
浅试Beautiful Soup
安装与准备工作
为了方便开发者在html或xml中提取所需数据,Beautiful Soup可以快速的查找html或xml中的信息。
为了使用Beautiful Soup,首先应在Terminal安装:
pip install beautifulsoup4
同时,为了提高效率和稳定性,建议同时安装解析器搭配使用(当然不搭配也可以):
- 安装 lxml:
pip install lxml - 安装 html5lib:
pip install html5lib
不同解析器的区别如下图:
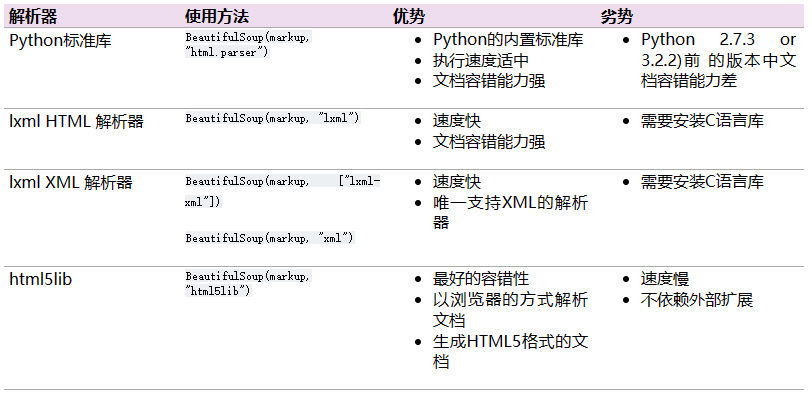
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#id9
使用bs4
首先引入bs4库(/包?)
from bs4 import BeautifulSoup
假设我们经过读取网站返回的Response,得到了如下页面:
点击查看代码
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
(当然也可以不指定解析器,bs4会选择最适合的解析器,并抛出一个提示。)
对于这个BeautifulSoup对象,可以使用soup.prettify()得到标准缩进形式。(prettify:美化)
几个简单的获取数据的指令:
-
得到标题:
点击查看代码
soup.title # <title>The Dormouse's story</title> -
得到某个标签tag的内容:
点击查看代码
soup.p # <p class="title"><b>The Dormouse's story</b></p>该指令仅会得到该标签第一次出现的内容。
-
得到tag内属性:
对于一个tag中的属性,可以近似看做一个字典。点击查看代码
soup.p['class'] # u'title' -
查找所有名称相同的tag:
点击查看代码
soup.find_all('a') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] -
找到某个属性和值对应的tag:
点击查看代码
soup.find(id="link3") # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> -
从文档中获取所有文字内容:
点击查看代码
print(soup.get_text()) # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
