
第十四节:排序算法详解2(归并排序、快速排序、堆排序)
一. 归并排序
1. 定义
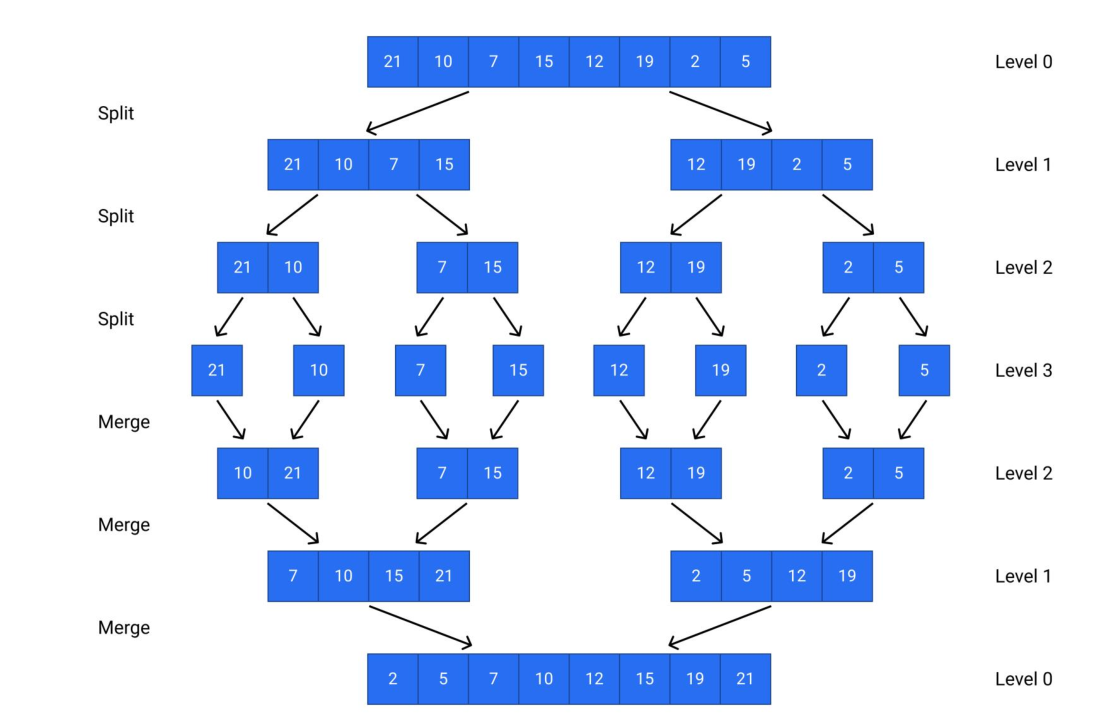
它的基本思想是将待排序数组分成若干个子数组。然后将相邻的子数组归并成一个有序数组。最后再将这些有序数组归并(merge)成一个整体有序的数组。
2. 流程
步骤一:分解(Divide):归并排序使用递归算法来实现分解过程,具体实现中可以分为以下几个步骤:
① 如果待排序数组长度为1,认为这个数组已经有序,直接返回;
② 将待排序数组分成两个长度相等的子数组,分别对这两个子数组进行递归排序;
③ 将两个排好序的子数组合并成一个有序数组,返回这个有序数组。
步骤二:合并(Merge):合并过程中,需要比较每个子数组的元素并将它们有序地合并成一个新的数组:
① 可以使用两个指针 i 和 j 分别指向两个子数组的开头,比较它们的元素大小,并将小的元素插入到新的有序数组中。
② 如果其中一个子数组已经遍历完,就将另一个子数组的剩余部分直接插入到新的有序数组中。
③ 最后返回这个有序数组。
步骤三:归并排序的递归终止条件:
归并排序使用递归算法来实现分解过程,当子数组的长度为1时,认为这个子数组已经有序,递归结束。
3.代码实操
/**
*
* @param arr 待排序的数组
* @returns 有序的数组(由小到大)
*/
function mergeSort(arr: number[]): number[] {
//1. 递归结束的条件:拆分到数组的长度为1
if (arr.length <= 1) return arr;
//2. 拆分数组
//2.1 第1次拆分数组
let mid = Math.floor(arr.length / 2); //向下取整
let leftArray = arr.slice(0, mid); // [) 前闭后开
let rightArray = arr.slice(mid); //前闭到结束
//2.2 递归拆分
let newLeftArray = mergeSort(leftArray);
console.log('--------------------------------------');
let newRightArray = mergeSort(rightArray);
//3.合并数组
let res: number[] = [];
// 双指针
let i = 0;
let j = 0;
//3.1 通过双指针比较两个数组元素, 合并成有序数组
while (i < newLeftArray.length && j < newRightArray.length) {
if (newLeftArray[i] <= newRightArray[j]) {
res.push(newLeftArray[i]);
i++;
} else {
res.push(newRightArray[j]);
j++;
}
}
//3.2 处理剩余的数组(下面的两个if不可能同时成立!!)
