一个高效的TensorFlow数据集前处理代码
def csv_reader_dataset(filepaths, repeat=1, n_readers=5,
n_read_threads=None, shuffle_buffer_size=10000,
n_parse_threads=5, batch_size=32):
dataset = tf.data.Dataset.list_files(filepaths).repeat(repeat)
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers, num_parallel_calls=n_read_threads)
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads)
dataset = dataset.batch(batch_size)
return dataset.prefetch(1)
train_set = csv_reader_dataset(train_filepaths, repeat=None)
valid_set = csv_reader_dataset(valid_filepaths)
test_set = csv_reader_dataset(test_filepaths)
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1),
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
batch_size = 32
model.fit(train_set, steps_per_epoch=len(X_train) // batch_size, epochs=10,
validation_data=valid_set)

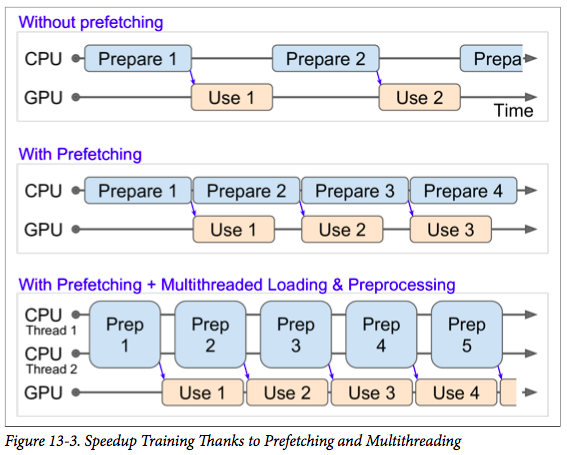
prefetch
prefetch可以使CPU和GPU的使用率最大化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号