systemd --user进程CPU占用高问题分析
正文
原文链接:https://www.cnblogs.com/yaohong/p/16046670.html,转载需经同意。
1.问题由来
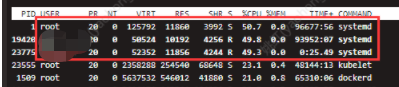
近期发现堡垒机环境有如下问题,systemd占用大量cpu:
2.问题定位
2.1.什么是systemd
咋们可以先从systemd这个进程入手分析这个问题:
根据文档《systemd (简体中文)》文档,我们可知如下图信息:
作用:
systemd 会给每个用户生成一个 systemd 实例,用户可以在这个实例下管理服务,启动、停止、启用以及禁用他们自己的单元。
工作原理:
1 | “从 systemd 226 版本开始,/etc/pam.d/system-login 默认配置中的 pam_systemd 模块会在用户首次登录的时候, 自动运行一个 systemd --user 实例。 只要用户还有会话存在,这个进程就不会退出;用户所有会话退出时,进程将会被销毁。”。 |
根据上面这段话,我们可以猜测:ssh登录时可以创建systemd进程,ssh退出登录时可以销毁systemd --user进程。
怀着这个猜测,我们进行下面的研究分析。
2.2.systemd进程怎么产生的
首先,我们在第一个终端,执行下面的命令创建test3用户:
1 2 3 | $ groupadd test3$ useradd -g test3 -m -d /home/test3 -s /bin/bash test3$ passwd test3 |
然后,在第二个终端,执行ssh登录test3
1 | $ ssh test3@172.21.0.46 |
接着,在第一个终端,执行如下命令过滤新产生的test3 用户的systemd进程
1 | $ top -bc |grep systemd |
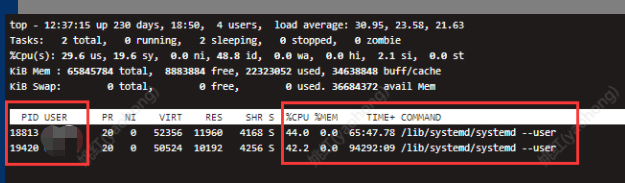
得到如下图回显,可知:1.9秒前产生了一个pid为19178的systemd --user进程,此进程占用了40.9%的CPU。
于是对接systemd进程创建得出如下结论:
systemd版本大于226(centos7为219、ubuntu1604为229),ssh 登录会产生登录用户对应的systemd进程。
2.3.systemd进程为何没有被销毁
既然ssh登录会产生systemd进程,那退出ssh登录应该会销毁对应systemd进程。
于是,我们在2.2中的第二个窗口执行 exit退出ssh连接。
1 | $ exit |

然后,再执行如下命令,发现没有test3用户的systemd进程了。
1 | $ top -bc | grep systemd |
至此,我们对systemd进程的退出也有了了解:退出ssh连接即可销毁对应systemd进程。
但,为什么我们看到的腾讯云环境上systemd进程一直没有被销毁?

