

五、kubernetes的资源对象之pod基础
一、应用容器与Pod资源
OS: root@harbor:~# cat /etc/issue Ubuntu 20.04.2 LTS \n \l root@harbor:~# uname -r 5.4.0-81-generic IP分配: 172.168.33.201 harbor.ywx.net k8s-deploy 172.168.33.202 haproxy01 172.168.33.203 haproxy02 172.168.33.204 ecd01 172.168.33.205 ecd02 172.168.33.206 ecd03 172.168.33.207 k8s-master01 172.168.33.208 k8s-master02 172.168.33.209 k8s-master03 172.168.33.210 k8s-node01 172.168.33.211 k8s-node02 172.168.33.212 k8s-node03 VIP: 172.168.33.50 api-server的VIP 172.168.33.51 172.168.33.52 172.168.33.53 Kubernetes: v1.21.5 root@k8s-master01:/usr/local/src# kubectl get nodes NAME STATUS ROLES AGE VERSION 172.168.33.207 Ready,SchedulingDisabled master 7d23h v1.21.5 172.168.33.208 Ready,SchedulingDisabled master 7d23h v1.21.5 172.168.33.209 Ready,SchedulingDisabled master 7d23h v1.21.5 172.168.33.210 Ready node 7d23h v1.21.5 172.168.33.211 Ready node 7d23h v1.21.5 172.168.33.212 Ready node 7d23h v1.21.5
kubernetes集群部署:
https://www.cnblogs.com/yaokaka/p/15308917.html
kubernetes集群升级:
1、什么是pod
Kubernetes是分布式运行于多个主机之上、负责运行及管理应用程序的“云操作系统”或“云原生应用操作系统”,它将Pod作为运行应用的最小化组件和基础调度单元。因而Pod是Kubernetes资源对象模型中可由用户创建或部署的最小化应用组件,而大多数其他API资源基本都是负责支撑和扩展Pod功能的组件。
https://kubernetes.io/zh/docs/concepts/workloads/pods/
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod (就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个)
说明: 除了 Docker 之外,Kubernetes 支持 很多其他容器运行时, Docker 是最有名的运行时, 使用 Docker 的术语来描述 Pod 会很有帮助。
Pod 的共享上下文包括一组 Linux 名字空间、控制组(cgroup)和可能一些其他的隔离 方面,即用来隔离 Docker 容器的技术。 在 Pod 的上下文中,每个独立的应用可能会进一步实施隔离。
就 Docker 概念的术语而言,Pod 类似于共享名字空间和文件系统卷的一组 Docker 容器。
简单来说:
Pod是Kubernetes创建和管理的最小单元,一个Pod由一个容器或多个容器组成,这些容器共享存储、网络。
2、Pod资源基础
现代应用容器技术用来运行单个进程(包括子进程),它在容器中PID名称空间中的进程号为1(及在容器中为父进程),可直接接收并处理信号,因而该进程终止也将导致容器终止并退出。这种设计使得容器与内部进程具有共同的生命周期,更容易发现和判定故障,也更利于对单个应用程序按需求进行扩容和缩容。单进程容器可将应用日志直接送往标准输出(STDOUT)和标准错误(STDERR),有利于让容器引擎及容器编排工具获取、存储和管理。
单进程模型的应用容器显然不利于有IPC通信等需求的多个具有强耦合关系的进程间的协同,除非在组织这类容器时人为地让它们运行于同一内核之上共享IPC名称空间。于是,跨多个主机运行的容器编排系统需要能够描述这种容器间的强耦合关系,并确保它们始终能够被调度至集群中的同一个节点之上。
配置容器运行时工具(例如Docker CLI)来控制容器组内各容器之间的共享级别:首先创建一个基础容器作为父容器,而后使用必要的命令选项来创建与父容器共享指定环境的新容器,并管理好这些容器的生命周期即可。Kubernetes使用名为pause的容器作为Pod中所有容器的父容器来支撑这种构想,因而也被称为Pod的基础架构容器。若用户为Pod启用了PID名称空间共享功能,pause容器还能够作为同一Pod的各容器的1号PID进程以回收僵尸进程。不过,Kubernetes默认不会为Pod内的各容器共享PID名称空间,它依赖于用户的显式定。
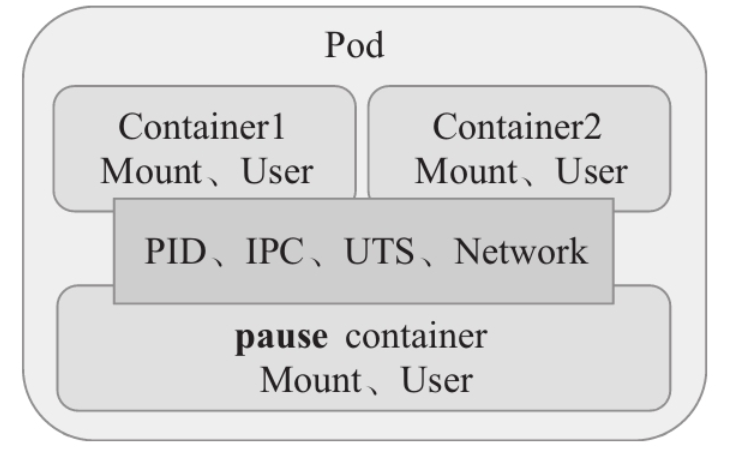
Pod内的容器共享PID、Network、IPC和UTS名称空间
PID命名空间 不同用户的进程就是通过pid命名空间隔离开的,且不同命名空间中可以有相同pid。所有的 LXC进程在Docker中的父进程为Docker进程,每个LXC进程具有不同的命名空间。同时由 允许嵌套,因此可以很方便的实现嵌套的Docker容器。 Network命名空间 有了pid命名空间,每个命名空间中的pid能够相互隔离,但是网络端口还是共享host的端口。网络隔离是通过net命名空间实现的,每个net命名空间有独立的网络设备,IP地址, 路由表,/proc/net目录。这样每个容器的网络就能隔离开来。Docker默认采用veth的方式,将容器中的虚拟网卡同host上的一个Docker网桥docker0连接在一起。 IPC命名空间 容器中进程交互还是采用了Linux常见的进程间交互方法(interprocess communication - IPC), 包括信号量、消息队列和共享内存等。然而同VM不同的是,容器的进程间交互实际上还是host上具有相同pid命名空间中的进程间交互,因此需要在IPC资源申请时加入命名空间信息,每个IPC资源有一个唯一的32位id。 UTS 命名空间 UTS("UNIX Time-sharing System")命名空间允许每个容器拥有独立的hostname和domain name,使其在网络上可以被视作一个独立的节点而非主机上的一个进程。
例如:业务应用和数据库系统就应该分别放在不同的Pod中,虽然它们之间存在通信,但并不是强耦合关系。将其分别放入不同的Pod中,两个不同的Pod会被调度到不同的Node节点,能更好的利用分布于集群中的计算资源和存储资源。
3、Pod中容器的模式
1)单容器模式
单容器模式为:将应用程序封装为应用容器运行。
2)单节点多容器模式
单节点多容器模式:是指跨容器的设计模式,其目的是在单个主机之上同时运行多个共生关系的容器,因而容器管理系统需要将它们作为一个原子单位进行统一调度。Kubernetes编排系统设计的Pod概念就是这个设计模式的实现之一。一个Pod中的所有容器会被调度到同一个node节点上。
若多个容器间存在强耦合关系,它们具有完全相同的生命周期,或者必须运行于同一节点之上时,通常应该将它们置于同一个Pod中,较常见的情况是为主容器并行运行一个助理式管理进程。单节点多容器模式的常见实现有Sidecar(边车)、适配器(Adapter)、大使(Ambassador)、初始化(Initializer)容器模式等。
