centos 7.3 快速安装ceph
Ceph简介
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
部署逻辑架构
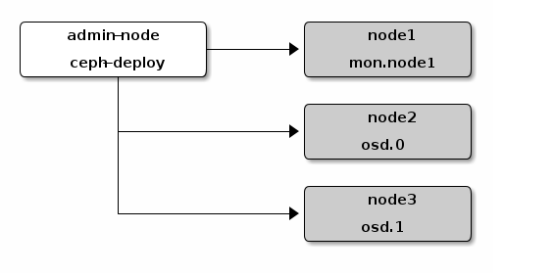
准备3台主机,并且修改主机名(hostnamectl set-hostname xxx 后重启)
IP地址 主机名(Hostname)
192.168.1.24 node1(用该主机同时作为管理和监控节点)
192.168.1.25 node2 (osd.0 节点)
192.168.1.26 node3 (osd.1 节点)
在各节点上安装启用软件仓库,启用可选软件库
# sudo yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/yum.repos.d/dl.fedoraproject.org*
# sudo yum install yum-plugin-priorities
修改node1节点/etc/hosts文件,增加以下内容:
192.168.1.24 node1
192.168.1.25 node2
192.168.1.26 node3
分别这三个节点上存储创建用户且赋予它root权限(本人这里用 ytcwd)
执行
# sudo useradd -d /home/ytcwd -m ytcwd
# sudo passwd ytcwd( 输入密码这里建议三台服务器密码设为一致)
//授予无密码sudo权限
#echo "ytcwd ALL = (root) NOPASSWD:ALL" >> /etc/sudoers.d/ytcwd
#sudo chmod 0440 /etc/sudoers.d/ytcwd
允许无密码 SSH 登录 因为 ceph-deploy 不支持输入密码,你必须在管理节点上生成 SSH 密钥并把其公钥分发到各 Ceph 节点。 ceph-deploy 会尝试给初始 monitors 生成 SSH 密钥对。生成 SSH 密钥对,使用创建的用户不要用 sudo 或 root 。
# ssh-keygen(提示 “Enter passphrase” 时,直接回车,口令即为空如下)
Generating public/private key pair.
Enter file in which to save the key (/ceph-admin/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /ceph-admin/.ssh/id_rsa.
Your public key has been saved in /ceph-admin/.ssh/id_rsa.pub.
//把公钥拷贝到各 Ceph 节点上
#ssh-copy-id ytcwd@node1
#ssh-copy-id ytcwd@node2
#ssh-copy-id ytcwd@node3
在管理节点node1 上修改~/.ssh/config文件(若没有则创建)增加一下内容:
Host node1
Hostname 192.168.1.24
User ytcwd
Host node2
Hostname 192.168.1.25
User ytcwd
Host node3
Hostname 192.168.1.26
User ytcwd
在各节点上安装ntp(防止时钟偏移导致故障)、openssh
#sudo yum install ntp ntpdate ntp-doc
#sudo yum install openssh-server
在各节点上配置防火墙开放所需要的端口和selinux,更新系统
#sudo firewall-cmd --zone=public --add-port=6789/tcp --permanent
//或者关闭防火墙
#sudo systemctl stop firewalld
#sudo systemctl disable firewalld
//关闭selinux
#sudo vim /etc/selinux/config
修改 SELINUX=disabled
在各节点上创建ceph 源(本人这里选择的jewel,这里推荐使用网易或阿里的ceph源,若用官方源文件会很慢而且容易出现下载失败中断等问题,本人深受下载官方源的坑害)
在 /etc/yum.repos.d/目录下创建 ceph.repo然后写入以下内容
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.163.com/ceph/rpm-jewel/el7/$basearch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.163.com/ceph/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.163.com/ceph/rpm-jewel/el7/noarch
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.163.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.163.com/ceph/rpm-jewel/el7/SRPMS
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.163.com/ceph/keys/release.asc
priority=1
在管理节点nod1上进行安装准备(使用ytcwd用户)
//新建文件夹ceph-cluster
$cd ~
$mkdir ceph-cluster
$cd ceph-cluster
//安装ceph-deploy
# sudo yum install ceph-deploy
//若安装ceph后遇到麻烦可以使用以下命令进行清除包和配置
#ceph-deploy purge node1 node2 node3
#ceph-deploy purgedata node1 node2 node3
#ceph-deploy forgetkeys
安装ceph创建集群
//进入到创建ceph-cluster文件夹下,执行命令
#ceph-deploy new node1 node2 node3
//在生成的ceph.conf中加入(写入[global] 段下)
osd pool default size = 2
//如果你有多个网卡,可以把 public network 写入 Ceph 配置文件的 [global] 段下
#public network = {ip-address}/{netmask}
//安装ceph
#ceph-deploy install node1 node2 node3
//配置初始 monitor(s)、并收集所有密钥
# ceph-deploy mon create-initial
新建osd
//添加两个 OSD ,登录到 Ceph 节点、并给 OSD 守护进程创建一个目录。
#ssh node2
#sudo mkdir /var/local/osd0
#exit
#ssh node3
#sudo mkdir /var/local/osd1
#exit
//然后,从管理节点执行 ceph-deploy 来准备 OSD
#ceph-deploy osd prepare node2:/var/local/osd0 node3:/var/local/osd1
//最后,激活 OSD
#ceph-deploy osd activate node2:/var/local/osd0 node3:/var/local/osd1
//确保你对 ceph.client.admin.keyring 有正确的操作权限。
#sudo chmod +r /etc/ceph/ceph.client.admin.keyring
//检查集群的健康状况
#ceph health等 peering 完成后,集群应该达到 active + clean 状态。
安装过程中可能遇到的问题的解决方法:
#ceph-deploy install node1 node2 node3 时报错:
(1) [ceph_deploy][ERROR ]RuntimeError: Failed to execute command: yum -y install epel-release
解决方法:
#yum -y remove ceph-release
(2) [admin-node][WARNIN] Anotherapp is currently holding the yum lock; waiting for it to exit...
