一、LVS的原理
linux virtual server简称LVS,Internet的快速增长使多媒体网络服务器面对的访问数量快速增加,服务器需要具备提供大量并发访问服务的能力,因此对于大负载的服务器来讲, CPU、I/O处理能力很快会成为瓶颈。由于单台服务器的性能总是有限的,简单的提高硬件性能并不能真正解决这个问题。为此,必须采用多服务器和负载均衡技术才能满足大量并发访问的需要。Linux 虚拟服务器(Linux Virtual Servers,LVS) 使用负载均衡技术将多台服务器组成一个虚拟服务器。它为适应快速增长的网络访问需求提供了一个负载能力易于扩展,而价格低廉的解决方案。lvs的负载能力特别强,优化空间特别大,lvs的变种DPVS据说是lvs性能的几倍,由爱奇艺开发,并广泛用于爱奇艺IDC。其他负载均衡服务器还有nginx,haproxy,F5,Netscale。
LVS简单工作原理:用户请求LVS VIP,LVS根据转发方式和算法,将请求转发给后端服务器,后端服务器接受到请求,返回给用户。对于用户来说,看不到WEB后端具体的应用。
二、LVS均衡的介绍
互联网主流可伸缩网络服务有很多结构,但是都一个共同的特点,它们都需要一个前端的负载调度器(或者多个进行主从备份)。实现虚拟网络服务的主要技术指出IP
已有的IP负载均衡技术中,主要有通过
在分析VS/NAT的缺点和网络服务的非对称性的基础上,可以通过IP隧道实现虚拟服务器的方法VS/TUN (Virtual Server via IP Tunneling),和通过直接路由实现虚拟服务器的方法VS/DR(Virtual Server via Direct Routing),它们可以极大地提高系统的伸缩性。
总体来说IP负载均衡技术分为:VS/NAT、VS/TUN和VS/
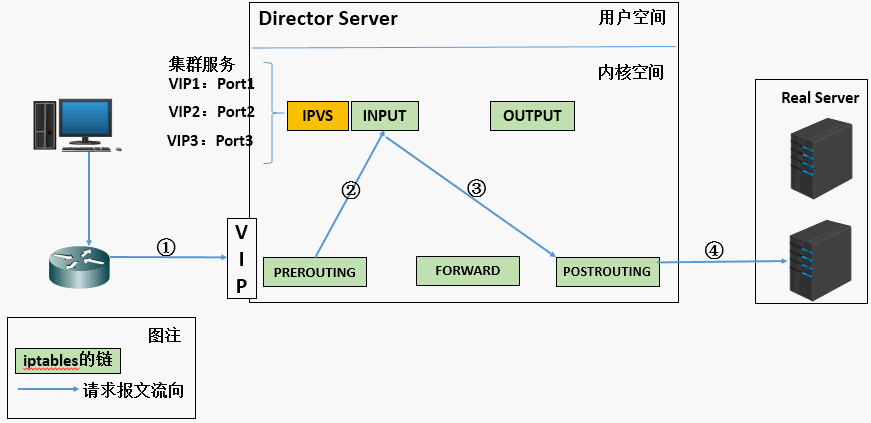
1、当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间。 2、PREROUTING链首先会接收到用户请求,判断目标IP确定是本机IP,将数据包发往INPUT链。 3、IPVS是工作在INPUT链上的,当用户请求到达INPUT时,IPVS会将用户请求和自己已定义好的集群服务进行比对,如果用户请求的就是定义的集群服务,那么此时IPVS会强行修改数据包里的目标IP地址及端口,并将新的数据包发往POSTROUTING链。 4、POSTROUTING链接收数据包后发现目标IP地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器。
LVS 由2部分程序组成,包括 ipvs 和 ipvsadm。
1、IPVS(ip virtual server):一段代码工作在内核空间,叫IPVS,是真正生效实现调度的代码。IPVS的总体结构主要由IP包处理、负载均衡算法、系统配置与管理三个模块及虚拟服务器与真实服务器链表组成。
2、ipvsadm:另外一段是工作在用户空间,叫ipvsadm,即IPVS管理器,负责为ipvs内核框架编写规则,定义谁是集群服务,而谁是后端真实的服务器(Real Server)。
DS:Director Server。指的是前端负载均衡器节点。
RS:Real Server。后端真实的工作服务器。
VIP:Virtual IP,向外部直接面向用户请求,作为用户请求的目标的IP地址。
