第十二节:MySQL8.x版本新特性和变化
一. 新特性1---必会
(建议使用8.0.17及之后的版本,更新的内容比较多)
1. 新增降序索引
MySQL在语法上很早就已经支持降序索引,但实际上创建的仍然是升序索引,即在8.0之前,即使你创建的时候降序索引,但实际上还是升序索引。8.0以后才能真正支持了降序索引(只有Innodb存储引擎支持降序索引)
(1). 数据准备---mysql5.7 和 8.0 都要执行
创建联合索引c1-c2,其中c1是升序的,c2是降序的。
mysql> create table t1(c1 int,c2 int,index idx_c1_c2(c1,c2 desc));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into t1 (c1,c2) values(1, 10),(2,50),(3,50),(4,100),(5,80);
Query OK, 5 rows affected (0.02 sec)(2). mysql5.7测试
查看表结构和执行计划,发现c2是升序的,
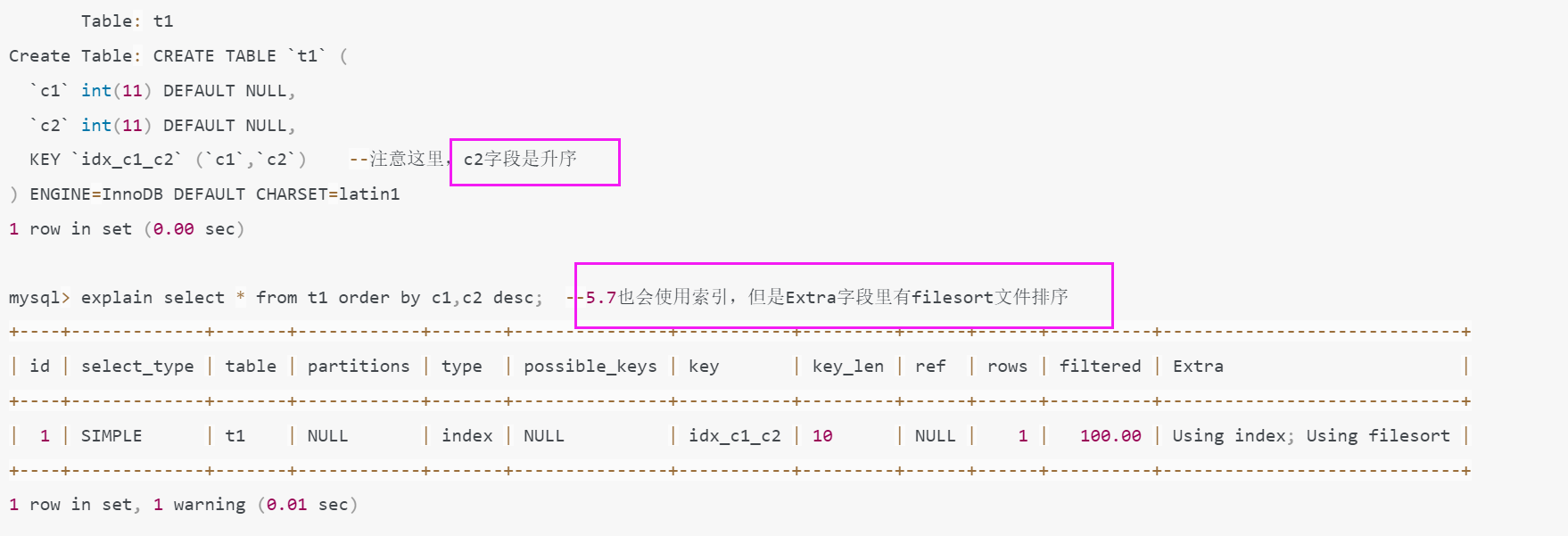
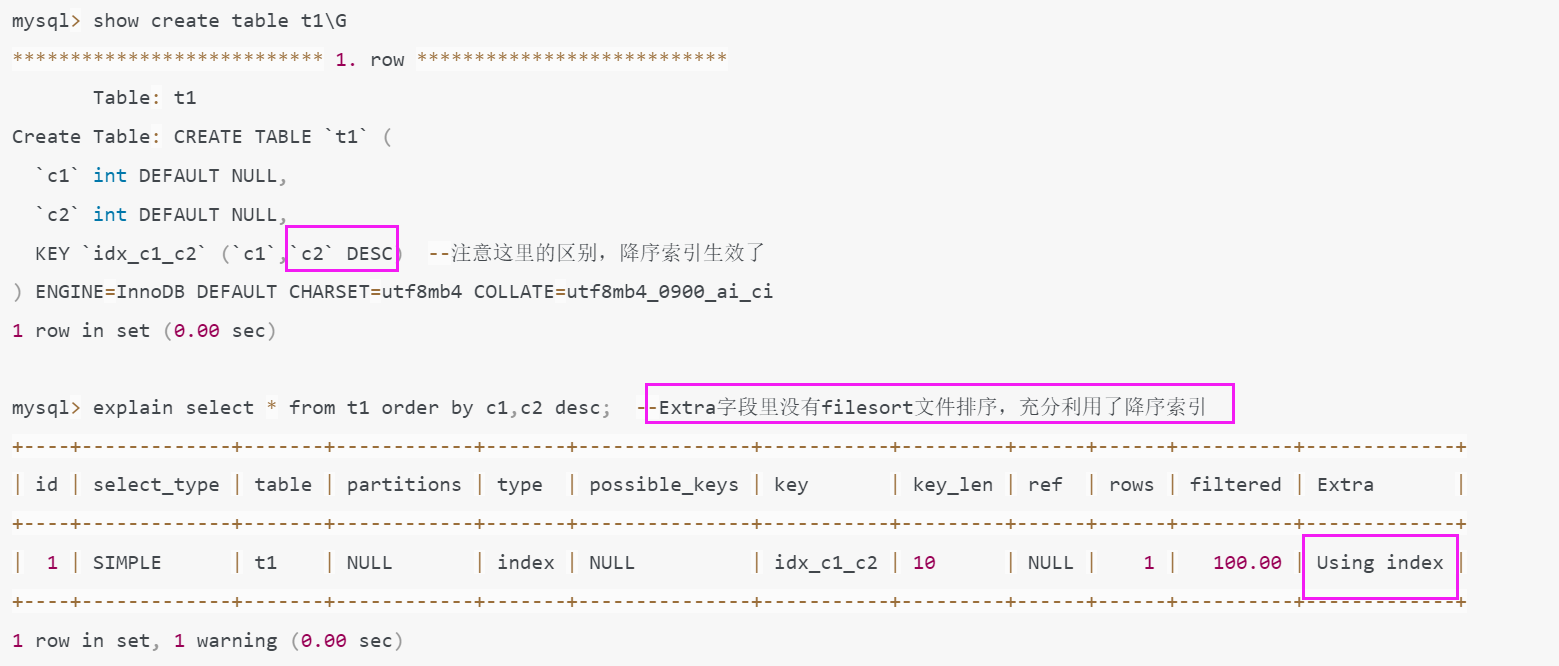
(3). mysql8.0测试
发现降序索引生效了。
其它测试:
排序必须按照每个字段定义的排序或按相反顺序才能充分利用索引
mysql> explain select * from t1 order by c1 desc,c2; --Extra字段里有Backward index scan,意思是反向扫描索引;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Backward index scan; Using index |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from t1 order by c1 desc,c2 desc; --Extra字段里有filesort文件排序,排序必须按照每个字段定义的排序或按相反顺序才能充分利用索引