解决方法:
#rm -f /var/run/yum.pid
#ceph-deploy osd activate node1 node2 node2报错
(1)若出现l类似错误:ceph-disk: Error: No cluster conf found in /etc/ceph with fsid c5bf8efd-2aea-4e32-85ca-983f1e5b18e7
解决方法:
这是由于fsid的配置文件不一样,导致的,修改对应节点的fsid与管理节点的fid一致即可
(2)若出现[ceph_deploy][ERROR ] RuntimeError: Failedto execute command: /usr/sbin/ceph-disk -v activate --mark-init systemd --mount/var/local/osd0
解决方法:
在各个节点上给/var/local/osd1/和/var/local/osd1/添加权限
如下:
chmod 777 /var/local/osd0/
chmod 777 /var/local/osd0/*
chmod 777 /var/local/osd1/
chmod 777 /var/local/osd1/*
当你的ceph集群出现如下状况时,
$ ceph -s
cluster 3a4399c0-2458-475f-89be-ff961fbac537
health HEALTH_WARN clock skew detected on mon.1, mon.2
monmap e17: 3 mons at {0=192.168.0.5:6789/0,1=192.168.0.6:6789/0,2=192.168.0.7:6789/0}, election epoch 6, quorum 0,1,2 0,1,2
mdsmap e39: 0/0/1 up
osdmap e127: 3 osds: 3 up, 3 in
pgmap v280: 576 pgs, 3 pools, 0 bytes data, 0 objects
128 MB used, 298 GB / 298 GB avail
576 active+clean
$ ceph health detail
HEALTH_WARN clock skew detected on mon.1, mon.2
mon.1 addr 192.168.0.6:6789/0 clock skew 8.37274s > max 0.05s (latency 0.004945s)
mon.2 addr 192.168.0.7:6789/0 clock skew 8.52479s > max 0.05s (latency 0.005965s)
这说明几个节点之间的时间同步出现了问题。
一个简单的解决办法就是:
1)停掉所有节点的ntpd服务,如果有的话
$ /etc/init.d/ntpd stop
2) 同步国际时间
$ ntpdate time.nist.gov
3) 如果执行完以上两步仍有报错,则需要重启所有monitor
另外一个办法就是重新配置ntp服务。
mon故障问题:
故障现象: health HEALTH_WARN 1 mons down, quorum 0,1 ceph-mon1,ceph-mon2
具体解决办法:
mon 故障处理:
[root@TDXY-ceph-01 ~]# ceph -s
cluster 00000000-0000-0000-0001-000000000010
health HEALTH_WARN 23 pgs degraded; 41 pgs peering; 31 pgs stale; 12 pgs stuck inactive; 24 pgs stuck unclean; recovery 7/60 objects degraded (11.667%); too few pgs per osd (4 < min 20); 4/45 in osds are down; 1 mons down, quorum 0,1,2,3 TDXY-ceph-02,TDXY-ceph-04,TDXY-ceph-05,TDXY-ceph-07
monmap e1: 5 mons at {TDXY-ceph-01=0.0.0.0:0/1,TDXY-ceph-02=10.10.120.12:6789/0,TDXY-ceph-04=10.10.120.14:6789/0,TDXY-ceph-05=10.10.120.15:6789/0,TDXY-ceph-07=10.10.120.17:6789/0}, election epoch 38, quorum 0,1,2,3 TDXY-ceph-02,TDXY-ceph-04,TDXY-ceph-05,TDXY-ceph-07
[root@TDXY-ceph-01 ~]# ceph mon remove TDXY-ceph-01
[root@TDXY-ceph-01 ~]# rm -rf /var/lib/ceph/mon/ceph-TDXY-ceph-01
[root@TDXY-ceph-01 ~]# ceph-mon --mkfs -i TDXY-ceph-01 --keyring /etc/ceph/ceph.mon.keyring
[root@TDXY-ceph-01 ~]# touch /var/lib/ceph/mon/ceph-TDXY-ceph-01/done
[root@TDXY-ceph-01 ~]# touch /var/lib/ceph/mon/ceph-TDXY-ceph-01/sysvinit
[root@TDXY-ceph-01 ~]# service ceph start mon

 浙公网安备 33010602011771号
浙公网安备 33010602011771号