
07爬虫相关
一. http/https相关知识
1. http与https
1)HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
2)HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
3)SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
2. get与post
1)GET是从服务器上获取数据,POST是向服务器传送数据
2)GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,即“Get”请求的参数是URL的一部分。 例如: http://www.baidu.com/s?wd=Chinese
3)POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
注意:避免使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。
3. Cookie和Session
1) Cookie:通过在 客户端 记录的信息确定用户的身份。
2) Session:通过在 服务器端 记录的信息确定用户的身份
4. 响应状态码

二. Requests使用
1. 最基本的GET请求可以直接用get方法
response = requests.get("http://www.baidu.com/")
也可以这么写
response = requests.request("get", "http://www.baidu.com/")
2. 添加 headers 和 查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests kw = {'wd':'长城'} headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode() response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers) # 查看响应内容,response.text 返回的是Unicode格式的数据 print (response.text) # 查看响应内容,response.content返回的字节流数据 print (respones.content) # 查看完整url地址 print (response.url) # 查看响应头部字符编码 print (response.encoding) # 查看响应码 print (response.status_code)
3. 最基本post方法
response = requests.post("http://www.baidu.com/", data = data)
import requests formdata = { "type":"AUTO", "i":"i love python", "doctype":"json", "xmlVersion":"1.8", "keyfrom":"fanyi.web", "ue":"UTF-8", "action":"FY_BY_ENTER", "typoResult":"true" } url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"} response = requests.post(url, data = formdata, headers = headers) print (response.text) # 如果是json文件可以直接显示 print (response.json())
4. 代理
import requests # 根据协议类型,选择不同的代理 proxies = { "http": "http://12.34.56.79:9527", "https": "http://12.34.56.79:9527", } response = requests.get("http://www.baidu.com", proxies = proxies) print response.text
5. 处理HTTPS请求 SSL证书验证
1)要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写)
import requests response = requests.get("https://www.baidu.com/", verify=True) # 也可以省略不写 # response = requests.get("https://www.baidu.com/") print (r.text)
2)如果我们想跳过 SSL证书验证,把 verify 设置为 False 就可以正常请求了。
r = requests.get("https://www.12306.cn/mormhweb/", verify = False)
三. 免费代理ip
1) 西刺免费代理IP: https://www.xicidaili.com/
2) 快代理免费代理: https://www.kuaidaili.com/free/inha/
3) 全网代理IP: http://www.goubanjia.com/
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站
import urllib.request import random proxy_list = [ {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"}, {"http" : "124.88.67.81:80"} ] # 随机选择一个代理 proxy = random.choice(proxy_list) # 使用选择的代理构建代理处理器对象 httpproxy_handler = urllib.request.ProxyHandler(proxy) opener = urllib.request.build_opener(httpproxy_handler) request = urllib.request.Request("http://www.baidu.com/") response = opener.open(request) print (response.read())
但是,这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
四. XPath
1. 概念
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
2. 选取节点

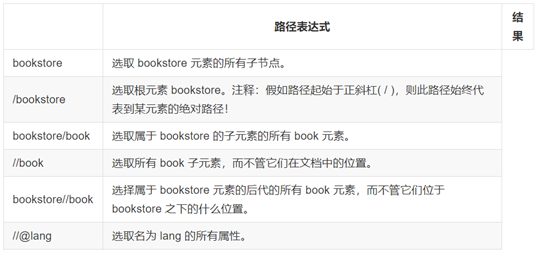
3. 谓语
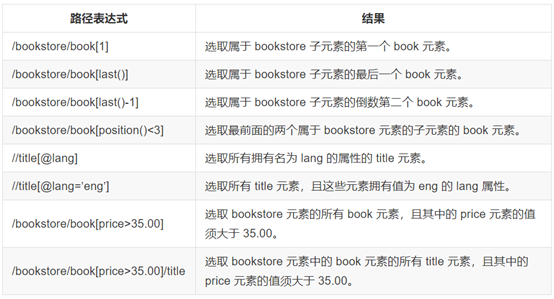
4. 选取未知节点
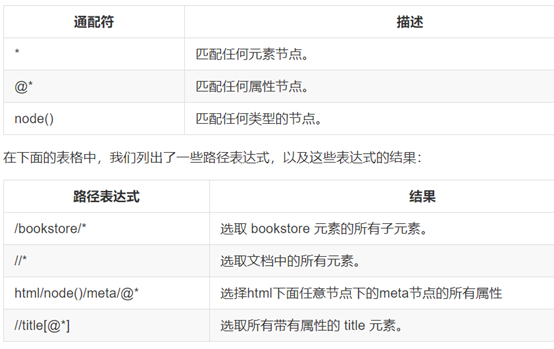
5. 选取若干路径