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from t1 order by c1,c2; --Extra字段里有filesort文件排序,排序必须按照每个字段定义的排序或按相反顺序才能充分利用索引
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
2. 新增隐藏索引
使用 invisible 关键字在创建表或者进行表变更中设置索引为隐藏索引。索引隐藏只是不可见,但是数据库后台还是会维护隐藏索引的,在查询时优化器不使用该索引,即使用force index,优化器也不会使用该索引,同时优化器也不会报索引不存在的错误,因为索引仍然真实存在,必要时,也可以把隐藏索引快速恢复成可见。注意,主键不能设置为 invisible。
使用场景:软删除就可以使用隐藏索引,比如我们觉得某个索引没用了,删除后发现这个索引在某些时候还是有用的,于是又得把这个索引加回来,如果表数据量很大的话,这种操作耗费时间是很多的,成本很高,这时,我们可以将索引先设置为隐藏索引,等到真的确认索引没用了再删除。
(1). 数据准备---mysql8.0执行
# 创建t2表,里面的c2字段为隐藏索引
mysql> create table t2(c1 int, c2 int, index idx_c1(c1), index idx_c2(c2) invisible);
Query OK, 0 rows affected (0.02 sec)(2). mysql8.0测试
A. 查看索引
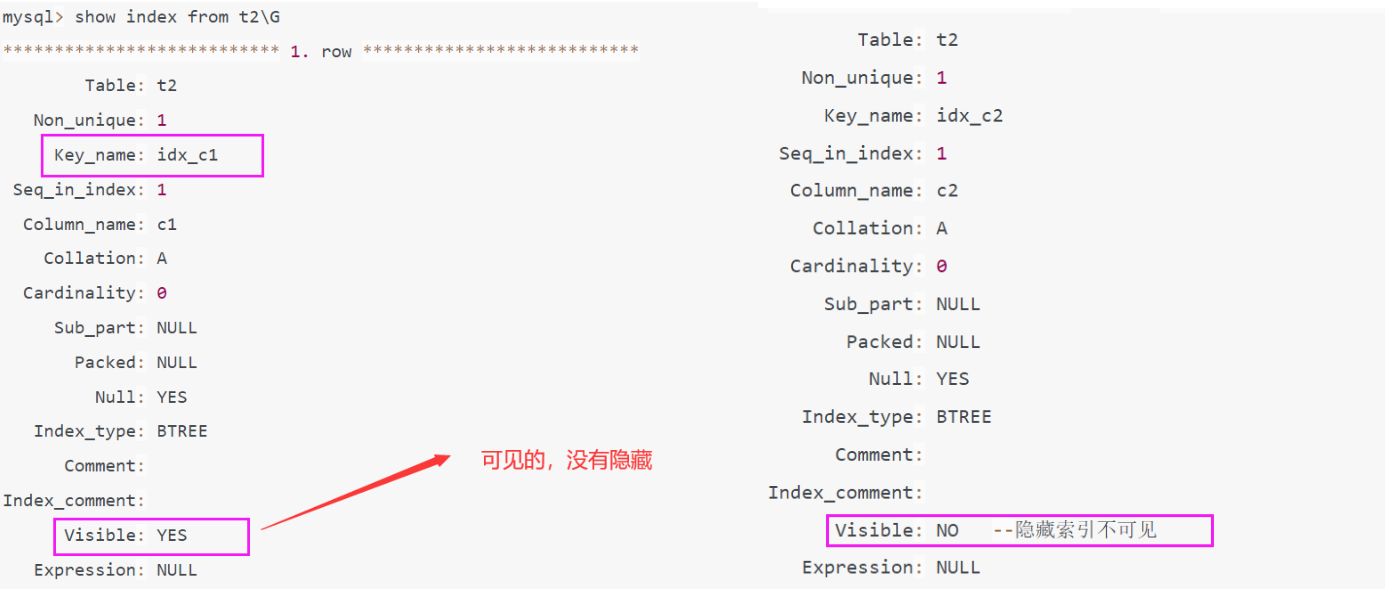
B. 查看执行计划

C. 打开索引 和 隐藏索引
# 打开索引
mysql> alter table t2 alter index idx_c2 visible;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
# 隐藏索引
mysql> alter table t2 alter index idx_c2 invisible;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
3. 新增函数索引