//循环完左边还有剩余
if (i < newLeftArray.length) {
res.push(...newLeftArray.slice(i));
}
// 循环完右边还有剩余
if (j < newRightArray.length) {
res.push(...newRightArray.slice(j));
}
//4.将合并后的数组返回
return res;
}性能测试:
4. 时间复杂度
◼ 复杂度的分析过程:
假设数组长度为 n,需要进行 logn 次归并操作;
每次归并操作需要 O(n) 的时间复杂度;
因此,归并排序的时间复杂度为 O(nlogn)。
◼ 最好情况: O(log n)
最好情况下,待排序数组已经是有序的了,那么每个子数组都只需要合并一次,即只需要进行一次归并操作。
因此,此时的时间复杂度是 O(log n)。
◼ 最坏情况: O(nlogn)
最坏情况下,待排序数组是逆序的,那么每个子数组都需要进行多次合并。
因此,此时的时间复杂度为 O(nlogn)。
◼ 平均情况: O(nlogn)
在平均情况下,我们假设待排序数组中任意两个元素都是等概率出现的。
此时,可以证明归并排序的时间复杂度为 O(nlogn)。
5.总结
(1).归并排序是一种非常高效的排序算法,它的核心思想是分治,即将待排序数组分成若干个子数组,分别对这些子数组进行排序, 最后将排好序的子数组合并成一个有序数组。
(2).归并排序的时间复杂度为 O(nlogn),并且在最好、最坏和平均情况下都可以达到这个时间复杂度。
(3).虽然归并排序看起来比较复杂,但是只要理解了基本思路,实现起来并不困难,而且它是一种非常高效的排序算法。
二. 快速排序
【非常非常非常重要!!!! 必须手写,如果面试让你写个算法排序,首选快速排序!!!】
1.定义
快速排序(Quick Sort)是一种基于分治思想的排序算法:
(1).基本思路是将一个大数组分成两个小数组,然后递归地对两个小数组进行排序。