DIP:Director Server IP,主要用于和内部主机通讯的IP地址。
RIP:Real Server IP,后端服务器的IP地址。
CIP:Client IP,访问客户端的IP地址。
六、LVS工作模式和原理
1、NAT模式
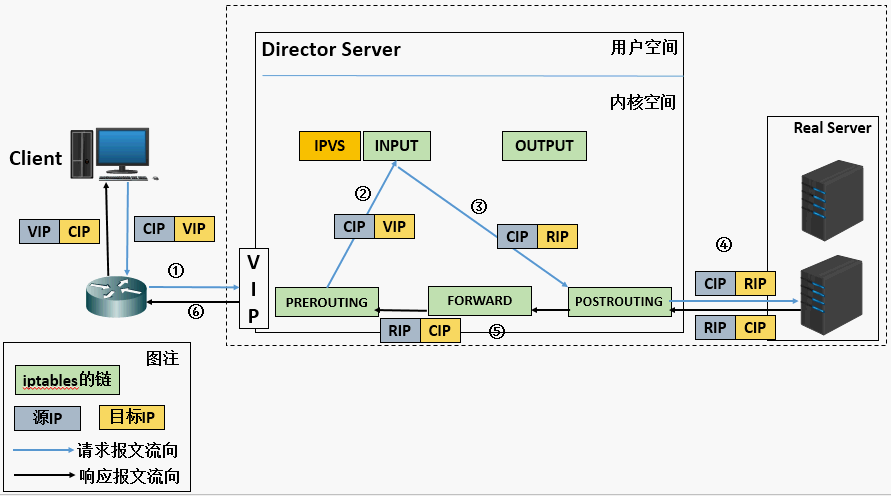
1、当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP。 2、PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链。 3、IPVS比对数据包请求的服务是否为集群服务,若是,修改数据包的目标IP地址为后端服务器IP,然后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP。 4、POSTROUTING链通过选路,将数据包发送给Real Server 5、Real Server比对发现目标为自己的IP,开始构建响应报文发回给Director Server。 此时报文的源IP为RIP,目标IP为CIP。 6、Director Server在响应客户端前,此时会将源IP地址修改为自己的VIP地址,然后响应给客户端。 此时报文的源IP为VIP,目标IP为CIP。
LVS NAT原理:用户请求LVS VIP到达director(LVS服务器:LB),director将请求的报文的目标IP地址改成后端的realserver IP地址(RIP),同时将报文的目标端口也改成后端选定的realserver相应端口,最后将报文发送到realserver,realserver将数据返给director,director再把数据发送给用户。(两次请求都经过director,所以访问大的话,director会成为瓶颈),后端只支持20-30台
NAT特性
- RIP最好是内网IP - RS的网关必须指向DIP,及均衡器的IP。 - DIP和RIP必须在同一个网段内。 - 请求和回应的报文都必须经过director,director容易成为瓶颈。 - nat支持端口转发。
NAT的总结
lvs-nat:本质是多目标IP的DNAT,通过将请求报文中的目标地址和目标端口修改为某挑出的RS的RIP和 PORT实现转发 (1)RIP和DIP应在同一个IP网络,且应使用私网地址;RS的网关要指向DIP (2)请求报文和响应报文都必须经由Director转发,Director易于成为系统瓶颈 (3)支持端口映射,可修改请求报文的目标PORT (4)LVS必须是Linux系统,RS可以是任意OS系统
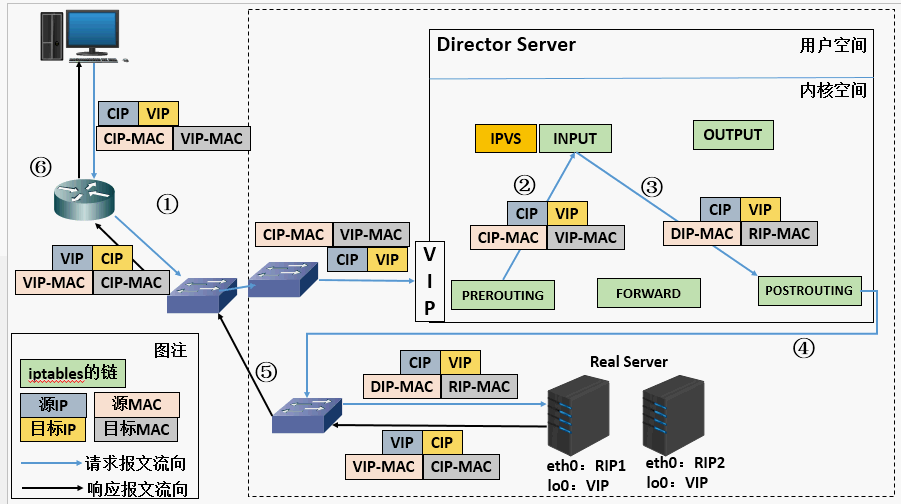
1、首先用户用CIP请求VIP。 2、根据上图可以看到,不管是Director Server还是Real Server上都需要配置相同的VIP,那么当用户请求到达我们的集群网络的前端路由器的时候,请求数据包的源地址为CIP目标地址为VIP,此时路由器会发广播问谁是VIP,那么我们集群中所有的节点都配置有VIP,此时谁先响应路由器那么路由器就会将用户请求发给谁,这样一来我们的集群系统是不是没有意义了,那我们可以在网关路由器上配置静态路由指定VIP就是Director Server,或者使用一种机制不让Real Server 接收来自网络中的ARP地址解析请求,这样一来用户的请求数据包都会经过Director Servrer。 