
CAP理论-简单理解
此篇文章转载(此篇文章非博主编写,文章内容不错特此转发)
原文地址:https://baijiahao.baidu.com/s?id=1650890231453975345&wfr=spider&for=pc
对于刚刚接触分布式系统的小伙伴们来说,一提起分布式系统,就感觉高大上,深不可测。而且看了很多书和视频还是一脸懵逼。这篇文章主要使用大白话的方式,带你理解一下分布式系统中的CAP理论。保证你能听懂。
为了防止被误以为是洗文的嫌疑,我在这里先说明一下:我参考了知乎和博客园上等相关文章,还有下面的图不是我自己画的,我觉得能清晰地表达出意思就是好图,在百度图片上下载了一波。
一、什么是分布式系统
拿一个最简单的例子,就比如说我们的图书管理系统。之前的系统包含了所有的功能,比如用户注册登录、管理员功能、图书借阅管理等。这叫做集中式系统。也就是一个人干了好几件事。
后来随着功能的增多,用户量也越来越大。集中式系统维护太麻烦,拓展性也不好。于是就考虑着把这些功能分开。通俗的理解就是原本需要一个人干的事,现在分给n个人干,各自干各自的,最终取得和一个人干的效果一样。
稍微正规一点的定义就是:一个业务分拆多个子业务,部署在不同的服务器上。 然后通过一定的通信协议,能够让这些子业务之间相互通信。
既然分给了n个人,那就涉及到这些人的沟通交流协作问题。想要去解决这些问题,就需要先聊聊分布式系统中的CAP理论。千万不要被这个看起来高大上的概念迷惑住。
二、简单的概述一下
CAP理论指的是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。拿一个网上的图来看看。
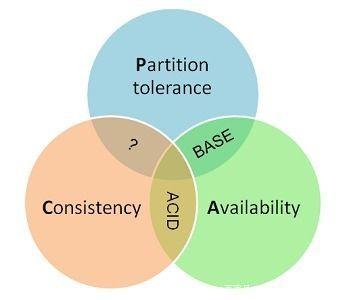
这张图不知道你之前看到过没,如果你看过书或者是视频,这张图应该被列举了好几遍了。下面我不准备直接上来就对每一个特性进行概述。我们先从案例出发逐步过渡。
1、一个小例子
首先我们看一张图。
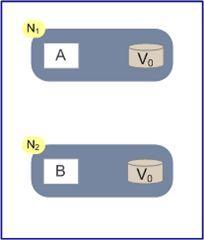
现在网络中有两个节点N1和N2,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的两个子数据库。
现在问题来了。突然有两个用户小明和小华分别同时访问了N1和N2。我们理想中的操作是下面这样的。
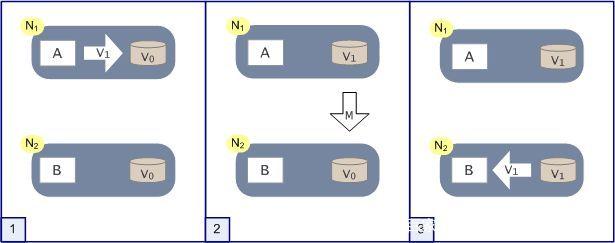
(1)小明访问N1节点,小华访问N2节点。同时访问的。
(2)小明把N1节点的数据V0变成了V1。
(2)N1节点一看自己的数据有变化,立马执行M操作,告诉了N2节点。
(4)小华读取到的就是最新的数据。也是正确的数据。
上面这是一种最理想的情景。它满足了CAP理论的三个特性。现在我们看看如何来理解满足的这三个特性。
2、Consistency 一致性
一致性指的是所有节点在同一时间的数据完全一致。就好比刚刚举得例子中,小明和小华读取的都是正确的数据,对他们用户来说,就好像是操作了同一个数据库的同一个数据一样。
因此对于一致性,也可以分为从客户端和服务端两个不同的视角来理解。
(1)客户端
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。也就是小明和小华同时访问,如何获取更新的最新的数据。
(2)服务端
从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。也就是N1节点和N2节点如何通信保持数据的一致。
对于一致性,一致的程度不同大体可以分为强、弱、最终一致性三类。
(1)强一致性
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。比如小明更新V0到V1,那么小华读取的时候也应该是V1。
