第十节:MySQL锁、事务隔离级别、MVCC机制详解、间隙锁、死锁等
一. 简介
可参考之前的文章:https://www.cnblogs.com/yaopengfei/p/11394728.html (用EFCore演示了事务隔离级别)
1. 锁定义
锁是计算机协调多个进程或线程并发访问某一资源的机制。
在数据库中,除了传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供需要用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素 。
2. 锁分类
(1). 从性能上:乐观锁和悲观锁。
A. 乐观锁: 通过rowversion比较数据的版本号,如果和最初数据不一致,则返回错误信息给用户,让用户决定下一步怎么办。
B. 悲观锁:修改数据前先加锁 锁定,防止其他人修改。
(2). 从对数据库操作上:读锁和写锁 (都属于悲观锁)。
A. 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
B. 写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
(3). 从对数据操作的颗粒上:表锁和行锁。
A. 表锁:每次操作锁住整张表。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 (MyISAM存储引擎)
B. 行锁:每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。(InnoDB存储引擎,行锁支持事务)
案例见下面的第二章节。
3. 事务
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性 。
原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
4. 并发事务带来的问题
(1). 更新丢失(Lost Update)
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题–最后的更新覆盖了由其他事务所做的更新。
(2). 脏读(Dirty Reads)
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致的状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此作进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象的叫做“脏读”。
一句话:事务A读取到了事务B已经修改但尚未提交的数据,还在这个数据基础上做了操作。此时,如果B事务回滚,A读取的数据无效,不符合一致性要求。
(3). 不可重复读(Non-Repeatable Reads)
一个事务内,在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
一句话:事务A读取到了事务B已经提交的修改数据,不符合隔离性。
(4). 幻读(Phantom Reads)
一个事务在未结束按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
一句话:事务A读取到了事务B提交的新增数据,不符合隔离性.
总结:
脏读是指一个事务读取到了其他事务没有提交的数据,不可重复读是指一个事务内多次根据同一个查询条件查询出来的“同一行记录的值不一样”,幻读是指一个事务内多次 根据同个条件查出来的记录行数不一样。为了解决事务并发带来的问题,才有了事务规范中的四个事务隔离级别,不同隔离级别对上面问题部分或者全部做了避免。
5. 事务隔离级别
(1).读未提交(READ_UNCOMMITTED):读未提交,该隔离级别允许脏读取,其隔离级别是最低的。换句话说,如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务, 因此还没有提交事务;而以此同时,允许另一个事务也能够访问该数据。
【引发的问题:脏读】
(2).读已提交(READ_COMMITTED) :事务执行的时候只能获取到其它事务已经提交的数据,获取不到未提交的数据。
【解决了“脏读”,但是解决不了“不可重复读”】
(3).可重复读(REPEATABLE_READ):保证在事务处理过程中,多次读取同一个数据时,该数据的值和事务开始时刻是一致的。
【解决了“脏读”和“不可重复度”,但是解决不了“幻读”】
(4).顺序读(可串行化)(SERIALIZABLE):最严格的事务隔离级别。它要求所有的事务排队顺序执行,即事务只能一个接一个地处理,不能并发。
【解决上述所有情况】
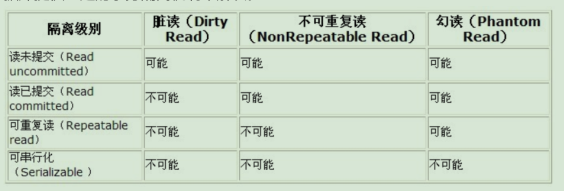
注:4 种事务隔离级别从上往下,级别越高,并发性越差,安全性就越来越高。一般数据默认级别是读已提交或可重复读。
PS:常见数据库的默认级别:
①:MySQL 数据库的默认隔离级别是 REPEATABLE_READ(可重复读) 级别。所以mysql中不会出现脏读、不可重复读,但是会出现幻读。
②:Oracle数据库中,只支持 SERIALIZABLE 和 READ_COMMITTED级别,默认的是 READ_COMMITTED 级别。
③:SQL Server 数据库中,默认的是 READ_COMMITTED(读已提交) 级别。
PS:MySQL下的指令:
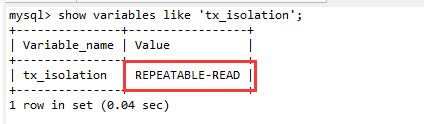
①:查看事务隔离级别
show variables like 'tx_isolation';
②:设置事务隔离级别(仅仅针对当前会话有效)
set tx_isolation='REPEATABLE-READ';
二. 实战
1. 读锁和写锁
表和数据准备(这里使用MyISAM引擎下的表级别锁)