3、当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP。 4、PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链。 5、IPVS比对数据包请求的服务是否为集群服务,若是,将请求报文中的源MAC地址修改为DIP的MAC地址,将目标MAC地址修改RIP的MAC地址,然后将数据包发至POSTROUTING链。 此时的源IP和目的IP均未修改,仅修改了源MAC地址为DIP的MAC地址,目标MAC地址为RIP的MAC地址 6、由于DS和RS在同一个网络中,所以是通过二层来传输。POSTROUTING链检查目标MAC地址为RIP的MAC地址,那么此时数据包将会发至Real Server。 7、RS发现请求报文的MAC地址是自己的MAC地址,就接收此报文。处理完成之后,将响应报文通过lo接口传送给eth0网卡然后向外发出。 此时的源IP地址为VIP,目标IP为CIP 8、响应报文最终送达至客户端。
LVS DR原理:用户请求LVS VIP到达director(LB均衡器),director将请求的报文的目标MAC地址改成后端的realserver MAC地址,目标IP为VIP(不变),源IP为用户IP地址(保持不变),然后Director将报文发送到realserver,realserver检测到目标为自己本地VIP,如果在同一个网段,然后将请求直接返给用户。如果用户跟realserver不在一个网段,则通过网关返回用户。
配置DR有三种方式:
第一种方式: 在路由器上明显说明vip对应的地址一定是Director上的MAC,只要绑定,以后再跟vip通信也不用再请求了,这个绑定是静态的,所以它也不会失效,也不会再次发起请求,但是有个前提,我们的路由设备必须有操作权限能够绑定MAC地址,万一这个路由器是运行商操作的,我们没法操作怎么办?第一种方式固然很简便,但未必可行。 第二种方式: 在给别主机上(例如:红帽)它们引进的有一种程序arptables,它有点类似于iptables,它肯定是基于arp或基于MAC做访问控制的,很显然我们只需要在每一个real server上定义arptables规则,如果用户arp广播请求的目标地址是本机的vip则不予相应,或者说相应的报文不让出去,很显然网关(gateway)是接受不到的,也就是director相应的报文才能到达gateway,这个也行。第二种方式我们可以基于arptables。 第三种方式: 在相对较新的版本中新增了两个内核参数(kernelparameter),第一个是arp_ignore定义接受到ARP请求时的相应级别;第二个是arp_announce定义将自己地址向外通告时的通告级别。【提示:很显然我们现在的系统一般在内核中都是支持这些参数的,我们用参数的方式进行调整更具有朴实性,它还不依赖于额外的条件,像arptables,也不依赖外在路由配置的设置,反而通常我们使用的是第三种配置】 arp_ignore:定义接受到ARP请求时的相应级别 0: 只要本地配置的有相应地址,就给予响应。(默认) 1: 仅回应目标IP地址是本地的入网地址的arp请求。 2: 仅回应目标IP地址是本地的入网地址,而且源IP和目标IP在同一个子网的arp请 求。 3: 不回应该网络界面的arp请求,而只对设置的唯一和连接地址做出回应 4-7:保留未使用 8: 不回应所有的arp请求。 arp_announce:定义将自己地址向外通告是的通告级别; 0: 将本地任何接口上的任何地址向外通告 1: 试图仅向目标网络通告与其网络匹配的地址 2: 仅向与本地接口上地址匹配的网络进行通告