8.0之前我们知道,如果在查询中加入了函数,索引不生效,所以MySQL 8引入了函数索引,MySQL 8.0.13开始支持在索引中使用函数(表达式)的值。
函数索引基于虚拟列功能实现,在MySQL中相当于新增了一个列,这个列会根据你的函数来进行计算结果,然后使用函数索引的时候就会用这个计算后的列作为索引。
(1). 数据准备---mysql8.0执行
mysql> create table t3(c1 varchar(10),c2 varchar(10));
Query OK, 0 rows affected (0.02 sec)
mysql> create index idx_c1 on t3(c1); --创建普通索引
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create index func_idx on t3((UPPER(c2))); --创建一个大写的函数索引
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0(2). mysql8.0测试
A. 查看索引
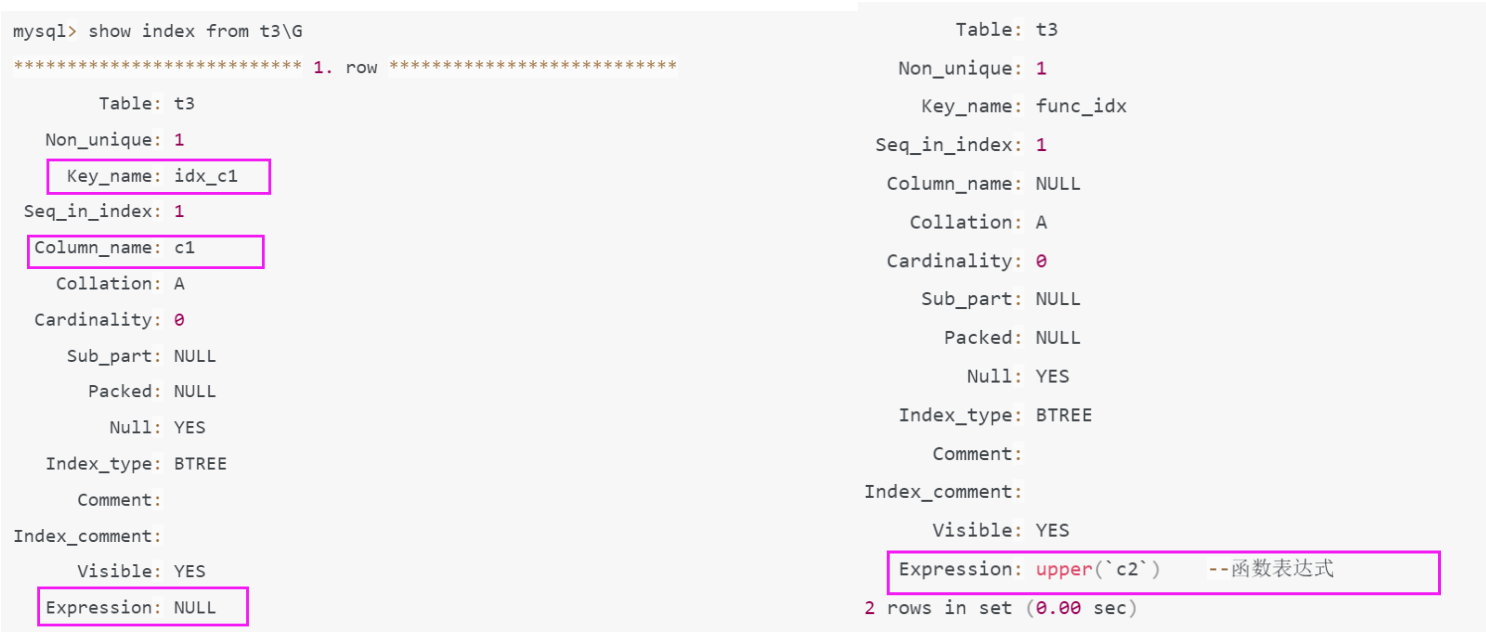
B. 查看执行计划

4. group by不再隐式排序
(1). mysql5.7测试
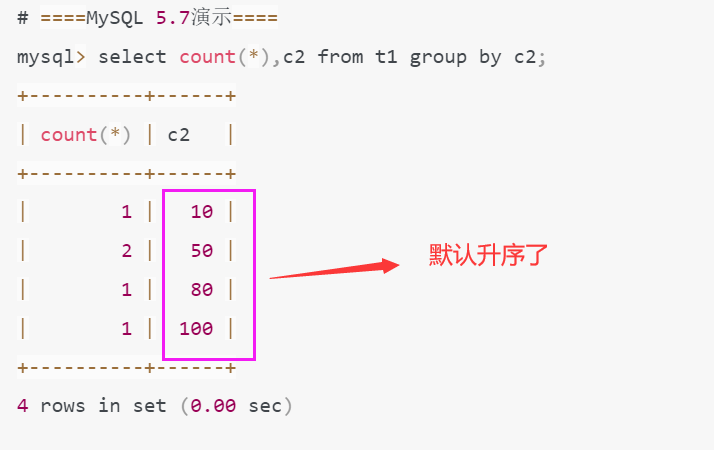
(2). mysql8.0测试
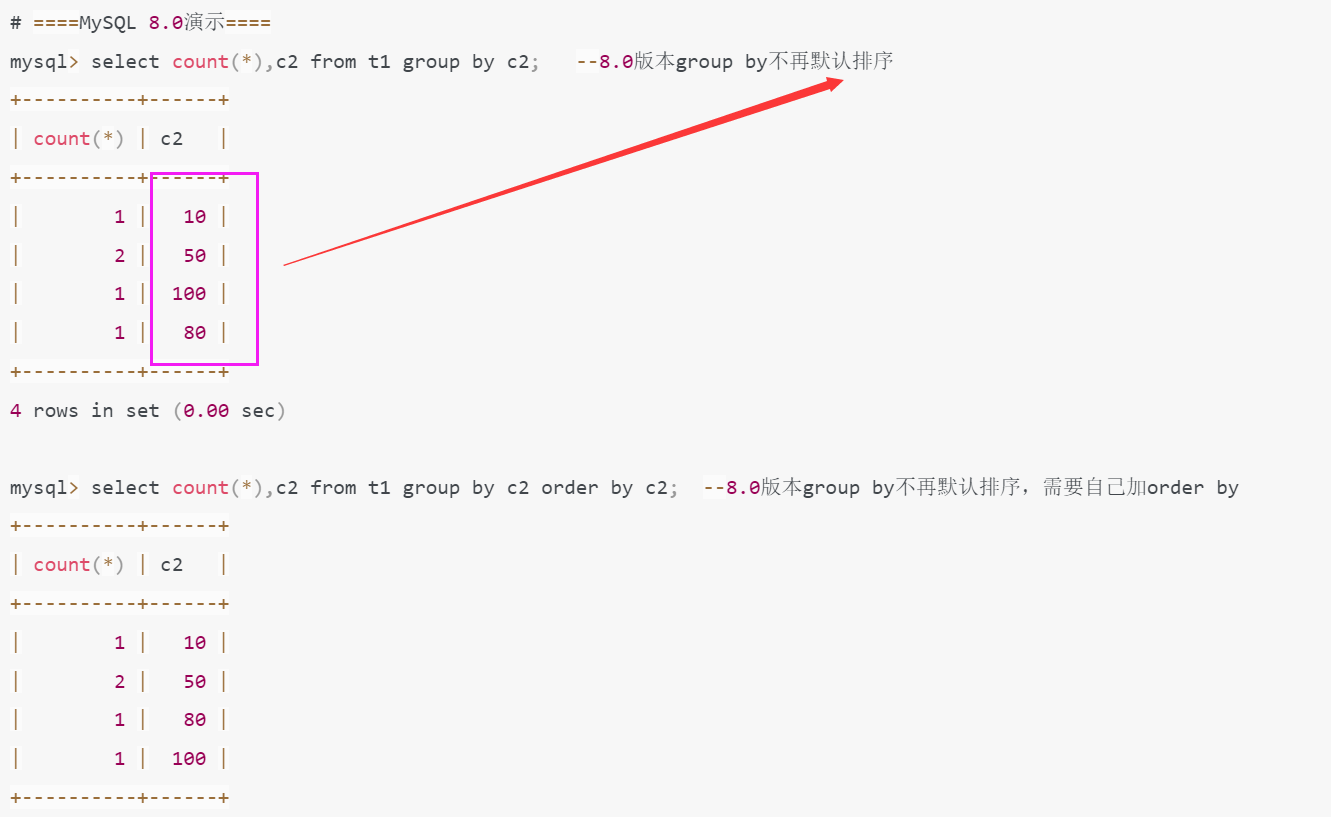
5. innodb存储引擎select for update跳过锁等待
(补充:在MySQL中,SELECT ... FOR UPDATE 语句用于在事务中锁定选定的行,以便其他事务在事务完成之前不能修改或锁定这些行。这种锁通常被称为“行级锁”(Row-level Lock)或“排他锁”(Exclusive Lock),因为它防止其他事务对这些行进行写操作(UPDATE, DELETE)或再次进行SELECT ... FOR UPDATE。)
对于select ... for share(8.0新增加查询共享锁的语法)或 select ... for update, 在语句后面添加NOWAIT、SKIP LOCKED语法可以跳过锁等待,或者跳过锁定。