(2) 具体实现方式是通过选择一个基准元素(pivot),将数组分成左右两部分,左部分的元素都小于或等于基准元素,右部分的元素都大于基准元素。
(3) 然后,对左右两部分分别进行递归调用快速排序,最终将整个数组排序。
2. 流程
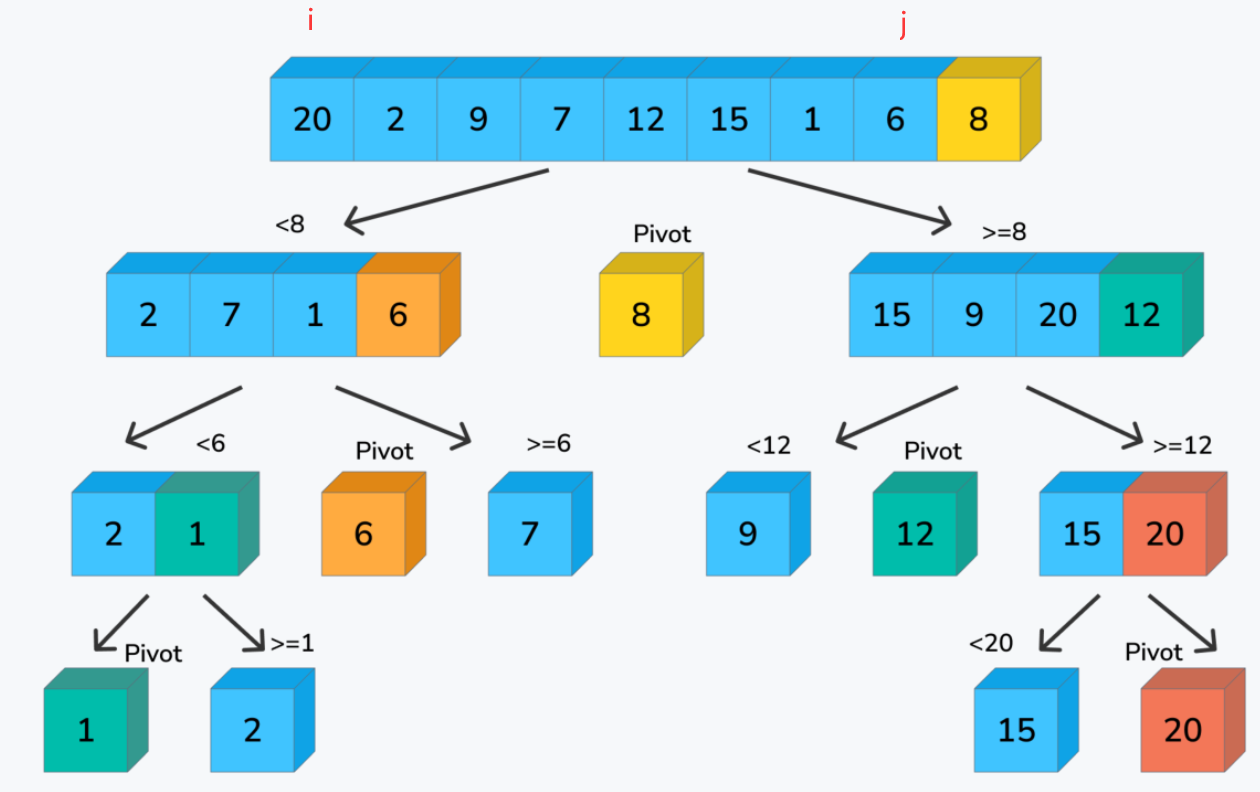
① 首先,我们需要选择一个基准元素,通常选择第一个或最后一个元素作为基准元素。
② 然后,我们定义两个指针 i 和 j,分别指向数组的左右两端。(j指向是right-1的位置,right代表pivot的位置)
③ 接下来,我们从右侧开始,向左移动 j 指针,直到找到一个小于或等于基准元素的值。
④ 然后,我们从左侧开始,向右移动 i 指针,直到找到一个大于或等于基准元素的值。
⑤ 如果 i 指针小于或等于 j 指针,交换 i 和 j 指针所指向的元素。
⑥ 重复步骤 3-5,直到 i 指针大于 j 指针,这时,我们将基准元素与 j 指针所指向的元素交换位置,将基准元素放到中间位置。
⑦ 接着,我们将数组分为两部分,左侧部分包含小于或等于基准元素的元素,右侧部分包含大于基准元素的元素。
⑧ 然后,对左右两部分分别进行递归调用快速排序,直到左右两部分只剩下一个元素。
⑨ 最终,整个数组就变得有序了。
3.代码实操
这里分享三种递归:
方案1:
在内部声明递归方法,可以保证arr至始至终是1个
补充重点:
(1). swap(arr, i, right); 为什么不是i+1?为什么不是j?
答:此时的i指向的元素比pivot大,j指向的元素比pivot小,且i>j, 所以i和pivot对应的内容相互交换.
(2). partition(left, j); 为什么是j,不是i,或者i+1?
答:此处需要画图更明显,因为走完上面的while循环后,i>j,即j在i的左侧, 所以是left-j为一个区间
(3). partition(i + 1, right); 为什么是i+1,而不是i?