4、Pod的生命周期
Pod对象从创建开始至终止退出之间的时间称为其生命周期,这段时间里的某个时间点,Pod会处于某个特定的运行阶段或相位(phase),以概括描述其在生命周期中所处的位置。Kubernetes为Pod资源严格定义了5种相位,并将特定Pod对象的当前相位存储在其内部的子对象PodStatus的phase字段上,因而它总是应该处于其生命进程中以下几个相位之一。
▪Pending:API Server创建了Pod资源对象并已存入etcd中,但它尚未被调度完成,或仍处于从仓库中下载容器镜像的过程中。
▪Running:Pod已经被调度至某节点,所有容器都已经被kubelet创建完成,且至少有一个容器处于启动、重启或运行过程中。
▪Succeeded:Pod中的所有容器都已经成功终止且不会再重启。
▪Failed:所有容器都已经终止,但至少有一个容器终止失败,即容器以非0状态码退出或已经被系统终止。
▪Unknown:API Server无法正常获取到Pod对象的状态信息,通常是由于其无法与所在工作节点的kubelet通信所致。
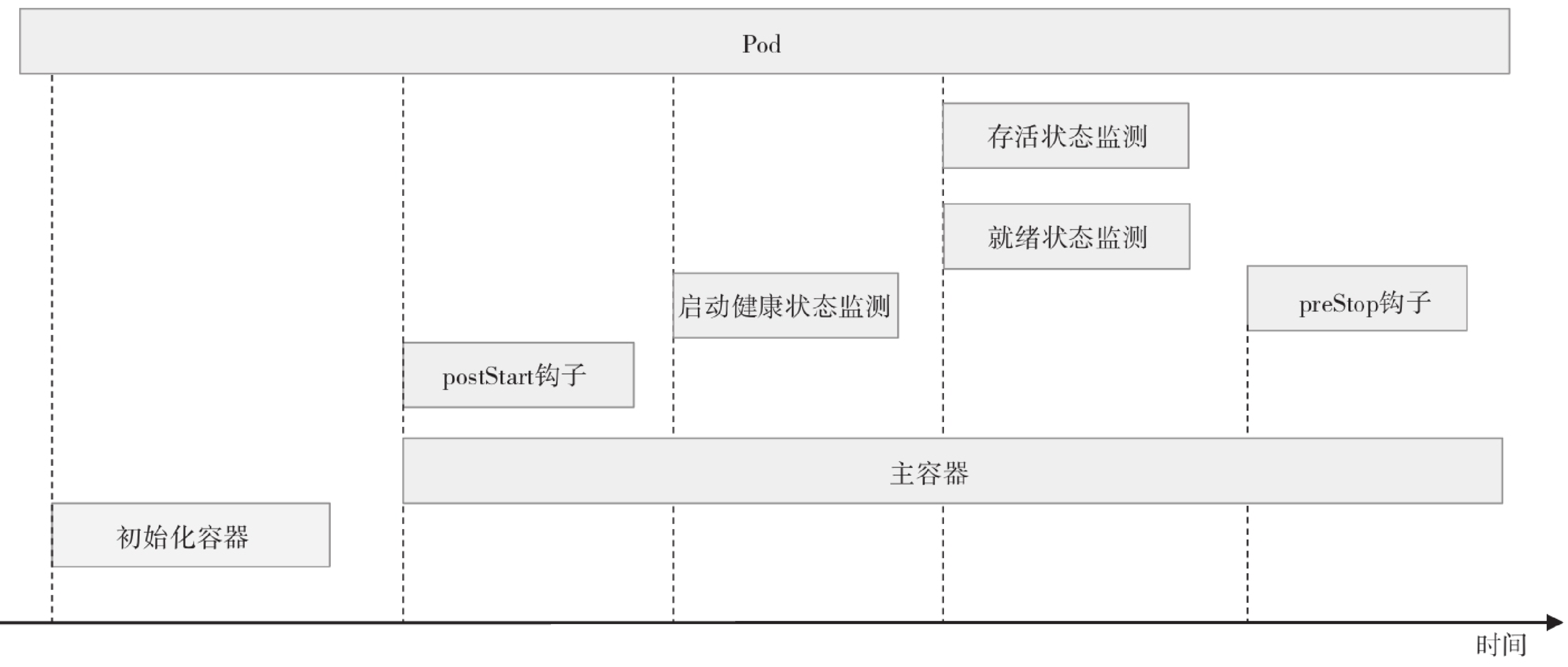
一个Pod对象生命周期的运行步骤
1)在启动包括初始化容器在内的任何容器之前先创建pause基础容器,它初始化Pod环境并为后续加入的容器提供共享的名称空间。 2)按顺序以串行方式运行用户定义的各个初始化容器进行Pod环境初始化;任何一个初始化容器运行失败都将导致Pod创建失败,并按其restartPolicy的策略进行处理,默认为重启。 3)待所有初始化容器成功完成后,启动应用程序容器,多容器Pod环境中,此步骤会并行启动所有应用容器,例如主容器和Sidecar容器,它们各自按其定义展开其生命周期;本步骤及后面的几个步骤都将以主容器为例进行说明;容器启动的那一刻会同时运行主容器上定义的PostStart钩子事件,该步骤失败将导致相关容器被重启。 4)运行容器启动健康状态监测(startupProbe),判定容器是否启动成功;该步骤失败,同样参照restartPolicy定义的策略进行处理;未定义时,默认状态为Success。 5)容器启动成功后,定期进行存活状态监测(liveness)和就绪状态监测(readiness);存活状态监测失败将导致容器重启,而就绪状态监测失败会使得该容器从其所属的Service对象的可用端点列表中移除。 6)终止Pod对象时,会先运行preStop钩子事件,并在宽限期(terminationGrace-PeriodSeconds)结束后终止主容器,宽限期默认为30秒。
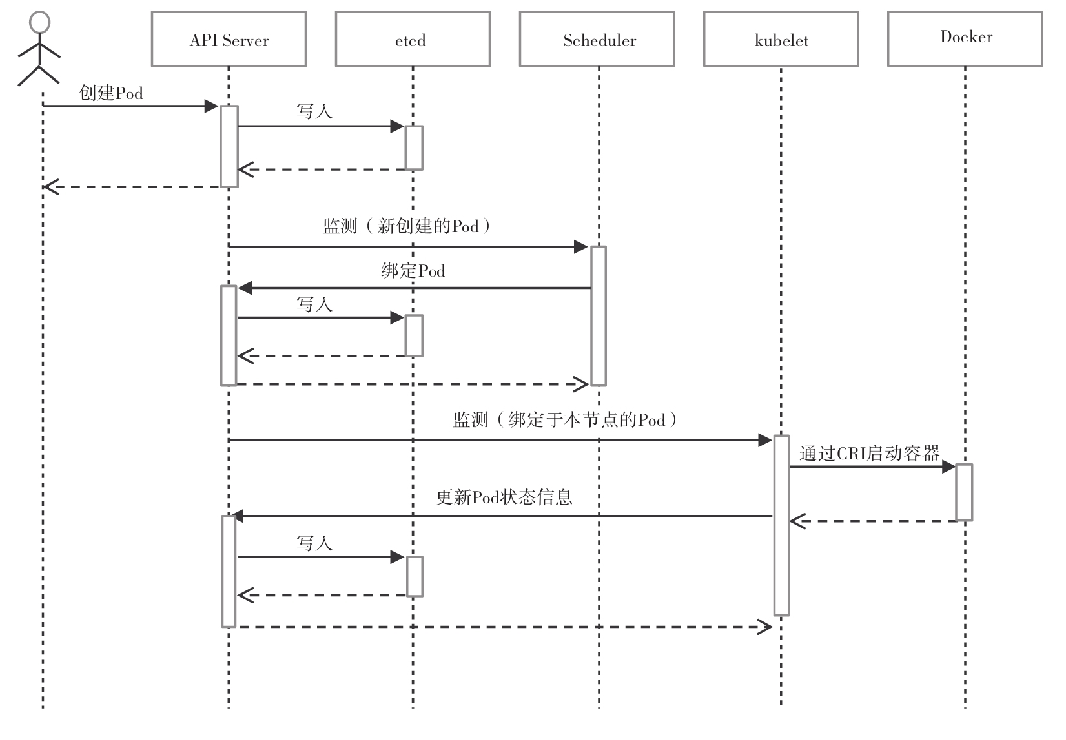
1)用户通过kubectl或其他API客户端提交Pod Spec给API Server。 2)API Server尝试着将Pod对象的相关信息存入etcd中,待写入操作执行完成,API Server即会返回确认信息至客户端。 3)Scheduler(调度器)通过其watcher监测到API Server创建了新的Pod对象,于是为该Pod对象挑选一个工作节点并将结果信息更新至API Server。 4)调度结果信息由API Server更新至etcd存储系统,并同步给Scheduler。 5)相应节点的kubelet监测到由调度器绑定于本节点的Pod后会读取其配置信息,并由本地容器运行时创建相应的容器启动Pod对象后将结果回存至API Server。 6)API Server将kubelet发来的Pod状态信息存入etcd系统,并将确认信息发送至相应的kubelet。
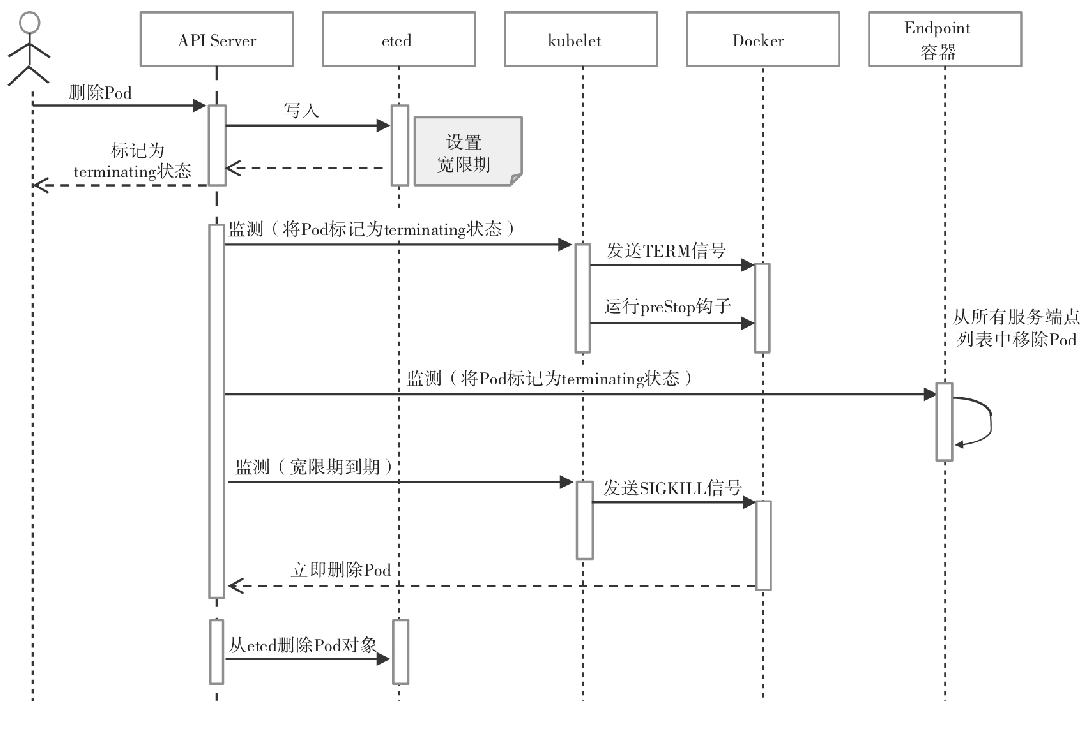
1)用户发送删除Pod对象的命令。 2)API服务器中的Pod对象会随着时间的推移而更新,在宽限期内(默认为30秒),Pod被视为dead。 3)将Pod标记为Terminating状态。 4)(与第3步同时运行)kubelet在监控到Pod对象转为Terminating状态的同时启动Pod关闭过程。 5)(与第3步同时运行)端点控制器监控到Pod对象的关闭行为时将其从所有匹配到此端点的Service资源的端点列表中移除。 6)如果当前Pod对象定义了preStop钩子句柄,在其标记为terminating后即会以同步方式启动执行;如若宽限期结束后,preStop仍未执行完,则重新执行第2步并额外获取一个时长为2秒的小宽限期。 7)Pod对象中的容器进程收到TERM信号。 8)宽限期结束后,若存在任何一个仍在运行的进程,Pod对象即会收到SIGKILL信号。 9)Kubelet请求API Server将此Pod资源的宽限期设置为0从而完成删除操作,它变得对用户不再可见。 默认情况下,所有删除操作的宽限期都是30秒,不过kubectl delete命令可以使用--grace-period=<seconds>选项自定义其时长,使用0值则表示直接强制删除指定的资源,不过此时需要同时为命令使用--force选项。
创建Pod: kubectl apply -f pod.yaml 或者使用命令kubectl run nginx --image=nginx 查看Pod: kubectl get pods kubectl describe pod <Pod名称> 查看日志: kubectl logs <Pod名称> [-c CONTAINER] kubectl logs <Pod名称> [-c CONTAINER] -f 进入容器终端: kubectl exec <Pod名称> [-c CONTAINER] --bash 删除Pod: kubectl delete <Pod名称>
二、在Pod中运行应用
Pod资源中可同时存在初始化容器、应用容器和临时容器3种类型的容器,不过创建并运行一个具体的Pod对象时,仅有应用容器是必选项,并且可以仅为其定义单个容器。
配置清单格式
apiVersion: v1 #api server版本 kind: Pod #资源类型 metadata: #元数据 name: ... #pod的名称,在同一个名称空间下必须唯一 namespaces: .... #pod所在的名称空间,默认为default名称空间 spec: #容器规划 containers: #定义容器,它是一个列表,可以定义一个或多个容器 - name: ... #容器名称,同一个Pod中名称必须唯一 image: ... #创建容器时使用的镜像 imagePullPolicy: ... #容器镜像拉取策略(Alway/IfNotPresent/Never) env: #定义容器的环境变量 #从pod属性中获取变量 - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName #自定义变量 - name: ABC value: "123456"
image虽为可选字段,这只是为方便更高级别的管理类资源(例如Deployment等)能覆盖它以实现某种高级管理功能而设置,对于非控制器管理的自主式Pod(或称为裸Pod)来说并不能省略该字段。下面是一个Pod资源清单示例文件,它仅指定了运行一个由ikubernetes/demoapp:v1.0镜像启动的主容器demo,该Pod对象位于default名称空间。
apiVersion: v1 kind: Pod metadata: name: test-pod namespace: default spec: containers: - name: test-pod #image: ikubernetes/demoapp:v1.0 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 imagePullPolicy: IfNotPresent
