


ORACLE的DDL日志 推送到Kafka,并用Flink进行实时计算
ORACLE的DDL日志 推送到Kafka,并用Flink进行实时统计
本次测试的环境:
环境:docker oracle12c
日志模式:归档日志模式 archivelog
用户:scott/tiger 具有dba权限
大数据组件:kafka(默认创建好topic:flink_topic),zookeeper
额外组件:kafka-connect-oracle-1.0.jar
下载地址: https://github.com/erdemcer/kafka-connect-oracle
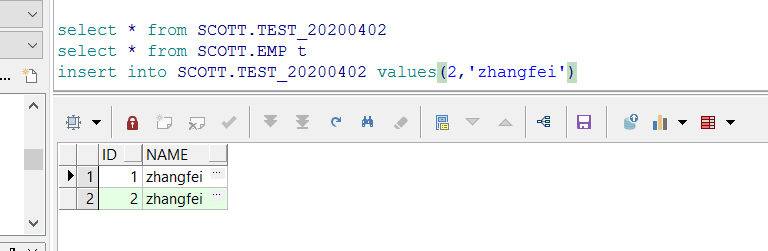
1. 创建测试表,并插入几条记录
2.开启归档日志模式
sqlplus / as sysdba SQL> shutdown immediate SQL> startup mount SQL> alter database archivelog; SQL> alter database open; SQL> alter database add supplemental log data (all) columns; SQL> conn username/password
3.准备相关Jar包
1. 从https://github.com/erdemcer/kafka-connect-oracle下载整个项目,把整个项目mvn clean package成kafa-connect-oracle-1.0.jar 2. 下载一个oracle的jdbc驱动jar—ojdbc7.jar 3. 将kafa-connect-oracle-1.0.jar and ojdbc7.jar放在kafka的安装包下的lib目录下 4. 将github项目里面的config/OracleSourceConnector.properties文件拷贝到kafak/config
4. 配置相关文件
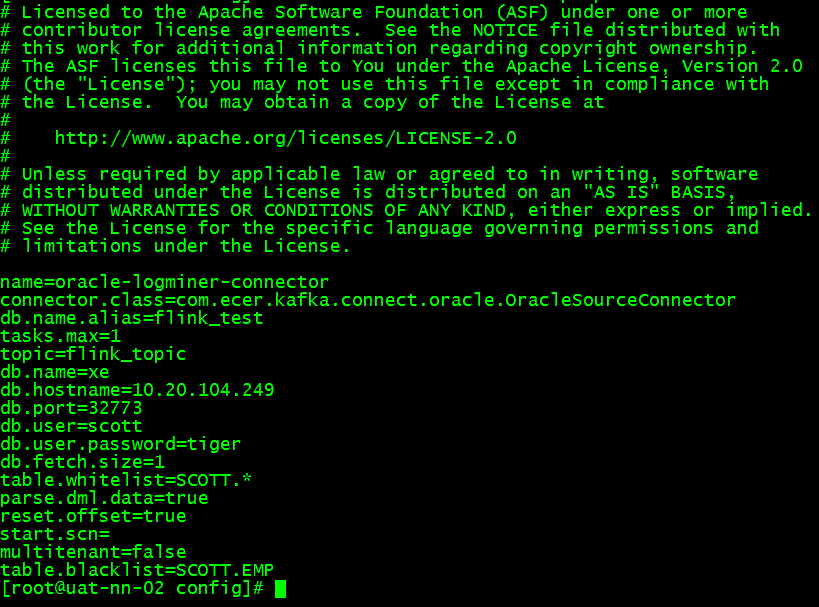
# vi /opt/cloudera/parcels/KAFKA/lib/kafka/config/OracleSourceConnector.properties
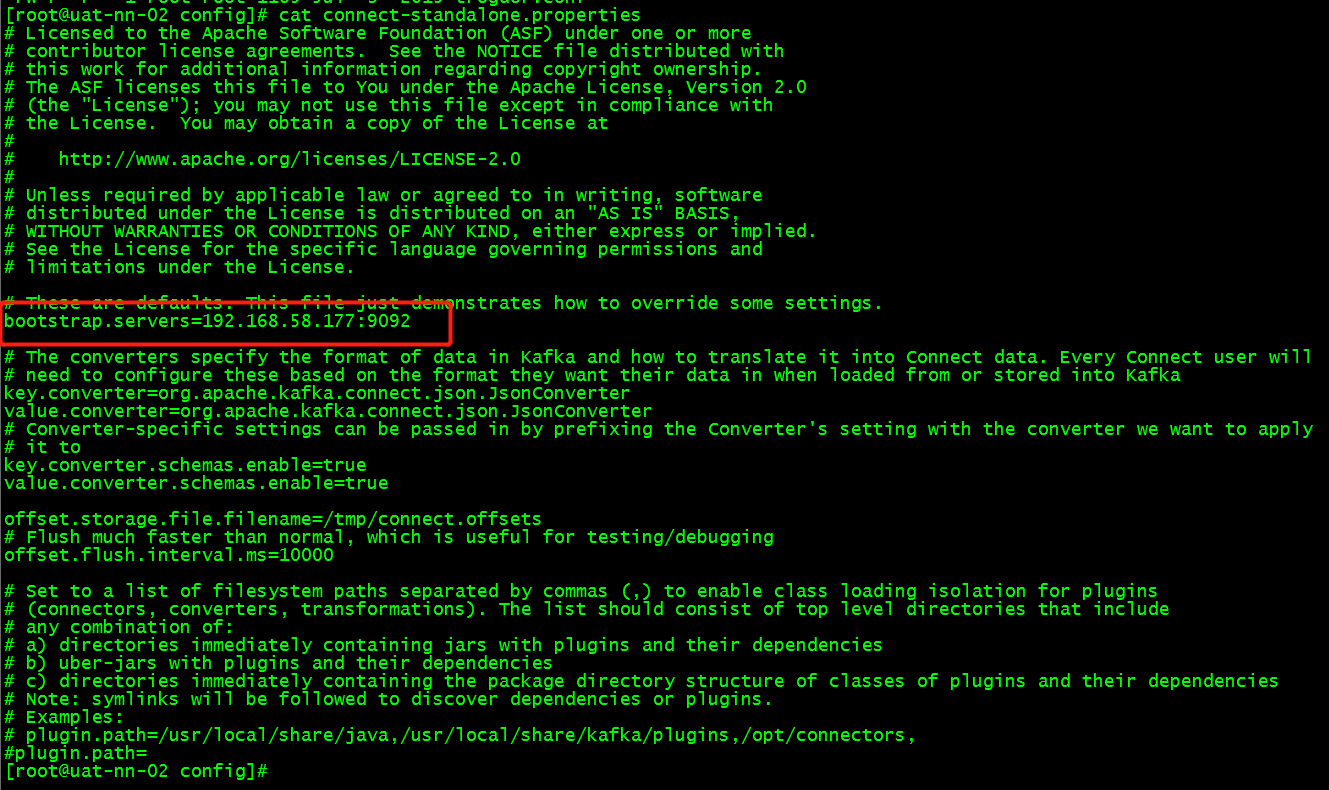
# vi /opt/cloudera/parcels/KAFKA/lib/kafka/config/connect-standalone.properties
5. 运行启动Connector
bin/connect-standalone.sh config/connect-standalone.properties config/OracleSourceConnector.properties
6. 启动consumer
bin/kafka-console-consumer.sh --bootstrap-server 192.168.58.177:9092 --from-beginning --topic flink_topic
7. 最后结果

{"schema":{"type":"struct","fields":
[
{"type":"int64","optional":false,"field":"SCN"},
{"type":"string","optional":false,"field":"SEG_OWNER"},
{"type":"string","optional":false,"field":"TABLE_NAME"},
{"type":"int64","optional":false,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"TIMESTAMP"},