此时我想到了 非正常退出ssh连接,
如2.1章节,在第二个终端,执行ssh登录test3,再如下图直接点“X”直接关闭窗口,
然后,在第一个终端,执行如下命令过滤新产生的test3 用户的systemd进程
1 | $ top -bc |grep systemd |
test3用户的systemd进程还存在,惊讶!!!
于是分别做如下操作对systemd进程关闭做测试,并得出相应结论:
- 1.xshell连内部vmware上虚拟机环境,点“X”号关闭窗口,对应systemd进程正常销毁;
- 2.web端连公司堡垒机上的云主机环境,点“X”号关闭窗口,对应systemd进程不能被销毁;
- 3.web端通过部门内部运维平台连接内部虚拟机环境,点“X”号关闭窗口,对应systemd进程不能被销毁;
于是对于systemd进程销毁得出如下结论:
web端连接的虚拟机终端,直接点“X”号关闭窗口,登录用户对应的systemd进程都不能被销毁,exit命令退出终端登录可以销毁,Xshell无此问题。
2.4.systemd进程吃CPU的原因
关于进程跟踪我们很容易想到strace命令。
我们对2.1章节中创建的test3的systemd进程进行跟踪。
得到如下回显:
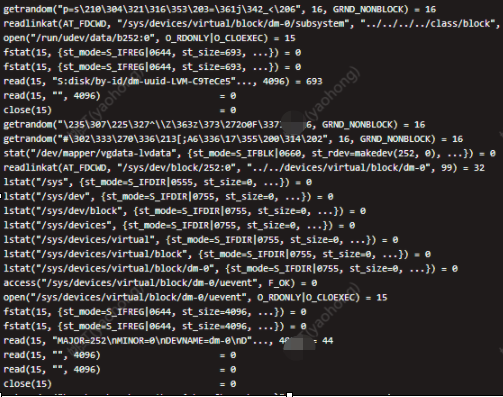
看这个进程是在不停的扫描磁盘。
关于这个问题,我在《google-cloud-kuberbetes-run-away-systemd-100-cpu-usage》一文中得到答案:
Docker在17.03和18.09版本之间的变化导致了大量的systemd活动,无论在pod中执行了什么。同时,只要runc发生change,它导致所有mount units被重新加载,作为执行存活探针的一部分。
于是针对这个猜想,我看了下k8s同一集群中systemd正常与异常的节点:
1.正常节点:
1 2 | # cat /proc/mounts |wc 120 720 46377 |
2.异常节点:
1 2 | # cat /proc/mounts |wc 1017 6102 341121 |
于是瞬间也有了结论:
systemd 进程cpu使用率太高是因为mount挂载点太多,mount有更新后,通过dbus通知到systemd重新遍历所有mount, 遍历操作比较耗cpu。
同时,既然说到和docker版本有关系,我便针对性找了两个有差异的环境做docker版本对不:
- 1.ubuntu1604+mount挂载多+systemd正常环境
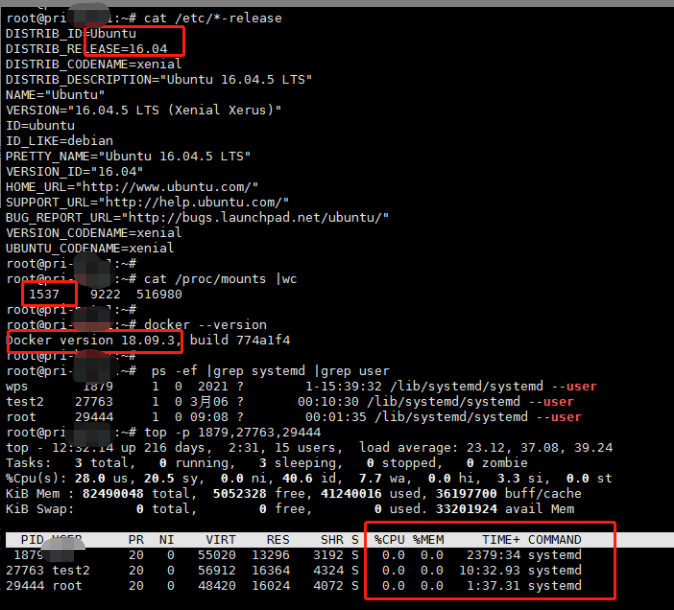
- 2.ubuntu1604+mount挂载多+systemd异常环境
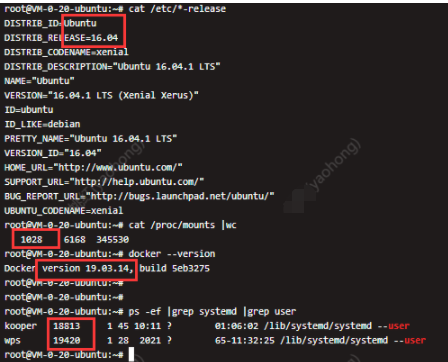
由上图我们发行,环境1中mount挂载为1537个,比环境2中mount挂载为1028个更高但是没出现systemd吃cpu问题,可知系统相同情况下和docker版本有关。
对于什么情况下出现systemd占用高,我们得出如下结论:
systemd版本大于226(ubuntu1604为229)+docker版本为19.03.14,无论runc做了什么操作,dbus会通知systemd重新遍历 mount,遍历mout过多(cat /proc/mounts |wc命令查看)会导致systemd进程吃CPU。
三、解决方案
1.不使用web终端连接systemd版本大于226,docker>=19.03.14的环境,可以使用比如xshell连接。
2.针对runc活动导致systemd进程吃CPU问题,google GKE 团队给出如下优化方案:
原文链接:https://www.cnblogs.com/yaohong/p/16046670.html
四、总结
1.systemd进程如何被创建:systemd版本大于226(centos7为219、ubuntu1604为229),ssh 登录会产生登录用户对应的systemd --user进程。
2.systemd进程为何未被销毁:web端连接的虚拟机终端,直接点“X”号关闭窗口,登录用户对应的systemd进程都不能被销毁,exit命令退出终端登录可以销毁,Xshell无此问题。
3.systemd进程为何吃cpu:systemd版本大于226(ubuntu1604为229)+docker版本为19.03.14,无论runc做了什么操作,dbus会通知systemd重新遍历 mount,如果遍历mount过多(cat /proc/mounts |wc命令查看,700个会吃30%CPU,1000个会吃50%左右CPU)就会导致systemd进程吃CPU。
原文链接:https://www.cnblogs.com/yaohong/p/16046670.html
五、参考文档
《systemd (简体中文)》
《google-cloud-kuberbetes-run-away-systemd-100-cpu-usage》
《 原文链接:https://www.cnblogs.com/yaohong/p/16046670.html》



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架