
11scrapy
一. Scrapy基础概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。Scrapy 使用了 Twisted异步网络框架,可以加快我们的下载速度。
二. 操作
1. 基本操作
1)创建一个scrapy项目
scrapy startproject mySpider
2)生成一个爬虫
scrapy genspider itcast "itcast.cn”
3)提取数据
完善spider,使用xpath等方法
4)保存数据
pipeline中保存数据
2. 完善spdier


3. spdier数据传到pipeline


4. 使用·pipeline

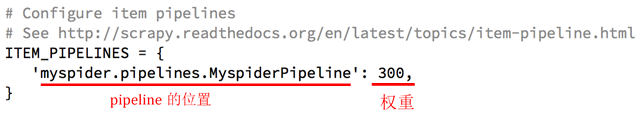
5. 设置log
为了让我们自己希望输出到终端的内容能容易看一些:
我们可以在setting中设置log级别
在setting中添加一行(全部大写):LOG_LEVEL = "WARNING”
默认终端显示的是debug级别的log信息
三. 实行翻页操作
1. 获取地址,使用scrapy.Request方法

需要传递数据时,可以在方法中传递meta:
yield scrapy.Request(next_page_url,callback=self.parse,meta=…)
dont_filter:让scrapy不会过滤当前url
四. 定义Item
1. 方法

2. 实例


3. 在不同的解析函数中传递参数
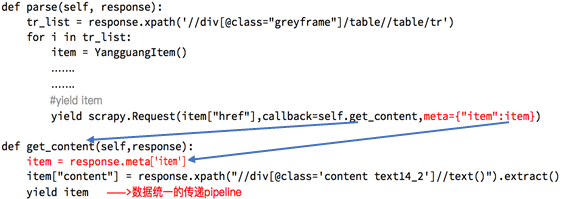
五. 深入pipeline

可以将一些需要初始化的数值添加在open_spider方法中
而close_spider可以做一些收尾工作
六. CrawlSpider
1. 功能
1)我们把满足某个条件的url地址传给rules,同时能够指定callback函数。不需要手动去找下一页的url地址,达到简化代码的目的
2)生成CrawlSpider的命令
scrapy genspider –t crawl 项目名 “域名”
2. 实例
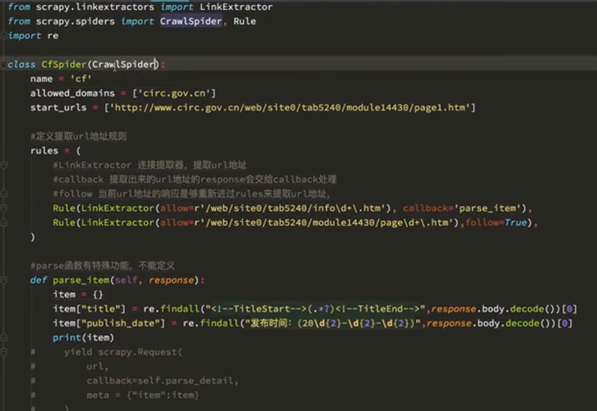
rules内的几个参数:
1) LinkExtractor 连接提取器,提取url地址
2) callback 提取出来的url地址的response会交给callback来处理
3) follow 当前url地址的响应是否重新进rules来提取url地址
3. 注意点

