百病,也有时可能让你病重),分析AWR发现是某个表频繁的全表扫描导致,用户将表历史数据归档临时解决这个问题。
案例分析与点评:
文章作者当时并没有意识到这就是一个典型的direct path read导致的问题。数据库重启前,数据量逐渐增长,虽然到了Direct path read的阀值,但是大量数据仍在数据库缓存(buffer cache),没有触发;数据库重启,数据库缓存被清空,触发了direct path read,导致了故障的发生。没有把这个根本原因找到,以后其他表还是有可能遇到相同的问题。
如何判断direct path read导致的性能问题:
如果数据库变慢,IO吞吐量突然急剧增长(存储或OS监控发现),十有八九可能遇到了direct path read的问题。
通过AWR进行确认:
生成AWR报告(单个AWR有时看起来不太明显,可以使用本人改写的ora工具,用ora load命令查看最近一段时间全部snap的系统负载情况列表,很容易发现数据突然变大。该命令实际上就是一段查dba_his相关视图的sql,比较简单,方便快速排障),参考案例一提供的相关指标,可以轻松判断:
如果AWR报告显示每秒的Read IO非常高,而且Top Event里面的Direct path read等待事件占DB time比例较高,就可以断定发生了Direct Path Read问题(注:这个判断一般是针对OLTP系统,OLAP里面direct path read高,很可能是正常的)
总结与建议:
通过上面介绍,我们了解到Direct path read这个功能的设计初衷是为了提高数据库的整体性能。但是如果不合理的使用(频繁访问的表没有索引,或是业务不合理,表逐渐增大,突然爆发),就非常有可能遇到严重的性能问题。怎么办?
建议:
oracle每次升级新版本都会带来一些性能上的改进,如果用的不好,反而会带来负面影响,成为数据库性能“杀手”。
如果能定期分析AWR,提前发现Top SQL存在的隐患,Direct path Read这个功能还是有必要保留的,前提是需要对数据库做精细化的管理,可以把“杀手”变成帮手。
但是目前绝大多数数据库维护现状是不如人意的,这种情况还是建议把这个参数关闭:
alter system set "_serial_direct_read"=never;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号