
RAC中的gc current block busy与redo log flush
这篇博文整理自我的帖子: RAC中的gc current block busy与redo log flush
对于log file sync(本质上是 write redolog慢)引发gc buffer busy acquire /release 集群等待事件的这个命题的真伪,其实Oracle在开发性能调优组件ADDM时一早给了我们答案:
RECOMMENDATION 2: Host Configuration, 12% benefit (507182 seconds)
ACTION: Investigate the possibility of improving the performance of I/O
to the online redo log files.
RATIONALE: The average size of writes to the online redo log files was
40 K and the average time per write was 10 milliseconds.
ADDITIONAL INFORMATION:
Waits on event “log file sync” were the cause of significant database
wait on “gc buffer busy” when releasing a data block. Waits on event
“log file sync” in this instance can cause global cache contention on
remote instances.
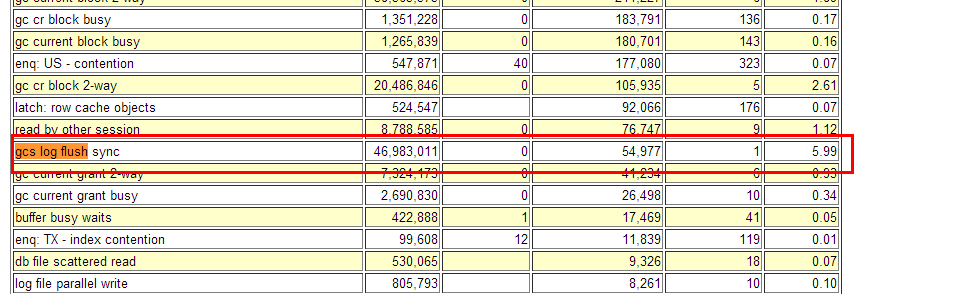
如果你在ADDM(?/rdbms/admin/addmrpt)中找到上述文字,那么基本可以确认gc buffer busy的源头是log file sync(虽然本质上不是),那么优先解决log file sync的问题; log file sync 当然有少数的bug存在,但更多的是存储、板卡、链路等硬件因素造成的。解决了log file sync后,那么gc buffer busy往往也就解决了。
gc current block busy 等待是RAC中global cache全局缓存当前块的争用等待事件, 该等待事件时长由三个部分组成:
Time to process current block request in the cache= (pin time + flush time + send time)
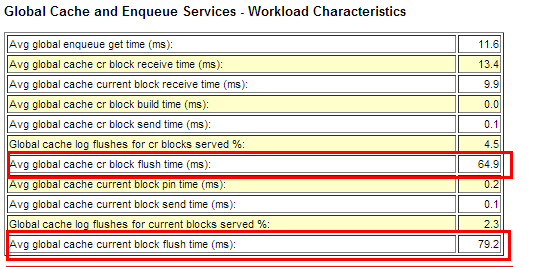
gc current block flush time
The current block flush time is part of the service (or processing) time for a current block. The pending redo needs to be flushed to the log file by LGWR before LMS sends it. The operation is asynchronous in that LMS queues the request, posts LGWR, and continues processing. The LMS would check its log flush queue for completions and then send the block, or go to sleep and be posted by LGWR. The redo log write time and redo log sync time can influence the overall service time significantly.
flush time 是Oracle为了保证Instance Recovery实例恢复机制,而要求每一个current block在本地节点local instance被修改后(modify/update) 必须要将该current block相关的redo 写入到logfile 后(要求LGWR必须完成写入后才能返回),才能由LMS进程传输给其他节点使用。
而gc buffer busy acquire/release 往往是 gc current block busy的衍生产品, 当同一实例内的 多个进程并发地访问同一个数据块时 , 首先发起的进程 将进入 gc current block busy的等待 ,而在 buffer waiter list 上的后续进程 会陷入gc buffer busy acquire/release 等待(A user on the same instance has started a remote operation on the same resource and the request has not completed yet or the block was requested by another node and the block has not been released by the local instance when the new local access was made), 这里存在一个排队效应, 即 gc current block busy是缓慢的,那么在 排队的gc buffer busy acquire/release就会更慢:
Pin time = (time to read the block into cache) + (time to modify/process the buffer)
Busy time = (average pin time) * (number of interested users waiting ahead of me)
不局限于current block (reference AWR Avg global cache current block flush time (ms)), cr block(Avg global cache cr block flush time (ms)) 也存在flush time。
可以通过 设置_cr_server_log_flush to false(LMS are/is waiting for LGWR to flush the pending redo during CR fabrication. Without going too much in to details, you can turn off the behaviour by setting _cr_server_log_flush to false.) 来禁止cr server flush redo log,_gc_log_flush(if TRUE, flush redo log before a current block transfer)来让current block transfer不用flush redo。 但是上述2个参数是有其副作用的……….. 大多数情况不要考虑去设置它们,用它们是个馊主意。
_gc_split_flush if TRUE, flush index split redo before rejecting bast FALSE ==> 控制index split redo flush,默认为FALSE
以上告诉我们 IO 在RAC中是十分重要的,特别是log file的write性能, 其重要性不亚于CPU 和 Interconnect network。


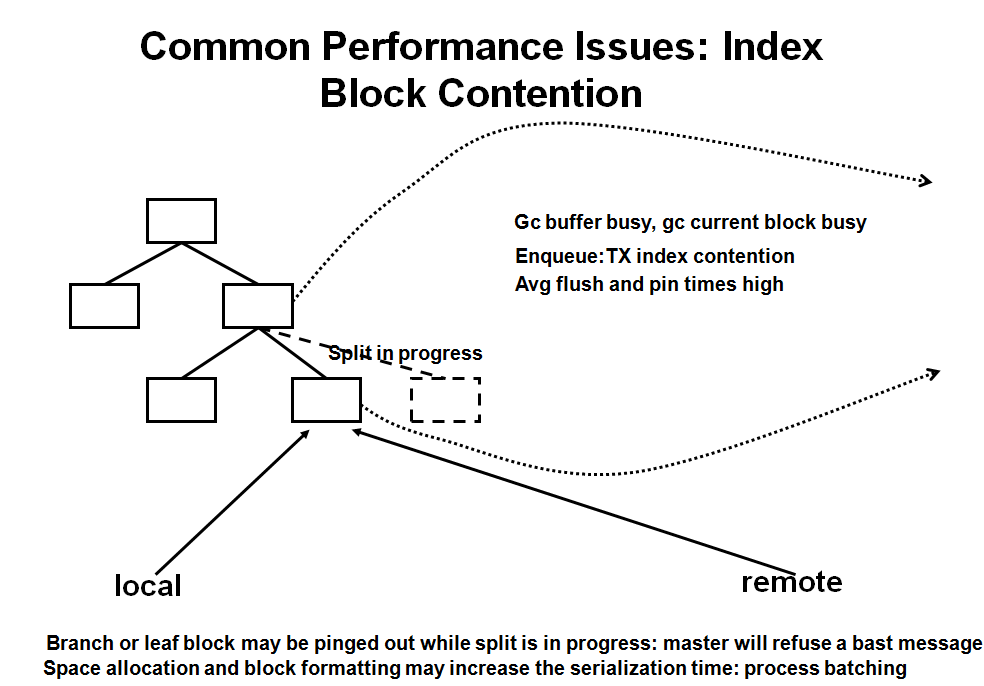
Log file sync delays due to slow log IO can impact the block shipping
LGWR does not post LMS when the redo is on disk
Can be considered and indicator of contention for “hot” blocks between instance competing for write or read-after-write access

 浙公网安备 33010602011771号
浙公网安备 33010602011771号