运行上面的配置清单pod-demo.yaml
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl apply -f pod.yml pod/test-pod created
该Pod对象由调度器绑定至特定工作节点后,由相应的kubelet负责创建和维护,实时状态也将同步给API Server并由其存储至etcd中。Pod创建并尝试启动的过程中,可能会经历Pending、ContainerCreating、Running等多种不同的状态,若Pod可正常启动,则kubectl get pods/POD命令输出字段中的状态(STATUS)则显示为Running,如下面的命令及结果所示,使用默认的名称空间时,其中的-n选项及参数default可以省略。
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl describe pod test-pod -n default Name: test-pod Namespace: default Priority: 0 Node: 172.168.33.212/172.168.33.212 #node节点的地址 Start Time: Sat, 02 Oct 2021 09:19:43 +0800 Labels: <none> Annotations: <none> Status: Running IP: 172.20.135.133 #容器的ip地址 IPs: IP: 172.20.135.133 Containers: test-pod: Container ID: docker://93b8116a2e18a31500de7bdf2203777e52495caba690bf8a977353b8b91999be Image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 Image ID: docker-pullable://harbor.ywx.net/k8s-baseimages/demoapp@sha256:6698b205eb18fb0171398927f3a35fe27676c6bf5757ef57a35a4b055badf2c3 Port: <none> Host Port: <none> State: Running Started: Sat, 02 Oct 2021 09:19:51 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-f5q6n (ro) ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- #pod被调度到了172.168.33.212 Normal Scheduled 15s default-scheduler Successfully assigned default/test-pod to 172.168.33.212 #拉取镜像 Normal Pulling 15s kubelet Pulling image "harbor.ywx.net/k8s-baseimages/demoapp:v1.0" Normal Pulled 9s kubelet Successfully pulled image "harbor.ywx.net/k8s-baseimages/demoapp:v1.0" in 5.621972341s #启动容器 Normal Created 8s kubelet Created container test-pod Normal Started 8s kubelet Started container test-pod
该pod已经被调度到了名为k8s-node03的node节点上,集群分配的ip为 172.20.135.133
对Pod中运行着的主容器的服务发起访问请求。镜像demoapp默认运行了一个Web服务程序,该服务监听TCP协议的80端口,镜像可通过“/”、/hostname、/user-agent、/livez、/readyz和/configs等路径服务于客户端的请求。例如,下面的命令先获取到Pod的IP地址,而后对其支持的Web资源路径/和/user-agent分别发出了一个访问请求:
root@k8s-master01:/apps/k8s-yaml/pod-case# demoIP=$(kubectl get pods test-pod -o jsonpath={.status.podIP}) root@k8s-master01:/apps/k8s-yaml/pod-case# curl $demoIP iKubernetes demoapp v1.0 !! ClientIP: 172.20.32.128, ServerName: test-pod, ServerIP: 172.20.135.133! root@k8s-master01:/apps/k8s-yaml/pod-case# curl -s http://$demoIP/user-agent User-Agent: curl/7.68.0 root@k8s-master01:/apps/k8s-yaml/pod-case# curl -s http://$demoIP/hostname ServerName: test-pod root@k8s-master01:/apps/k8s-yaml/pod-case# curl 172.20.135.133 iKubernetes demoapp v1.0 !! ClientIP: 172.20.32.128, ServerName: test-pod, ServerIP: 172.20.135.133! #测试该容器的健康状态(该容器的健康状态必须先做进容器中) root@k8s-master01:/apps/k8s-yaml/pod-case# curl -s http:// 172.20.135.133/livez OK
▪Always:每次启动Pod时都要从指定的仓库下载镜像。
▪IfNotPresent:仅本地镜像缺失时方才从目标仓库下载镜像。
▪Never:禁止从仓库下载镜像,仅使用本地镜像。
3、删除Pod
删除Pod对象则使用kubectl delete命令。
▪命令式命令:kubectl delete pods/NAME。 ▪命令式对象配置:kubectl delete -f FILENAME。 若删除后Pod一直处于Terminating状态,则可再一次执行删除命令,并同时使用--force和--grace-period=0选项进行强制删除。
资源创建或运行过程中偶尔会因故出现异常,此时用户需要充分获取相关的状态及配置信息以便确定问题所在。另外,在对资源对象进行创建或修改完成后,也需要通过其详细的状态信息来了解操作成功与否。kubectl有多个子命令,用于从不同角度显示对象的状态信息,这些信息有助于用户了解对象的运行状态、属性详情等。
▪kubectl describe:显示资源的详情,包括运行状态、事件等信息,但不同的资源类型输出内容不尽相同。 ▪kubectl logs:查看Pod对象中容器输出到控制台的日志信息;当Pod中运行有多个容器时,需要使用选项-c指定容器名称。 ▪kubectl exec:在Pod对象某容器内运行指定的程序,其功能类似于docker exec命令,可用于了解容器各方面的相关信息或执行必需的设定操作等,具体功能取决于容器内可用的程序。
kubectl describe pods/NAME -n NAMESPACE命令可打印Pod对象的详细描述信息,包括events和controllers等关系的子对象等,它会输出许多字段,不同的需求场景中,用户可能会关注不同维度的输出,但Priority、Status、Containers和Events等字段通常是重点关注的目标字段,各级别的多数输出字段基本都可以见名知义。