答:此处需要画图更明显,i和pivot指向的内容交换了,此时i指向的值 比其左侧都大,比起右侧都小,所以不需要考虑i了,直接从i+1开始排序后面 的即可。
查看代码
/**
* 快速排序-递归写法1
* (在内部声明递归方法,可以保证arr至始至终是1个)
* @param arr 待排序的数组
* @returns 由小到大排序的数组
*/
function quickSort(arr: number[]): number[] {
//调用递归排序
partition(0, arr.length - 1);
/**
* 分区递归排序方法
* @param left 左侧索引
* @param right 右侧索引
*/
function partition(left: number, right: number) {
//递归结束条件
if (left >= right) return;
//1.找到基准元素(pivot轴心)
//这里通常以最右侧的元素为轴心
const pivot = arr[right];
//2.双指针交换操作
//(左边都是比pivot小的元素,右边都是大于等于pivot元素)
let i = left;
let j = right - 1;
while (i <= j) {
//左侧开始,找1个比pivot大(或等于)的元素
while (arr[i] < pivot) {
i++;
}
//右侧开始,找1个比pivot小(或等于)的元素
while (arr[j] > pivot) {
j--;
}
//此时,说明找到了比pivot大的元素、比pivot小的元素
if (i <= j) {
swap(arr, i, j); //交换位置
i++;
j--;
}
}
//3.将pivot放到正确的位置 即和i交换(传递的是索引)
swap(arr, i, right);
//4. 左右继续划分区域进行递归
partition(left, j);
partition(i + 1, right);
}
return arr;
}方案2:
在外部声明递归方法,需要把arr传递进去
查看代码
/**
* 快速排序-递归写法2
* (在外部声明递归方法,需要把arr传递进去)
* @param arr 待排序的数组
* @returns 由小到大排序的数组
*/
function quickSort2(arr: number[]): number[] {
//调用递归函数
partFunc(arr, 0, arr.length - 1);
return arr;
}
/**
* 分区递归排序方法
* @param left 左侧索引
* @param right 右侧索引
*/
function partFunc(arr: number[], left: number, right: number) {
//递归结束条件
if (left >= right) return;
//定义参考元素pivot
let pivot = arr[right];