在5.7及之前的版本,select...for update,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout超时。
在8.0版本,通过添加nowait,skip locked语法,能够立即返回。如果查询的行已经加锁,那么nowait会立即报错返回,而skip locked也会立即返回,只是返回的结果中不包含被锁定的行。
应用场景比如查询余票记录,如果某些记录已经被锁定,用skip locked可以跳过被锁定的记录,只返回没有锁定的记录,提高系统性能。
Session1中更改数据,但不提交事务:
# 先打开一个session1:
mysql> select * from t1;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 10 |
| 2 | 50 |
| 3 | 50 |
| 4 | 100 |
| 5 | 80 |
+------+------+
5 rows in set (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update t1 set c2 = 60 where c1 = 2; --锁定第二条记录
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0Session2:
# 另外一个session2:
mysql> select * from t1 where c1 = 2 for update; --等待超时
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> select * from t1 where c1 = 2 for update nowait; --查询立即返回
ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set.
mysql> select * from t1 for update skip locked; --查询立即返回,过滤掉了第二行记录
+------+------+
| c1 | c2 |
+------+------+
| 1 | 10 |
| 3 | 50 |
| 4 | 100 |
| 5 | 80 |
+------+------+
4 rows in set (0.00 sec)在8.0之前的版本,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1,这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。
一直到8.0才被解决,8.0版本将会对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。
5.7
查看代码
# ====MySQL 5.7演示====
mysql> create table t(id int auto_increment primary key,c1 varchar(20));
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t(c1) values('zhuge1'),('zhuge2'),('zhuge3');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge3 |
+----+--------+
3 rows in set (0.00 sec)
mysql> delete from t where id = 3;
Query OK, 1 row affected (0.01 sec)
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
+----+--------+
2 rows in set (0.00 sec)
mysql> exit;
Bye
# 重启MySQL服务,并重新连接MySQL
mysql> insert into t(c1) values('zhuge4');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge4 |
+----+--------+
3 rows in set (0.00 sec)
mysql> update t set id = 5 where c1 = 'zhuge1';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 3 | zhuge4 |
| 5 | zhuge1 |
+----+--------+
3 rows in set (0.00 sec)
mysql> insert into t(c1) values('zhuge5');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 3 | zhuge4 |
| 4 | zhuge5 |
| 5 | zhuge1 |
+----+--------+
4 rows in set (0.00 sec)
mysql> insert into t(c1) values('zhuge6');
ERROR 1062 (23000): Duplicate entry '5' for key 'PRIMARY'8.0
查看代码
# ====MySQL 8.0演示====
mysql> create table t(id int auto_increment primary key,c1 varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t(c1) values('zhuge1'),('zhuge2'),('zhuge3');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge3 |
+----+--------+
3 rows in set (0.00 sec)
mysql> delete from t where id = 3;
Query OK, 1 row affected (0.01 sec)
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
+----+--------+
2 rows in set (0.00 sec)
mysql> exit;
Bye
[root@localhost ~]# service mysqld restart
Shutting down MySQL.... SUCCESS!
Starting MySQL... SUCCESS!