也可以通过kubectl get pods/POD -o yaml|json命令的status字段来了解Pod的状态详情,它保存有Pod对象的当前状态。如下命令显示了pod-demo的状态信息。
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl get pods test-pod -n default -o yaml ...... status: conditions: - lastProbeTime: null #上次进行探测的时间戳。 lastTransitionTime: "2021-10-02T01:19:43Z" #Pod上次发生状态转换的时间戳。 status: "True" #是否为状态信息,可取值有True、False和Unknown。 type: Initialized #所有的初始化容器都已经成功启动 - lastProbeTime: null lastTransitionTime: "2021-10-02T01:19:52Z" status: "True" type: Ready #表示已经就绪,可服务客户端请求 - lastProbeTime: null lastTransitionTime: "2021-10-02T01:19:52Z" status: "True" type: ContainersReady #则表示所有容器均已就绪。 - lastProbeTime: null lastTransitionTime: "2021-10-02T01:19:43Z" status: "True" type: PodScheduled #表示已经与节点绑定 containerStatuses: #容器级别的状态信息 #容器ID - containerID: docker://93b8116a2e18a31500de7bdf2203777e52495caba690bf8a977353b8b91999be #镜像名称 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 #镜像ID imageID: docker-pullable://harbor.ywx.net/k8s-baseimages/demoapp@sha256:6698b205eb18fb0171398927f3a35fe27676c6bf5757ef57a35a4b055badf2c3 lastState: {} #前一次的状态 name: test-pod ready: true #是否就绪 restartCount: 0 #容器重启次数 started: true state: #当前状态 running: startedAt: "2021-10-02T01:19:51Z" #容器启动时间 hostIP: 172.168.33.212 #调度的node节点的ip phase: Running #Pod当前的相位 podIP: 172.20.135.133 #当前pod的ip地址 podIPs: #该Pod的所有IP - ip: 172.20.135.133 qosClass: BestEffort #QOS类型 startTime: "2021-10-02T01:19:43Z"
上面的命令结果中,conditions字段是一个称为PodConditions的数组,它记录了Pod所处的“境况”或者“条件”,其中的每个数组元素都可能由如下6个字段组成。
▪lastProbeTime:上次进行Pod探测时的时间戳。
▪lastTransitionTime:Pod上次发生状态转换的时间戳。
▪message:上次状态转换相关的易读格式信息。
▪reason:上次状态转换原因,用驼峰格式的单个单词表示。
▪status:是否为状态信息,可取值有True、False和Unknown。
▪type:境况的类型或名称,有4个固定值;PodScheduled表示已经与节点绑定;Ready表示已经就绪,可服务客户端请求;Initialized表示所有的初始化容器都已经成功启动;ContainersReady则表示所有容器均已就绪。
2)查看容器日志
规范化组织的应用容器一般仅运行单个应用程序,其日志信息均通过标准输出和标准错误输出直接打印至控制台,kubectl logs POD [-c CONTAINER]命令可直接获取并打印这些日志,不过,若Pod对象中仅运行有一个容器,则可以省略-c选项及容器名称。
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl logs test-pod -n default * Running on http://0.0.0.0:80/ (Press CTRL+C to quit) 172.20.32.128 - - [02/Oct/2021 03:52:56] "GET / HTTP/1.1" 200 - 172.20.32.128 - - [02/Oct/2021 03:53:26] "GET /user-agent HTTP/1.1" 200 - 172.20.32.128 - - [02/Oct/2021 03:53:30] "GET /hostname HTTP/1.1" 200 - 172.20.32.128 - - [02/Oct/2021 03:54:00] "GET / HTTP/1.1" 200 - 172.20.32.128 - - [02/Oct/2021 03:54:14] "GET /livez HTTP/1.1" 200 -
3)在容器中额外运行其他程序
运行着非交互式进程的容器中缺省运行的唯一进程及其子进程启动后,容器即进入独立、隔离的运行状态。对容器内各种详情的了解需要穿透容器边界进入其中运行其他应用程序进行,kubectl exec可以让用户在Pod的某容器中运行用户所需要的任何存在于容器中的程序。在kubectl logs获取的信息不够全面时,此命令可以通过在Pod中运行其他指定的命令(前提是容器中存在此程序)来辅助用户获取更多信息。一个更便捷的使用接口是直接交互式运行容器中的某shell程序。例如,直接查看Pod中的容器运行的进程:
#查看容器中的进程(容器必须可以执行该命令的) root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl exec test-pod -- ps aux PID USER TIME COMMAND 1 root 0:02 python3 /usr/local/bin/demo.py 17 root 0:00 ps aux #查看容器地址(容器必须可以执行该命令的) root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl exec test-pod -- ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 4: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 46:4e:78:58:12:19 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 172.20.135.133/32 scope global eth0 valid_lft forever preferred_lft forever
有时候需要打开容器的交互式shell接口以方便多次执行命令,为kubectl exec命令额外使用-it选项,并指定运行镜像中可用的shell程序就能进入交互式接口。如下示例中,命令后的斜体部分表示在容器的交互式接口中执行的命令。