//定义双指针
let i = left;
let j = right - 1;
//开始遍历
while (i <= j) {
while (arr[j] > pivot) {
j--;
}
while (arr[i] < pivot) {
i++;
}
if (i <= j) {
swap(arr, i, j); //交换位置
i++;
j--;
}
}
//将pivot放到准确位置, 即和i交换(传递的是索引)
swap(arr, right, i);
//继续分区递归
partFunc(arr, left, j);
partFunc(arr, i + 1, right);
}方案3:
/**
* 快速排序-递归写法3
* (自身递归,单指针,第1个元素作为pivot基准元素)
* @param arr 待排序的数组
* @returns 由小到大排序的数组
*/
function quickSort3(arr: number[]): number[] {
//1.递归结束条件
if (arr.length <= 1) return arr;
//2.定义基础变量
let pivot = arr[0];
let leftArr = [];
let rightArr = [];
for (let i = 1; i < arr.length; i++) {
if (arr[i] < pivot) {
leftArr.push(arr[i]);
} else {
rightArr.push(arr[i]);
}
}
return [...quickSort3(leftArr), pivot, ...quickSort3(rightArr)];
}性能测试:
3. 时间复杂度
(1) 最好情况: O(nlogn)
当每次划分后,两部分的大小都相等,即基准元素恰好位于数组的中间位置,此时递归的深度为 O(log n)。
每一层需要进行 n 次比较,因此最好情况下的时间复杂度为 O(nlogn)。
(2) 最坏情况: O(n^2)
当每次划分后,其中一部分为空,即基准元素是数组中的最大或最小值,此时递归的深度为 O(n)。
每一层需要进行 n 次比较,因此最坏情况下的时间复杂度为 O(n^2)。
需要注意的是,采用三数取中法或随机选择基准元素可以有效避免最坏情况的发生。
(3) 平均情况: O(nlogn)
在平均情况下,每次划分后,两部分的大小大致相等,此时递归的深度为 O(log n)
每一层需要进行大约 n 次比较,因此平均情况下的时间复杂度为 O(nlogn)。
注:快速排序是一个原地排序算法,不需要额外的数组空间。
4. 总结
快速排序的性能优于许多其他排序算法,因为它具有良好的局部性和使用原地排序的优点。
它在大多数情况下的时间复杂度为 O(n log n),但在最坏情况下会退化到 O(n^2)。
为了避免最坏情况的发生,可以使用一些优化策略,比如随机选择基准元素和三数取中法。
三. 堆排序
1. 定义
堆排序(Heap Sort)是一种基于比较的排序算法,它的核心思想是使用"二叉堆"来维护一个有序序列。