{"type":"string","optional":false,"field":"SQL_REDO"},
{"type":"string","optional":false,"field":"OPERATION"},
{"type":"struct","fields":
[
{"type":"double","optional":true,"field":"ID"},
{"type":"string","optional":true,"field":"NAME"}
],"optional":true,"name":"value","field":"data"},
{"type":"struct","fields":
[
{"type":"double","optional":true,"field":"ID"},
{"type":"string","optional":true,"field":"NAME"}
],"optional":true,"name":"value","field":"before"}
],"optional":false,"name":"flink_test.scott.test_20200402.row"},
"payload":
{
"SCN":1719627,
"SEG_OWNER":"SCOTT",
"TABLE_NAME":"TEST_20200402",
"TIMESTAMP":1585773001000,
"SQL_REDO":"insert into \"SCOTT\".\"TEST_20200402\"(\"ID\",\"NAME\") values (2,'zhangfei')",
"OPERATION":"INSERT",
"data":{"ID":2.0,"NAME":"zhangfei"},
"before":null
}
}
8.Flink中读取数据 Demo
public static void main(String[] args) throws Exception { StreamExecutionEnvironment Env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "192.168.58.177:9092"); properties.setProperty("zookeeper.connect", "192.168.58.171:2181,192.168.58.177:2181"); properties.setProperty("group.id", "test"); FlinkKafkaConsumer myConsumer = new FlinkKafkaConsumer("flink_topic",new SimpleStringSchema(),properties); //设置并行度 myConsumer.setStartFromEarliest(); //添加数据源,json格式 DataStreamSource<ObjectNode> stream = Env.addSource(myConsumer); stream.print(); Env.execute("flink_topic"); } public static class DataS{ public Integer id; public String name; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
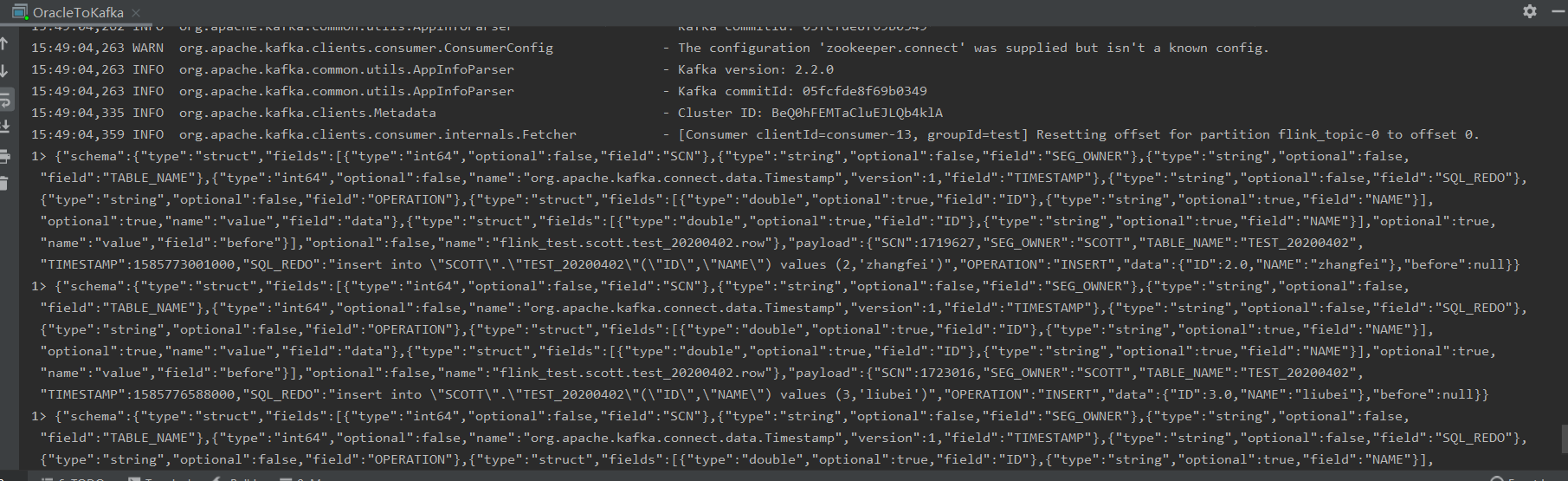
9. 运用Flink Sql进行实时计算