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl exec -it test-pod -- /bin/sh [root@test-pod /]# hostname test-pod [root@test-pod /]# netstat -antlp Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1/python3
5、自定义容器应用与参数
容器镜像启动容器时运行的默认应用程序由其Dockerfile文件中的ENTRYPOINT指令进行定义,传递给程序的参数则通过CMD指令设定,ETRYPOINT指令不存在时,CMD可同时指定程序及其参数。例如,要了解镜像harbor.ywx.net/k8s-baseimages/demoapp:v1.0中定义的ENTRYPOINT和CMD,可以在任何存在此镜像的节点上执行类似如下命令来获取:
root@k8s-node03:~# docker inspect harbor.ywx.net/k8s-baseimages/demoapp:v1.0 -f {{.Config.Entrypoint}} [/bin/sh -c python3 /usr/local/bin/demo.py] root@k8s-node03:~# docker inspect harbor.ywx.net/k8s-baseimages/demoapp:v1.0 -f {{.Config.Cmd}} []
Pod配置中,spec.containers[].command字段可在容器上指定非镜像默认运行的应用程序,且可同时使用spec.containers[].args字段进行参数传递,它们将覆盖镜像中默认定义的参数。若定义了args字段,该字段值将作为参数传递给镜像中默认指定运行的应用程序;而仅定义了command字段时,其值将覆盖镜像中定义的程序及参数。下面的资源配置清单保存在pod-demo-with-cmd-and-args.yaml文件中,它把镜像harbor.ywx.net/k8s-baseimages/demoapp:v1.0的默认应用程序修改为/bin/sh -c,参数定义为python3 /usr/local/bin/demo.py -p 8080,其中的-p选项可修改服务监听的端口为指定的自定义端口。
apiVersion: v1 kind: Pod metadata: name: pod-demo-with-cmd-and-arags namespace: default spec: containers: - name: demo #image: ikubernetes/demoapp:v1.0 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 imagePullPolicy: IfNotPresent #修改容器运行的端口为8080 command: ["/bin/sh","-c"] args: ["python3 /usr/local/bin/demo.py -p 8080"]
下面将上述清单中定义的Pod对象创建到集群上,验证其监听的端口是否从默认的80变为了指定的8080
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl apply -f pod-demo-with-cmd-and-arags.yaml pod/pod-demo-with-cmd-and-arags created NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-demo-with-cmd-and-arags 1/1 Running 0 37s 172.20.135.134 172.168.33.212 <none> <none> test-pod 1/1 Running 0 4h25m 172.20.135.133 172.168.33.212 <none> <none> <none> #80端口已经无法访问 root@k8s-master01:~# curl 172.20.135.134 curl: (7) Failed to connect to 172.20.135.134 port 80: Connection refused #8080端口可以访问 root@k8s-master01:~# curl 172.20.135.134:8080 iKubernetes demoapp v1.0 !! ClientIP: 172.20.32.128, ServerName: pod-demo-with-cmd-and-arags, ServerIP: 172.20.135.134! root@k8s-master01:~# kubectl exec pod-demo-with-cmd-and-arags -- netstat -tnl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN
6、容器的环境变量env
定义args参数,也是向容器中应用程序传递配置信息的常用方式之一,对于非云原生的应用程序,这几乎是最简单的配置方式了。另一个常用配置方式是使用环境变量。
非容器化的传统管理方式中,复杂应用程序的配置信息多数由配置文件进行指定,用户借助简单的文本编辑器完成配置管理。然而,对于容器隔离出的环境中的应用程序,用户就不得不穿透容器边界在容器内进行配置编辑并进行重载,复杂且低效。于是,由环境变量在容器启动时传递配置信息就成了一种受到青睐的方式。
注意
这种方式需要应用程序支持通过环境变量进行配置,否则用户要在制作Docker镜像时通过entrypoint脚本完成环境变量到程序配置文件的同步。
通过环境变量的配置容器化应用时,需要在容器配置段中嵌套使用env字段,它的值是一个由环境变量构成的列表。每个环境变量通常由name和value字段构成。
▪name <string>:环境变量的名称,必选字段。 ▪value <string>:传递给环境变量的值,通过$(VAR_NAME)引用,逃逸格式为$$(VAR_NAME)默认值为空。 ▪envFrom: 1)fieldRef:是从pod属性中获取变量,仅仅支持一下属性 metadata.name,metadata.namespace,metadata.labels['<KEY>'],metadata.annotations['<KEY>'],spec.nodeName,spec.serviceAccountName, status.hostIP, status.podIP, status.podIPs 2)configMapKeyRef:从configmap中获取变量 3)resourceFieldRef: 从容器资源中获取变量,仅仅支持requests和limits的cpu跟memory only resources limits and requests(limits.cpu, limits.memory, limits.ephemeral-storage, requests.cpu,requests.memory and requests.ephemeral-storage) 4) secretKeyRef:从secret中获取变量