二叉堆是一种完全二叉树,其中每个节点都满足父节点比子节点大(或小)的条件。
在堆排序中,我们使用"最大堆"来进行排序,也就是保证每个节点都比它的子节点大。
2. 流程
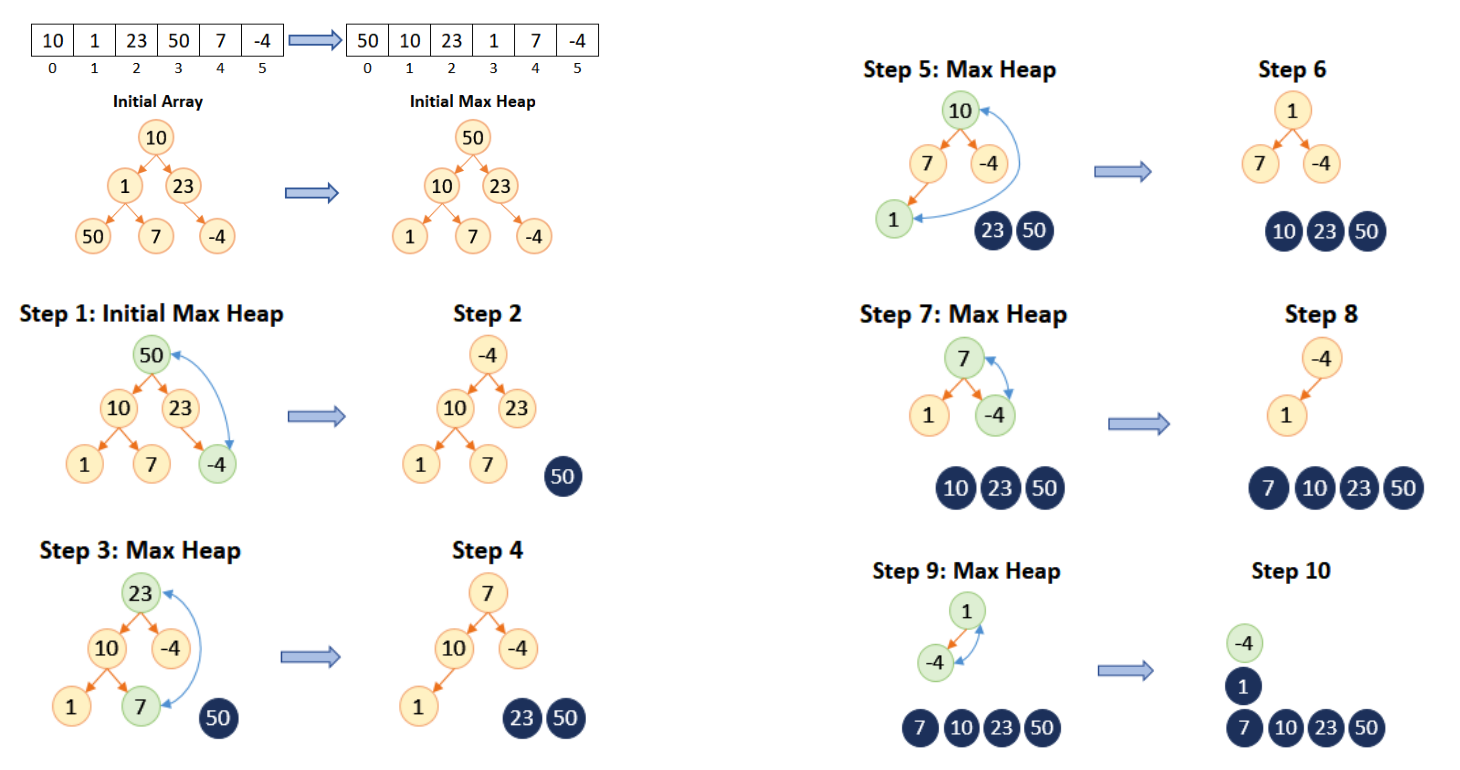
(1).首先构建一个最大堆(原地建堆)。
(2).然后,我们将堆的根节点(也就是最大值)与堆的最后一个元素交换,这样最大值就被放在了正确的位置上。
(3).接着,我们将堆的大小减一,并将剩余的元素进行下滤(从上而下)操作,重新构建成一个最大堆。
(4).我们不断重复这个过程,直到堆的大小为 1。
(5).这样,我们就得到了一个有序的序列。
PS: 与选择排序的关系
A.选择排序的基本思想是在待排序的序列中选出最小(或最大)的元素,然后将其放置到序列的起始位置。
B.堆排序也是一种选择排序算法,它使用最大堆来维护一个有序序列,然后不断选择出最大的值。
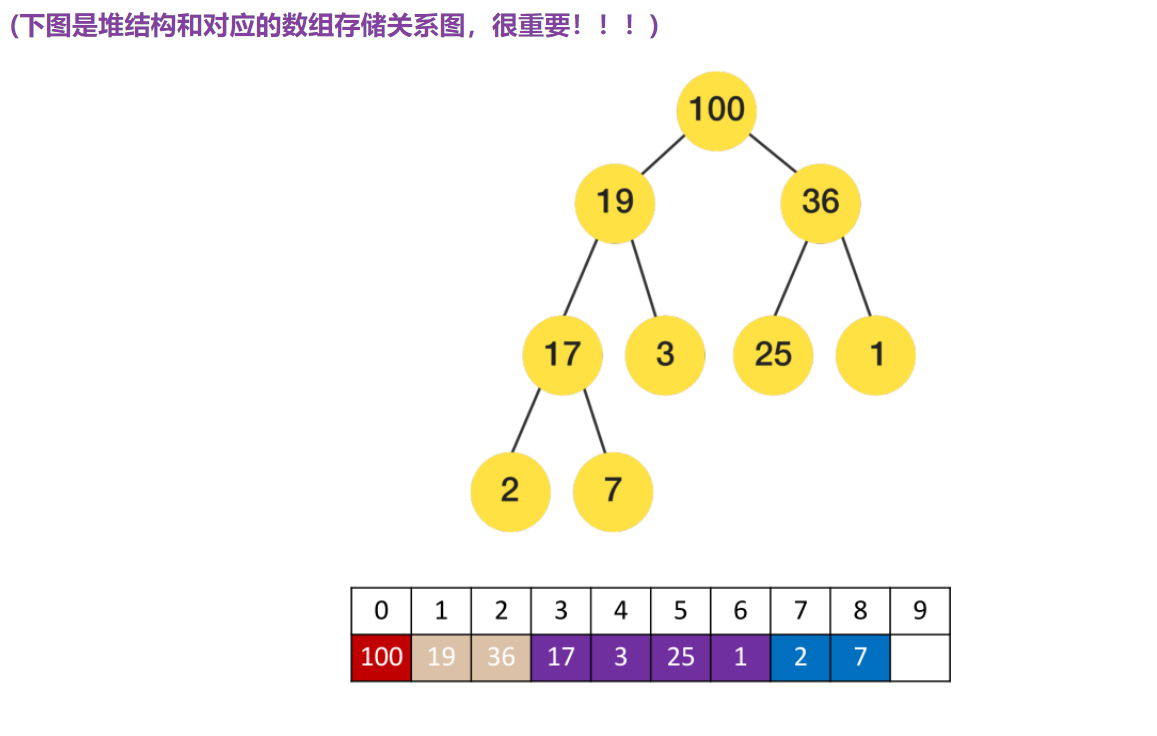
3. 思路详细分析
堆排序可以分成两大步骤:构建最大堆和排序
◼ 构建最大堆:
① 遍历待排序序列,从最后一个非叶子节点开始,依次对每个节点进行调整。
② 假设当前节点的下标为 i,左子节点的下标为 2i+1,右子节点的下标为 2i+2,父节点的下标为 (i-1)/2。
③ 对于每个节点 i,比较它和左右子节点的值,找出其中最大的值,并将其与节点 i 进行交换。
④ 重复进行这个过程,直到节点 i 满足最大堆的性质。
⑤ 依次对每个非叶子节点进行上述操作,直到根节点,这样我们就得到了一个最大堆。
◼ 排序:
① 将堆的根节点(也就是最大值)与堆的最后一个元素交换,这样最大值就被放在了正确的位置上。
② 将堆的大小减小一,并将剩余的元素重新构建成一个最大堆。
③ 重复进行步骤 ① 和步骤 ②,直到堆的大小为 1,这样我们就得到了一个有序的序列。
4.代码实操
import { testSort, measureSort, swap } from 'hy-algokit';
/**
* 堆排序
* @param arr 待排序的数组
* @returns 排序好的,由大到小的数组
*/
function heapSort(arr: number[]): number[] {
let n = arr.length;
//1. 原地建堆
//从第一个非叶子节点开始,进行下滤操作
let start = Math.floor(n / 2 - 1); //公式,记住即可
for (let i = start; i >= 0; i--) {
//下滤操作
heapify_down(arr, i, n);
}
//2. 执行堆排序
for (let i = n - 1; i > 0; i--) {
swap(arr, 0, i);
heapify_down(arr, 0, i);
}
return arr;
}
/**
* 下滤
* @param arr 在该数组中进行下滤