‐‐建表SQL CREATE TABLE `mylock` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `NAME` VARCHAR (20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = MyISAM DEFAULT CHARSET = utf8; ‐‐插入数据 INSERT INTO `mylock` (`id`, `NAME`) VALUES ('1', 'a'); INSERT INTO `mylock` (`id`, `NAME`) VALUES ('2', 'b'); INSERT INTO `mylock` (`id`, `NAME`) VALUES ('3', 'c'); INSERT INTO `mylock` (`id`, `NAME`) VALUES ('4', 'd');
案例1-读锁
(1). 在会话1中给mylock表添加读锁
lock table mylock read;
(2). 分别在会话1和会话2中进行数据查询,均可查询成功。

(3). 分别在会话1和会话2中进行插入或更新操作,会话1报错,会话2等待。

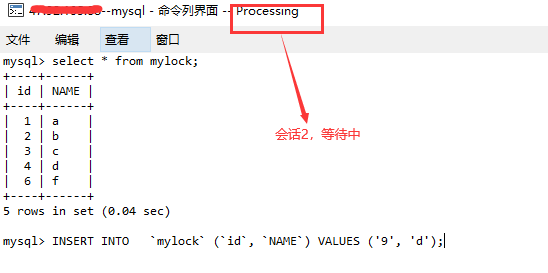
(4). 释放会话1的锁【unlock tables;】,会话2插入成功。


案例2-写锁
添加写锁的指令:
--写锁 lock table mylock write;
重复上述步骤,得出的结论:当前会话对该表的增删改查都没有问题,其他会话对该表的所有操作被阻塞。
总结:
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。
(1). 对MyISAM表的读操作(加读锁) ,不会阻寒其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。
(2). 对MylSAM表的写操作(加写锁) ,不会祖册当前进程,但会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
补充查看锁的指令:
--查看锁(In_use为1代表有锁) show open tables;
2. 读未提交
数据准备(后面案例都基于这些数据)
--创建表 CREATE TABLE `account` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `name` VARCHAR (255) DEFAULT NULL, `balance` int(255) NULL DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8; --清空表数据 truncate table `account`; --插入数据 INSERT INTO `IndexTestDB`.`account`(`name`, `balance`) VALUES ('lilei', 450); INSERT INTO `IndexTestDB`.`account`(`name`, `balance`) VALUES ('hanmei', 16000); INSERT INTO `IndexTestDB`.`account`(`name`, `balance`) VALUES ('lucy', 2400);
(1). 设置会话A的事务隔离级别为【读未提交】
set session transaction isolation level read uncommitted;
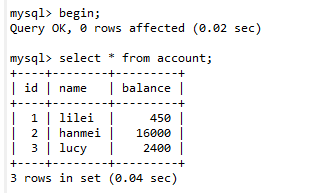
开启事务(begin),进行数据查询,如下图:
select * from account;
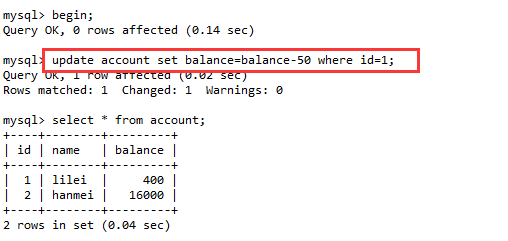
(2). 打开会话B,保持默认的事务隔离级别即可,开启事务(begin),执行一条更新操作,不提交事务。
update account set balance=balance-50 where id=1;