(2)弱一致性
如果能容忍后续的部分或者全部访问不到,则是弱一致性。比如小明更新VO到V1,可以容忍那么小华读取的时候是V0。
(3)最终一致性
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。比如小明更新VO到V1,可以使得小华在一段时间之后读取的时候是V0。
3、可用性
可用性指服务一直可用,而且是正常响应时间。就好比刚刚的N1和N2节点,不管什么时候访问,都可以正常的获取数据值。而不会出现问题。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
对于可用性来说就比较好理解了。
4、分区容错性
分区容错性指在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。就好比是N1节点和N2节点出现故障,但是依然可以很好地对外提供服务。
这个分区容错性也是很好理解。
在经过上面的分析中,在理想情况下,没有出现任何错误的时候,这三条应该都是满足的。但是天有不测风云。系统总是会出现各种各样的问题。下面来分析一下为什么说CAP理论只能满足两条。
三、验证CAP理论
既然系统总是会有错误,那我们就来看看可能会出现什么错误。
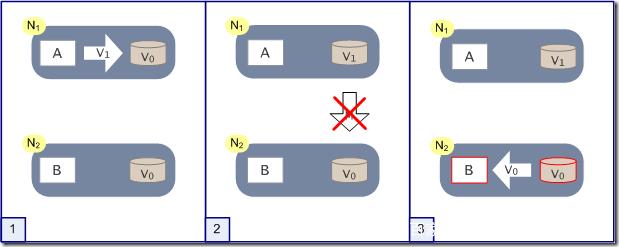
N1节点更新了V0到V1,想在也想把这个消息通过M操作告诉N1节点,却发生了网络故障。这时候小明和小华都要同时访问这个数据,怎么办呢?现在我们依然想要我们的系统具有CAP三个特性,我们分析一下会发生什么。
(1)系统网络发生了故障,但是系统依然可以访问,因此具有容错性。
(2)小明在访问节点N1的时候更改了V0到V1,想要小华访问节点N2的V数据库的时候是V1,因此需要等网络故障恢复,将N2节点的数据库进行更新才可以。
(3)在网络故障恢复的这段时间内,想要系统满足可用性,是不可能的。因为可用性要求随时随地访问系统都是正确有效的。这就出现了矛盾。
正是这个矛盾所以CAP三个特性肯定不能同时满足。既然不能满足,那我们就进行取舍。
有两种选择:
(1)牺牲数据一致性,也就是小明看到的衣服数量是10,买了一件应该是9了。但是小华看到的依然是10。
(2)牺牲可用性,也就是小明看到的衣服数量是10,买了一件应该是9了。但是小华想要获取的最新的数据的话,那就一直等待阻塞,一直到网络故障恢复。
现在你可以看到了CAP三个特性肯定是不能同时满足的,但是可以满足其中两个。
三、CAP特性的取舍
我们分析一下既然可以满足两个,那么舍弃哪一个比较好呢?
(1)满足CA舍弃P,也就是满足一致性和可用性,舍弃容错性。但是这也就意味着你的系统不是分布式的了,因为涉及分布式的想法就是把功能分开,部署到不同的机器上。
(2)满足CP舍弃A,也就是满足一致性和容错性,舍弃可用性。如果你的系统允许有段时间的访问失效等问题,这个是可以满足的。就好比多个人并发买票,后台网络出现故障,你买的时候系统就崩溃了。
(3)满足AP舍弃C,也就是满足可用性和容错性,舍弃一致性。这也就是意味着你的系统在并发访问的时候可能会出现数据不一致的情况。
实时证明,大多数都是牺牲了一致性。像12306还有淘宝网,就好比是你买火车票,本来你看到的是还有一张票,其实在这个时刻已经被买走了,你填好了信息准备买的时候发现系统提示你没票了。这就是牺牲了一致性。
但是不是说牺牲一致性一定是最好的。就好比mysql中的事务机制,张三给李四转了100块钱,这时候必须保证张三的账户上少了100,李四的账户多了100。因此需要数据的一致性,而且什么时候转钱都可以,也需要可用性。但是可以转钱失败是可以允许的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号