03pandas
一.pandas简述
1)pandas是一个开源的,BSD许可的库,为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
2)numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
二.pandas的数据类型
1.Series
1)Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
l 类似一维数组的对象
l 由数据和索引组成
² 索引(index)在左,数据(values)在右
² 索引是自动创建的
2)创建
ser_obj = pd.Series(np.arange(10),index=list(string.ascii_uppercase[:10]))

3)切片和索引
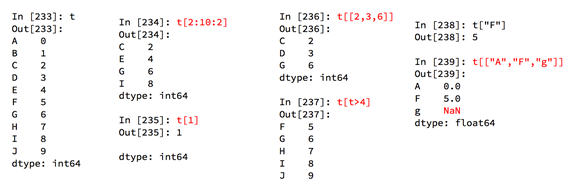
切片:直接传入strat end或步长即可
索引:一个的时候直接传入序号或者index,多个的时候传入序号或者index的列表
4)索引和值
l 获取索引 t.index
l 获取值 t.values

2.DataFrame
2.1简介
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
l 类似多维数组/表格数据 (如,excel, R中的data.frame)
l 每列数据可以是不同的类型
l 索引包括列索引和行索引
2.2操作
- 通过ndarray构建DataFrame
代码:
import numpy as np # 通过ndarray构建DataFrame array = np.random.randn(5,4) print(array) df_obj = pd.DataFrame(array) print(df_obj.head())
输出:
[[0.83500594-1.49290138-0.53120106-0.11313932]
[0.64629762-0.367799410.080110840.60080495]
[-1.234585220.33409674-0.58778195-0.73610573]
[-1.476514140.994001870.21001995-0.90515656]
[0.566694191.38238348-0.490990071.94484598]]
0123
00.835006-1.492901-0.531201-0.113139
10.646298-0.3677990.0801110.600805
2-1.2345850.334097-0.587782-0.736106
3-1.4765140.9940020.210020-0.905157
40.5666941.382383-0.4909901.944846
2.通过dict构建dataframe
代码:
# 通过dict构建DataFrame dict_data = {'A': 1, 'B': pd.Timestamp('20170426'), 'C': pd.Series(1, index=list(range(4)),dtype='float32'), 'D': np.array([3] * 4,dtype='int32'), 'E': ["Python","Java","C++","C"], 'F': 'ITCast' } #print dict_data df_obj2 = pd.DataFrame(dict_data) print(df_obj2)
输出:
A B C D E F012017-04-261.03Python ITCast
112017-04-261.03Java ITCast
212017-04-261.03C++ ITCast
312017-04-261.03C ITCas
3.通过列索引获取列数据(Series类型)
df_obj[col_idx] 或 df_obj.col_idx
4.增加列数据
df_obj[new_col_idx] = data
5.删除列
del df_obj[col_idx]
2.3基础属性

2.4整体情况查询

2.5排序
df.sort_values(by="Count_AnimalName",ascending=False)
ascending参数默认为true,即升序排列
2.6取行、取列
1)取某一列df[" Count_AnimalName "]
2)取行取列df[:100][" Count_AnimalName "]
2.7 loc取行取列
1) df.loc 通过标签索引行数据
2) df.iloc 通过位置获取行数据

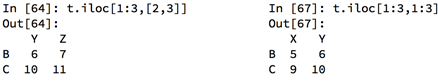
赋值更改数据:

2.8布尔索引
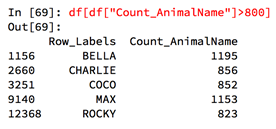
2.9字符串方法

三.数据处理
1) 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
2) 处理缺失数据
l 方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
l 方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
3) 处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
四.数据合并
1.join
默认情况下他是把行索引相同的数据合并到一起

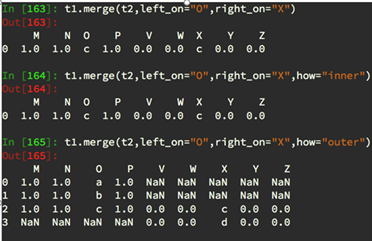
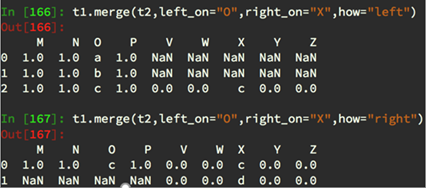
2.merge
按照指定的列把数据按照一定的方式合并到一起
1) 默认的合并方式inner,并集
2) merge outer,交集,NaN补全
3) merge left,左边为准,NaN补全
4) merge right,右边为准,NaN补全
五.分组和聚合
1)groupby方法
grouped = df.groupby(by="columns_name")
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组
元组里面是(索引(分组的值),分组之后的DataFrame)
2)DataFrameGroupBy对象有很多经过优化的方法

六.索引和复合索引
简单的索引操作:
l 获取index:df.index
l 指定index :df.index = ['x','y']
l 重新设置index : df.reindex(list("abcedf"))
l 指定某一列作为index :df.set_index("Country",drop=False)
l 返回index的唯一值:df.set_index("Country").index.unique()

七.时间序列
1.使用
pd.date_range(start=起始时间, end=“”, periods=生成个数, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
2.关于freq频率的更多缩写

3. 使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
4.重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
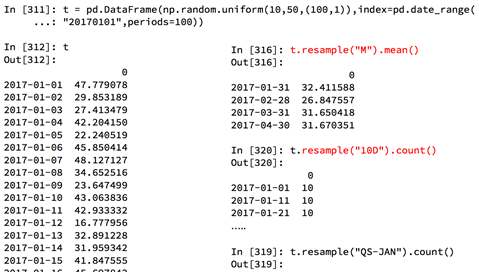
pandas提供了一个resample的方法来帮助我们实现频率转化
5.periodIndex
periods=pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H")
之前所学习的DatetimeIndex可以理解为时间戳,那么现在我们要学习的PeriodIndex可以理解为时间段。
七.数据重构
1.stack
l 将行索引转换为列索引,完成层级索引
l DataFrame->Seriees
示例代码:
import numpy as np import pandas as pd df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2']) print(df_obj) stacked = df_obj.stack() print(stacked)
运行结果:
# print(df_obj) data1 data2 0 7 9 1 7 8 2 8 9 3 4 1 4 1 2 # print(stacked) 0 data1 7 data2 9 1 data1 7 data2 8 2 data1 8 data2 9 3 data1 4 data2 1 4 data1 1 data2 2 dtype: int64
2. unstack
l 将层级索引展开
l Series->DataFrame
l 认操作内层索引,即level=-1
示例代码:
# 默认操作内层索引 print(stacked.unstack()) # 通过level指定操作索引的级别 print(stacked.unstack(level=0))
运行结果:
# print(stacked.unstack()) data1 data2 0 7 9 1 7 8 2 8 9 3 4 1 4 1 2 # print(stacked.unstack(level=0)) 0 1 2 3 4 data1 7 7 8 4 1 data2 9 8 9 1 2
八.数据转换
1.处理重复数据
1) duplicated() 返回布尔型Series表示每行是否为重复行
2) drop_duplicates() 过滤重复行
l 默认判断全部列 df_obj.drop_duplicates()
l 可指定按某些列判断 df_obj.drop_duplicates('data2')
2.数据替换
replace根据值的内容进行替换
示例代码:
# 单个值替换单个值 print(ser_obj.replace(1, -100)) # 多个值替换一个值 print(ser_obj.replace([6, 8], -100)) # 多个值替换多个值 print(ser_obj.replace([4, 7], [-100, -200]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号