(3). 回到会话A,再次查询数据,发现读取到了事务B修改后的数据,但是事务B并没有提交,这就是脏读。
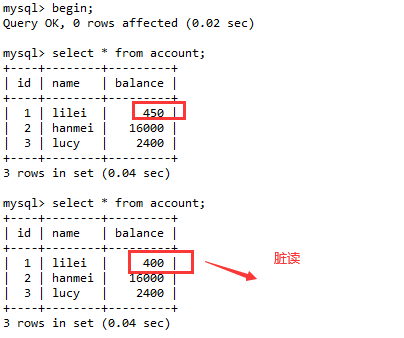
剖析:在实际应用程序中,我们会拿着400去做业务处理,即使会话B事务回滚了,应用程序也不知道。
3. 读已提交
(1). 设置会话A的事务隔离级别为【读已提交】 ,开启事务(begin),进行数据查询。
set session transaction isolation level read committed;
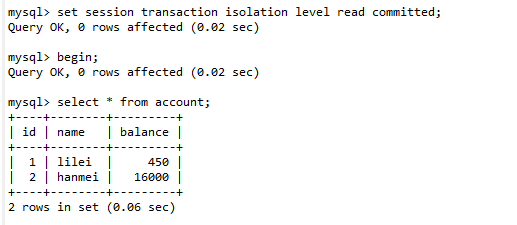
(2). 打开会话B,保持默认的事务隔离级别即可,开启事务(begin),执行一条更新操作,不提交事务。
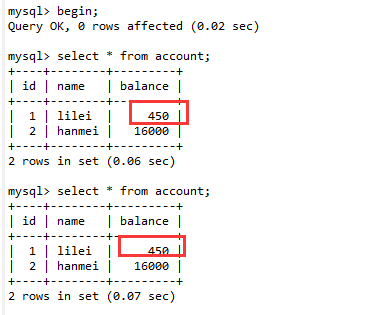
(3). 回到会话A,进行数据查询,发现查询的结果是450,而不是400,说明会话A并没有读取会话B事务没有提交的数据,解决了脏读问题。
(4). 回到会话B,进行事务提交(commit)。
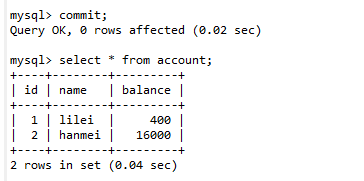
(5). 回到会话A,继续进行数据查询,发现查出来的数据是400,在同一个事务中,事务还没有结束,同样的语句查出来不同的结果值,这就是不可重复读。

4. 可重复读
(1). 设置会话A的事务隔离级别为【读已提交】 ,开启事务,进行数据查询。(或者不做任何设置,mysql的默认事务隔离级别就是读已提交)
set session transaction isolation level repeatable read;
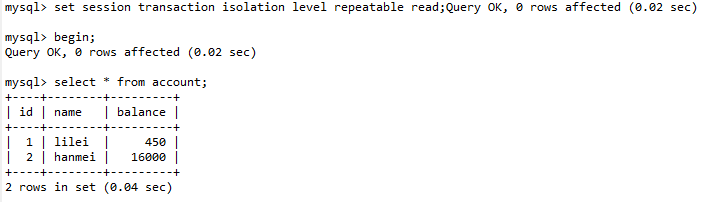
(2). 打开会话B,开启事务,更新数据,并且事务提交。
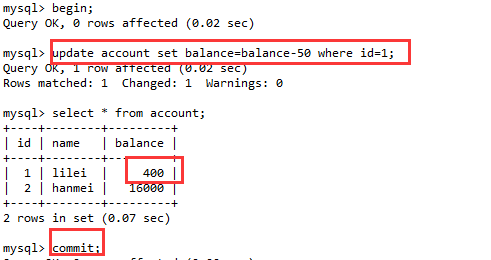
(3). 回到会话A,进行数据查询,发现查出来的结果是450,两次查询结果一致,解决了不可重复读问题。
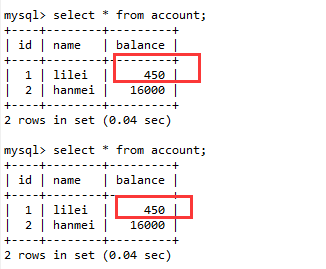
(4). 在会话A中执行更新操作,发现结果是350,而不是400,数据的一致性倒是没有被破坏,这就是MVCC机制。
可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。
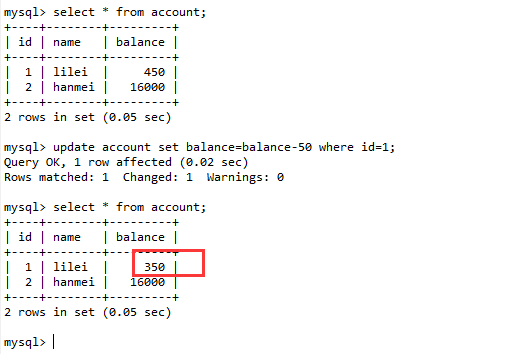
下面开始验证幻读:
(5). 重新打开会话B,开启事务,插入一条id=3的数据,提交事务。

