
hdfs扩容
hdfs文件系统扩容
hdfs热部署和冷部署
热部署:服务不停止,直接增加节点机器,增加主机器中的slaves,hadoop-deamon.sh start datanode
冷部署:服务停止,增加机器后,开启服务
在namenode和yarn已经分配好后,后续的增加容量,加多个节点时,热冷部署步骤相同。
横向扩充:增加节点机器
克隆之前的机器
修改ip
修改ip映射,主机名
保持hadoop/tmp/文件夹的干净
修改主机器的slaves文件--增加克隆的主机名
在克隆主机上 启动datanode服务
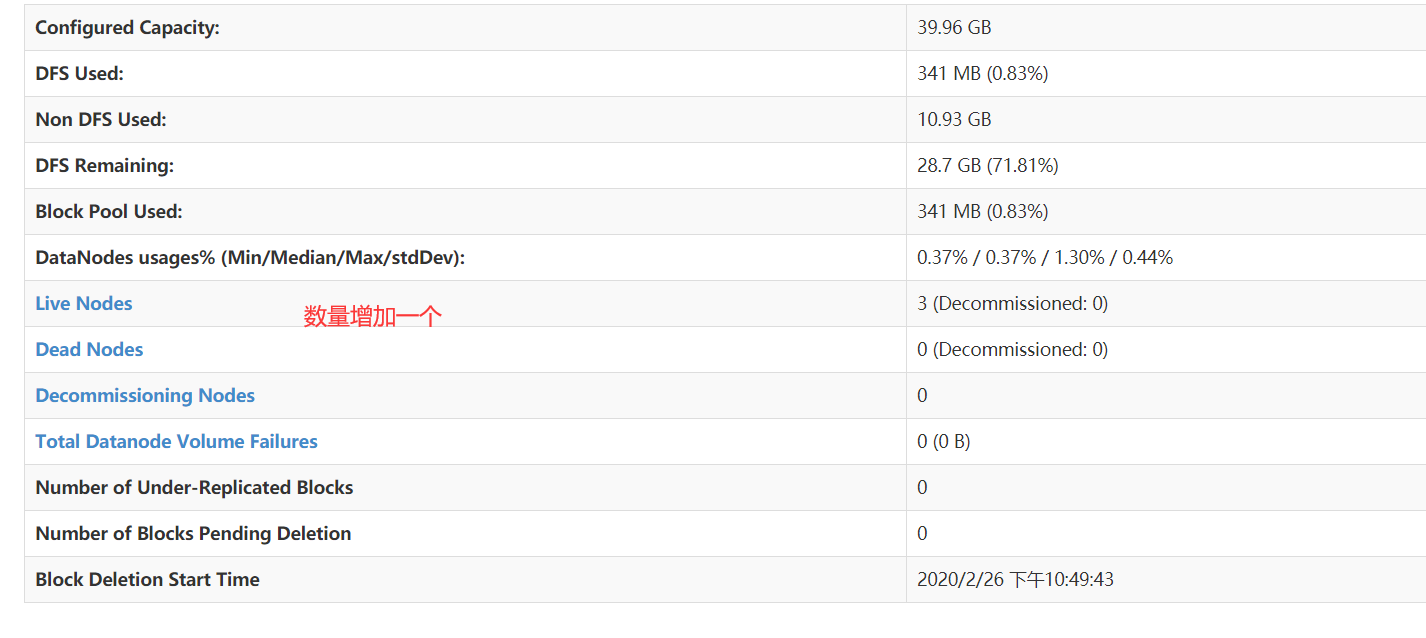
测试:
新增一个livenode
纵向扩充:增加磁盘
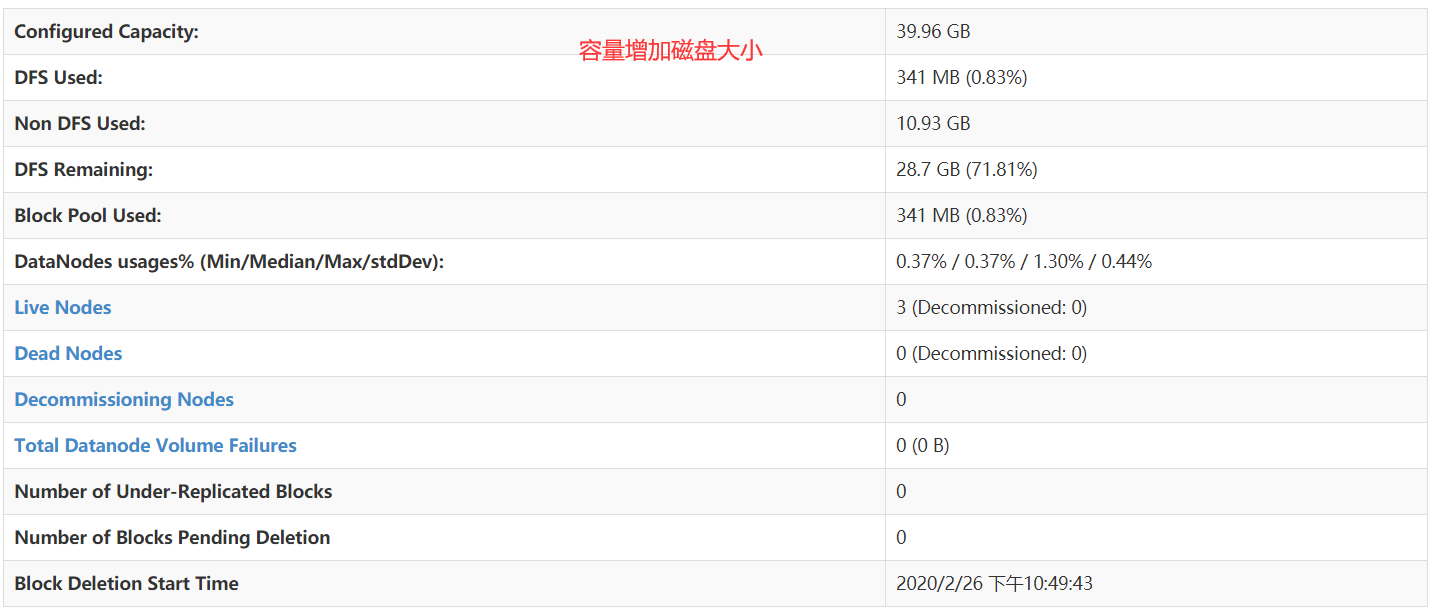