apiVersion: v1 kind: Pod metadata: name: pod-using-env namespace: default spec: containers: - name: demo #image: ikubernetes/demoapp:v1.0 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 imagePullPolicy: IfNotPresent env: #自定义的变量 - name: HOST value: "127.0.0.1" - name: PORT value: "8080" #从pod属性中获取变量 - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName #从从容器资源中获取变量 - name: LIMIT_CPU valueFrom: resourceFieldRef: resource: limits.cpu
下面将清单文件中定义的Pod对象创建至集群中,并查看应用程序监听的地址和端口来验证配置结果:
root@k8s-master01:~# kubectl get pod -n default -o wide|grep pod-using-env pod-using-env 1/1 Running 0 4m 172.20.58.195 172.168.33.211 <none> <none> root@k8s-master01:~# kubectl exec pod-using-env -- netstat -tnl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN root@k8s-master01:~# kubectl exec -it pod-using-env -- /bin/sh root@k8s-master01:~# kubectl exec -it pod-using-env -- /bin/sh [root@pod-using-env /]# echo $HOST 127.0.0.1 [root@pod-using-env /]# echo $PORT 8080 [root@pod-using-env /]# echo $MY_NODE_NAME 172.168.33.211 [root@pod-using-env /]# echo $LIMIT_CPU 1 [root@pod-using-env /]#
无论它们是否真正被用到,传递给容器的环境变量都会直接注入容器的shell环境中,使用printenv一类的命令就能在容器中获取到所有环境变量的列表。
root@k8s-master01:~# kubectl exec pod-using-env -- printenv|egrep -w "HOST|PORT|MY_NODE_NAME|LIMIT_CPU" LIMIT_CPU=1 HOST=127.0.0.1 PORT=8080 MY_NODE_NAME=172.168.33.211
Pod对象的IP地址仅在集群内可达,它们无法直接接收来自集群外部客户端的请求流量,尽管它们的服务可达性不受工作节点边界的约束,但依然受制于集群边界。不考虑通过Service资源进行服务暴露的情况下,服务于集群外部的客户端的常用方式有两种:一种是在其运行的节点上进行端口映射,由节点IP和选定的协议端口向Pod内的应用容器进行DNAT转发;另一种是让Pod共享其所在的工作节点的网络名称空间,应用进程将直接监听工作节点IP地址和协议端口。
1)容器端口映射
Pod的IP地址处于同一网络平面,无论是否为容器指定了要暴露的端口都不会影响集群中其他节点之上的Pod客户端对其进行访问,这意味着,任何在非本地回环接口lo上监听的端口都可直接通过Pod网络被请求。从这个角度来说,容器端口只是信息性数据,它仅为集群用户提供了一个快速了解相关Pod对象的可访问端口的途径,但显式指定容器的服务端口可额外为其赋予一个名称以方便按名称调用。定义容器端口的ports字段的值是一个列表,由一到多个端口对象组成,它的常用嵌套字段有如下几个。
▪containerPort <integer>:必选字段,指定在Pod对象的IP地址上暴露的容器端口,有效范围为(0,65536);使用时,需要指定为容器应用程序需要监听的端口。 ▪name <string>:当前端口的名称标识,必须符合IANA_SVC_NAME规范且在当前Pod内要具有唯一性;此端口名可被Service资源按名调用。 ▪protocol <string>:端口相关的协议,其值仅支持TCP、SCTP或UDP三者之一,默认为TCP。
需要借助于Pod所在节点将容器服务暴露至集群外部时,还需要使用hostIP与hostPort两个字段来指定占用的工作节点地址和端口。如图所示的Pod A与Pod C可分别通过各自所在节点上指定的hostIP和hostPort服务于客户端请求。

通过hostIP和hostPort暴露容器服务
▪hostPort <integer>:主机端口,它将接收到的请求通过NAT机制转发至由container-Port字段指定的容器端口。 ▪hostIP <string>:主机端口要绑定的主机IP,默认为主机之上所有可用的IP地址;该字段通常使用默认值。
下面的资源配置清单示例(pod-using-hostport.yaml)中定义的demo容器指定了要暴露容器上TCP协议的80端口,并将之命名为http,该容器可通过工作节点的10080端口接入集群外部客户端的请求。
apiVersion: v1 kind: Pod metadata: name: pod-using-hostport namespace: default spec: containers: - name: demo #image: ikubernetes/demoapp:v1.0 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 imagePullPolicy: IfNotPresent ports: #定义port #port的名称 - name: http #容器使用的端口 containerPort: 80 #协议 protocol: TCP #把pod所在的node节点的10080映射为80端口 hostPort: 10080
在集群中创建配置清单中定义的Pod对象后,需获取其被调度至的目标节点,例如下面第二个命令结果中的k8s-node03/172.168.32.206,而后从集群外部向该节点的10080端口发起Web请求进行访问测试:
[root@k8s-master01 apps]# kubectl apply -f pod-using-hostport.yaml pod/pod-using-hostport created #查看pod-using-hostport在那个node节点 [root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl get pod -n default -o wide | grep pod-using-hostport pod-using-hostport 1/1 Running 0 3m38s 172.20.85.194 172.168.33.210 <none> <none> root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl describe pods pod-using-hostport |grep "^Node" Node: 172.168.33.210/172.168.33.210 Node-Selectors: <none> #通过node01/172.168.33.210:10080可以访问容器服务 root@k8s-master01:/apps/k8s-yaml/pod-case# curl 172.168.33.210:10080 iKubernetes demoapp v1.0 !! ClientIP: 172.168.33.207, ServerName: pod-using-hostport, ServerIP: 172.20.85.194!