# 重新连接MySQL
mysql> insert into t(c1) values('zhuge4');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t; --生成的id为4,不是3
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 4 | zhuge4 |
+----+--------+
3 rows in set (0.00 sec)
mysql> update t set id = 5 where c1 = 'zhuge1';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 4 | zhuge4 |
| 5 | zhuge1 |
+----+--------+
3 rows in set (0.00 sec)
mysql> insert into t(c1) values('zhuge5');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 4 | zhuge4 |
| 5 | zhuge1 |
| 6 | zhuge5 |
+----+--------+
4 rows in set (0.00 sec)
二. 新特性2--不常用
能够让InnoDB根据服务器上检测到的内存大小自动配置innodb_buffer_pool_size,innodb_log_file_size等参数,会尽可能多的占用系统可占用资源提升性能。
解决非专业人员安装数据库后默认初始化数据库参数默认值偏低的问题,前提是服务器是专用来给MySQL数据库的,如果还有其他软件或者资源或者多实例MySQL使用,不建议开启该参数,不然会影响其它程序。
mysql> show variables like '%innodb_dedicated_server%'; --默认是OFF关闭,修改为ON打开
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_dedicated_server | OFF |
+-------------------------+-------+
1 row in set (0.02 sec)MySQL 8.0 (MySQL 5.7.15)增加了一个新的动态变量 innodb_deadlock_detect,用于控制系统是否执行 InnoDB 死锁检查,默认是打开的。
死锁检测会耗费数据库性能的,对于高并发的系统,我们可以关闭死锁检测功能,提高系统性能。但是我们要确保系统极少情况会发生死锁,同时要将锁等待超时参数调小一点,以防出现死锁等待过久的情况。
mysql> show variables like '%innodb_deadlock_detect%'; --默认是打开的
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_deadlock_detect | ON |
+------------------------+-------+
1 row in set, 1 warning (0.01 sec)默认创建2个UNDO表空间,不再使用系统表空间。

在8.0版本之前,binlog日志过期时间设置都是设置expire_logs_days参数,精确到天。而在8.0版本中,MySQL默认使用binlog_expire_logs_seconds参数。
在8.0版本之前,默认字符集为latin1,utf8指向的是utf8mb3,8.0版本默认字符集为utf8mb4,utf8默认指向的也是utf8mb4。
将系统表(mysql)和数据字典表全部改为InnoDB存储引擎,默认的MySQL实例将不包含MyISAM表,除非手动创建MyISAM表。
MySQL 8.0删除了之前版本的元数据文件,例如表结构.frm等文件,全部集中放入mysql.ibd文件里。

MySQL 8.0版本支持在线修改全局参数并持久化,通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。set global 设置的变量参数在mysql重启后会失效。
mysql> set persist innodb_lock_wait_timeout=25;
#系统会在数据目录下生成一个包含json格式的mysqld-auto.cnf 的文件,格式化后如下所示,当my.cnf 和mysqld-auto.cnf 同时存在时,后者具有更高优先级。
{
"Version": 1,
"mysql_server": {
"innodb_lock_wait_timeout": {
"Value": "25",
"Metadata": {
"Timestamp": 1675290252103863,
"User": "root",
"Host": "localhost"
}
}
}
}InnoDB表的DDL支持事务完整性,要么成功要么回滚。
比如在mysql5.7 和 8.0中,都只有t1表。 然后在 5.7 和 8.0 中分别执行


三. 新特性3-窗口函数
1. 说明
从 MySQL 8.0 开始,新增了一个叫窗口函数的概念,它可以用来实现若干新的查询方式。
窗口函数与 SUM()、COUNT() 这种分组聚合函数类似,在聚合函数后面加上over()就变成窗口函数了,在括号里可以加上partition by等分组关键字指定如何分组,窗口函数即便分组也不会将多行查询结果合并为一行,而是将结果放回多行当中,即窗口函数不需要再使用 GROUP BY。
2. 实操
(1). 数据准备
# 创建一张账户余额表
CREATE TABLE `account_channel` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '姓名',
`channel` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '账户渠道',
`balance` int DEFAULT NULL COMMENT '余额',
PRIMARY KEY (`id`)
) ENGINE=InnoDB
# 插入一些示例数据
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('1', 'zhuge', 'wx', '100');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('2', 'zhuge', 'alipay', '200');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('3', 'zhuge', 'yinhang', '300');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('4', 'lilei', 'wx', '200');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('5', 'lilei', 'alipay', '100');
INSERT INTO `test`.`account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('6', 'hanmeimei', 'wx', '500');
mysql> select * from account_channel;
+----+-----------+---------+---------+
| id | name | channel | balance |
+----+-----------+---------+---------+
| 1 | zhuge | wx | 100 |