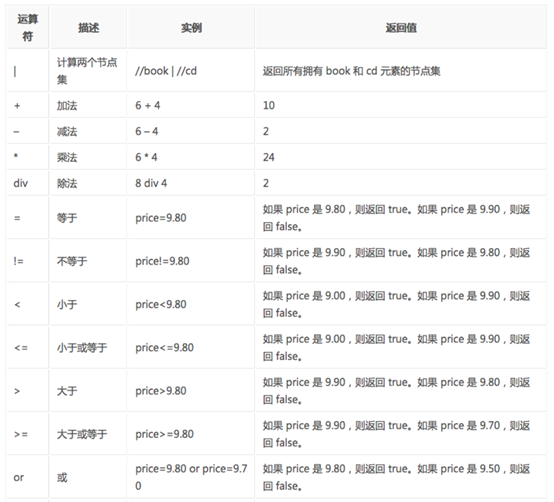
6. XPath运算符
在XPath里边可以用的运算符

五. lxml
1. 解析和提取 HTML/XML 数据
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
# lxml_test.py # 使用 lxml 的 etree 库 from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签 </ul> </div> ''' #利用etree.HTML,将字符串解析为HTML文档 html = etree.HTML(text) # 按字符串序列化HTML文档 result = etree.tostring(html) print(result)
输出结果:
<html> <body> <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> </body> </html>
lxml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签
2. 读取文件
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html --> <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div>
再利用 etree.parse() 方法来读取文件。
# lxml_parse.py from lxml import etree # 读取外部文件 hello.html html = etree.parse('./hello.html') result = etree.tostring(html, pretty_print=True) print(result)
输出结果与之前相同
3. 运用
获取<li> 标签的所有 class属性
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/@class') print result
结果:
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
六. 利用JSON爬虫
1. import json
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
2. json.loads()
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
import json strList = '[1, 2, 3, 4]' strDict = '{"city": "北京", "name": "大猫"}' json.loads(strList) # [1, 2, 3, 4] json.loads(strDict) # json数据自动按Unicode存储 # {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
3. json.dumps()
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串。
从python原始类型向json类型的转化对照如下:

注意:json.dumps() 序列化时默认使用的ascii编码;添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
import json import chardet listStr = [1, 2, 3, 4] tupleStr = (1, 2, 3, 4) dictStr = {"city": "北京", "name": "大刘"} print json.dumps(dictStr, ensure_ascii=False) # {"city": "北京", "name": "大刘"}
4. json.dump()
将Python内置类型序列化为json对象后写入文件
import json listStr = [{"city": "北京"}, {"name": "大刘"}] json.dump(listStr, open("listStr.json","w"), ensure_ascii=False) dictStr = {"city": "北京", "name": "大刘"} json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
5. json.load()
读取文件中json形式的字符串元素 转化成python类型
# json_load.py import json strList = json.load(open("listStr.json")) print strList # [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}] strDict = json.load(open("dictStr.json")) print strDict # {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
七. 实现爬虫的套路
1. 准备url
1)准备start_url
2)url地址规律不明显,总数不确定
3)通过代码提取下一页的url
- 3.1 xpath
- 3.2寻找url地址,部分参数在当前的响应中(比如,当前页码数和总的页码数在当前的响应中)
4)准备url_list
5)页码总数明确
6)url地址规律明显
2. 发送请求,获取响应
1)添加随机的User-Agent,反反爬虫
2)添加随机的代理ip,反反爬虫
3)在对方判断出我们是爬虫之后,应该添加更多的headers字段,包括cookie
4)cookie的处理可以使用session来解决
5)准备一堆能用的cookie,组成cookie池
6)如果不登录
6.1准备刚开始能够成功请求对方网站的cookie,即接收对方网站设置在response的cookie
6.2 下一次请求的时候,使用之前的列表中的cookie来请求
7)如果登录
- 7.1 准备多个账号
- 7.2 使用程序获取每个账号的cookie
- 7.3 之后请求登录之后才能访问的网站随机的选择cookie
3. 提取数据
1)确定数据的位置
2)如果数据在当前的url地址中
- 提取的是列表页的数据
- 直接请求列表页的url地址,不用进入详情页
- 提取的是详情页的数据
- 确定url
- 发送请求
- 提取数据
- 返回
八. 多线程爬虫
# coding=utf-8 import requests from lxml import etree import json from queue import Queue import threading class Qiubai: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWeb\ Kit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"} self.url_queue = Queue() #实例化三个队列,用来存放内容 self.html_queue =Queue() self.content_queue = Queue() def get_total_url(self): ''' 获取了所有的页面url,并且返回urllist return :list ''' url_temp = 'https://www.qiushibaike.com/8hr/page/{}/' url_list = [] for i in range(1,36): self.url_queue.put(url_temp.format(i)) def parse_url(self): ''' 一个发送请求,获取响应,同时etree处理html ''' while self.url_queue.not_empty: url = self.url_queue.get() print("parsing url:",url) response = requests.get(url,headers=self.headers,timeout=10) #发送请求 html = response.content.decode() #获取html字符串 html = etree.HTML(html) #获取element 类型的html self.html_queue.put(html) self.url_queue.task_done() def get_content(self): ''' :param url: :return: 一个list,包含一个url对应页面的所有段子的所有内容的列表 ''' while self.html_queue.not_empty: html = self.html_queue.get() total_div = html.xpath('//div[@class="article block untagged mb15"]') #返回divelememtn的一个列表 items = [] for i in total_div: #遍历div标枪,获取糗事百科每条的内容的全部信息 author_img = i.xpath('./div[@class="author clearfix"]/a[1]/img/@src') author_img = "https:" + author_img[0] if len(author_img) > 0 else None author_name = i.xpath('./div[@class="author clearfix"]/a[2]/h2/text()') author_name = author_name[0] if len(author_name) > 0 else None item = dict( author_name=author_name, author_img=author_img ) items.append(item) self.content_queue.put(items) self.html_queue.task_done() #task_done的时候,队列计数减一 def save_items(self): ''' 保存items :param items:列表 ''' while self.content_queue.not_empty: items = self.content_queue.get() f = open("qiubai.txt","a") for i in items: json.dump(i,f,ensure_ascii=False,indent=2) # f.write(json.dumps(i)) f.close() self.content_queue.task_done() def run(self): # 1.获取url list # url_list = self.get_total_url() thread_list = [] thread_url = threading.Thread(target=self.get_total_url) thread_list.append(thread_url) #发送网络请求 for i in range(10): thread_parse = threading.Thread(target=self.parse_url) thread_list.append(thread_parse) #提取数据 thread_get_content = threading.Thread(target=self.get_content) thread_list.append(thread_get_content) #保存 thread_save = threading.Thread(target=self.save_items) thread_list.append(thread_save) for t in thread_list: t.setDaemon(True) #为每个进程设置为后台进程,效果是主进程退出子进程也会退出 t.start() #为了解决程序结束无法退出的问题 # # for t in thread_list: # t.join() self.url_queue.join() #让主线程等待,所有的队列为空的时候才能退出 self.html_queue.join() self.content_queue.join() if __name__ == "__main__": qiubai = Qiubai() qiubai.run()
九. Selenium与PhantomJS
1. Selenium
1)Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
2)Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。
2. PhantomJS
1) PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
2) 如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
3. 快速入门
1) 导包
from selenium import webdriver # 调用键盘按键操作时需要引入的Keys包 from selenium.webdriver.common.keys import Keys
2) 调用环境变量指定的PhantomJS浏览器创建浏览器对象
- driver = webdriver.PhantomJS()
3) 访问页面
- driver.get("http://www.baidu.com/")
4) 截图
- driver.save_screenshot("baidu.png")
5) 在百度搜索框写入文字
- driver.find_element_by_id("kw").send_keys(u"长城")
6)百度搜索按钮,click() 是模拟点击
- driver.find_element_by_id("su").click()
7)ctrl+a 全选输入框内容
- driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
8)模拟Enter回车键
- driver.find_element_by_id("su").send_keys(Keys.RETURN)
9)页面前进和后退
driver.forward()#前进
driver.back()# 后退
10) 清除输入框内容
- driver.find_element_by_id("kw").clear()
11)关闭页面或关闭浏览器
- 关闭页面:driver.close()
- 关闭浏览器:driver.quit()
4. selenium使用的注意点
1)获取文本和获取属性:先定位到元素,然后调用`.text`或者`get_attribute`方法来去
2)selenium获取的页面数据是浏览器中elements的内容
3)find_element和find_elements的区别
- find_element返回一个element,如果没有会报错
- find_elements返回一个列表,没有就是空列表
- 在判断是否有下一页的时候,使用find_elements来根据结果的列表长度来判断
4) 如果页面中含有iframe、frame,需要先调用driver.switch_to.frame的方法切换到frame中才能定位元素
5) selenium请求第一页的时候回等待页面加载完了之后在获取数据,但是在点击翻页之后,hi直接获取数据,此时可能会报错,因为数据还没有加载出来,需要time.sleep(3)
6)selenium中find_element_by_class_name智能接收一个class对应的一个值,不能传入多个
十. 验证码识别
1. url不变,验证码不变
请求验证码的地址,获得相应,识别
2. url不变,验证码会变
思路:对方服务器返回验证码的时候,会和每个用户的信息和验证码进行一个对应,之后,在用户发送post请求的时候,会对比post请求中法的验证码和当前用户真正的存储在服务器端的验证码是否相同
1) 实例化session
2) 使用seesion请求登录页面,获取验证码的地址
3) 使用session请求验证码,识别
4) 使用session发送post请求’
3. 使用selenium登录,遇到验证码
1)url不变,验证码不变,同上
2)url不变,验证码会变
- selenium请求登录页面,同时拿到验证码的地址
- 获取登录页面中driver中的cookie,交给requests模块发送验证码的请求,识别
- 输入验证码,点击登录