DR特性
特点1:保证前端路由将目标地址为VIP报文统统发给Director Server,而不是RS。
Director和RS的VIP为同一个VIP。
RS可以使用私有地址;也可以是公网地址,如果使用公网地址,此时可以通过互联网对RIP进行直接访问。
RS跟Director Server必须在同一个物理网络中。
所有的请求报文经由Director Server,但响应报文必须不能进过Director Server。
不支持地址转换,也不支持端口映射
RS可以是大多数常见的操作系统
RS的网关绝不允许指向DIP(因为我们不允许他经过director)
RS上的lo接口配置VIP的IP地址
DR模式是市面上用得最广的。
缺陷:RS和DS必须在同一机房中
补充:特点1的解决方法
在前端路由器做静态地址路由绑定,将对于VIP的地址仅路由到Director Server。存在问题:用户未必有路由操作权限,因为有可能是运营商提供的,所以这个方法未必实用。
arptables:在arp的层次上实现在ARP解析时做防火墙规则,过滤RS响应ARP请求。这是由iptables提供的。
修改RS上内核参数(arp_ignore和arp_announce)将RS上的VIP配置在lo接口的别名上,并限制其不能响应对VIP地址解析请求。
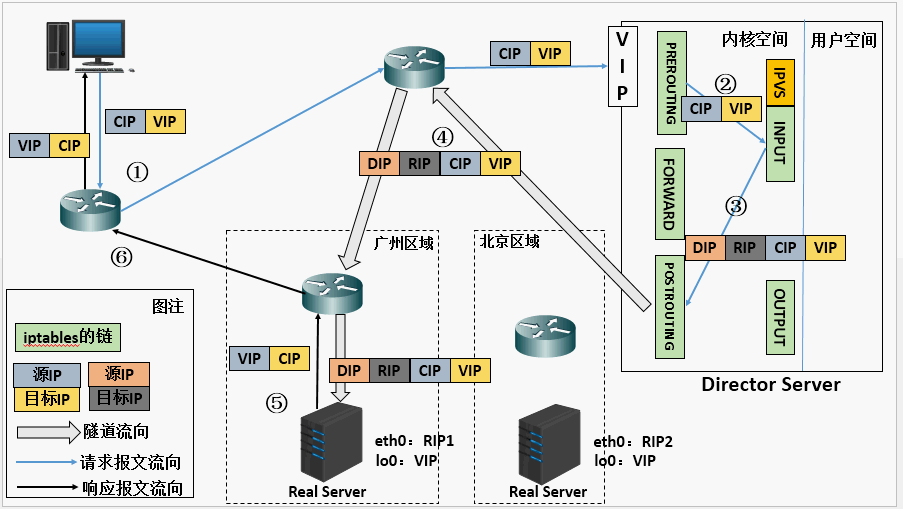
1、当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP 。 2、PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链。 3、IPVS比对数据包请求的服务是否为集群服务,若是,在请求报文的首部再次封装一层IP报文,封装源IP为为DIP,目标IP为RIP。然后发至POSTROUTING链。 此时源IP为DIP,目标IP为RIP。 4、POSTROUTING链根据最新封装的IP报文,将数据包发至RS(因为在外层封装多了一层IP首部,所以可以理解为此时通过隧道传输)。 此时源IP为DIP,目标IP为RIP。 5、RS接收到报文后发现是自己的IP地址,就将报文接收下来,拆除掉最外层的IP后,会发现里面还有一层IP首部,而且目标是自己的lo接口VIP,那么此时RS开始处理此请求,处理完成之后,通过lo接口送给eth0网卡,然后向外传递。 此时的源IP地址为VIP,目标IP为CIP 6、响应报文最终送达至客户端
Tunnel模式特性:
1、RIP、VIP、DIP全是公网地址。 2、RS的网关不会也不可能指向DIP 3、所有的请求报文经由Director Server,但响应报文必须不能进过Director Server 4、不支持端口映射 5、RS的系统必须支持隧道
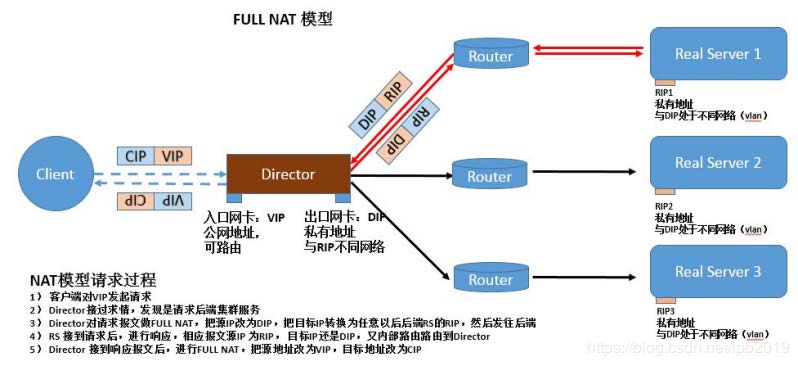
1、客户端对VIP发起请求。 2、Director接收请求,发现是请求后端集群服务。 3、Director对请求报文做full NAT,把源IP改为DIP,把目标IP转换为任意一台后端RS的RIP,然后转发到后端。 4、RS接收到请求后,进行响应,响应报文源IP为RIP,目标IP还是DIP。又内部路由路由到Director. 5、Director接到响应报文后,进行FULL NAT,把源地址改为VIP,目标地址改为CIP,发送给用户。 通过同时修改请求报文的源IP地址和目标IP地址进行转发