| 2 | zhuge | alipay | 200 |
| 3 | zhuge | yinhang | 300 |
| 4 | lilei | wx | 200 |
| 5 | lilei | alipay | 100 |
| 6 | hanmeimei | wx | 500 |
+----+-----------+---------+---------+
6 rows in set (0.00 sec)(2). 窗口函数的使用
在聚合函数后面加上over()就变成分析函数了,后面可以不用再加group by制定分组,因为在over里已经用partition关键字指明了如何分组计算,这种可以保留原有表数据的结构,不会像分组聚合函数那样每组只返回一条数据
over()里如果不加条件,则默认使用整个表的数据做运算
mysql> select name,sum(balance) from account_channel group by name;
+-----------+--------------+
| name | sum(balance) |
+-----------+--------------+
| zhuge | 600 |
| lilei | 300 |
| hanmeimei | 500 |
+-----------+--------------+
3 rows in set (0.00 sec)
# 在聚合函数后面加上over()就变成分析函数了,后面可以不用再加group by制定分组,因为在over里已经用partition关键字指明了如何分组计算,这种可以保留原有表数据的结构,不会像分组聚合函数那样每组只返回一条数据
mysql> select name,channel,balance,sum(balance) over(partition by name) as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500 |
| lilei | wx | 200 | 300 |
| lilei | alipay | 100 | 300 |
| zhuge | wx | 100 | 600 |
| zhuge | alipay | 200 | 600 |
| zhuge | yinhang | 300 | 600 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)
mysql> select name,channel,balance,sum(balance) over(partition by name order by balance) as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500 |
| lilei | alipay | 100 | 100 |
| lilei | wx | 200 | 300 |
| zhuge | wx | 100 | 100 |
| zhuge | alipay | 200 | 300 |
| zhuge | yinhang | 300 | 600 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)
# over()里如果不加条件,则默认使用整个表的数据做运算
mysql> select name,channel,balance,sum(balance) over() as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| zhuge | wx | 100 | 1400 |
| zhuge | alipay | 200 | 1400 |
| zhuge | yinhang | 300 | 1400 |
| lilei | wx | 200 | 1400 |
| lilei | alipay | 100 | 1400 |
| hanmeimei | wx | 500 | 1400 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)
mysql> select name,channel,balance,avg(balance) over(partition by name) as avg_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | avg_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500.0000 |
| lilei | wx | 200 | 150.0000 |
| lilei | alipay | 100 | 150.0000 |
| zhuge | wx | 100 | 200.0000 |
| zhuge | alipay | 200 | 200.0000 |
| zhuge | yinhang | 300 | 200.0000 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)3. 其它专用窗口函数
- 序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- 分布函数:PERCENT_RANK()、CUME_DIST()
- 前后函数:LAG()、LEAD()
- 头尾函数:FIRST_VALUE()、LAST_VALUE()
- 其它函数:NTH_VALUE()、NTILE()
# 按照balance字段排序,展示序号
mysql> select name,channel,balance,row_number() over(order by balance) as row_number1 from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | row_number1 |
+-----------+---------+---------+-------------+
| zhuge | wx | 100 | 1 |
| lilei | alipay | 100 | 2 |
| zhuge | alipay | 200 | 3 |
| lilei | wx | 200 | 4 |
| zhuge | yinhang | 300 | 5 |
| hanmeimei | wx | 500 | 6 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)
# 按照balance字段排序,first_value()选出排第一的余额
mysql> select name,channel,balance,first_value(balance) over(order by balance) as first1 from account_channel;
+-----------+---------+---------+--------+
| name | channel | balance | first1 |
+-----------+---------+---------+--------+
| zhuge | wx | 100 | 100 |
| lilei | alipay | 100 | 100 |
| zhuge | alipay | 200 | 100 |
| lilei | wx | 200 | 100 |
| zhuge | yinhang | 300 | 100 |
| hanmeimei | wx | 500 | 100 |
+-----------+---------+---------+--------+
6 rows in set (0.01 sec)
!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号