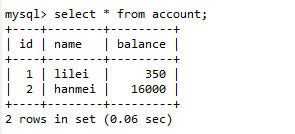
(6). 回到会话A,进行数据查询,仍然是两条数据,并没有出现幻读。
(7). 在会话A中执行对 id=3的数据的更新操作。然后进行数据查询,出现了3条数据,即多了一条id=3的数据,这就是幻读。
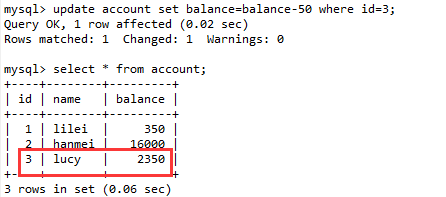
注:上述6中查不出来数据,7中更新一下查出来数据,结合下面的MVCC详解来理解这个现象。
5. 串行化
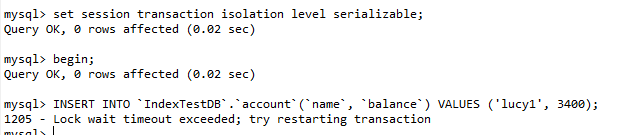
(1). 设置会话A的事务隔离级别为【串行化】 ,开启事务,进行数据查询。
set session transaction isolation level serializable;
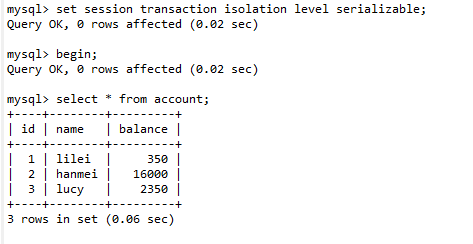
(2). 打开会话B,设置隔离级别为【串行化】,开启事务,进行数据插入操作,发现并不能插入,一直在等待,从而解决了幻读问题。(这种级别非常少用)
6. 行锁
会话A开启事务更新id=1的数据,不提交;会话B开启事务,更新id=1的数据会被阻塞,更新其他数据没问题。
PS:以前理解的脏读是不准确的,那只是并发导致的一个bug,可以认为他是更新丢失。
三. MVCC机制
1. 业务准备
开启3个事务操作accout表,然后开启两个事务进行select查询操作,如下图:

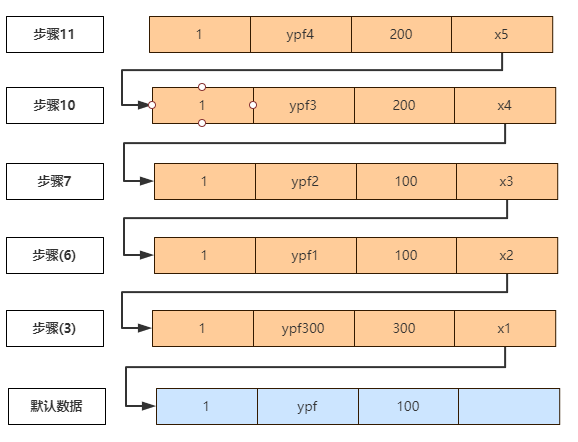
2. MVCC底层剖析
(1). 底部版本链记录 和 原理分析

(2). 分析查询事务Select1
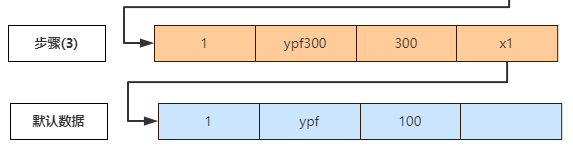
A. 步骤(5),未提交的事务id为100和200,已经提交的事务id为300,所以生成的readview为 [100,200],300,从上往下分析版本链,
① 步骤(3) trx_id=300,300属于右上图橙色范畴,且不在trx_id 的数组中,所以表示该行记录是已经提交的的事务生成的,数据是可见的,所以name=ypf300.
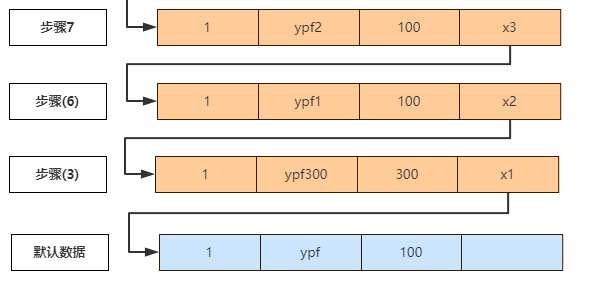
B. 步骤(8),同一个事务中readview是不变的,所以 readview为 [100,200],300,从上往下分析版本链:
① 步骤(7), trx_id=100,100在readview的数组中,表示该行记录是由还没有提交的事务生成的,所以不可见。
② 步骤(6), 同步骤(7), 数据不可见
③ 步骤(3), 上面的A中已经分析过,数据可见,所以name=ypf300
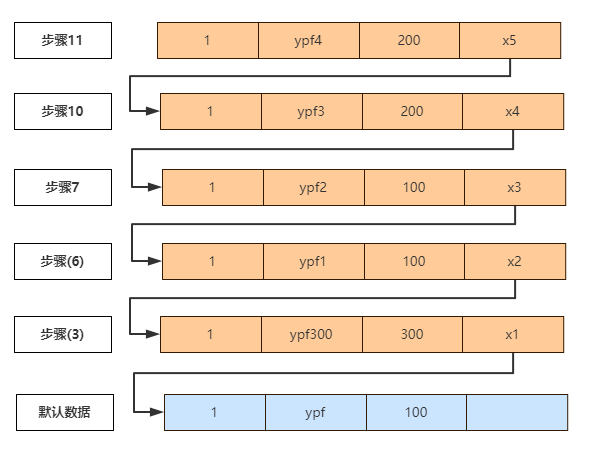
C. 步骤(12), 同一个事务中readview是不变的,所以 readview为 [100,200],300,从上往下分析版本链:
① 步骤(11), trx_id=200,200在readview的数组中,表示该行记录是由还没有提交的事务生成的,所以不可见。
② 步骤(10), 同步骤(11), 数据不可见
① 步骤(7), trx_id=100,100在readview的数组中,表示该行记录是由还没有提交的事务生成的,所以不可见。
② 步骤(6), 同步骤(7), 数据不可见
③ 步骤(3), 上面的A中已经分析过,数据可见,所以name=ypf300
(3). 分析查询事务Select12
步骤(13),未提交的事务id为200,已经提交的事务id为300,所以生成的readview为 [200],300,从上往下分析版本链,
① 步骤(11), trx_id=200, 200在readview的数组中,表示该行记录是由还没有提交的事务生成的,所以不可见。
② 步骤(10), 同步骤(11), 数据不可见
① 步骤(7), trx_id=100,100<200,属于右上图绿色范畴,表示该行记录是由已经提交的事务生成的,是可见的,所有name=ypf2。
四. 其它补充
1. 间隙锁
间隙锁在某些情况下可以解决幻读问题。
要避免幻读可以用间隙锁在会话A下面执行,则其他会话没法在这个范围所包含的间隙里插入或修改任何数据。
update account set name ='zhuge' where id > 10 and id <=20;,
2. 行锁升级表锁
(1). 锁主要是加在索引上,如果对非索引字段更新, 行锁可能会变表锁
会话A执行:
update account set balance = 800 where name = 'lilei';
(2). 会话B对该表任一行操作都会阻塞住
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。
锁定某一行还可以用lock in share mode(共享锁) 和for update(排它锁),例如:select * from test_innodb_lock where a = 2 for update; 这样其他session只能读这行数据,修改则会被阻塞,直到锁定行的session提交。
补充:行锁分析
show status like'innodb_row_lock%';
对各个状态量的说明如下:
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg: 每次等待所花平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数
对于这5个状态变量,比较重要的主要是:
Innodb_row_lock_time_avg (等待平均时长)
Innodb_row_lock_waits (等待总次数)
Innodb_row_lock_time(等待总时长)
尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手制定优化计划。
3. 死锁
会话A执行: select * from account where id=1 for update; 会话B执行: select * from account where id=2 for update; 会话A执行: select * from account where id=2 for update; 会话B执行: select * from account where id=1 for update;
PS:大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况mysql没法自动检测死锁
4. 优化建议
(1). 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
(2). 合理设计索引,尽量缩小锁的范围
(3). 尽可能减少检索条件范围,避免间隙锁
(4). 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql
(5). 尽量放在事务最后执行
(6). 尽可能低级别事务隔离
!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号