fullnat模式特点:
1. VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络;因此,RIP的网关一般不会指向DIP 2. RS收到的请求报文源地址是DIP,因此,只需响应给DIP;但Director还要将其发往Client 3. 请求和响应报文都经由Director 4. 相对NAT模式,可以更好的实现LVS-RealServer间跨VLAN通讯 5. 支持端口映射 注意:此类型kernel默认不支持,
| NAT | TUN | DR | |
|---|---|---|---|
| Server | any | Tunneling | non-arp device |
| server network | private | wlan|lan | lan |
| server number | low(10-20) | high(100) | high(100) |
| server gateway | load balancer | own router | own router |
lvs-nat与lvs-fullnat:
请求和响应报文都经由Director lvs-nat:RIP的网关要指向DIP lvs-fullnat:RIP和DIP未必在同一IP网络,但要能通信
lvs-dr与lvs-tun:
请求报文要经由Director,但响应报文由RS直接发往Client lvs-dr:通过封装新的MAC首部实现,通过MAC网络转发 lvs-tun:通过在原IP报文外封装新IP头实现转发,支持远距离通信
仅根据算法本身进行调度
1、rr:轮询(round robin)
这种算法是最简单的,就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是简单。轮询算法假设所有的服务器处理请求的能力都是一样的,调度器会将所有的请求平均分配给每个真实服务器,不管后端 RS 配置和处理能力,非常均衡地分发下去。这个调度的缺点是,不管后端服务器的繁忙程度是怎样的,调度器都会讲请求依次发下去。如果A服务器上的请求很快请求完了,而B服务器的请求一直持续着,将会导致B服务器一直很忙,而A很闲,这样便没起到均衡的左右。
2、wrr:加权轮询(weight round robin)
这种算法比 rr 的算法多了一个权重的概念,可以给 RS 设置权重,权重越高,那么分发的请求数越多,权重的取值范围 0 – 100。主要是对rr算法的一种优化和补充, LVS 会考虑每台服务器的性能,并给每台服务器添加要给权值,如果服务器A的权值为1,服务器B的权值为2,则调度到服务器B的请求会是服务器A的2倍。权值越高的服务器,处理的请求越多。
3、dh:目标地址散列调度算法 (destination hash)
简单的说,即将同一类型的请求分配给同一个后端服务器,例如将以 .jgp、.png等结尾的请求转发到同一个节点。这种算法其实不是为了真正意义的负载均衡,而是为了资源的分类管理。这种调度算法主要应用在使用了缓存节点的系统中,提高缓存的命中率。
DH:Destination Hashing;目标地址哈希,第一次轮询调度至RS,后续将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如:宽带运营商。