* @param index 从该位置开始进行下滤
* @param n 下滤的范围(即数组的截至位置)
*/
function heapify_down(arr: number[], index: number, n: number) {
//开始位置index的左子节点小于n的情况下,即左子节点存在,可以一直循环
while (2 * index + 1 < n) {
//1. 获取左右子节点索引
let leftChildIndex = 2 * index + 1;
let rightChildIndex = 2 * index + 2;
//2. 获取左右子节点中较大的值
let largerIndex = leftChildIndex; //先默认左子节点, 因为右子节点可能不存在
if (rightChildIndex < n && arr[rightChildIndex] > arr[leftChildIndex]) {
largerIndex = rightChildIndex;
}
//3. 判断index位置的值比更大的子节点, 直接break
if (arr[index] >= arr[largerIndex]) {
break; //终止循环
}
//4.交换位置,继续进行
swap(arr, index, largerIndex);
index = largerIndex;
}
}测试:
//测试
{
console.log('---------------------01-堆排序准确性测试--------------------------');
testSort(heapSort);
}
{
console.log('---------------------02-堆排序性能测试--------------------------');
measureSort(heapSort);
} 
5.时间复杂度
步骤一:堆的建立过程
堆的建立过程包括 n/2 次堆的向下调整操作,因此它的时间复杂度为 O(n)。
步骤二:排序过程
排序过程需要执行 n 次堆的删除最大值操作,每次操作都需要将堆的最后一个元素与堆顶元素交换,然后向下 调整堆。
每次向下 调整操作的时间复杂度为 O(logn),因此整个排序过程的时间复杂度为 O(nlogn)。
◼ 综合起来,堆排序的时间复杂度为 O(nlogn)。
6.总结
堆排序是一种高效的排序算法,它利用堆这种数据结构来实现排序。
◼ 堆排序具有时间复杂度为 O(nlogn) 的优秀性能,并且由于它只使用了常数个辅助变量来存储堆的信息,因此空间复杂度为 O(1)。
◼ 但是,由于堆排序的过程是不稳定的,即相同元素的相对位置可能会发生变化,因此在某些情况下可能会导致排序结果不符合要求。
◼ 总的来说,堆排序是一种高效的、通用的排序算法,它适用于各种类型的数据,并且可以应用于大规模数据的排序。
7. 非叶子节点的推导

!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?