

druid

主要用到的是ReentrantLock锁,还有 notEmpty empty两个条件,生产连接与消费连接的线程在两个条件上等待与唤醒。empty还是生产者,notEmpty是消费者。
主要DruidAbstractDataSource与DruidDataSource两个类了。
创建连接 DruidDataSource里的CreateConnectionThread,连接太多了的时候,在empty条件上等待,就是等空了再运行,现在别急着创建连接,等着吧!
connection = createPhysicalConnection(); 创建一个物理连接。然后put一下,这个put很可能是放池子中,
使用连接 DruidDataSource 的getConnectionInternal的takeLast()方法从池子里面获取连接。getConnectionInternal方法还会直接创建一个物理连接createPhysicalConnection()
谁在用takeLast(),查找发现是getPooledConnection()--getConnection(maxWait)---getConnectionDirect(maxWaitMillis)--getConnectionInternal(maxWaitMillis)
getConnection(),这里面又是插入了过滤链,果然是为统计而生,都记录在案了。
减少连接 在创建连接线程附近还有一个DestroyConnectionThread()有destroyTask.run();----->shrink(true);看名字是收缩嘛,可能连接空闲的太多了,就缩小呗。
初始化方法init()
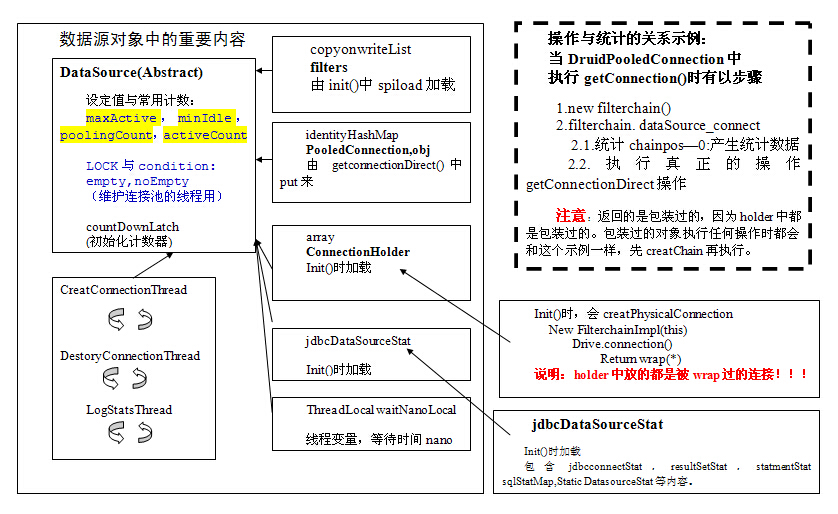
一个创建的线程,一个清理的线程,一个获取连接的线程,3个线程公用一把锁。
public class AA { public static DataSource getDataSource1() throws Exception{ DruidDataSource dataSource1 = new DruidDataSource(); dataSource1.setDriverClassName("com.mysql.jdbc.Driver"); dataSource1.setUrl("jdbc:mysql://127.0.0.1:3306/account?useUnicode=true&characterEncoding=utf-8&useSSL=false"); dataSource1.setUsername("root"); dataSource1.setPassword("123456"); // dataSource1.addFilters("stat"); return dataSource1; } public static void main(String[] args) throws SQLException, Exception { final String sql = "select * from money"; for (int i = 0; i < 5; i++) { new Thread(new Runnable() { @Override public void run() { try { Connection conn = getDataSource1().getConnection(); StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace(); for (StackTraceElement ele : stackTrace) { System.out.println(ele); } PreparedStatement preparedStatement = conn.prepareStatement(sql); ResultSet re = preparedStatement.executeQuery(); while(re.next()) { System.out.println(re.getDouble("money")); System.out.println(re.getString("name")); System.out.println(re.getInt("id")); } preparedStatement.close(); conn.close(); } catch (Exception e) { e.printStackTrace(); } } }, "get()线程" + (i+1)).start(); } } }

