
12scrapy_redis
一.简介
1.redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
2.github地址
https://github.com/rmax/scrapy-redis
3.为什么学习redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式。
二.爬虫过程

三.使用
1.常用命令

中文文档 http://www.redis.cn/commands.html
2.代码

3.源码
git clone https://github.com/rolando/scrapy-redis.git
三.源码
1.domz


执行domz的爬虫,会发现redis中多了一下三个键:
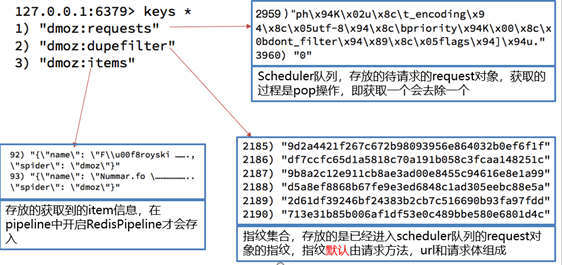
变化结果:
dmoz:requests 有变化(变多或者变少或者不变)
dmoz:dupefilter 变多
dmoz:items 不变
变化结果分析:
redispipeline中仅仅实现了item数据存储到redis的过程,我们可以新建一个pipeline(或者修改默认的ExamplePipeline),让数据存储到任意地方
2.RedisPipeline

3. RFPDupeFilter

4. Scheduler

四.在项目中使用
1.RedisSpider


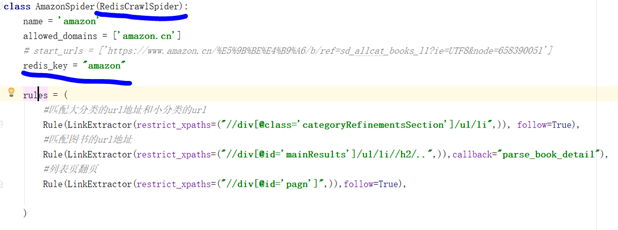
2. RedisCrawlSpider

五. Crontab爬虫定时执行
1.安装及介绍

2.执行步骤