2)配置Pod使用节点网络
同一个Pod对象的各容器运行于一个独立、隔离的Network、UTS和IPC名称空间中,共享同一个网络协议栈及相关的网络设备,但也有些特殊的Pod对象需要运行于所在节点的名称空间中,执行系统级的管理任务(例如查看和操作节点的网络资源甚至是网络设备等),或借助节点网络资源向集群外客户端提供服务等。
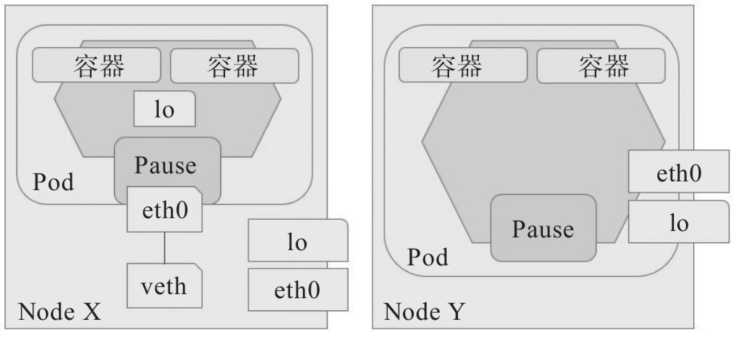
由kubeadm部署的Kubernetes集群中的kube-apiserver、kube-controller-manager、kube-scheduler,以及kube-proxy和kube-flannel等通常都是第二种类型的Pod对象。网络名称空间是Pod级别的属性,用户配置的Pod对象,仅需要设置其spec.hostNetwork的属性为true即可创建共享节点网络名称空间的Pod对象,如下面保存在pod-using-hostnetwork.yaml文件中的配置清单所示。
apiVersion: v1 kind: Pod metadata: name: pod-using-hostnetwork namespace: default spec: containers: - name: pod-using-hostnetwork #image: ikubernetes/demoapp:v1.0 image: harbor.ywx.net/k8s-baseimages/demoapp:v1.0 imagePullPolicy: IfNotPresent hostNetwork: true
将上面配置清单中定义的pod-using-hostnetwork创建于集群上,并查看主机名称或网络接口的相关属性信息以验证它是否能共享使用工作节点的网络名称空间。
root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl apply -f pod-using-hostnetwork.yaml pod/pod-using-hostnetwork created #查看pod的ip root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl get pod -n default -o wide |grep pod-using-hostnetwork pod-using-hostnetwork 1/1 Running 0 98s 172.168.33.212 172.168.33.212 <none> <none> #查看pod坐在的node节点ip root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl describe pod pod-using-hostnetwork |grep "^Node" Node: 172.168.33.212/172.168.33.212 Node-Selectors: <none> #hostnetwork中pod的ip为所在node节点的ip root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl exec pod-using-hostnetwork -- ifconfig eth0 eth0 Link encap:Ethernet HWaddr 00:50:56:85:0B:19 inet addr:172.168.33.212 Bcast:172.168.255.255 Mask:255.255.0.0 inet6 addr: fe80::250:56ff:fe85:b19/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:1656196 errors:0 dropped:708 overruns:0 frame:0 TX packets:938938 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:1135275631 (1.0 GiB) TX bytes:73820731 (70.4 MiB) ##hostnetwork中pod的hostname为所在node节点的hostname root@k8s-master01:/apps/k8s-yaml/pod-case# kubectl exec pod-using-hostnetwork -- hostname k8s-node03 #访问node节点ip就可以访问pod root@k8s-master01:/apps/k8s-yaml/pod-case# curl 172.168.33.212 iKubernetes demoapp v1.0 !! ClientIP: 172.168.33.207, ServerName: k8s-node03, ServerIP: 172.168.33.212!
与容器端口映射存在的同样问题是,用户无法事先预知Pod对象会调度至哪个节点,除非事先指示调度器将Pod绑定至固定的目标节点之上。
四、Pod的重启策略
Pod对象的应用容器因程序崩溃、启动状态检测失败、存活状态检测失败或容器申请超出限制的资源等原因都可能导致其被终止,此时是否应该重启则取决于Pod上的restartPolicy(重启策略)字段的定义,该字段支持以下取值。
1)Always:无论因何原因、以何种方式终止,kubelet都将重启该Pod,此为默认设定。 2)OnFailure:仅在Pod对象以非0方式退出时才将其重启。 3)Never:不再重启该Pod。
需要注意的是,restartPolicy适用于Pod对象中的所有容器,而且它仅用于控制在同一个节点上重新启动Pod对象的相关容器。首次需要重启的容器,其重启操作会立即进行,而再次重启操作将由kubelet延迟一段时间后进行,反复的重启操作的延迟时长依次为10秒、20秒、40秒、80秒、160秒和300秒,300秒是最大延迟时长。
五、资源需求与资源限制
容器在运行时具有多个维度,例如内存占用、CPU占用和其他资源的消耗等。每个容器都应该声明其资源需求,并将该信息传递给管理平台。这些资源需求信息会在CPU、内存、网络、磁盘等维度对平台执行调度、自动扩展和容量管理等方面影响编排工具的决策。
1、资源需求与限制
在Kubernetes上,可由容器或Pod请求与消费的“资源”主要是指CPU和内存(RAM),它可统称为计算资源,另一种资源是事关可用存储卷空间的存储资源。
相比较而言,CPU属于可压缩型资源,即资源额度可按需弹性变化,而内存(当前)则是不可压缩型资源,对其执行压缩操作可能会导致某种程度的问题,例如进程崩溃等。目前,资源隔离仍属于容器级别,CPU和内存资源的配置主要在Pod对象中的容器上进行,并且每个资源存在的需求和限制两种类型。为了表述方便,人们通常把资源配置称作Pod资源的需求和限制,只不过它是指Pod内所有容器上的某种类型资源的请求与限制总和。

▪资源需求:定义需要系统预留给该容器使用的资源最小可用值,容器运行时可能用不到这些额度的资源,但用到时必须确保有相应数量的资源可用。
▪资源限制:定义该容器可以申请使用的资源最大可用值,超出该额度的资源使用请求将被拒绝;显然,该限制需要大于等于requests的值,但系统在某项资源紧张时,会从容器回收超出request值的那部分。