七. Scrapy模拟登录
1. 携带cookie登录
1)直接携带cookie,在浏览器登录之后获取检查里边cookies的值
2)找到发送post请求的url地址,带上信息,发送请求
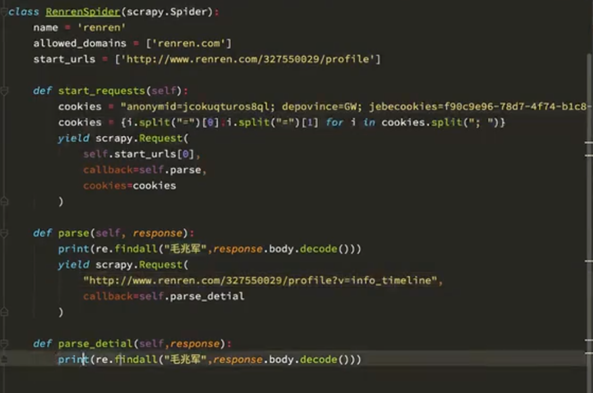
可以在settings里边添加参数【COOKIES_DEBUG=True】观察cookies的传递过程。
不能把cookies放在headers中
2. 使用FormRequest
1) scrapy.FormRequest(url,formdata={},callback) formdata请求体
2) formdata里边的数据,可以试着在浏览器输入用户名和密码之后,在session的Headers里边找到formdata,接着在Elements中查找对应的组件

3)示例

3. 自动寻找Form表单中action的url
1) scrapy.FormRequest.from_response(response,formdata={},callback)
2) 示例

八. 案例分析
1. 贴吧爬虫
1.1 补充不完整的链接
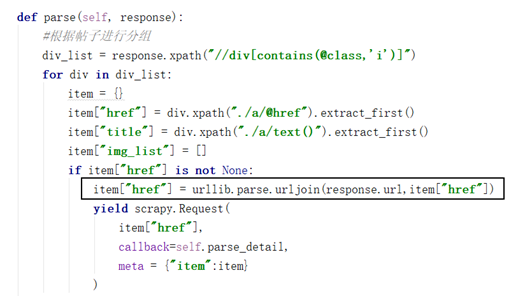
注意:需要导入import urllib
通过urljoin方法自动把链接补全
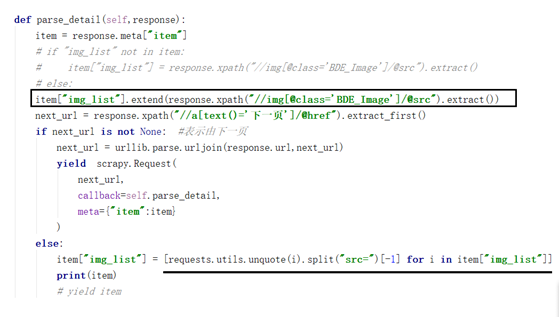
1.2 对图片解码以及翻页时处理内容覆盖的问题
1) 图片解码:需要import requests
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
2) 翻页使用extend()来处理
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
1.3 spider下的tb.py完整代码
import scrapy import urllib import requests class TbSpider(scrapy.Spider): name = 'tb' allowed_domains = ['tieba.baidu.com'] start_urls = ['http://tieba.baidu.com/mo/q----,sz@320_240-1-3---2/m?kw=%E6%9D%8E%E6%AF%85&lp=9001'] def parse(self, response): #根据帖子进行分组 div_list = response.xpath("//div[contains(@class,'i')]") for div in div_list: item = {} item["href"] = div.xpath("./a/@href").extract_first() item["title"] = div.xpath("./a/text()").extract_first() item["img_list"] = [] if item["href"] is not None: item["href"] = urllib.parse.urljoin(response.url,item["href"]) yield scrapy.Request( item["href"], callback=self.parse_detail, meta = {"item":item} ) #列表页的翻页 next_url = response.xpath("//a[text()='下一页']/@href").extract_first() if next_url is not None: next_url = urllib.parse.urljoin(response.url,next_url) yield scrapy.Request( next_url, callback=self.parse, ) def parse_detail(self,response): item = response.meta["item"] # if "img_list" not in item: #item["img_list"] = response.xpath("//img[@class='BDE_Image']/@src").extract() # else: item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract()) next_url = response.xpath("//a[text()='下一页']/@href").extract_first() if next_url is not None: #表示由下一页 next_url = urllib.parse.urljoin(response.url,next_url) yield scrapy.Request( next_url, callback=self.parse_detail, meta={"item":item} ) else: item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]] print(item) # yield item