4、sh:源地址散列调度算法(source hash)
即将来自同一个ip的请求发给后端的同一个服务器,如果后端服务器工作正常没有超负荷的话。这可以解决session共享的问题,但是这里有个问题,很多企业、社区、学校都是共用的一个IP,这将导致请求分配的不均衡。
SH:Source Hashing,实现session sticky,源IP地址hash;将来自于同一个IP地址的请求始终发往第一次挑中的RS,从而实现会话绑定
动态方法
主要根据每RS当前的负载状态及调度算法进行调度Overhead=value 较小的RS将被调度
这个算法会根据后端 RS 的连接数来决定把请求分发给谁,比如 RS1 连接数比 RS2 连接数少,那么请求就优先发给 RS1。这里问题是无法做到会话保持,即session共享。
适用于长连接应用
Overhead=activeconns*256+inactiveconns
2、wlc:加权最少连接数(weight least-connection)
这个比最少连接数多了一个加权的概念,即在最少连接数的基础上加一个权重值,当连接数相近,权重值越大,越优先被分派请求。
WLC:Weighted LC,默认调度方法
Overhead=(activeconns*256+inactiveconns)/weight
3、SED:Shortest Expection Delay,初始连接高权重优先
Overhead=(activeconns+1)*256/weight
4、NQ:Never Queue,第一轮均匀分配,后续SED
5、lblc:基于局部性的最少连接调度算法(locality-based least-connection)
将来自同一目的地址的请求分配给同一台RS如果这台服务器尚未满负荷,否则分配给连接数最小的RS,并以它为下一次分配的首先考虑。
动态的DH算法,使用场景:根据负载状态实现正向代理
6、lblcr:基于地址的带重复最小连接数调度 (Locality-Based Least-Connection with Replication)
LBLC with Replication,带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制到负载轻的RS
这个用得少,可以略过。
7、内核版本 4.15 版本后新增调度算法:FO和OVF
FO(Weighted Fail Over)调度算法,在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还 未过载(未设置IP_VS_DEST_F_OVERLOAD标志)的且权重最高的真实服务器,进行调度 OVF(Overflow-connection)调度算法,基于真实服务器的活动连接数量和权重值实现。将新连接调 度到权重值最高的真实服务器,直到其活动连接数量超过权重值,之后调度到下一个权重值最高的真实 服务器,在此OVF算法中,遍历虚拟服务相关联的真实服务器链表,找到权重值最高的可用真实服务器。 一个可用的真实服务器需要同时满足以下条件:
1、未过载(未设置IP_VS_DEST_F_OVERLOAD标志)
2、真实服务器当前的活动连接数量小于其权重值
3、其权重值不为零

 浙公网安备 33010602011771号
浙公网安备 33010602011771号