在Kubernetes系统上,1个单位的CPU相当于虚拟机上的1颗虚拟CPU(vCPU)或物理机上的一个超线程(Hyperthread,或称为一个逻辑CPU),它支持分数计量方式,一个核心(1 core)相当于1000个微核心(millicores,以下简称为m),因此500m相当于是0.5个核心,即1/2个核心。内存的计量方式与日常使用方式相同,默认单位是字节,也可以使用E、P、T、G、M和K为单位后缀,或Ei、Pi、Ti、Gi、Mi和Ki形式的单位后缀。
的配置清单示例(resource-requests-demo.yaml)中的自主式Pod要求为stress容器确保128MiB的内存及1/5个CPU核心(200m)资源可用。Pod运行stress-ng镜像启动一个进程(-m 1)进行内存性能压力测试,满载测试时stress容器也会尽可能多地占用CPU资源,另外再启动一个专用的CPU压力测试进程(-c 1)。stress-ng是一个多功能系统压力测试具,master/worker模型,master为主进程,负载生成和控制子进程,worker是负责执行各类特定测试的子进程,例如测试CPU的子进程,以及测试RAM的子进程等。
apiVersion: v1 kind: Pod metadata: name: stress-pod spec: containers: - name: stress #image: ikubernetes/stress-ng image: harbor.ywx.net/k8s-baseimages/stress-ng command: ["/usr/bin/stress-ng", "-m 1", "-c 1", "-metrics-brief"] resources: requests: #定义容器的最少使用资源 memory: "128Mi" cpu: "200m"
集群中的每个节点都拥有定量的CPU和内存资源,调度器将Pod绑定至节点时,仅计算资源余量可满足该Pod对象需求量的节点才能作为该Pod运行的可用目标节点。也就是说,Kubernetes的调度器会根据容器的requests属性定义的资源需求量来判定哪些节点可接收并运行相关的Pod对象,而对于一个节点的资源来说,每运行一个Pod对象,该Pod对象上所有容器requests属性定义的请求量都要给予预留,直到节点资源被绑定的所有Pod对象瓜分完毕为止。
3、容器资源限制
容器为保证其可用的最少资源量,并不限制可用资源上限,因此对应用程序自身Bug等多种原因导致的系统资源被长时间占用无计可施,这就需要通过资源限制功能为容器定义资源的最大可用量。一旦定义资源限制,分配资源时,可压缩型资源CPU的控制阀可自由调节,容器进程也就无法获得超出其CPU配额的可用值。但是,若进程申请使用超出limits属性定义的内存资源时,该进程将可能被杀死。不过,该进程随后仍可能会被其控制进程重启,例如,当Pod对象的重启策略为Always或OnFailure时,或者容器进程存在有监视和管理功能的父进程等。
配置清单文件(resource-limits-demo.yaml)中定义使用simmemleak镜像运行一个Pod对象,它模拟内存泄漏操作不断地申请使用内存资源,直到超出limits属性中memory字段设定的值而被杀死。
apiVersion: v1 kind: Pod metadata: name: memleak-pod namespace: default labels: app: memleak spec: containers: - name: simmemleak image: ikubernetes/simmemleak imagePullPolicy: IfNotPresent resources: requests: #定义容器的最小使用资源 memory: "64Mi" cpu: "1" limits: #定义容器的最大使用资源 memory: "128Mi" cpu: "1.2"
OOMKilled表示容器因内存耗尽而被终止,因此为limits属性中的memory设置一个合理值至关重要。与资源需求不同的是,资源限制并不影响Pod对象的调度结果,即一个节点上的所有Pod对象的资源限制数量之和可以大于节点拥有的资源量,即支持资源的过载使用(overcommitted)。不过,这么一来,一旦内存资源耗尽,几乎必然地会有容器因OOMKilled而终止。 另外需要说明的是,Kubernetes仅会确保Pod对象获得它们请求的CPU时间额度,它们能否取得额外(throttled)的CPU时间,则取决于其他正在运行作业的CPU资源占用情况。例如对于总数为1000m的CPU资源来说,容器A请求使用200m,容器B请求使用500m,在不超出它们各自最大限额的前下,则余下的300m在双方都需要时会以2 : 5(200m : 500m)的方式进行配置。
注意:
容器可用资源受限于requests和limits属性中的定义,但容器中可见的资源量依然是节点级别的可用总量。
六、Pod服务质量类别
Kubernetes允许节点的Pod对象过载使用资源,这意味着节点无法同时满足绑定其上的所有Pod对象以资源满载的方式运行。因而在内存资源紧缺的情况下,应该以何种次序终止哪些Pod对象就变成了问题。事实上,Kubernetes无法自行对此做出决策,它需要借助于Pod对象的服务质量和优先级等完成判定。根据Pod对象的requests和limits属性,Kubernetes把Pod对象归类到BestEffort、Burstable和Guaranteed这3个服务质量类别(Quality of Service,QoS)类别下。
▪Guaranteed:Pod对象为其每个容器都设置了CPU资源需求和资源限制,且二者具有相同值;同时为每个容器都设置了内存资需求和内存限制,且二者具有相同值。这类Pod对象具有最高级别服务质量。
▪Burstable:至少有一个容器设置了CPU或内存资源的requests属性,但不满足Guaranteed类别的设定要求,这类Pod对象具有中等级别服务质量。
▪BestEffort:不为任何一个容器设置requests或limits属性,这类Pod对象可获得的服务质量为最低级别。
const ( PodInfraOOMAdj int = -998 KubeletOOMScoreAdj int = -999 DockerOOMScoreAdj int = -999 KubeProxyOOMScoreAdj int = -999 guaranteedOOMScoreAdj int = -998 besteffortOOMScoreAdj int = 1000 )
因此,同等级别优先级的Pod资源在OOM时,与自身的requests属性相比,其内存占用比例最大的Pod对象将先被杀死。例如,下图中的同属于Burstable类别的Pod A将先于Pod B被杀死,虽然其内存用量小,但与自身的requests值相比,它的占用比例为95%,要大于Pod B的80%。
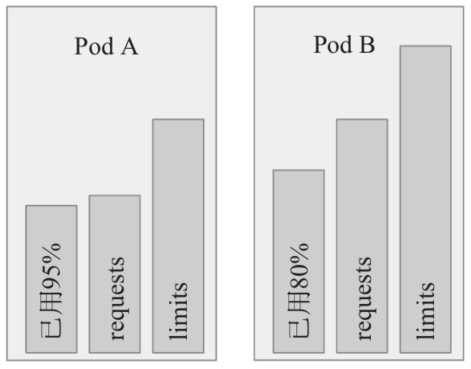
需要特别说明的是,OOM是内存耗尽时的处理机制,与可压缩型资源CPU无关,因此CPU资源的需求无法得到保证时,Pod对象仅仅是暂时获取不到相应的资源来运行而已。

