
05tensorflow分布式会话
一. tensorflow分布式
1. 概念
分布式Tensorflow是由高性能的gRPC框架作为底层技术来支持的。这是一个通信框架gRPC(google remote procedure call),是一个高性能、跨平台的RPC框架。RPC协议,即远程过程调用协议,是指通过网络从远程计算机程序上请求服务。
2. 模式
1)单机单卡 一台服务器上多台设备(GPU)
2)多机多卡(分布式)
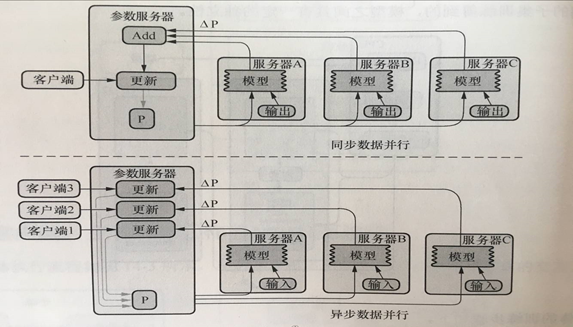
l 参数服务器(parameter server)ps:更新参数、保存参数
l 工作服务器(worker):主要功能是计算。worker节点中需要一个主节点来进行会话初始化,创建文件等操作,其他节点等待进行计算
二. API
1. 分布式会话
MonitoredTrainingSession(master=‘’,is_chief=True,checkpoint_dir=None,hooks=None,save_checkpoint_secs=600,save_summaries_steps=USE_DEFAULT,save_summaries_secs=USE_DEFAULT,config=None) 分布式会话函数
- master:指定运行会话协议IP和端口(用于分布式)
“grpc://192.168.0.1:2000”
- is_chief是否为主worker(用于分布式)
如果True,它将负责初始化和恢复基础的TensorFlow会话。如果False,
它将等待一位负责人初始化或恢复TensorFlow会话。
- checkpoint_dir:检查点文件目录,同时也是events目录
- config:会话运行的配置项, tf.ConfigProto(log_device_placement=True)
- hooks:可选SessionRunHook对象列表
生成的对象可调用的函数:
- should_stop():是否异常停止
- run():跟session一样可以运行op
2. Hook
tf.train.SessionRunHook
- Hook to extend calls to MonitoredSession.run()
- 1、begin():
- 在会话之前,做初始化工作
- 2、before_run(run_context)
在每次调用run()之前调用,以添加run()中的参数。
ARGS:
run_context:一个SessionRunContext对象,包含会话运行信息
return:一个SessionRunArgs对象,例如:tf.train.SessionRunArgs(loss)
- 3、after_run(run_context,run_values)
在每次调用run()后调用,一般用于运行之后的结果处理
该run_values参数包含所请求的操作/张量的结果 before_run()。
该run_context参数是相同的一个发送到before_run呼叫。
ARGS:
run_context:一个SessionRunContext对象
run_values一个SessionRunValues对象, run_values.results
注:在使用钩子的时候需要定义一个全局步数
global_step = tf.contrib.framework.get_or_create_global_step()
3. 创建集群
cluster = tf.train.ClusterSpec({"ps": ps_spec, "worker": worker_spec})
cluster = tf.train.ClusterSpec({
“worker”:[“worker0.example.com:2222”, /job:worker/task:0
“worker1.example.com:2222”, /job:worker/task:1
“worker2.example.com:2222”], /job:worker/task:2
"ps": [“ps0.example.com:2222”, /job:ps/task:0
“ps1.example.com:2222”] /job:ps/task:1
})
4. 创建服务
tf.train.Server(server_or_cluster_def, job_name=None, task_index=None, protocol=None, config=None, start=True) 创建服务(ps,worker)
l server_or_cluster_def: 集群描述
l job_name: 任务类型名称
l task_index: 任务数
attribute:target
返回tf.Session连接到此服务器的目标
method:join()
参数服务器端,直到服务器等待接受参数任务关闭
5. 工作节点指定设备运行
tf.device(device_name_or_function)
- 选择指定设备或者设备函数
- if device_name:
- 指定设备
- 例如:"/job:worker/task:0/cpu:0”
- if function:
- tf.train.replica_device_setter(worker_device=worker_device,cluster=cluster)
- 作用:通过此函数协调不同设备上的初始化操作
- worker_device:为指定设备,
“/job:worker/task:0/cpu:0” or"/job:worker/task:0/gpu:0"
- cluster:集群描述对象
注:使用with tf.device(),使不同工作节点工作在不同的设备上
三. 案例
1 import tensorflow as tf 2 3 FLAGS = tf.app.flags.FLAGS 4 5 tf.app.flags.DEFINE_string("job_name", " ", "启动服务的类型ps or worker") 6 tf.app.flags.DEFINE_integer("task_index", 0, "指定ps或者worker当中的那一台服务器以task:0 ,task:1") 7 8 def main(argv): 9 10 # 定义全集计数的op ,给钩子列表当中的训练步数使用 11 global_step = tf.contrib.framework.get_or_create_global_step() 12 13 # 指定集群描述对象, ps , worker 14 cluster = tf.train.ClusterSpec({"ps": ["10.211.55.3:2223"], "worker": ["192.168.65.44:2222"]}) 15 16 # 创建不同的服务, ps, worker 17 server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index) 18 19 # 根据不同服务做不同的事情 ps:去更新保存参数 worker:指定设备去运行模型计算 20 if FLAGS.job_name == "ps": 21 # 参数服务器什么都不用干,是需要等待worker传递参数 22 server.join() 23 else: 24 worker_device = "/job:worker/task:0/cpu:0/" 25 26 # 可以指定设备取运行 27 with tf.device(tf.train.replica_device_setter( 28 worker_device=worker_device, 29 cluster=cluster 30 )): 31 # 简单做一个矩阵乘法运算 32 x = tf.Variable([[1, 2, 3, 4]]) 33 w = tf.Variable([[2], [2], [2], [2]]) 34 35 mat = tf.matmul(x, w) 36 37 # 创建分布式会话 38 with tf.train.MonitoredTrainingSession( 39 master= "grpc://192.168.65.44:2222", # 指定主worker 40 is_chief= (FLAGS.task_index == 0),# 判断是否是主worker 41 config=tf.ConfigProto(log_device_placement=True),# 打印设备信息 42 hooks=[tf.train.StopAtStepHook(last_step=200)] 43 ) as mon_sess: 44 while not mon_sess.should_stop(): 45 print(mon_sess.run(mat)) 46 47 48 if __name__ == "__main__": 49 tf.app.run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号