package com.flink; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.StreamTableEnvironment; public class OracleToFlink { public static void main(String[] args) throws Exception { //创建flink运行环境 StreamExecutionEnvironment Env = StreamExecutionEnvironment.getExecutionEnvironment(); //创建tableEnvironment StreamTableEnvironment TableEnv = StreamTableEnvironment.create(Env); TableEnv.sqlUpdate("CREATE TABLE user_log2 (\n" + " payload ROW(SCN string,SEG_OWNER string,data ROW(ID DECIMAL,NAME string))\n" + ") WITH (\n" + " 'connector.type' = 'kafka',\n" + " 'connector.version' = 'universal',\n" + " 'connector.topic' = 'flink_topic',\n" + " 'connector.startup-mode' = 'latest-offset',\n" + " 'connector.properties.group.id' = 'test',\n" + " 'connector.properties.zookeeper.connect' = '192.168.58.171:2181,192.168.58.177:2181,192.168.58.178:2181',\n" + " 'connector.properties.bootstrap.servers' = '192.168.58.177:9092',\n" + " 'format.type' = 'json',\n" + " 'format.json-schema' =\n" + " '{\n" + " type : \"object\",\n" + " \"properties\":\n" + " {\n" + " \"payload\": {type : \"object\",\n" + " \"properties\": \n" + " {\n" + " \"SCN\" : {type :\"string\"},\n" + " \"SEG_OWNER\" : {type :\"string\"},\n" + " \"data\": {type : \"object\",\n" + " \"properties\": {\"ID\": {type : \"integer\"},\n" + " \"NAME\": {type : \"string\"}\n" + " }\n" + " }\n" + " }}\n" + " }\n" + " }'\n" + ")" ) ; Table result=TableEnv.sqlQuery("select payload.data.NAME,sum(payload.data.ID) from user_log2 group by payload.data.NAME"); TableEnv.toRetractStream(result,Types.TUPLE(Types.STRING,Types.STRING,Types.BIG_DEC,Types.STRING)) .print(); Env.execute("flink job"); } }
运行结果:

目标:致力于技术的发展,整理自己工作中的内容,并用于以后的学习。
邮箱:taotao8810@hotmail.com
转载请注明出处!!!