hdfs默认的data数据保存在tmp/dfs/data中, 修改hdfs-site.xml文件,添加硬盘路径,可以无限增加。
配置如下:
hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>磁盘挂载路径,data存放的默认目录(tmp/hdfs/data)</value>
</property>
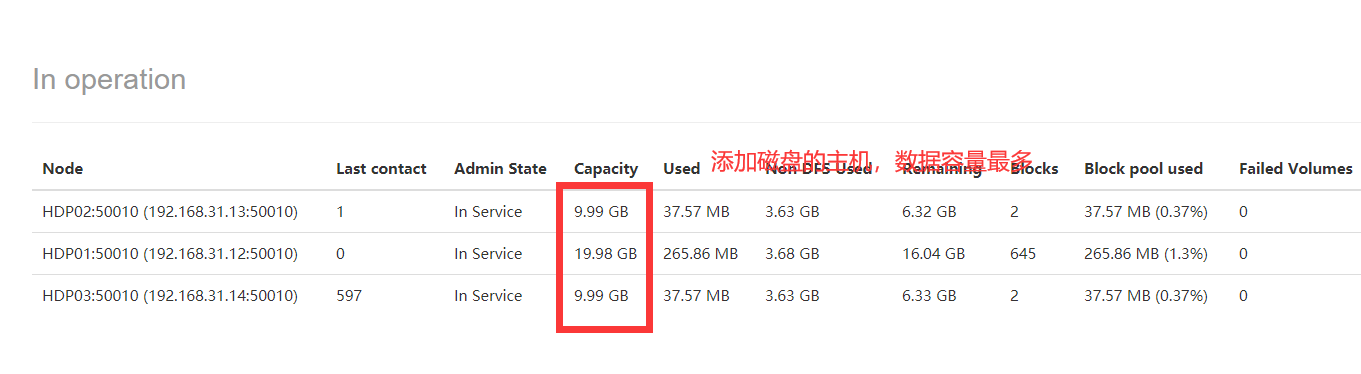
在添加的磁盘主机上不需要重启服务,关闭再开启datanode就好了 hadoop-daemon.sh stop datanode hadoop-daemon.sh start datanode
hdfs总容量增加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号